Apache Ignite + Apache Spark Data Frames: More Fun Together
Hi, Habr! My name is Nikolai Izhikov, I work for Sberbank Technologies in the development team for Open Source solutions. Over 15 years of commercial development in Java. I am an Apache Ignite committer and an Apache Kafka contributor.
Under the cat you will find a video and text version of my report on the Apache Ignite Meetup on how to use Apache Ignite with Apache Spark and what features we have implemented for this.
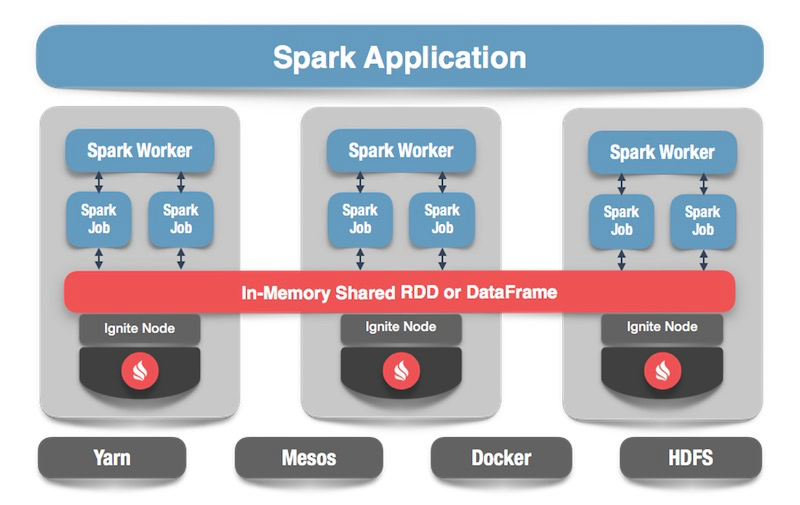
What is Apache Spark? This is a product that allows you to quickly perform distributed computing and analytical queries. Basically, Apache Spark is written in Scala.
Apache Spark has a rich API for connecting to various storage systems or retrieving data. One of the features of the product is a universal SQL-like query engine for data obtained from various sources. If you have several sources of information, you want to combine them and get some results, Apache Spark is what you need.
One of the key abstractions that Spark provides is Data Frame, DataSet. In terms of a relational database, this is a table, a kind of source that provides data in a structured way. The structure, type of each column, its name, etc. are known. Data frames can be created from various sources. Examples include json files, relational databases, various hadoop systems, and Apache Ignite.
Spark supports joines in SQL queries. You can combine data from various sources and get results, perform analytical queries. In addition, there is an API for saving data. When you have completed queries, conducted a study, Spark provides an opportunity to save the results to the receiver that supports this feature, and, accordingly, to solve the data processing problem.
Apache Spark can read data from Apache Ignite SQL tables and write them in the form of such a table. Any DataFrame that is formed in Spark can be saved as an Apache Ignite SQL table.
Apache Ignite allows you to use all existing Ignite SQL tables in Spark Session without registering with your hands — using IgniteCatalog inside an extension of the standard SparkSession - IgniteSparkSession.
Here it is necessary to go deep into the Spark device. In terms of a normal database, a directory is a place where meta-information is stored: which tables are available, which columns are in them, and so on. When a request arrives, meta-information is pulled from the directory and the SQL engine does something with tables, data. By default, Spark all read tables (it doesn’t matter from a relational database, Ignite, Hadoop) have to be manually registered in a session. As a result, you get the opportunity to make a SQL query on these tables. Spark finds out about them.
To work with the data that we loaded into Ignite, we need to register the tables. But instead of registering each table with “hands”, we implemented the ability to automatically access all Ignite tables.
What is the feature here? For some reason I do not understand, the Spark directory is the internal API, i.e. A third party cannot come and create their own directory implementation. And since Spark left Hadoop, it only supports Hive. And everything else you have to register with your hands. Users often ask how to get around this and immediately make SQL queries. I implemented a directory that allows you to browse and access Ignite tables without registering ~ and sms ~, and initially offered this patch to the Spark community, to which I received the answer: this patch is not interesting for some internal reasons. And they also did not give the internal API forward.
Now the Ignite-catalog is an interesting feature implemented using the internal Spark API. To use this directory, we have our own session implementation, This is a regular SparkSession, within which you can make requests, process data. The differences are that we have built in ExternalCatalog for working with Ignite tables, as well as IgniteOptimization, which will be described below.
SQL Optimization - the ability to execute SQL statements inside Ignite. By default, when performing join, grouping, calculating aggregates, other complex SQL queries, Spark reads data in row by row mode. The only thing that a data source can do is to filter rows efficiently.
If join or grouping is used, Spark pulls out all the data from the table to itself in memory for the worker, applying the specified filters, and only then groups them or performs other SQL operations. In the case of Ignite, this is not optimal, because Ignite itself has a distributed architecture and has knowledge of the data that is stored in it. Therefore, Ignite itself can effectively calculate the aggregates, carry out grouping. In addition, there can be a lot of data, and for their grouping you will need to subtract everything, pick up all the data in Spark, which is quite expensive.
Spark provides an API with which you can change the original SQL plan of the query, perform optimization, and forward into the Ignite that part of the SQL query that can be executed there. This will be effective in terms of speed, as well as memory consumption, because we will not use it to extract data that will be immediately grouped.
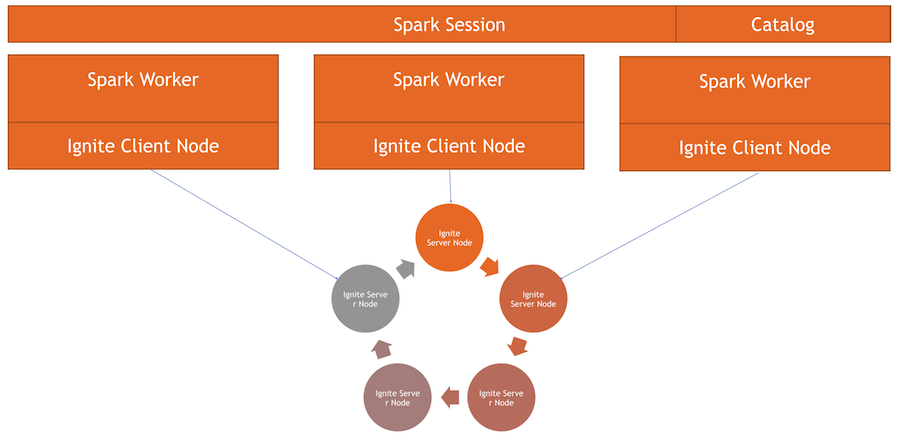
We have a cluster Ignite - this is the bottom half of the picture. Zookeeper is not, because there are only five nodes. There are Spark workers, within each worker a client Ignite node rises. Through it, we can make a request and read the data, interact with the cluster. Also, the client node rises inside the IgniteSparkSession to run the directory.
Moving to code: how to read data from a SQL table? In the case of Spark, everything is quite simple and good: we say that we want to calculate some data, we specify the format - this is a definite constant. Next we have several options - the path to the configuration file for the client node, which starts when reading data. We indicate which table we want to read, and tell Spark to load. We receive data and we can do with them what we want.
Once we have generated the data — not necessarily from Ignite, from any source — we can just as easily save everything, specifying the format and the corresponding table. Command Spark to record, specify the format. In the config we prescribe which cluster to connect to. We specify the table in which we want to save. Additionally, we can prescribe service options - specify the primary key, which we create on this table. If the data simply goes without creating a table, then this parameter is not needed. At the end, click save and the data is written.
Now let's see how this all works.
LoadDataExample.scala
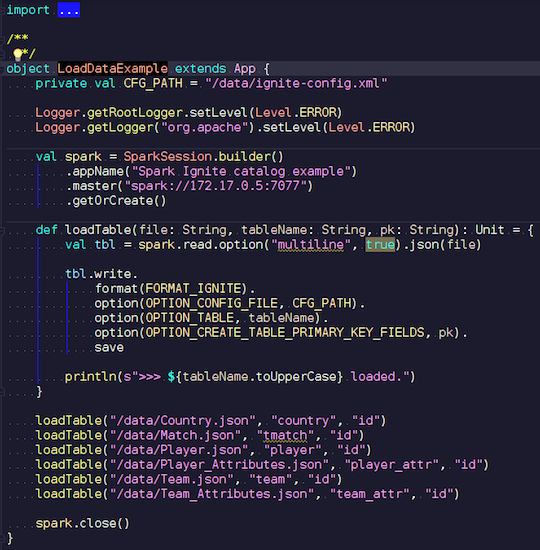
This obvious application will first demonstrate write capabilities. I chose for example data on football matches, downloaded statistics from a known resource. It contains information on tournaments: leagues, matches, players, teams, player attributes, team attributes - data that describe football matches in European leagues (England, France, Spain, etc.).
I want to upload them to Ignite. We create a Spark session, specify the address of the wizard, and trigger the loading of these tables, passing parameters. An example on Scala, and not on Java, because Scala is less verbose and so is better for example.
We pass the name of the file, read it, indicate that it is multiline, this is a standard json file. Then write to Ignite. We do not describe the structure of our file anywhere - Spark itself determines what data we have and what their structure is. If everything goes smoothly, a table is created that contains all the necessary fields of the desired data types. This is how we can load everything inside Ignite.
When the data is loaded, we can see it in Ignite and use it immediately. As a simple example - a request that allows you to find out which team played the most matches. We have two columns: hometeam and awayteam, hosts and guests. We select, group, count, summarize and join with data by command — to enter the name of the command. Ta-dam - and the data from the json-chikov we got into Ignite. We see Paris Saint-Germain, Toulouse - we had a lot of data on French teams.
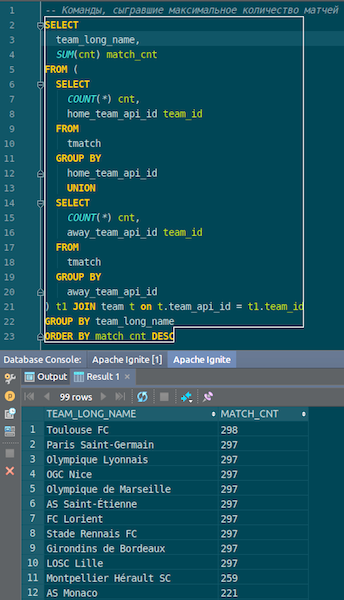
We summarize. We have now loaded the data from the source, json-file, into Ignite, and quite quickly. Perhaps, from the point of view of big data, this is not too large, but for a local computer it is decent. The table schema is taken from the json file in its original form. The table was created, the column names were copied from the source file, the primary key was created. The ID is everywhere, and the primary key is the ID. This data got into Ignite, we can use it.
Let's see how it works.
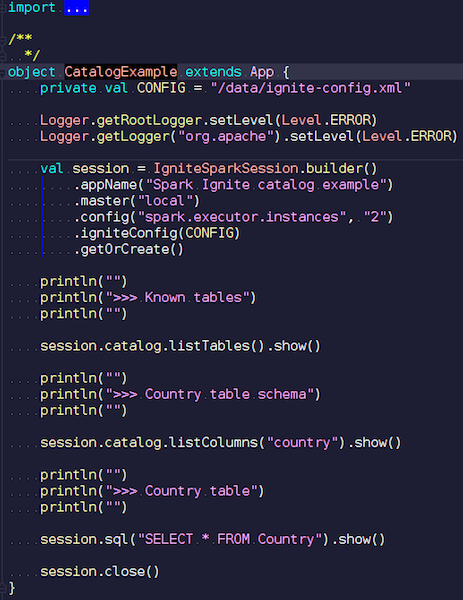
CatalogExample.scala In a
fairly simple way, you can access and query all your data. In the past example, we ran a standard Spark session. And Ignite had no specifics there - besides the fact that you have to put a jar with the right data source - a completely standard job through the public API. But, if you want to access the Ignite-tables automatically, you can use our extension. The difference is that instead of SparkSession, we write IgniteSparkSession.
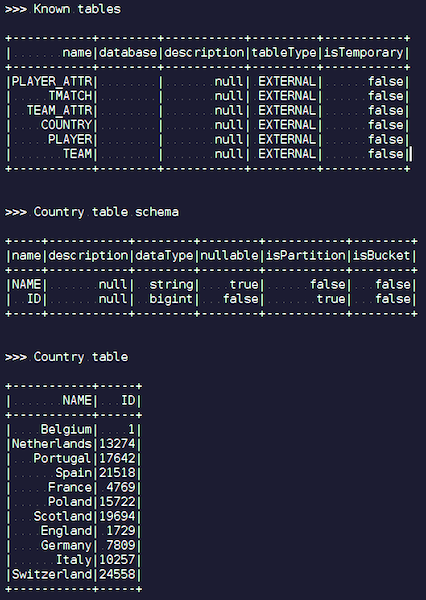
As soon as you create an IgniteSparkSession object, you can see in the directory all the tables that you just loaded into Ignite. You can see their diagram and all the information. Spark already knows about the tables that Ignite has, and you can easily get all the data.
When you make complex queries in Ignite using a JOIN, Spark first pulls out the data and only then JOIN groups it. To optimize the process, we made the IgniteOptimization feature - it optimizes the Spark query plan and allows you to forward into the Ignite those parts of the query that can be executed inside Ignite. We show the optimization on a specific request.
Execute the request. We have a person table - some employees, people. Each employee knows the ID of the city in which he lives. We want to know how many people live in each city. Filter - in which city more than one person lives. Here is the original plan Spark is building:
Relation is just an Ignite table. There are no filters - we just download all data from the Person table from the cluster over the network. Then Spark aggregates all this - in accordance with the query and returns the result of the query.
It is easy to see that all this subtree with filter and aggregation can be executed inside Ignite. This will be much more efficient than pulling all the data from a potentially large Spark table — this is what our IgniteOptimization feature does. After analyzing and optimizing the tree, we get the following plan:
As a result, we get only one relation, since we optimized the whole tree. And inside you can already see that the request will go to Ignite, which is quite close to the original request.
Suppose we are joining different data sources: for example, we have one DataFrame from Ignite, the second from json, the third from Ignite again, and the fourth from some relational database. In this case, only the subtree will be optimized in the plan. We optimize what we can, throw it into Ignite, and Spark will do the rest. Due to this, we get a gain in speed.
Another example with JOIN:
We have two tables. We click on the value and select all of them - ID, values. Spark offers a plan like this:
We see that he will pull out all the data from one table, all the data from the second, join them inside of himself and produce results. After processing and optimization, we get exactly the same query that goes to Ignite, where it is executed relatively quickly.
I will show another example.
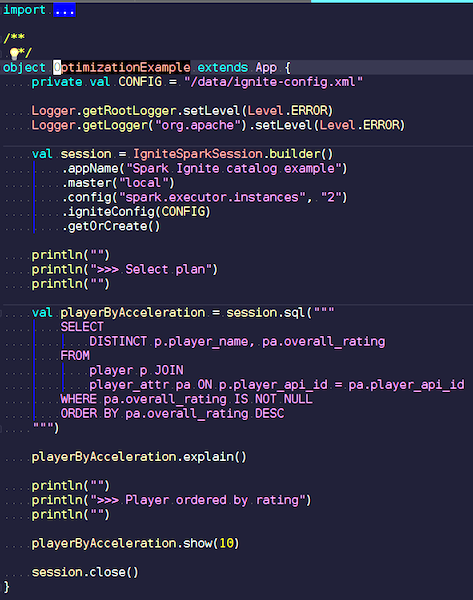
OptimizationExample.scala
We create an IgniteSpark session that automatically includes all of our optimization features. Here is the query: find the players with the highest rating and display their names. In the player table - their attributes and data. We join, filter garbage data and display the players with the highest rating. Let's see what plan we have after optimization, and show the results of this query.
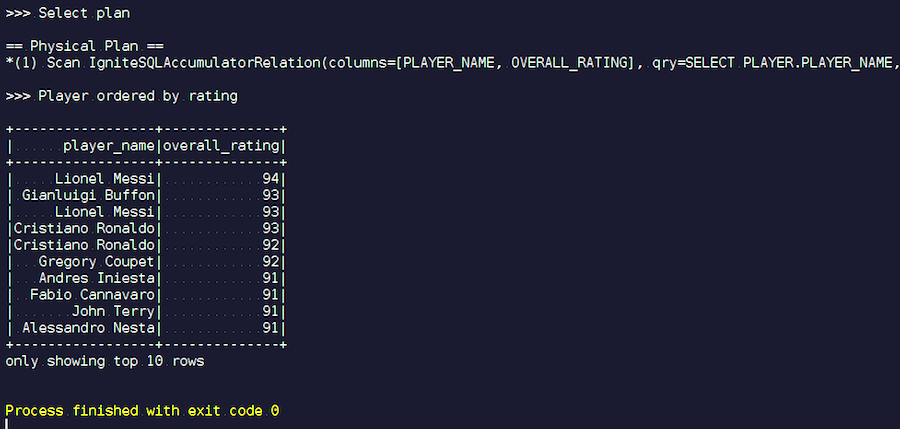
We start. We see familiar names: Messi, Buffon, Ronaldo, etc. By the way, some for some reason are found in two ways - Messi and Ronaldo. Fans of football may seem strange that the list includes unknown players. These are goalkeepers, players with fairly high performance - compared to other players. Now we look at the plan of the request that was executed. In Spark, almost nothing was done, that is, we sent the entire request again to Ignite.
Our project is an open source product, so we always welcome patches and feedback from developers. Your help, feedback, patches are very welcome. We are waiting for them. 90% of the Ignite-community is Russian-speaking. For example, for me, until I started working on Apache Ignite, not the best knowledge of English was a deterrent. In Russian, it is hardly worth writing a dev-list, but even if you write something wrong, they will answer and help you.
What can be improved on this integration? How can you help if you have such a desire? The list below. Asterisks denote complexity.

To test the optimization, you need to write tests with complex queries. Above, I showed some obvious queries. It is clear that if you write a lot of groupings and a lot of joins, then something can fall. This is a very simple task - come and do it. If we find any bugs on the basis of tests, they will need to be fixed. There will be more difficult.
Another clear and interesting task is the integration of Spark with a thin client. He is initially able to specify some sets of IP addresses, and this is enough to join the Ignite cluster, which is convenient in the case of integration with an external system. If you suddenly want to join the solution of this problem, I will personally help with it.
If you want to join the Apache Ignite community, here are some helpful links:
We have a responsive dev-list, which will help you. It is still far from ideal, but in comparison with other projects it is really alive.
If you know Java or C ++, you are looking for a job and want to develop Open Source (Apache Ignite, Apache Kafka, Tarantool, etc.) write here: join-open-source@sberbank.ru.
Under the cat you will find a video and text version of my report on the Apache Ignite Meetup on how to use Apache Ignite with Apache Spark and what features we have implemented for this.
What Apache Spark Can Do
What is Apache Spark? This is a product that allows you to quickly perform distributed computing and analytical queries. Basically, Apache Spark is written in Scala.
Apache Spark has a rich API for connecting to various storage systems or retrieving data. One of the features of the product is a universal SQL-like query engine for data obtained from various sources. If you have several sources of information, you want to combine them and get some results, Apache Spark is what you need.
One of the key abstractions that Spark provides is Data Frame, DataSet. In terms of a relational database, this is a table, a kind of source that provides data in a structured way. The structure, type of each column, its name, etc. are known. Data frames can be created from various sources. Examples include json files, relational databases, various hadoop systems, and Apache Ignite.
Spark supports joines in SQL queries. You can combine data from various sources and get results, perform analytical queries. In addition, there is an API for saving data. When you have completed queries, conducted a study, Spark provides an opportunity to save the results to the receiver that supports this feature, and, accordingly, to solve the data processing problem.
What kind of integration of Apache Spark with Apache Ignite we have implemented
- Reading data from Apache Ignite SQL tables.
- Writing data to Apache Ignite SQL tables.
- IgniteCatalog inside IgniteSparkSession is the ability to use all existing Ignite SQL tables without hands-on registration.
- SQL Optimization - the ability to execute SQL statements inside Ignite.
Apache Spark can read data from Apache Ignite SQL tables and write them in the form of such a table. Any DataFrame that is formed in Spark can be saved as an Apache Ignite SQL table.
Apache Ignite allows you to use all existing Ignite SQL tables in Spark Session without registering with your hands — using IgniteCatalog inside an extension of the standard SparkSession - IgniteSparkSession.
Here it is necessary to go deep into the Spark device. In terms of a normal database, a directory is a place where meta-information is stored: which tables are available, which columns are in them, and so on. When a request arrives, meta-information is pulled from the directory and the SQL engine does something with tables, data. By default, Spark all read tables (it doesn’t matter from a relational database, Ignite, Hadoop) have to be manually registered in a session. As a result, you get the opportunity to make a SQL query on these tables. Spark finds out about them.
To work with the data that we loaded into Ignite, we need to register the tables. But instead of registering each table with “hands”, we implemented the ability to automatically access all Ignite tables.
What is the feature here? For some reason I do not understand, the Spark directory is the internal API, i.e. A third party cannot come and create their own directory implementation. And since Spark left Hadoop, it only supports Hive. And everything else you have to register with your hands. Users often ask how to get around this and immediately make SQL queries. I implemented a directory that allows you to browse and access Ignite tables without registering ~ and sms ~, and initially offered this patch to the Spark community, to which I received the answer: this patch is not interesting for some internal reasons. And they also did not give the internal API forward.
Now the Ignite-catalog is an interesting feature implemented using the internal Spark API. To use this directory, we have our own session implementation, This is a regular SparkSession, within which you can make requests, process data. The differences are that we have built in ExternalCatalog for working with Ignite tables, as well as IgniteOptimization, which will be described below.
SQL Optimization - the ability to execute SQL statements inside Ignite. By default, when performing join, grouping, calculating aggregates, other complex SQL queries, Spark reads data in row by row mode. The only thing that a data source can do is to filter rows efficiently.
If join or grouping is used, Spark pulls out all the data from the table to itself in memory for the worker, applying the specified filters, and only then groups them or performs other SQL operations. In the case of Ignite, this is not optimal, because Ignite itself has a distributed architecture and has knowledge of the data that is stored in it. Therefore, Ignite itself can effectively calculate the aggregates, carry out grouping. In addition, there can be a lot of data, and for their grouping you will need to subtract everything, pick up all the data in Spark, which is quite expensive.
Spark provides an API with which you can change the original SQL plan of the query, perform optimization, and forward into the Ignite that part of the SQL query that can be executed there. This will be effective in terms of speed, as well as memory consumption, because we will not use it to extract data that will be immediately grouped.
How things work
We have a cluster Ignite - this is the bottom half of the picture. Zookeeper is not, because there are only five nodes. There are Spark workers, within each worker a client Ignite node rises. Through it, we can make a request and read the data, interact with the cluster. Also, the client node rises inside the IgniteSparkSession to run the directory.
Ignite Data Frame
Moving to code: how to read data from a SQL table? In the case of Spark, everything is quite simple and good: we say that we want to calculate some data, we specify the format - this is a definite constant. Next we have several options - the path to the configuration file for the client node, which starts when reading data. We indicate which table we want to read, and tell Spark to load. We receive data and we can do with them what we want.
spark.read
.format(FORMAT_IGNITE)
.option(OPTION_CONFIG_FILE, TEST_CONFIG_FILE)
.option(OPTION_TABLE, "person")
.load()Once we have generated the data — not necessarily from Ignite, from any source — we can just as easily save everything, specifying the format and the corresponding table. Command Spark to record, specify the format. In the config we prescribe which cluster to connect to. We specify the table in which we want to save. Additionally, we can prescribe service options - specify the primary key, which we create on this table. If the data simply goes without creating a table, then this parameter is not needed. At the end, click save and the data is written.
tbl.write.
format(FORMAT_IGNITE).
option(OPTION_CONFIG_FILE, CFG_PATH).
option(OPTION_TABLE, tableName).
option(OPTION_CREATE_TABLE_PRIMARY_KEY_FIELDS, pk).
save
Now let's see how this all works.
LoadDataExample.scala
This obvious application will first demonstrate write capabilities. I chose for example data on football matches, downloaded statistics from a known resource. It contains information on tournaments: leagues, matches, players, teams, player attributes, team attributes - data that describe football matches in European leagues (England, France, Spain, etc.).
I want to upload them to Ignite. We create a Spark session, specify the address of the wizard, and trigger the loading of these tables, passing parameters. An example on Scala, and not on Java, because Scala is less verbose and so is better for example.
We pass the name of the file, read it, indicate that it is multiline, this is a standard json file. Then write to Ignite. We do not describe the structure of our file anywhere - Spark itself determines what data we have and what their structure is. If everything goes smoothly, a table is created that contains all the necessary fields of the desired data types. This is how we can load everything inside Ignite.
When the data is loaded, we can see it in Ignite and use it immediately. As a simple example - a request that allows you to find out which team played the most matches. We have two columns: hometeam and awayteam, hosts and guests. We select, group, count, summarize and join with data by command — to enter the name of the command. Ta-dam - and the data from the json-chikov we got into Ignite. We see Paris Saint-Germain, Toulouse - we had a lot of data on French teams.
We summarize. We have now loaded the data from the source, json-file, into Ignite, and quite quickly. Perhaps, from the point of view of big data, this is not too large, but for a local computer it is decent. The table schema is taken from the json file in its original form. The table was created, the column names were copied from the source file, the primary key was created. The ID is everywhere, and the primary key is the ID. This data got into Ignite, we can use it.
IgniteSparkSession and IgniteCatalog
Let's see how it works.
CatalogExample.scala In a
fairly simple way, you can access and query all your data. In the past example, we ran a standard Spark session. And Ignite had no specifics there - besides the fact that you have to put a jar with the right data source - a completely standard job through the public API. But, if you want to access the Ignite-tables automatically, you can use our extension. The difference is that instead of SparkSession, we write IgniteSparkSession.
As soon as you create an IgniteSparkSession object, you can see in the directory all the tables that you just loaded into Ignite. You can see their diagram and all the information. Spark already knows about the tables that Ignite has, and you can easily get all the data.
IgniteOptimization
When you make complex queries in Ignite using a JOIN, Spark first pulls out the data and only then JOIN groups it. To optimize the process, we made the IgniteOptimization feature - it optimizes the Spark query plan and allows you to forward into the Ignite those parts of the query that can be executed inside Ignite. We show the optimization on a specific request.
SQL Query:
SELECT
city_id,
count(*)
FROM
person p
GROUPBY city_id
HAVINGcount(*) > 1Execute the request. We have a person table - some employees, people. Each employee knows the ID of the city in which he lives. We want to know how many people live in each city. Filter - in which city more than one person lives. Here is the original plan Spark is building:
== AnalyzedLogicalPlan ==
city_id: bigint, count(1): bigint
Project [city_id#19L, count(1)#52L]
+- Filter (count(1)#54L > cast(1 as bigint))
+- Aggregate [city_id#19L], [city_id#19L, count(1) AS count(1)#52L, count(1) AS count(1)#54L]
+- SubqueryAlias p
+- SubqueryAlias person
+- Relation[NAME#11,BIRTH_DATE#12,IS_RESIDENT#13,SALARY#14,PENSION#15,ACCOUNT#16,AGE#17,ID#18L,CITY_ID#19L]
IgniteSQLRelation[table=PERSON]
Relation is just an Ignite table. There are no filters - we just download all data from the Person table from the cluster over the network. Then Spark aggregates all this - in accordance with the query and returns the result of the query.
It is easy to see that all this subtree with filter and aggregation can be executed inside Ignite. This will be much more efficient than pulling all the data from a potentially large Spark table — this is what our IgniteOptimization feature does. After analyzing and optimizing the tree, we get the following plan:
== OptimizedLogicalPlan ==
Relation[CITY_ID#19L,COUNT(1)#52L]
IgniteSQLAccumulatorRelation(
columns=[CITY_ID, COUNT(1)], qry=SELECTCITY_ID, COUNT(1) FROMPERSONGROUPBY city_id HAVING count(1) > 1)As a result, we get only one relation, since we optimized the whole tree. And inside you can already see that the request will go to Ignite, which is quite close to the original request.
Suppose we are joining different data sources: for example, we have one DataFrame from Ignite, the second from json, the third from Ignite again, and the fourth from some relational database. In this case, only the subtree will be optimized in the plan. We optimize what we can, throw it into Ignite, and Spark will do the rest. Due to this, we get a gain in speed.
Another example with JOIN:
SQL Query -
SELECT
jt1.id as id1,
jt1.val1,
jt2.id as id2,
jt2.val2
FROM
jt1 JOIN
jt2 ON jt1.val1 = jt2.val2
We have two tables. We click on the value and select all of them - ID, values. Spark offers a plan like this:
== AnalyzedLogicalPlan ==
id1: bigint, val1: string, id2: bigint, val2: string
Project [id#4L AS id1#84L, val1#3, id#6L AS id2#85L, val2#5]
+- JoinInner, (val1#3 = val2#5)
:- SubqueryAlias jt1
: +- Relation[VAL1#3,ID#4L] IgniteSQLRelation[table=JT1]
+- SubqueryAlias jt2
+- Relation[VAL2#5,ID#6L] IgniteSQLRelation[table=JT2]We see that he will pull out all the data from one table, all the data from the second, join them inside of himself and produce results. After processing and optimization, we get exactly the same query that goes to Ignite, where it is executed relatively quickly.
== OptimizedLogicalPlan ==
Relation[ID#84L,VAL1#3,ID#85L,VAL2#5]
IgniteSQLAccumulatorRelation(columns=[ID, VAL1, ID, VAL2],
qry=
SELECTJT1.IDAS id1, JT1.VAL1, JT2.IDAS id2, JT2.VAL2
FROMJT1JOINJT2ONJT1.val1 = JT2.val2
WHEREJT1.val1 ISNOTNULLANDJT2.val2 ISNOTNULL)I will show another example.
OptimizationExample.scala
We create an IgniteSpark session that automatically includes all of our optimization features. Here is the query: find the players with the highest rating and display their names. In the player table - their attributes and data. We join, filter garbage data and display the players with the highest rating. Let's see what plan we have after optimization, and show the results of this query.
We start. We see familiar names: Messi, Buffon, Ronaldo, etc. By the way, some for some reason are found in two ways - Messi and Ronaldo. Fans of football may seem strange that the list includes unknown players. These are goalkeepers, players with fairly high performance - compared to other players. Now we look at the plan of the request that was executed. In Spark, almost nothing was done, that is, we sent the entire request again to Ignite.
Apache Ignite Development
Our project is an open source product, so we always welcome patches and feedback from developers. Your help, feedback, patches are very welcome. We are waiting for them. 90% of the Ignite-community is Russian-speaking. For example, for me, until I started working on Apache Ignite, not the best knowledge of English was a deterrent. In Russian, it is hardly worth writing a dev-list, but even if you write something wrong, they will answer and help you.
What can be improved on this integration? How can you help if you have such a desire? The list below. Asterisks denote complexity.
To test the optimization, you need to write tests with complex queries. Above, I showed some obvious queries. It is clear that if you write a lot of groupings and a lot of joins, then something can fall. This is a very simple task - come and do it. If we find any bugs on the basis of tests, they will need to be fixed. There will be more difficult.
Another clear and interesting task is the integration of Spark with a thin client. He is initially able to specify some sets of IP addresses, and this is enough to join the Ignite cluster, which is convenient in the case of integration with an external system. If you suddenly want to join the solution of this problem, I will personally help with it.
If you want to join the Apache Ignite community, here are some helpful links:
- Start here - https://ignite.apache.org/community/resources.html
- Sources here - https://github.com/apache/ignite/
- Docks here - https://apacheignite.readme.io/docs
- The bugs here are https://issues.apache.org/jira/browse/IGNITE
- You can write here - dev@ignite.apache.org, user@ignite.apache.org
We have a responsive dev-list, which will help you. It is still far from ideal, but in comparison with other projects it is really alive.
If you know Java or C ++, you are looking for a job and want to develop Open Source (Apache Ignite, Apache Kafka, Tarantool, etc.) write here: join-open-source@sberbank.ru.