EMC ViPR 2.1: Third Platform Data Management
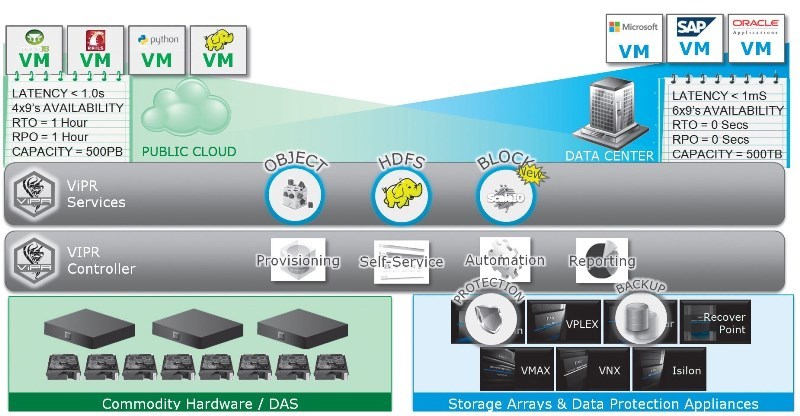
ViPR - Software Defined Data Center Element
ViPR implements for the storage segment about the same as VMware did for the server segment - it creates the ability to abstract resources, form pools and implement automation for the infrastructure. Using VMware APIs, storage pools created in EMC ViPR are presented in VMware vSphere as a simple array. In addition, ViPR provides integration with VMware vStorage API for Storage Awareness (VASA), vCOps, as well as VMware SDDC management and orchestration tools, vCloud Automation Center, and vCenter Operations Manager. Thus, in ViPR, storage management can be carried out both as a standalone object, which appears to be such as such in Microsoft and OpenStack virtual environments, and as part of a VMware software-defined data center.
The main goal of EMC ViPR development was to simplify and reduce the cost of managing existing heterogeneous storage infrastructures, as well as to create a simple data management and data access system in distributed cluster file systems, for example, based on hadoop clusters, as well as in cloud environments.
The basic functionality of EMC ViPR is freely available without any charge and no time limit for use. It is represented by the components: ViPR Controller and SolutionPack (M&R - monitoring and reporting). ViPR Services components that provide support for object, block, and HDFS access are licensed separately. To deploy ViPR with basic functionality, one VMware ESX virtual machine with two processors is sufficient. The ViPR Solution Pack requires four more virtual processors.
You can deploy ViPR not only on EMC equipment, but also on third-party servers. The platform can be used both for managing the storage infrastructure and for managing data hosted on hadoop clusters. In this case, ViPR is additionally deployed as an agent on a separate node.
EMC ViPR is designed for cloud environments and service providers, as well as for those corporate customers who are switching to the model of "IT as a service" and are engaged in creating an internal cloud with web access. ViPR is designed on the basis of a globally distributed architecture, which allows you to do without moving large amounts of data over the network. The platform provides horizontal scaling as the number of devices and data volumes grows, eliminates a single point of failure and allows you to build an environment with fully autonomous control and resource allocation.
Management level
ViPR Controller software is designed to simplify storage infrastructure management (including heterogeneous) both locally and globally. If you compare ViPR Controller with classic storage virtualizers, it is an Out-Of-Band solution, because it does not store any data inside and does not pass any information through itself and is essentially neither a storage system nor a storage virtualizer. ViPR Controller only deals with the management (administration) of the storage pool and related services. Creation of storage pools and their further assignment to applications occurs through a self-service portal.
ViPR Controller can significantly improve automation features, in particular by reducing the harm to administration, as it virtualizes the underlying storage infrastructure. Storage management features, such as resource allocation and migration, are abstracted so that different storage arrays can be managed as a single resource pool from a single console.
At the same time, the corresponding arrays, data protection tools, technological settings and others are “attached” to each pool. Then each pool is associated with a given service level of service.
After creating storage pools, they are shared for use by applications. The self-service portal serves for this. In it, you can browse the catalog of data storage services and select the service resources that are most suitable for your tasks.
For most traditional storage infrastructures, EMC ViPR will only provide the level of control that performs storage discovery, virtual storage pool creation, and assignment of these pools to applications. At the same time, the management of all data exchange remains at the array level.
ViPR Controller supports all types of data access: block, file, object, as well as access to hadoop clusters (data storage based on the distributed file system - HDFS) via iSCSI, NFS, REST, etc. At the block level, ViPR can work with SAN Zoning (SAN Zoning, Brocade Switches, and Cisco).
The new version of ViPR Controller includes support for standard disks and a large number of third-party storage arrays thanks to built-in support or through the OpenStack Cinder plug-in. A complete list of built-in support includes EMC, Hitachi Data Systems (AMS 2100, USP-V, HUS VM and VSP) and NetApp FAS (7-mode only) solutions, as well as standard storage systems. When installing OpenStack Cinder, ViPR also supports Dell, HP, and IBM arrays. In fact, ViPR received support for most of the storage systems available on the market: Dell EqualLogic, HDS (HUS), HP 3PAR (StoreServ), HP Lefthand (StoreVirtual), Huawei T / Dorado, IBM DS8000, IBM Storwize Family / SVC, IBM XIV, LVM (Reference), NetApp, Nexenta, Solaris (ZFS), SolidFire, Zadara Storage and others. Single panel in ViPR 2.
In addition, the new version adds support for standard disks and block data management services based on EMC ScaleIO. ViPR Controller 2.0 began to support converged infrastructures based on VCE Vblock Systems.
EMC array support has been expanded through enhanced integration and administration of EMC VPLEX, EMC RecoverPoint, SRDF, and Data Domain. New features include data management at multiple sites thanks to the storage spatial scaling features that provide data access, integrity and protection. Enhanced multi-tenant functionality to support geographically distributed storage systems that scale to hundreds of clients in multiple locations in the same namespace. This means that ViPR object data management services can now work with multiple locations, offering the most advanced spatial replication and spatial distribution functions to provide a whole new level of efficiency and productivity. ViPR object data management services offer additional features to ensure compliance with the requirements of various regulators, as well as support for the EMC Centera CAS (Content Addressable Storage) API. As a result, EMC Centera users can still use the unique long-term storage features available in their applications on any platform supported by ViPR without modifying existing software.
Since ViPR Controller is in the public domain, it can be said that EMC in terms of SRM solutions is moving towards greater openness and accessibility.
Event monitoring
VIPR SolutionPack (Reporting and Monitoring) includes a number of features. So, for example, visualization of trends in loading storage resources by service levels and virtual storage pools (VSP) with details on virtual arrays (virtual storage arrays - VSA) is available. It is also possible to visualize trends in the use of VSA by service level and visualize trends in the use of storage resources by tenants. In addition, the system allows monitoring VIPR events (warnings, errors, etc.), as well as their presentation for a certain time period.
Data level
In the case of traditional file and block-based workloads, the EMC ViPR platform “self-relieves” and transfers the role of the data layer hosted in this infrastructure to the underlying array. Most workloads of applications in the data center belong to this model, and according to EMC estimates, such workloads will grow by about 70% by 2016. But at the same time, new application workloads are emerging that often work with huge volumes and data flows and serve thousands or millions of users. These are the so-called “third platform” technologies, which are associated with the widespread dissemination of big data, mobile systems, social networks and cloud services, and create thousands of times more information than their predecessors, requiring new storage infrastructures
The features of these new applications suggest a completely new architecture. A mandatory requirement of massive scalability requires a simpler approach to storage infrastructure - object storage. At the same time, access methods are also changing: traditional protocols (such as NFS and iSCSI) give way to new ones, such as HDFS, which are known as the basis of the Hadoop database. To support these new architectures, EMC ViPR provides object data services.
ViPR's object data services provide access via HDFS and REST-based APIs that are compatible with Amazon S3 and OpenStack Swift, and thus applications written for these APIs work without any problems. They also support existing EMC Atmos, EMC VNX, and EMC Isilon arrays as a permanent tier, as well as third-party arrays and standard server solutions. At the moment, this list includes about 20 lines of storage.
ViPR “sees” objects in the form of files, which allows you to get the performance typical of file access and eliminate delays inherent in object data storage. In addition, the ViFS HDFS data service enables local analytics across a heterogeneous storage environment. As a result, the extremely time-consuming and resource-intensive task of managing heterogeneous storage environments disappears by itself.
The solution facilitates the transition to the “third platform”, providing the possibility of coordinated and fully automated management of classic and new storage infrastructures, and also provides integration with the higher level management and orchestration tools offered by VMware, OpenStack and Microsoft, due to which the storage system is seamlessly integrated into the system Data Center workflows and business processes.
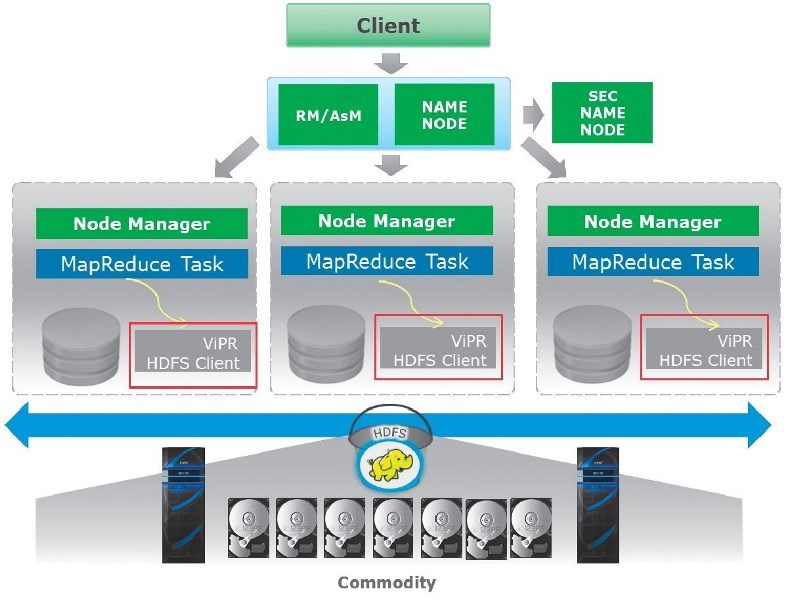
ViPR HDFS data service
Apache Hadoop presents a set of utilities, libraries, and a framework for developing and running distributed programs running on clusters of hundreds and thousands of nodes, and consists of several modules. Hadoop Distributed File System (HDFS) - a distributed file system that writes data to standard servers, providing high aggregated bandwidth of the entire cluster. Hadoop YARN (Yet Another Resource Negotiator) is a resource management platform responsible for managing computing resources in clusters and using their user applications. Hadoop MapReduce is a programming model for processing large amounts of data. The Hadoop ecosystem is an ecosystem of Apache projects such as Pig, Hive, Sqoop, Flume, Oozie, Spark, HBase, Zookeeper, etc., which add value to the project and improve its use.
ViPR HDFS Data Service Architecture
The main components of HDFS are NameNode and DataNode. The first is the central element of HDFS, which serves as the metadata server for the file system. HDFS is managed through a dedicated NameNode server, which hosts the file system indexes, and a secondary NameNode, which can generate snapshots of the memory structures in, thus preventing damage to the file system and reducing data loss. In HDFS, individual files are split into blocks of fixed size. These blocks are stored in a cluster on one or more nodes, links to which are stored in DataNodes. DataNode nodes are used to process read and write requests as directed by NameNode.
Apache Hadoop YARN - This cluster management technology is a key feature of the second generation of Hadoop and is characterized as a highly scalable distributed operating system for applications oriented to work with big data. YARN combines a centralized resource manager, coordinating the way the application uses the resources of the Hadoop system with Node Manager agents, which, in turn, monitor the processing of operations by individual cluster nodes. Separating HDFS from MapReduce using YARN makes the Hadoop environment more suitable for productive (transactional) applications that cannot wait for batch jobs to complete.
It is worth noting that the native implementation of Hadoop has a number of limitations, including limited namespace and cluster performance, low file system reliability, support for only one protocol, high storage costs, inefficient processing of small files, outdated architecture, and lack of enterprise-level capabilities and multi-leases. Let us dwell on these limitations.
The HDFS file system namespace is managed by one server and stored in its memory. Its size is limited by the amount of available memory on the NameNode, and the performance of the file system, in turn, is limited by the performance of NameNode.
Prior to Hadoop 2.x, NameNode was a single point of failure. A NameNode failure caused the cluster to be unavailable. Recently, the High Availability option was added to HDFS, but it has limitations: Hot Standby NameNode cannot actively process requests, in addition, new equipment is needed to support the STAND-BY NameNode.
The native HDFS implementation provides support for only one protocol for accessing data. Object and file access methods are not supported.
By default, HDFS replicates all data blocks three times. This leads to a doubling of storage costs, which becomes extremely redundant, for example, when archiving.
HDFS is inefficient when processing a large volume of small files, because the metadata for each file in the file system must be stored in the memory of one server - in NameNode. For example, a million files consume about 3 GB of RAM.
Since HDFS was designed almost 10 years ago, it focused on unreliable consumer magnetic hard drives and legacy network infrastructure (1GbE). The bottleneck was supposed to be the network, not the drive, which is no longer true for modern infrastructures.
The HDFS file system lacks enterprise-class features such as geo-distribution, disaster recovery, consistent snapshots, deduplication, parameter control, etc. In addition, multi-tenancy features that can provide guaranteed data isolation and performance for many companies are not supported. As a result, many isolated clusters with low utilization.
ViPR HDFS data service allows you to get rid of the above limitations and make the hadoop cluster as close as possible to corporate requirements, regardless of whether they are installed on file servers or / and on ECS. This hadoop-compatible file system (HCFS, Hadoop Compatible File System), which makes it possible to run applications written for Hadoop 2.2 on file arrays and / or EMC ECS (Elastic Cloud Storage) and managed by ViPR Controller. When the ViPR HDFS client is installed on each node of the cluster, all requests to the node are processed by the ViPR HDFS data service client (JAR), and the native components are no longer used. ViPR HDFS data service increases the efficiency, performance and reliability of Hadoop, while providing a number of advantages.
So, an ECS device can easily scale to petabyte and exabyte sizes. At the same time, the ViPR data services / ECS architecture allows scaling of performance and storage capacity independently of each other. ECS provides access within the same platform with support for several API objects, as well as HDFS access, which makes life easier for application developers. Geo-distributed data protection ensures complete information security in the event of a site malfunction or in the event of any disaster. Since the data is highly consistent, applications can access it through any ECS website, regardless of where the latest information was recorded.
Erasing encoding ensures efficient storage of data without compromising its protection or access to it. The ECS storage engine implements the Reed Solomon 12/4 coding erasure scheme, in which the block is divided into 12 data fragments and 4 coding fragments. The resulting 16 fragments are distributed between nodes on the local site. The storage mechanism can restore the entire block from a minimum of 12 fragments. In addition, ViPR data services / ECS is adapted to handle a large number of both small and large files. Using a technology called box-carting, ECS can perform a large number of user transactions at the same time with very little delay. This allows ECS to support high-performance workloads. ECS is also effective in processing very large files.
It is also worth noting that ViPR HDFS data service allows you to select several Hadoop-vendors and combine them for sharing services.
Advanced Packages for Software Defined Storage
Significant changes have affected packages for software-defined storage systems EMC - ViPR SRM and Service Assurance (SA) Suite. Updated complexes provide the most visual representation of complex environments with equipment from different suppliers. In addition to supporting a wide range of EMC and third-party platforms, the ViPR SRM package provides improved integration with ViPR and VPLEX, which gives organizations new opportunities to distribute costs between departments to implement the IT as a Service model outside of the SLA. Enhancements to the ViPR SRM package also include enhanced virtual storage management from the ViPR console. SAS 9.3 integrates with VMware NSX, which provides in-depth visualization of computing and network infrastructure in physical and virtual environments.
The ViPR product family implements two main functions - virtualization of resource management and providing access to data for cloud infrastructures, while the solutions are primarily aimed at large infrastructures of large data centers.
If the task is to automate the process of allocating disk resources for virtual machines, as well as tracking changes in the environment configuration, ViPR Controller is a solution that automates the work with storage systems of any manufacturer. When creating a virtual machine in any virtualization environment, the necessary disks will be allocated immediately with it. Resource allocation and use can be centrally monitored using ViPR SRM, which also supports solutions from many storage manufacturers. The ViPR product is built in such a way that you can manage and monitor an environment of any size by parallelizing the task to many virtual machines. To increase the efficiency of the data center, now you do not need an expensive hardware virtualizer, which is located on the data exchange path, adding additional delays to the environment and slowing down applications.
ViPR Data Services provides the ability to create managed cloud storage resources of any type of data (object, file, block) based on ordinary servers with local disks. This solution has impressive scalability indicators and was developed taking into account the possibility of leasing cloud storage resources.
Using ViPR Controller, this type of storage can be successfully integrated into the data center, where traditional storage systems from different manufacturers are used. Management virtualization will create a single consolidated resource allocation pool from servers with local disks (DAS), storage area network storage (SAN) and network connection storage (NAS).
For questions, contact: emc@muk.ua.
It is worth noting that EMC solutions through a group of companies are now available in Moldova , Georgia , Azerbaijan and Kazakhstan - a distribution contract has recently been signed in these countries.
MUK-Service - all types of IT repair: warranty, non-warranty repair, sale of spare parts, contract service