Testing configuration for Java developers: practical experience

With tests for code, everything is clear (well, at least that they need to be written). With tests for configuration, things are much less obvious, since their very existence. Does someone write them? Is it important? Is it difficult? What kind of results can be achieved with their help?
It turns out that this is also very useful, it is very easy to start doing it, and at the same time there are many nuances in configuration testing. What exactly - is written under the cut on the basis of practical experience.
The material is based on the transcript of the report by Ruslan cheremin Cheremin (Java developer at Deutsche Bank). Next - a speech from the first person.
My name is Ruslan, I work at Deutsche Bank. We start with this:

There is a lot of text here, from afar it may seem that it is Russian. But this is not true. This is a very ancient and dangerous language. I have translated into simple Russian:
- All characters are fictional.
- Use with caution
- Funeral at his own expense
I will describe briefly what I’m going to talk about today. Suppose we have the code:

That is, initially we had some kind of task, we write the code to solve it, and he presumably earns us money. If this code for some reason does not work correctly, it solves the wrong problem and earns us the wrong money. Business does not like that kind of money - they look bad in financial reports.
Therefore, for our important code, we have tests:

Usually there. Now, probably, almost everyone has it. Tests check that the code solves the correct problem and earns the right money. But the service is not limited to the code, and next to the code there is also a configuration:

At least in almost all the projects where I participated, such a configuration was, in one form or another. (I can only remember a couple of cases from my early UI-years, where there were no configuration files, and everything was configured via UI) In this configuration, there are ports, addresses, and algorithm parameters.
Why is configuration important to test?
That's the thing: configuration errors harm the execution of a program no less than errors in the code. They can also force the code to perform an incorrect task - and then look above.
And finding errors in the configuration is even more difficult than in the code, since the configuration is usually not compiled. I cited property files as an example, there are various options in general (JSON, XML, someone stores in YAML), but it is important that none of this is compiled and, therefore, not checked. If you accidentally sealed in a Java file - most likely, it simply will not pass compilation. A random typo in the property does not excite anyone, she will go to work.
And the IDE does not highlight errors in the configuration either, because it knows about the format (for example) of the property-files only the most primitive: that there must be a key and a value, and between them is equal, a colon or a space. But the fact that the value should be a number, network port or address - IDE does not know anything.
And even if you test the application in UAT or in a staging environment, this also does not guarantee anything. Because the configuration, as a rule, is different in each environment, and in UAT you tested only the UAT configuration.
Another subtlety is that, even in production, configuration errors sometimes do not appear immediately. The service may not start at all - and this is still a good script. But it can start, and work for a very long time - until the moment X, when exactly that parameter is needed, in which there is an error. And here you find that the service, which recently even barely changed, suddenly stopped working.
After all that I said, it would seem that testing configurations should be a hot topic. But in practice it looks something like this:
At least, we had it this way - until a certain point. And one of the tasks of my report is to make you look like that, too. I hope that I can push you to this.
Three years ago, Andrei Satarin worked in QA with us at Deutsche Bank, on my team. It was he who brought the idea of testing configurations - that is, he simply took and committed the first such test. Six months ago, at the previous Heisenbug, he gave a talk about configuration testing, as he sees it. I recommend to look, because there he gave a broad view of the problem: both from scientific articles and from the experience of large companies that faced configuration errors and their consequences.
My report will be narrower - on practical experience. I will talk about what problems I, as a developer, faced when I wrote configuration tests, and how I solved these problems. My decisions may not be the best decisions, these are not best practices - this is my personal experience, I tried not to make broad generalizations.
General plan of the report:
- "What you can catch before lunch on Monday": simple, useful examples.
- “Monday, two years later”: where and how can you do better.
- Support for refactoring configuration: how to achieve a dense coverage; software configuration model.
The first part is motivational: I will describe the simplest tests that started it all. There will be a large variety of examples. I hope that at least one of them is resonating with you, that is, you will see some similar problem in yourself, and its solution.
In the first part, the tests themselves are simple, even primitive - from an engineering point of view there is no rocket science. But exactly that they can be done quickly - especially valuable. This is such an "easy entry" to testing configuration, and it is important because there is a psychological barrier before writing these tests. And I want to show that “this can be done”: well, we did it, we did it well, and so far no one has died, we have been living for three years already.
The second part is about what to do after. When you wrote a lot of simple tests - the question of support arises. Some of them are beginning to fall, you understand the errors that they allegedly highlighted. It turns out that this is not always convenient. And there is the question of writing more complex tests - because you have already covered simple cases, you want something more interesting. And here again there are no best practices, I will simply describe some solutions that have worked for us.
The third part is about how testing can support refactoring in a fairly complex and confusing configuration. Again a case study - how we did it. From my point of view, this is an example of how configuration testing can be scaled to solve larger problems, and not just for plugging small holes.
Part 1. "So you can do it"
Now it is difficult to understand what was the first test configuration with us. Andrew is sitting in the hall, he can say that I lied. But it seems to me that everything started with this:

The situation is this: we have n services on one host, each of them raises its JMX server on its port, exports some monitoring JMXs. Ports for all services are configured in the file. But the file takes several pages, and there are many other properties there - it often turns out that the ports of different services conflict. It is easy to make a mistake. Then everything is trivial: some service does not rise, it does not rise beyond it dependent on it - testers rage.
This problem is solved in a few lines. This test, which (I think) was our first, looked like this:

There is nothing complicated in it: go to the folder where the configuration files are located, load them, parse as properties, filter the values whose name contains “jmx.port”, and check that all values are unique. No need to even convert values to integer. Presumably, there are only ports.
My first reaction, when I saw it, was mixed:
The first feeling: what is it in my beautiful unit tests? Why do we climb into the file system?
And then came the surprise: “What, was it possible?”
I’m talking about this because it seems to have some kind of psychological barrier that prevents you from writing such tests. Three years have passed since then, the project is full of such tests, but I often see that my colleagues, running into a configuration error made, do not write tests on it. For the code, everyone is already accustomed to writing regression tests - so that the found error is no longer reproduced. And for the configuration do not do that, something interferes. There is some kind of psychological barrier with which to cope - so I mention such a reaction so that you will also find it in yourselves if it appears.
The following example is almost the same, but slightly modified - I removed all the “jmx”. This time we check all the properties that are called “something there-port”. They must be integer values, and be a valid network port. The Matcher validNetworkPort () hides our custom hamcrest Matcher, which checks that the value is above the range of system ports, below the range of ephemeral ports, and we know that some of the ports we have on the servers are pre-occupied - that’s their list is also hidden in this matcher.
This test is still very primitive. Note that there is no indication in it, what specific property we are testing - it is massive. A single such test can test 500 properties with the name "... port", and verify that they are all integers, in the right range, with all the necessary conditions. Once written, a dozen lines - that's all. This is a very convenient feature, it appears because the configuration has a simple format: two columns, a key and a value. Therefore, it can be so massively processed.
Another example of the test. What are we checking here?

He checks that real passwords do not leak into production. All passwords should look something like this:

You can write a lot of such tests for property files. I will not give more examples - I do not want to repeat, the idea is very simple, then everything should be clear.
... and after writing a sufficient number of such tests, an interesting question emerges: what do we mean by configuration, where is its boundary? We consider the property file as a configuration, we covered it - and what else can be covered in the same style?
What is considered a configuration
It turns out that the project has a lot of text files that are not compiled - at least in the normal build process. They are not verified until the moment of execution on the server, that is, errors in them occur late. All these files - with some stretch - can be called a configuration. At least, they will be tested approximately equally.
For example, we have a system of SQL patches that roll onto the database during the deployment process.

They are written for SQL * Plus. SQL * Plus is a tool from the 60s, and it requires anything strange: for example, the end of the file must be on a new line. Of course, people regularly forget to put the end of the line there, because they were not born in the 60s.
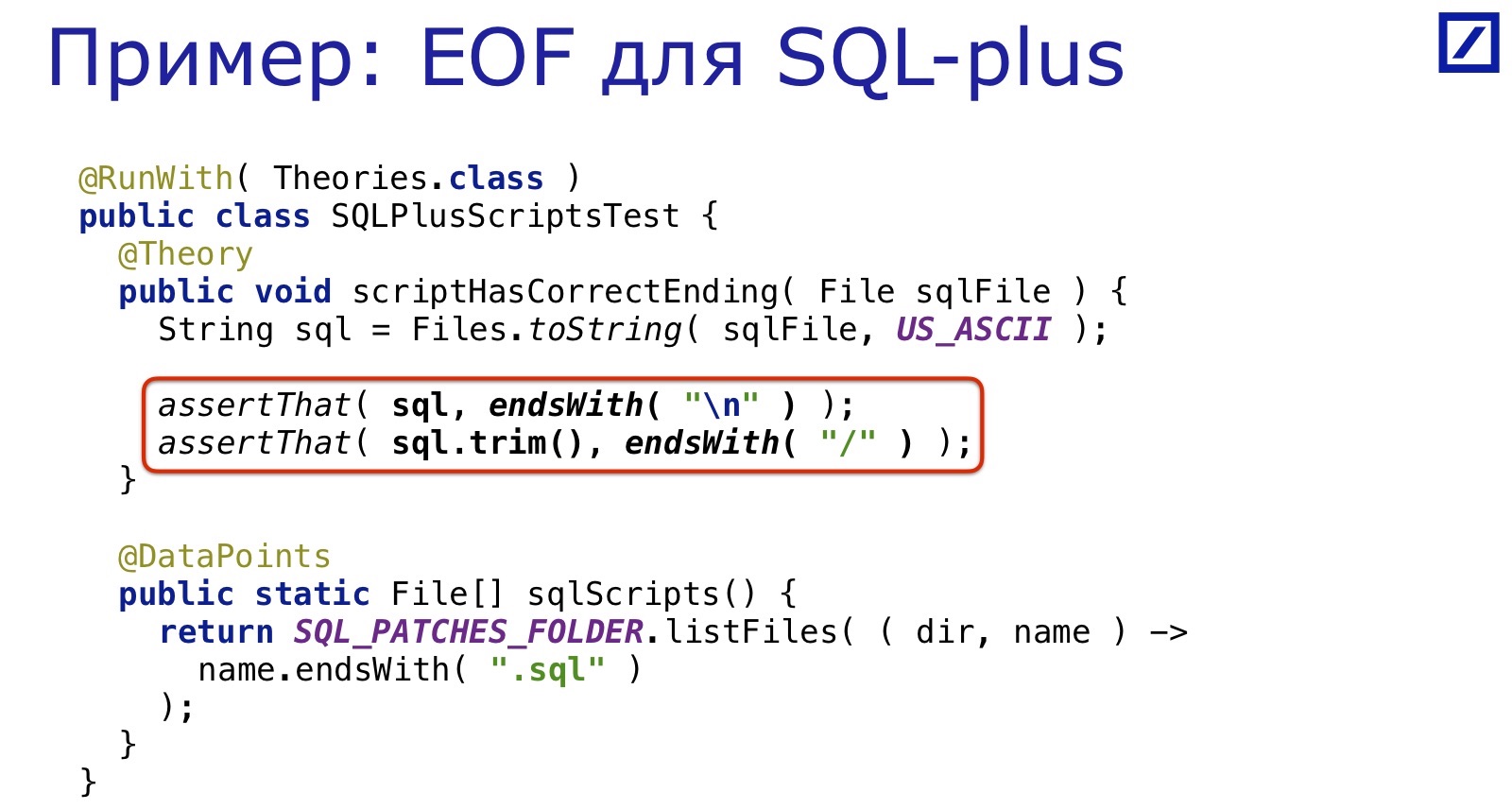
And again it is solved by the same dozen lines: we select all the SQL files, check that there is a trailing slash at the end. Simple, convenient, fast.
Another example of a “text file” is crontabs. Our crontab services start and stop. Two errors most often occur in them:
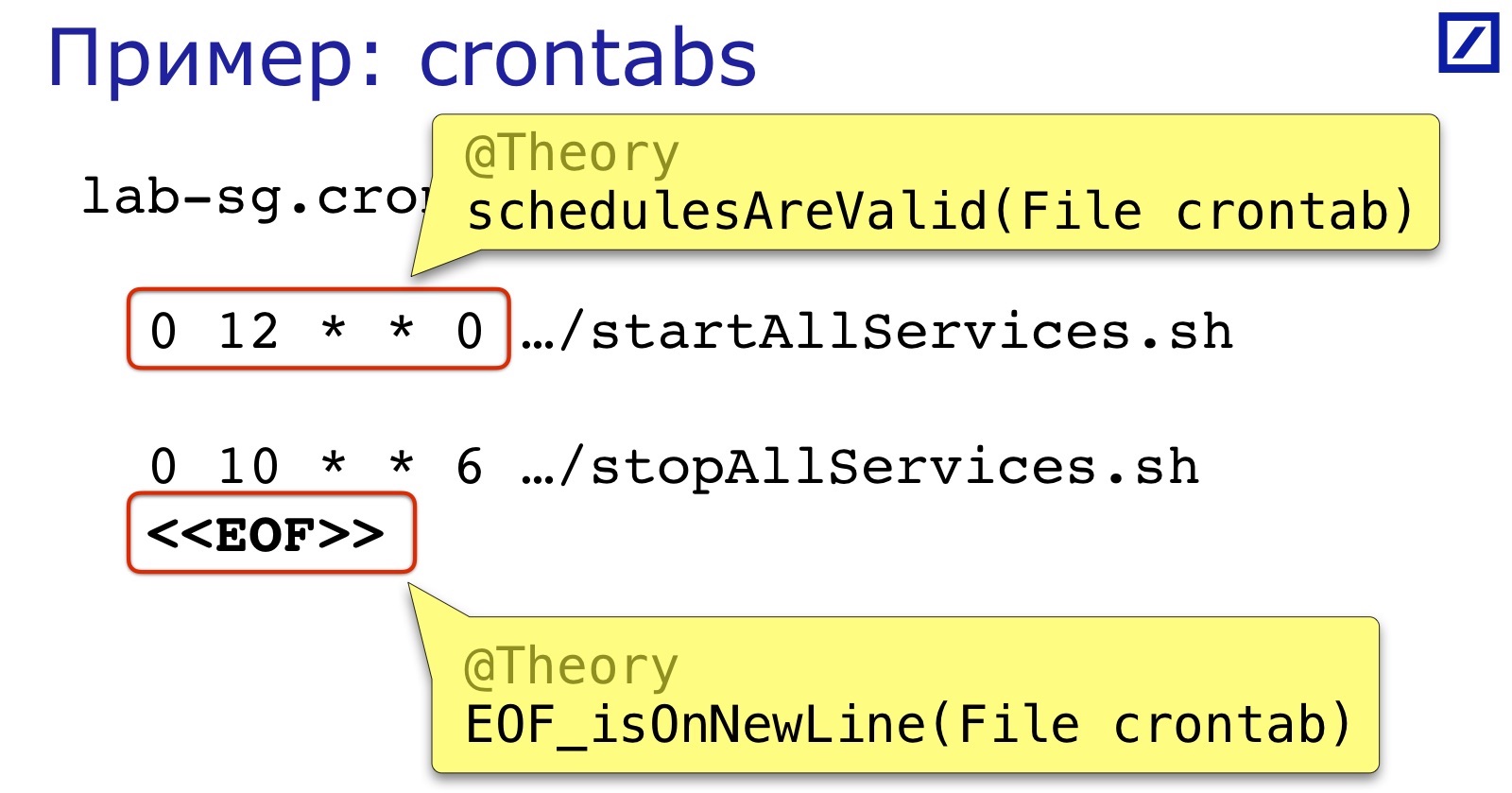
First, the schedule expression format. It is not so complicated, but no one checks it before launch, so it’s easy to put an extra space, comma and the like.
Secondly, as in the previous example, the end of the file must also be on a new line.
And it's all pretty easy to check. About the end of the file is clear, and to check the schedule you can find ready-made libraries that parse cron expression. Before the report I googled: there were at least six of them. I found this six, and in general can be more. When we wrote, we took the simplest of the found ones, because we did not need to check the contents of the expression, but only its syntactic correctness in order for cron to load it successfully.
In principle, you can wind up more checks - check that you start on the right day of the week, that you do not stop services in the middle of the working day. But it was not so useful for us, and we did not bother.
Another idea that works fine is shell scripts. Of course, writing a full-featured bash script parser in Java is a pleasure for the brave. But the bottom line is that a large number of these scripts is not a full-fledged bash. Yes, there are bash-scripts, where the code is straight code, hell and hell, where they drop in once a year and, swearing, run away. But a lot of bash scripts are the same configurations. There are some number of system variables and environment variables that are set to the desired value, thereby configuring other scripts that use these variables. And such variables are easy to grep from this bash file and check something about them.

For example, check that JAVA_HOME is installed on each environment, or that some jni-library used by us is located in LD_LIBRARY_PATH. Somehow we moved from one version of Java to another, and expanded the test: we checked that JAVA_HOME contains “1.8” exactly on that subset of enviroment, which we gradually transferred to the new version.
Here are a few examples. Let you down on the first part of the findings:
- Configuration tests are confusing at first, there is a psychological barrier. But after overcoming it, there are many places in the application that are not covered by checks and can be covered.
- Then they are written easily and cheerfully : a lot of “low-hanging fruits” that quickly give great benefits.
- Reduces the cost of detecting and correcting configuration errors. Since these are essentially unit tests, you can run them on your computer, even before a commit, this greatly reduces the Feedback Loop. Many of them, of course, would be checked at the test deployment stage, for example. And many would not be checked - if it is a production-configuration. And so they are checked directly on the local computer.
- Give the second youth. In the sense that there is a feeling that you can still test a lot of interesting things. After all, the code is not so easy to find that you can test.
Part 2. More complex cases
Let us turn to more complex tests. After covering a large part of the trivial checks, such as those shown here, the question arises: is it possible to check something more complicated?
What does “harder” mean? The tests that I have just described have a structure like this:

They check something for one specific file. That is, we go through the files, we apply to each check a certain condition. This way you can check a lot, but there are more useful scripts:
- A UI application connects to its environment server .
- All services of the same environment connect to the same management server.
- All services of the same environment use the same database.
For example, a UI application connects to its environment server. Most likely, the UI and the server are different modules, if not projects at all, and they have different configurations, they are unlikely to use the same configuration files. Therefore, it is necessary to link them so that all services of one environment are connected to one key management server through which commands are distributed. Again, most likely, these are different modules, different services and generally different teams develop them.
Or all services use the same database, the same - services in different modules.
In fact, there is such a picture: a lot of services, each of them has its own structure of configs, you need to reduce and check something at the intersection:

Of course, you can do exactly that: load one, the second, pull something out somewhere, paste it in the test code. But you can imagine how big the code will be and how readable it will be. We started with this, but then we realized how difficult it is. How to do better?
If you dream, as it were more convenient, then I planned that the test would look like I explain it in human language:
@TheorypublicvoideachEnvironmentIsXXX( Environment environment ){
for( Server server : environment.servers() ) {
for( Service service : server.services() ) {
Properties config = buildConfigFor(
environment,
server,
service
);
//… check {something} about config
}
}
}
For each environment, some condition is met. To check this, you need to find a list of servers, a list of services from the environment. Next, download configs and check something at the intersection. Accordingly, I need such a thing, I called it Deployment Layout.
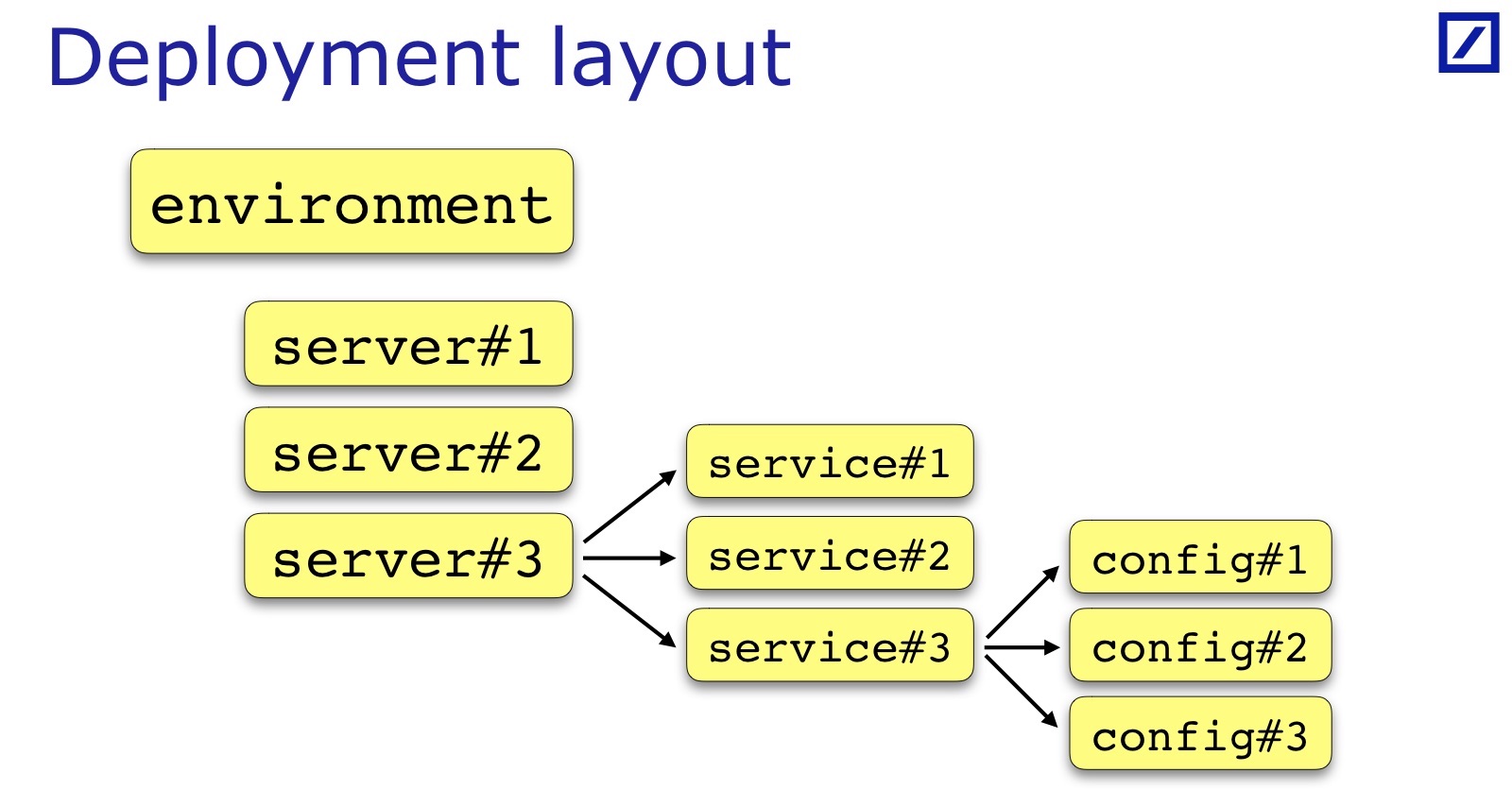
We need the ability from the code to get access to how the application is deployed: on which servers which services are placed, in which Environment - to get this data structure. And based on it, I begin to load the configuration and process it.
Deployment Layout is specific to each team and each project. What I have painted is a general case: there is usually a set of servers and services, a service sometimes has a set of config files, and not one. Sometimes additional parameters are required, which are useful for tests, they have to be added. For example, the rack in which the server is located may be important. Andrei gave an example in his report, when it was important for their services that Backup / Primary services were necessarily in different racks - for his case, you will need to keep an indication of the rack in the deployment layout:
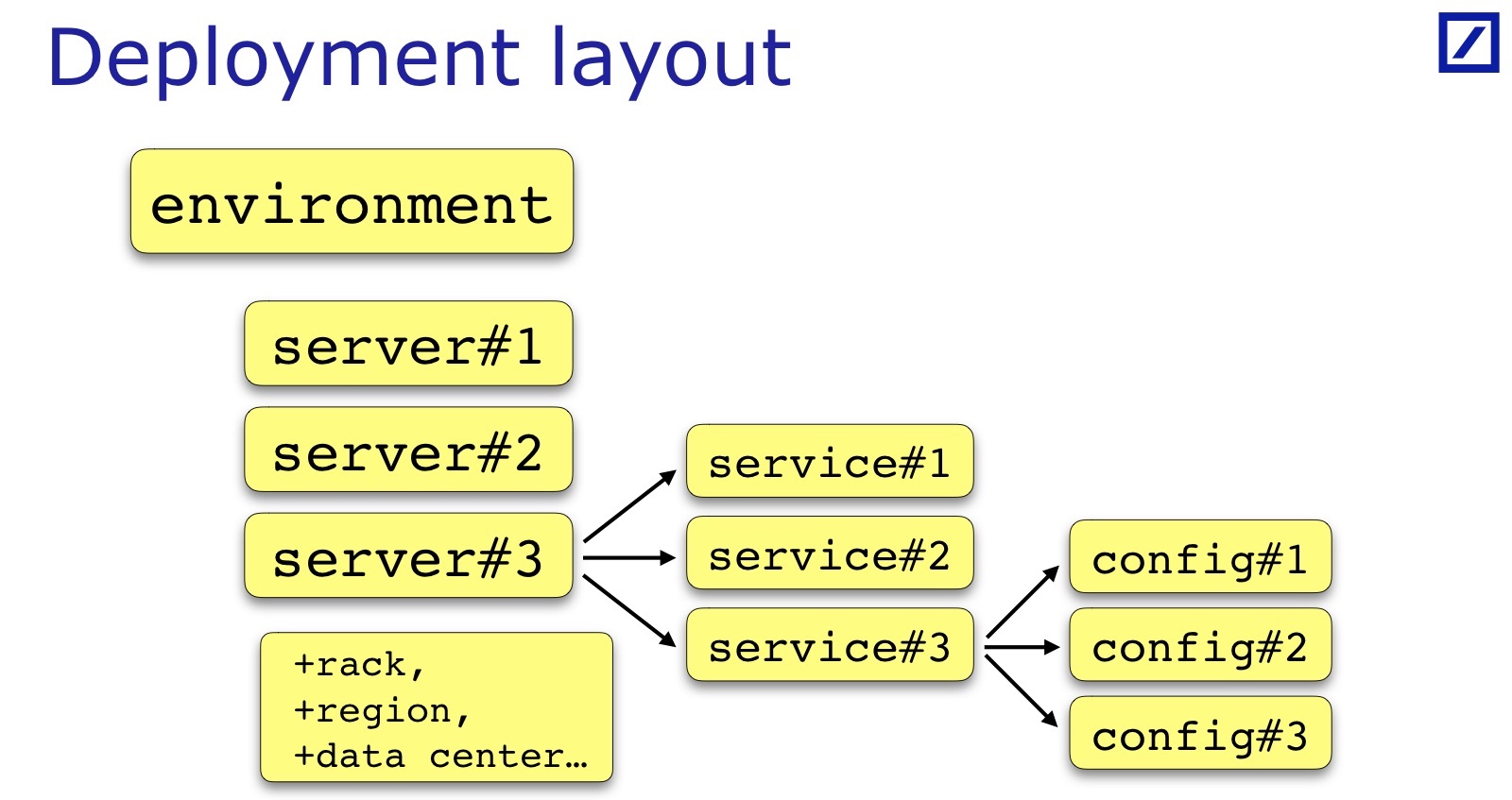
For our purposes, the server region is important, a specific data center , in principle, also, so that Backup / Primary were in different data centers. These are all additional properties of servers, they are project-specific, but on the slide this is such a common denominator.
Where to get the deployment layout? It seems that in any large company there is an Infrastructure Management system, everything is described there, it is reliable, reliable and all that ... in fact, no.
At least, my practice in two projects has shown that it is easier to hard-code first, and then, after three years ... leave it hard.
We have been living with this project for three years now. In the second, it seems, we will integrate with Infrastructure Management in a year, but all these years we have lived like this. By experience, the task of integrating with IM makes sense to postpone in order to get ready-made tests as soon as possible, which will show that they are working and useful. And then it may turn out that this integration may not be so necessary, because the distribution of services across servers does not change so often.
Zakhardkodit can literally like this:
publicenum Environment {
PROD( PROD_UK_PRIMARY, PROD_UK_BACKUP,
PROD_US_PRIMARY, PROD_US_BACKUP,
PROD_SG_PRIMARY, PROD_SG_BACKUP )
…
public Server[] servers() {…}
}
publicenum Server {
PROD_UK_PRIMARY(“rflx-ldn-1"), PROD_UK_BACKUP("rflx-ldn-2"),
PROD_US_PRIMARY(“rflx-nyc-1"), PROD_US_BACKUP("rflx-nyc-2"),
PROD_SG_PRIMARY(“rflx-sng-1"), PROD_SG_BACKUP("rflx-sng-2"),
public Service[] services() {…}
}
The easiest way that we use in the first project is to list the Environment with a list of servers in each of them. There is a list of servers and, it would seem, there should be a list of services, but we cheated: we have starting scripts (which are also part of the configuration).

They start services for each Environment. And the services () method simply grep all services from the file of your server. This is done because there are not so many Environment's, and the servers are also not often added or removed - but there are many services and they are shuffled quite often. It made sense to load the actual layout of services from scripts in order not to change hard-coded layout too often.
After creating such a software configuration model, pleasant bonuses appear. For example, you can write this test:

A test that on every Environment all key services are present. Suppose there are four key services, and the rest can be or not, but without these four there is no sense. You can verify that you have never forgotten them, that all of them have backups within the same Environment. Most often, such errors occur when UAT configuration of these instances, but also in PROD can leak. In the end, errors in UAT also spend time and nerves of testers.
The question arises of maintaining the relevance of the configuration model. You can also write a test for this.
publicclassHardCodedLayoutConsistencyTest{
@Theory
eachHardCodedEnvironmentHasConfigFiles(Environment env){
…
}
@Theory
eachConfigFileHasHardCodedEnvironment(File configFile){
…
}
}
There are configuration files, and there is a deployment layout in the code. And you can check that for each Environment / server / etc. there is a corresponding configuration file, and for each file of the required format - the corresponding Environment. As soon as you forget to add something in one place, the test will fall.
As a result, the deployment layout:
- Simplifies the writing of complex tests that bring together configs from different parts of the application.
- Makes them clearer and more readable. They look like you think about them at a high level, and not like they go through configs.
- During its creation, when people ask questions, it turns out a lot of interesting things about deployment. Restrictions, implicit sacred knowledge - for example, about the possibility of hosting two Environment on the same server. It turns out that developers consider differently and write their services accordingly. And it is useful to settle such moments between developers.
- Well complements the documentation (especially if it is not). Even if there is - I, as a developer, enjoy it in code. Moreover, there you can write important to me, and not to someone, comments. And you can also zhardkodit. That is, if you decide that there can be no two Environment on one server, you can insert a check, and now it will not. At least you will find out if someone tries. That is, this documentation with the ability to enforce it. It is very useful.
Go ahead. After the tests have written, they are "defended" the year, some begin to fall. Some start to fall earlier, but it's not so scary. It is terrible, when a test written a year ago falls, you look at its error message and you do not understand.

Suppose I understand and agree that this is an invalid network port - but where is it? Before the report, I looked at the fact that in our project there are 1200 property-files scattered across 90 modules, in the total of 24,000 lines. (Though I was surprised, but if you count, it is not such a large number — for one service with 4 files each.) Where is this port?
It is clear that there is a message argument in assertThat (), you can write something into it that will help identify the place. But when you write a test, you do not think about it. And even if you think you have to guess what description will be detailed enough so that in a year it can be understood. I would like to automate this moment so that there is a way to write tests with automatic generation of a more or less understandable description by which you can find an error.
Again, I dreamed and planned something like this:
SELECT
environment, server, component, configLocation,
propertyName,
propertyValue
FROM
configuration(environment, server, component)
WHERE
propertyName like “%.port%”
and
propertyValue isnot validNetworkPort()
This is such a pseudo-SQL - well, I just know SQL, so the brain threw a solution out of what is familiar. The idea is that most configuration tests consist of a few of the same kind. First, a subset of parameters is selected by the condition:

Then we check something for the subset with respect to the value:

And then, if there are properties whose values do not satisfy the desire, this is the “sheet” that we want to receive in the error message:

At one time, I even thought about writing a SQL-like type parser to me, since this is easy now. But then I realized that the IDE would not support and prompt him, so people would have to write on this self-made “SQL” blindly, without prompts from the IDE, without compiling, without checking — this is not very convenient. So we had to look for solutions supported by our programming language. If we had .NET, LINQ would help, it’s almost SQL-like.
In Java, there is no LINQ, as close as possible, that is streaming. This is how this test should look like in streams:
ValueWithContext[] incorrectPorts =
flattenedProperties( environment )
.filter( propertyNameContains( ".port" ) )
.filter(
!isInteger( propertyValue )
|| !isValidNetworkPort( propertyValue )
)
.toArray();
assertThat( incorrectPorts, emptyArray() );
flattenedProperties () takes all the configurations of this environment, all files for all servers, services and expands them into a large table. In essence, this is a SQL-like table, but in the form of a set of Java objects. And flattenedProperties () returns this string set as a stream.

Then you add some conditions on this set of Java objects. In this example: we select the “port” that contain propertyName and filter those where the values are not converted to an Integer, or not from a valid range. These are erroneous values, and in theory, they should be an empty set.

If they are not an empty set, we throw an error, which will look like this:

Part 3. Testing as support for refactoring.
Typically, code testing is one of the most powerful refactoring supports. Refactoring is a dangerous process, much is being reworked, and I want to make sure that the application after it is still viable. One way to make sure of this is to first put all the tests on all sides, and then refactor along with it.
And now I had the task of refactoring the configuration. There is an application that is written seven years ago by one intelligent person. The configuration of this application looks like this:

This is an example, there is still a lot of this. Triple nesting level of substitutions, and it is used throughout the configuration:

In the configuration itself, there are few files, but they are included in each other. It uses a small extension iu Properties - Apache Commons Configuration, which just supports inclusions and resolution substitutions in curly braces.
And the author did a fantastic job using just these two things. I think he built a Turing machine on them there. In some places it actually seems that he is trying to do calculations using inclusions and substitutions. I do not know whether this system is Turing-complete, but he, in my opinion, tried to prove that this is so.
And the man left. I wrote, the application works, and he left the bank. Everything works, only nobody fully understands the configuration.
If we take a separate service, then it turns out 10 inclusions, up to triple depth, and in total, if everything is expanded, 450 parameters. In fact, this particular service uses 10-15% of them, the remaining parameters are intended for other services, because the files are shared, used by several services. But what exactly 10-15% of this particular service uses is not so easy to understand. The author apparently understood. Very smart man, very.
The task, respectively, was to simplify the configuration, its refactoring. At the same time, we wanted to keep the application running, because in this situation, the chances of that are low. I want to:
- Simplify configuration.
- So that after refactoring each service still has all its necessary parameters.
- So that he does not have extra parameters. 85% not related to it should not clutter the page.
- That services are still successfully connected in clusters and to work together.
The problem is that it is not known how well they are connected now, because the system is with a high level of redundancy. For example, looking ahead: during refactoring, it turned out that in one of the production configurations there should be four servers in the backup cage, and in fact there were two. Because of the high level of redundancy, no one noticed this - the error accidentally surfaced, but in fact the level of redundancy was for a long time lower than we expected. The point is that we cannot rely on the fact that the current configuration is correct everywhere.
I lead to the fact that you can not just compare the new configuration with the old one. It may be equivalent, but remain at the same time somewhere wrong. It is necessary to check the logical content.
Minimum program: each individual parameter of each service it needs to isolate and check for correctness that the port is the port, the address is the address, the TTL is a positive number, etc. And check out the key interconnections, that the services are mainly connected at the main end points. It wanted to achieve, at least. That is, unlike the previous examples, the task here is not to check individual parameters, but to cover the entire configuration with a full network of checks.
How to test it?
publicclassSimpleComponent{
…
publicvoidconfigure( final Configuration conf ){
int port = conf.getInt( "Port", -1 );
if( port < 0 ) thrownew ConfigurationException();
String ip = conf.getString( "Address", null );
if( ip == null ) thrownew ConfigurationException();
…
}
…
}
How did I solve this problem? There is some simple component, in the example simplified to the maximum. (For those who have not encountered the Apache Commons Configuration: the Configuration object is like Properties, only it has typed methods getInt (), getLong (), etc .; we can assume that this is juProperties on small steroids.) Suppose a component needs two parameters: for example, a TCP address and a TCP port. We pull them out and check. What are four common parts here?

This is the parameter name, type, default values (here they are trivial: null and -1, sometimes there are sane values) and some kind of validation. The port here is validated too simply, incomplete - you can specify the port that will pass it, but will not be a valid network port. Therefore, I would like to improve this moment too. But first of all I want these four things to collapse into one thing. For example, such:
IProperty<Integer> PORT_PROPERTY
= intProperty( "Port" )
.withDefaultValue( -1 )
.matchedWith( validNetworkPort() );
IProperty<String> ADDRESS_PROPERTY
= stringProperty( "Address" )
.withDefaultValue( null )
.matchedWith( validIPAddress() );
Such a composite object is a description of a property that knows its name, the default value, and is able to do validation (here I again use the hamcrest matcher). And this object has an interface like this:
interfaceIProperty<T> {
/* (name, defaultValue, matcher…) *//** lookup (or use default),
* convert type,
* validate value against matcher
*/FetchedValue<T> fetch( final Configuration config )
}
class FetchedValue<T> {
publicfinal String propertyName;
publicfinal T propertyValue;
…
}
That is, after creating an implementation-specific object, you can ask it to extract the parameter that it represents from the configuration. And he will pull out this parameter, check in the process, if there is no parameter, it will give the default value, lead to the desired type, and return it immediately with the name.
That is, here is the name of the parameter and the actual value that the service will see if it requests from this configuration. This allows you to wrap several lines of code in one entity, this is the first simplification that I need.
The second simplification that I needed to solve the problem is the representation of the component, which needs several properties for its configuration. Component configuration model:

We had a component that uses these two properties, there is a model for its configuration — the IConfigurationModel interface that this class implements. IConfigurationModel does everything that the component does, but only the part that relates to the configuration. If a component needs parameters in a certain order with certain default values - IConfigurationModel in itself reduces this information, encapsulates. All other actions of the component are not important to him. This is the component model in terms of access to the configuration.

The point of this idea is that the models are combinable. If there is a component that uses other components, and they are combined there, then the model of this complex component can also merge the results of calls to two subcomponents.
That is, you can build a hierarchy of configuration models parallel to the hierarchy of the components themselves. At the upper model, call fetch (), which will return a sheet from the parameters that he pulled out of the configuration with their names - exactly those that will be needed by the corresponding component in real-time. If we wrote all the models correctly, of course.
That is, the task is to write such models for each component in the application that has access to the configuration. In my application, such components turned out to be quite a bit: the application itself is quite spreading, but it actively re-uses the code, so only 70 main classes are configured. For them, I had to write 70 models.
What it cost:
- 12 services
- 70 configurable classes
- => 70 ConfigurationModels (~ 60 are trivial);
- 1-2 man-weeks.
I just opened the screen with the code of the component that configures itself, and on the next screen I wrote the code of the corresponding ConfigurationModel. Most of them are trivial, like the example shown. In some cases, there are branches and conditional transitions - there the code becomes more spreading, but everything is also solved. For one and a half to two weeks, I solved this problem, for all 70 components I described the models.
As a result, when we put all this together, we get the following code:

For each service / environment / etc. take the configuration model, that is, the top node of this tree, and we ask you to get everything from the config. At this moment, all validations pass inside, each of the properties, when it gets itself out of the config, checks its value for correctness. If at least one does not pass, except for the inside fly out. All code is obtained by checking that all values are valid in isolation.
Service Interdependencies
We still had a question about how to check the interdependencies of services. It is a bit more complicated, you have to look at what interdependencies are there. It turned out that interdependencies boil down to the fact that services must “meet” via network endpoints. Service A should listen to exactly the address to which Service B sends packets, and vice versa. In my example, all the dependencies between the configurations of different services boiled down to this. It was possible to solve this problem so straightforwardly: get ports and addresses from different services and check them. There would be a lot of tests, they would be cumbersome. I'm a lazy person and I did not want this. Therefore, I did otherwise.
First, I wanted to somehow abstract this network endpoint itself. For example, for a TCP connection, you only need two parameters: an address and a port. For a multicast connection, there are four parameters. I would like to turn it into some kind of object. I did this in the Endpoint object, which inside hides everything you need. In the slide, an example is OutcomingTCPEndpoint, an outgoing TCP network connection.
IProperty<IEndpoint> TCP_REQUEST = outcomingTCP(
// (+matchers, +default values)
“TCP.Request.Address”,
“TCP.Request.Port»
);
classOutcomingTCPEndpointimplementsIEndpoint{
//(localInterface, localAddress, multicastGroup, port) @Overridebooleanmatches( IEndpoint other);
}
Outwardly, the Endpoint interface yields a single matches () method, in which you can give another Endpoint, and find out if this pair is similar to the server and client parts of a single connection.
Why is it "like"? Because we do not know what will happen in reality: maybe, formally, it should connect to the port addresses, but in a real network between these nodes, the firewall is worth it - we cannot verify this only by configuration. But we can find out if they are already even formally, the ports / addresses do not match. Then, most likely, in reality, they also will not connect with each other.
Accordingly, instead of primitive values of properties, addresses-ports-multicast-groups, we now have a complex property that returns Endpoint. And in all ConfigurationModels instead of separate properties - there are such complex ones. What does this give us? This gives us the following cluster connectivity check:
ValueWithContext[] allEndpoints =
flattenedConfigurationValues(environment)
.filter( valueIsEndpoint() )
.toArray();
ValueWithContext[] unpairedEndpoints =
Arrays.stream( allEndpoints )
.filter( e -> !hasMatchedEndpoint(e, allEndpoints) )
.toArray();
assertThat( unpairedEndpoints, emptyArray() );
We choose endpoints from all the properties of this environment, and then we just clarify whether there are some that do not match with anyone, do not connect with anyone. All previous machinery allows you to make such a test in a few lines. Here, the complexity of checking “all with all” will be O (n ^ 2), but this is not so important, because there are hundreds of endpoints, you can not even optimize them.
That is, for each Endpoint we go through all the rest and find out if at least one who connects with it. If there was not one, most likely he was supposed to be there, but because of an error, he was not there.
In general, it may be that the service has holes that stick outward - that is, to external services, outside the current application. Such holes will need to be explicitly filtered. I was lucky, in my case, external clients are connected by the same holes that the service itself uses inside. It is so closed and economical in terms of network connections.
Here is a solution to the problem of testing. And the main task, I remind you, was to refactor. And I was ready to do the refactoring with my hands, but when I did all these tests, and they stopped, I realized that I had the opportunity to refactor automatically.
This entire ConfigurationModel hierarchy allows:
- Convert to another format
- Execute configuration requests (“all udp ports used by services on this server”)
- Export network connections between services as a diagram.
I can draw the whole configuration into memory in such a way that each property tracks its origin. After that, I can convert this configuration in memory, and pour it into other files, in a different order, in a different format - as it suits me. So I did: I wrote a small code to transform that sheet into the kind in which I wanted to transform it. In fact, it had to be done several times, because initially it was not obvious which format would be convenient and understandable, and I had to make several visits to try.
But this is not enough. With this construct, with the help of ConfigurationModels, I can make requests to the configuration. Raise it in memory and find out which specific UDP ports are used on this server by different services, request a list of the ports used, with the instructions of the services.
Moreover, I can link the services by endpoints and output it as a diagram, export to .dot. And other similar requests are easily made. It turned out such a Swiss knife - the cost of its construction has paid off.
On this I finish. Findings:
- In my opinion, in my experience, testing the configuration is important and fun.
- There are a lot of low-hanging fruits, the entry threshold to start low. You can solve complex problems, but there are a lot of simple ones too.
- If you use a little brains, you can get powerful tools that allow you not only to test, but also a lot to do with the configuration.
If you like this report from the Heisenbug 2018 Piter, pay attention: the next Heisenbug will take place on December 6-7 in Moscow . Most of the descriptions of new reports are already available on the conference website . And from November 1, ticket prices are rising - so it makes sense to decide now.