Servers based on the new Intel Xeon E5v3 processors and DDR4 memory

We hasten to inform you that dedicated servers based on the processors of the new Intel Xeon E5v3 family and DDR4 memory are now available for order in our data centers. We are the first in Russia to offer these servers to the customers the latest and most productive configurations to date.
A complete list of available configurations is presented on our website .
In this article, we will talk in detail about the new processors and their capabilities.
Intel Xeon E5v3: what's new
Intel Xeon E5v3 processors are manufactured according to the same technological process as the previous generation processors, but at the same time they have implemented many improvements at the microarchitecture level and the chip design has been improved.
The main innovations are listed in the table below:
| Region | Change | Advantage |
| Crystal Interconnects | Two ring buses per processor | Enhances processing power and throughput of cores |
| Memory controller (home agent) |
|
|
| Last Level Cache, LLC |
|
|
| Power management | Each core operates at its own frequency under voltage corresponding to the current load. |
|
| QPI 1.1 | Up to 9.6GT / s | Speeding up cache synchronization in multiprocessor configurations |
| Integrated I / O Controller (IO-Hub) |
| Increased PCI bandwidth in a conflict situation (multiple simultaneous attempts to access the same cache line) |
| PCI Express 3.0 | Allows simultaneous bus recording to multiple devices | Reduced Bus Bandwidth Utilization |
Below we will talk about them in more detail.
Cluster on Die (Cluster on Die)
As mentioned above, Intel Xeon E5v3 processors use the Cluster on Die circuitry. To better understand the features of this scheme, compare it with previous microarchitectures.
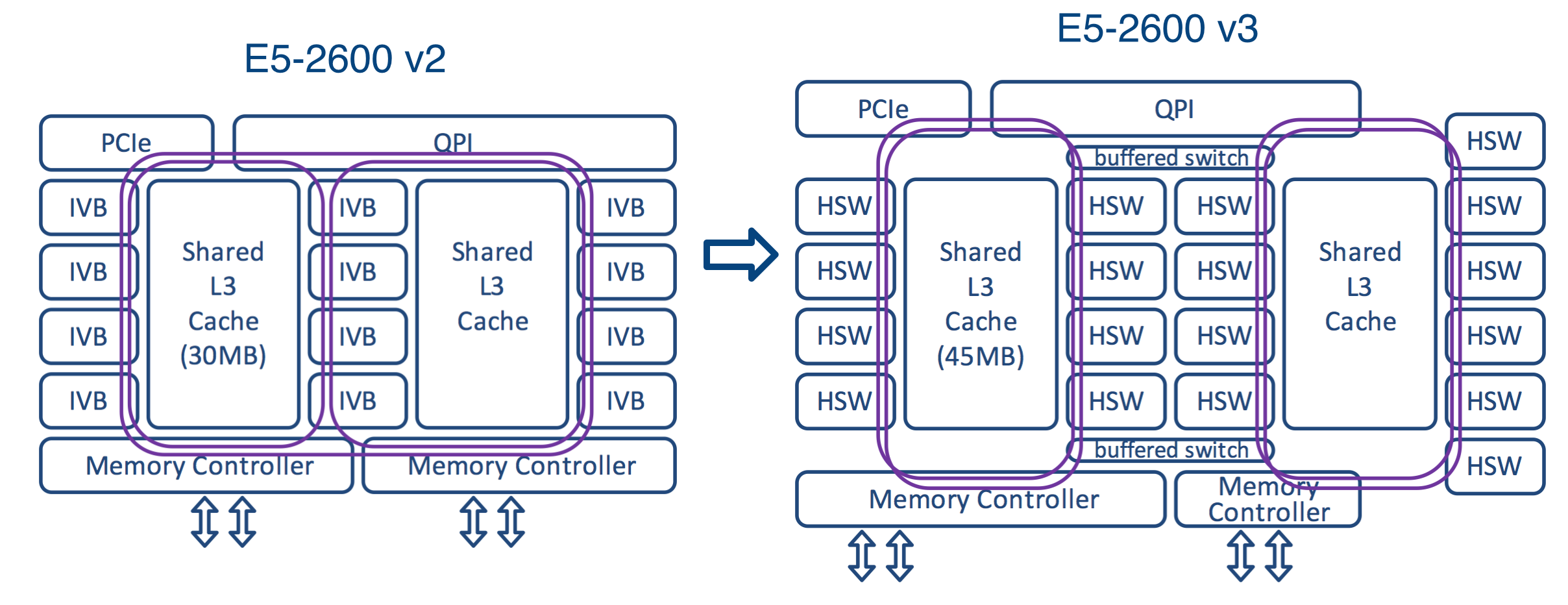
Sandy Bridge processors consisted of two rows of cores and the last level cache blocks connected by one ring bus. The Ivy Bridge processors (Intel Xeon E5v2) had three rows connected by two ring buses. Ring busses moved data in opposite directions (clockwise and counterclockwise) to ensure their delivery along the shortest route and reduce delay time. After the data entered the ring structure, it was necessary to coordinate their route in order to avoid confusion with the previous data.
On Intel Xeon E5v3 processors, the cores are arranged in four rows around two last-level cache blocks. It is very difficult to control the movement of data using such a scheme, and therefore the following solution was proposed: two ring buses were separated from each other. A buffered switch is used to exchange data between them - this is similar to how an Ethernet switch divides a network into two segments.
Ring buses can operate independently, and this increases the bandwidth. This innovation is especially useful when FMA / AVX instructions work with large 256-bit chunks of data.
In addition to the described configuration, there are two others. The basic information about them is presented in the following graphic diagram:
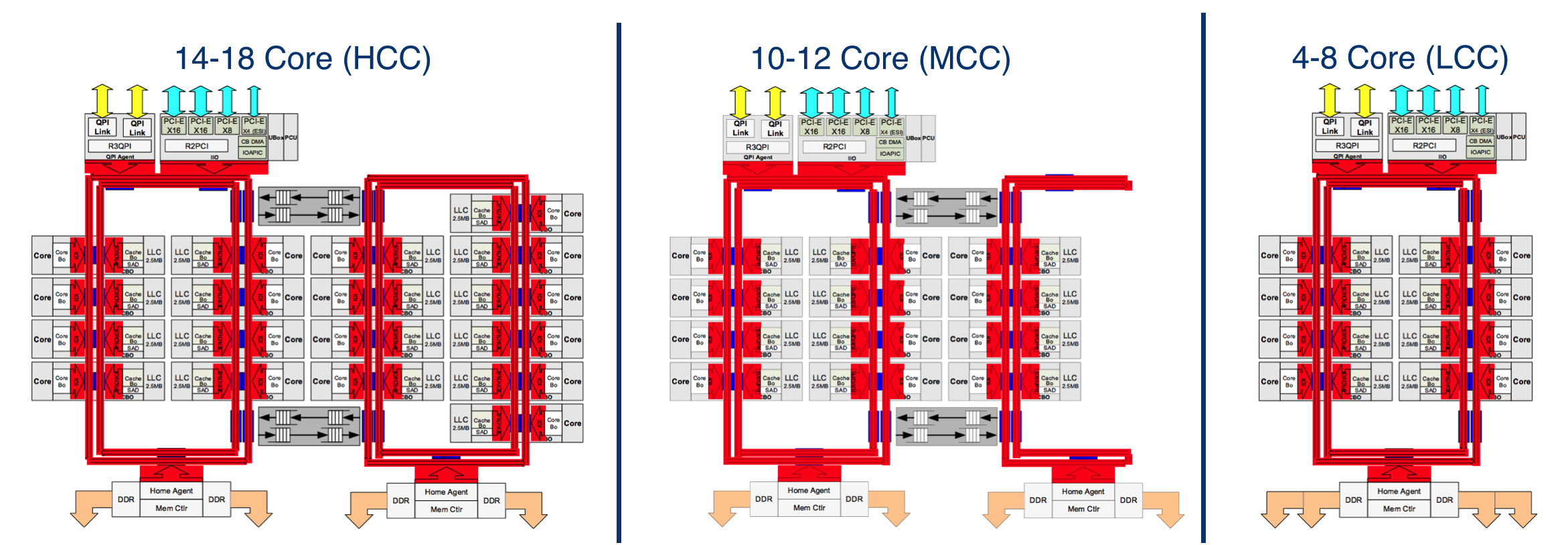
| Processor circuit | Number of rows | Number of Home Agent | Number of Cores | Power consumption | The number of transistors, billions | Crystal area, mm 2 |
| Hcc | 4 | 2 | 14 - 18 | 110 - 145 | 5.69 | 662 |
| Mcc | 3 | 2 | 6 - 12 | 65 - 160 | 3.84 | 492 |
| Lcc | 2 | 1 | 4 - 8 | 55 - 140 | 2.60 | 354 |
The first supports 4 to 8 cores. It consists of one double ring bus, two columns of cores and an agent for memory controllers. The last level cache in this configuration is less, and its delay time is lower.
The second configuration supports 10 - 12 cores and is a reduced version of the configuration, which we have already described above. In this configuration, the chip is equipped with two memory controller agents. The blue points on the diagram indicate where the data goes into the ring buses.
In all three processor circuits, the crystal configuration is asymmetrical: for example, an 18-core processor has 8 cores and 20 MB of the last level cache on one side, and 10 cores and 25 MB of cache on the other.
Kernel data and instructions are not stored in cache sections located next to them. Such a solution may not provide the minimum possible delay, but it avoids cache overflow. Data is stored on physical addresses, which provides uniform access to all cache cells of the last level. Transactions take the shortest route.
Each ring bus operates at its own frequency and voltage optimized for the current load. In case of increased load, the tires can be allocated additional power, which allows for a higher speed.
Improving instruction sets
Compared with the previous generation, the performance of new processors has increased significantly. This has been made possible thanks to the most extensive over the past three years improvement of the AVX 2.0 instruction set.
The bit depth of vector computing blocks in new processors has been increased from 128 to 256 bits. As a result, the performance of floating point computing has increased by 70 - 100%. The speed of many application operations has increased: for example, when calculating checksums for data deduplication and Thin Provisioning, the processor load is reduced by about half.
AVX 2.0 also includes an updated set of FMA instructions (fused-multiply-add, multiplication-addition with a single rounding). For code that performs sequential multiply-add operations, FMA halves the number of cycles. This innovation allows you to significantly increase the speed of high-performance applications (professional graphics, pattern recognition, etc.).
The new processor family has also improved the Intel Advanced Encryption Standard New Instructions (AES-NI) instruction set, which has almost doubled the encryption and decryption speed.
Energy efficiency
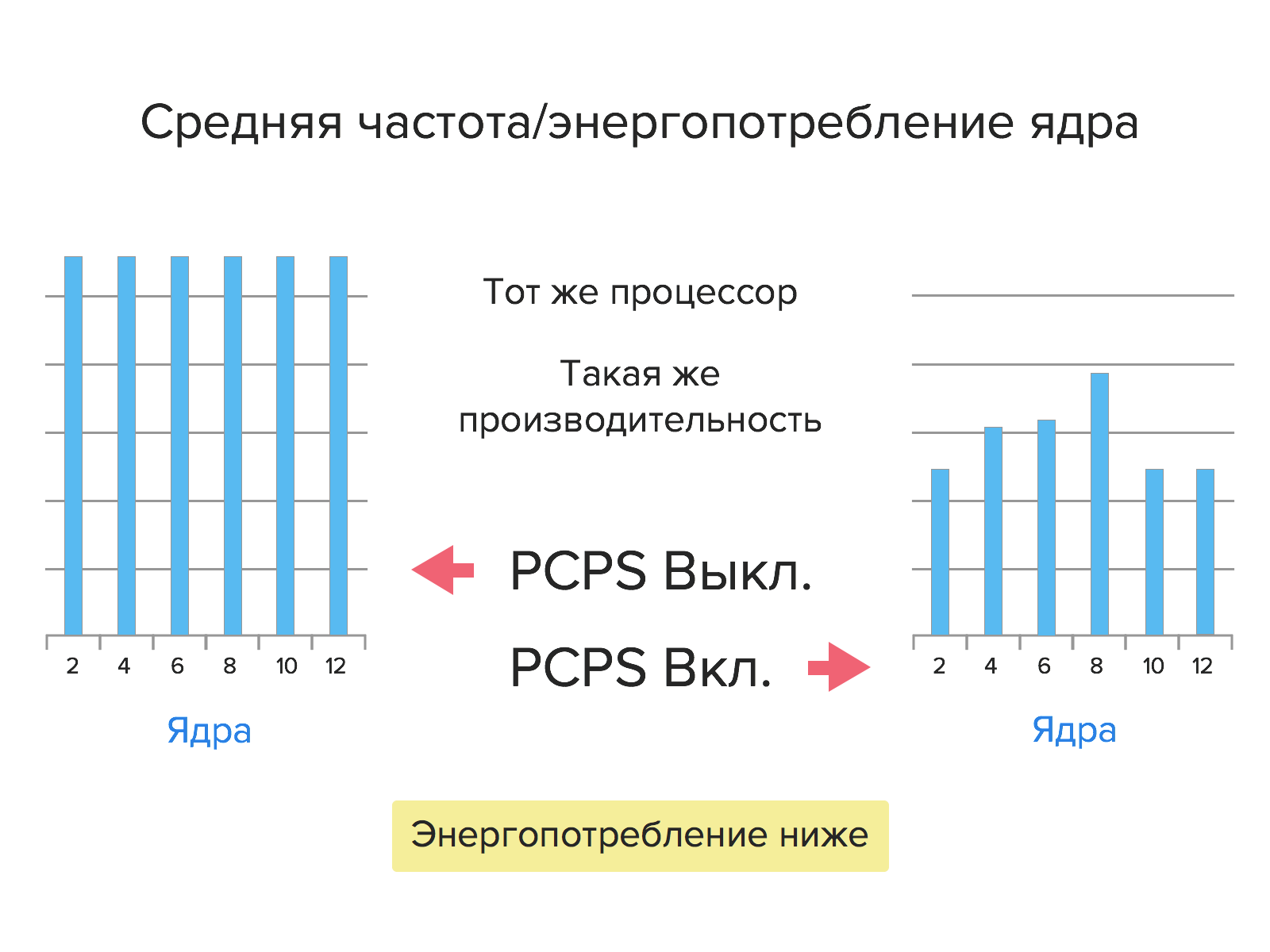
Compared to the previous generation, Intel Xeon E5v3 processors consume 36% less power.
This increase in energy efficiency was made possible by PCPS (Per-Core P-States) technology. Firstly, each core now operates at its own frequency with a voltage corresponding to the current load. Secondly, the cores of new processors can go into low power mode not only all together (as was the case with the previous generation processors), but also separately.
Virtualization
The number of cores in the Intel Xeon E5v3 processors increased, which made it possible to increase the density of virtualization (the number of VMs per server). In this regard, there is a need for improvements in the field of instructions for hardware virtualization. Such improvements have been implemented; they include the use of Cache Quality of Service Monitoring, Virtual Machine Control Structure Shadowing and Extended Page Accessed and Dirty Bits technologies, as well as improvements to Direct Data I / O technology.
Let us consider in more detail these technologies and their advantages.
Cache quality of service monitoring
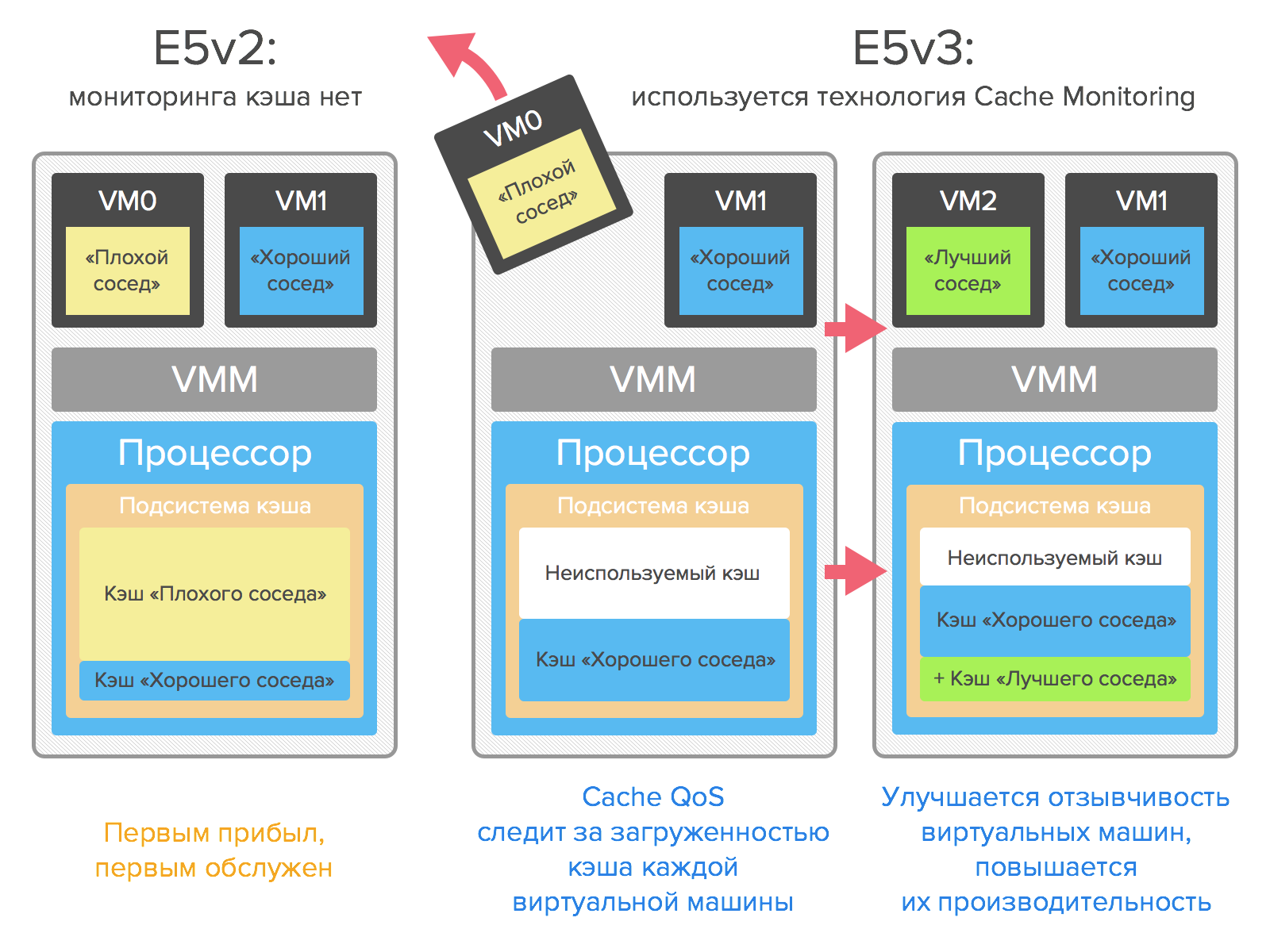
This technology allows real-time monitoring of cache loading at the kernel, thread, application or virtual machine level. Thanks to it, you can reduce the likelihood of crowding out data from the cache of one VM, improve the responsiveness of virtual machines and increase their performance.
Monitoring Cache QoS will help to identify “bad neighbors” consuming too large cache volumes in a virtual environment, as well as optimize the load in multi-user environments.
Virtual Machine Control Structure Shadowing
Using this technology, you can run a hypervisor in a hypervisor. It gives guest hypervisors access to the server hardware (under the control of the primary hypervisor). Thanks to this, you can run any guest software with a minimal drop in performance.
VMCS Shadowing technology can be used to test and debug hypervisors, operating systems and other programs that need direct access to VMCS (Virtual Machine Control Structure) and VMM (Virtual Machine Monitor).
Support for VMCS Shadowing is already implemented in KVM-3.1 and Xen-4.3 and higher.
Extended Pages Accessed and Dirty Bits
Migration of virtual machines is fraught with a number of problems, especially in the case of migration of actively running VMs. When migrating virtual machines, it is important that the actual data is transferred in memory.
EPT A / D Bits (Extended Pages Accessed and Dirty Bits) technology allows hypervisors to get more information about the state of VM memory pages using the Accessed and Dirty flags, which reduces the number of calls to the VMExit instruction during VM migration. Its use accelerates migration, and therefore reduces the downtime of virtual machines.
Improving Direct Data I / O Technology
One of the key innovations of the Intel E5 processor family was Direct Data I / O, which allows peripheral devices to direct I / O traffic directly to the processor’s cache. As a result of its use, the amount of data transferred to the system memory is reduced, power consumption is optimized and input / output delays are reduced.
In Intel Xeon E5v3 processors, this technology has been improved. With it, you can now configure the binding of LLC to the cores and lines of PCIe. This reduces memory and cache accesses during I / O virtualization, which further improves performance and reduces latency.
Detailed information on these technologies can also be found on the Intel Developer Blog .
DDR4
One of the key features of Intel Xeon E5v3 processors is support for the new DDR4 SDRAM.
An important difference between DDR4 and previous generations is the organization of memory chips: the number of banks is doubled to 16 (for technical details see, for example, here ). Switching between banks is faster; DDR4 chips open arbitrary strings twice as fast as DDR3.
An increase in the number of banks and related technological innovations, firstly, make it possible to create memory modules with increased capacity, and secondly, they contribute to increased productivity.
DDR4 memory is highly energy efficient: having higher performance compared to the previous generation, the new memory consumes 40% less energy.
Available configurations
We offer the following server configurations based on Intel Xeon E5v3 processor family:
| CPU | Memory | Disks | Price, rub / month |
| Xeon E5-1650v3 3.5 GHz | 64 GB DDR4 | 2 × 4 TB SATA | 10,000 |
| Xeon E5-1650v3 3.5 GHz | 64 GB DDR4 | 2 × 480 GB SSD | 12000 |
| 2 × Xeon E5-2630v3 2.4 GHz | 128 GB DDR4 | 2 × 480 GB SSD | 15500 |
| 2 × Xeon E5-2630v3 2.4 GHz | 64 GB DDR4 | 2 × 4 TB SATA, 2 × 480 GB SSD | 16000 |
| 2 × Xeon E5-2670v3 2.3 GHz | 256 GB DDR4 | 2 × 800 GB SSD | 30000 |
Servers are already available for order in St. Petersburg. In the very near future they can be ordered in Moscow. Also, it will soon be possible to build custom configuration servers based on the new Xeon E5v3 processors.
PS Servers of all previous configurations are now available for sale . Hurry up to rent dedicated servers on very favorable terms!
Readers who for one reason or another are not able to leave comments here are welcome to our blog .