MapReduce 2.0. What is modern digital elephant?

If you are ITchnik, then you can’t just take it and go to work on January 2 : review the third season of the psychic battle or the recording of the Gordon program on NTV (a matter of
It cannot be because other employees will definitely have gifts for you: the secretary has run out of coffee, the MP has deadlines, and the database administrator has
It turned out that the engineers at the Hadoop team also love to pamper each other with New Year's surprises.
2008
January 2. Lacking a detailed description of the emotional and psychological state of those participating in the events described below, I will immediately turn to the fact: the Map-Reduce 2.0 task has been set up for MAPREDUCE-279 . Leaving a joke about the number, I’ll note that before the 1st stable version of Hadoop there is just under 4 years.
During this time, the Hadoop project will evolve from a small innovative snowball launched in 2005 to a big snow
Below we will try to figure out what value the January task MAPREDUCE-279 played (and I'm sure will play in 2013) in the evolution of the Hadoop platform.
2011
In February 2011, Yahoo engineers delighted the world with the article “The Next Generation of Apache Hadoop MapReduce” [2]. In October 2011, the Apache Software Foundation published in its wiki-work entitled “Apache Hadoop NextGen MapReduce (YARN)” [1]. On December 27, the world saw the inscription on the Apache Software Foundation website:
... release 1.0.0 available. After six years of gestation, Hadoop reaches 1.0.0!and link the stable version of Hadoop v1.0.
2012
Hadoop 2.0.0-alpha became available for download at the end of May. In May, the book “Hadoop: The Definitive Guide, Third Edition” (by Tom White) was published, where YARN was given a significant amount. In early June, Tom White made a presentation of “MapReduce 2.0” ( video ) at the Chicago Hadoop User Group. In the same month, Cloudera announced the support for Hadoop 2.0.0 Alpha in its CDH4 product. A little later, Hortonworks also announced support for Hadoop 2.0 in its distributions.
On September 17, the Apache Software Foundation published that YARN and MapReduce v2 are available in Hadoop 0.23.3.
Below, we will look at the approaches to distributed computing in the classic Hadoop MapReduce and the new architecture, describe the techniques and components that implement the concepts of the new model, and compare the classical and 2.0 architectures.
1. Hadoop MapReduce Classic
Hadoop is a popular software framework for building distributed applications for massive parallel processing (MPP) data.
Hadoop includes the following components:
- HDFS - distributed file system;
- Hadoop MapReduce is a program model (framework) for performing distributed calculations for large amounts of data within the map / reduce paradigm.
The concepts embodied in the Hadoop MapReduce architecture and the HDFS structure caused a number of bottlenecks in the components themselves, including single points of failure. This ultimately determined the limitations of the Hadoop platform as a whole.
The latter include:
- Hadoop cluster scalability limitation : ~ 4K compute nodes; ~ 40K parallel tasks;
- Strong connectedness of the distributed computing framework and client libraries implementing the distributed algorithm. Consequently:
- Lack of support for an alternative software model for performing distributed computing: in Hadoop v1.0, only the map / reduce model is supported.
- The presence of single points of failure and, as a consequence, the impossibility of use in environments with high requirements for reliability;
- Version compatibility issues : the requirement for a one-time update of all computing nodes in the cluster when upgrading the Hadoop platform (installing a new version or service pack);
- Lack of support for work with updateable / streaming data.
The new Hadoop architecture aimed to remove many of the above limitations.
On the very architecture of Hadoop 2.0 and the limitations that it allowed to overcome, and let's talk below.
2. Hadoop MapReduce Next
Major changes have been made to the Hadoop MapReduce distributed computing component.
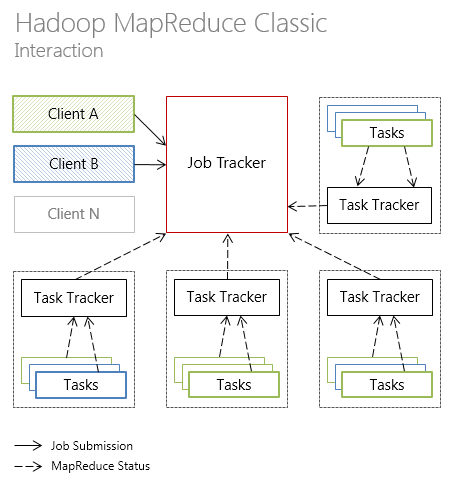
The classic Hadoop MapReduce was a single JobTracker process and an arbitrary number of TaskTracker processes .
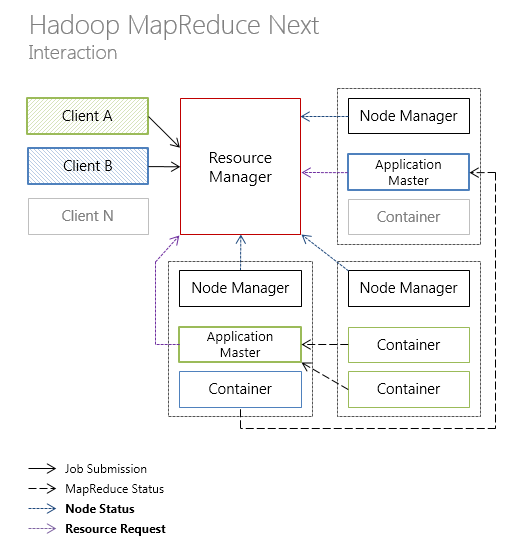
In the new Hadoop MapReduce architecture, JobTracker’s resource management and task life cycle planning / coordination functions were divided into 2 separate components:
- resources manager the ResourceManager ;
- ApplicationMaster scheduler and coordinator .
Consider each component in more detail.
ResourceManager
ResourceManager (RM) is a global resource manager whose task is to allocate the resources requested by applications and monitor the compute nodes on which these applications run.
ResourceManager, in turn, includes the following components:
- Scheduler - the scheduler responsible for the allocation of resources among the requested resources applications.
Scheduler is a “clean” scheduler: it does not monitor or track application status. - ApplicationsManager (AsM) is the component responsible for starting ApplicationMaster instances, as well as monitoring the nodes (containers) on which execution takes place and restarting the "dead" nodes.
It is worth noting that the Scheduler in the ResourceManager is a plugin component (pluggable). There are 3 types of Scheduler: FIFO scheduler (default), Capacity scheduler and Fair scheduler. In the Hadoop version 0.23, the first 2 types of schedulers are supported, the 3rd is not.
Resources are requested from RM for the abstract concept of Container , which will be discussed later, and which can be set such parameters as the required processor time, the amount of RAM, the required network bandwidth. For December 2012, only the “RAM” parameter is supported.
The introduction of RM makes it possible to treat cluster nodes as computational resources, which qualitatively enhances the utilization of cluster resources.
Applicationmaster
ApplicationMaster (AM) is the component responsible for planning the life cycle, coordinating and tracking the execution status of a distributed application. Each application has its own ApplicationMaster instance.
At this level, it is worth considering YARN.
YARN (Yet Another Resource Negotiator) is a software framework for running distributed applications (which the ApplicationMaster instance is). YARN provides the components and APIs needed to develop distributed applications of various types. The framework itself assumes responsibility for the allocation of resources in response to requests for resources from running applications and the responsibility for tracking the status of application execution.
The YARN model is more general (generic) than the model implemented in the classic Hadoop MapReduce.
Thanks to YARN on the Hadoop cluster, it is possible to run not only “map / reduce” applications, but also distributed applications created using: Open MPI, Spark, Apache HAMA, Apache Giraph, etc. It is possible to implement other distributed algorithms (here it is the power of the OOP!). Detailed instructions are described in the Apache Wiki.
In turn, MapReduce 2.0 (or MR2, or MRv2) is a framework for performing distributed computing within the map / reduce program model that lies above the YARN level.
The division of responsibility for resource management and application life-cycle planning / coordination between the components of the ResourceManager and ApplicationMaster made the Hadoop platform more distributed. That, in turn, had a positive impact on the scalability of the platform.
Nodemanager
NodeManager (NM) - an agent running on a compute node, whose duties include:
- tracking of used computing resources (CPU, RAM, network, etc.);
- sending reports on the resources used to the ResourceManager / Scheduler resource manager scheduler.
Interaction protocols
Control commands and status transfer to various components of the Hadoop platform are made through the following protocols:
- ClientRMProtocol - client interaction protocol with the ResourceManager for starting, checking the status and closing applications.
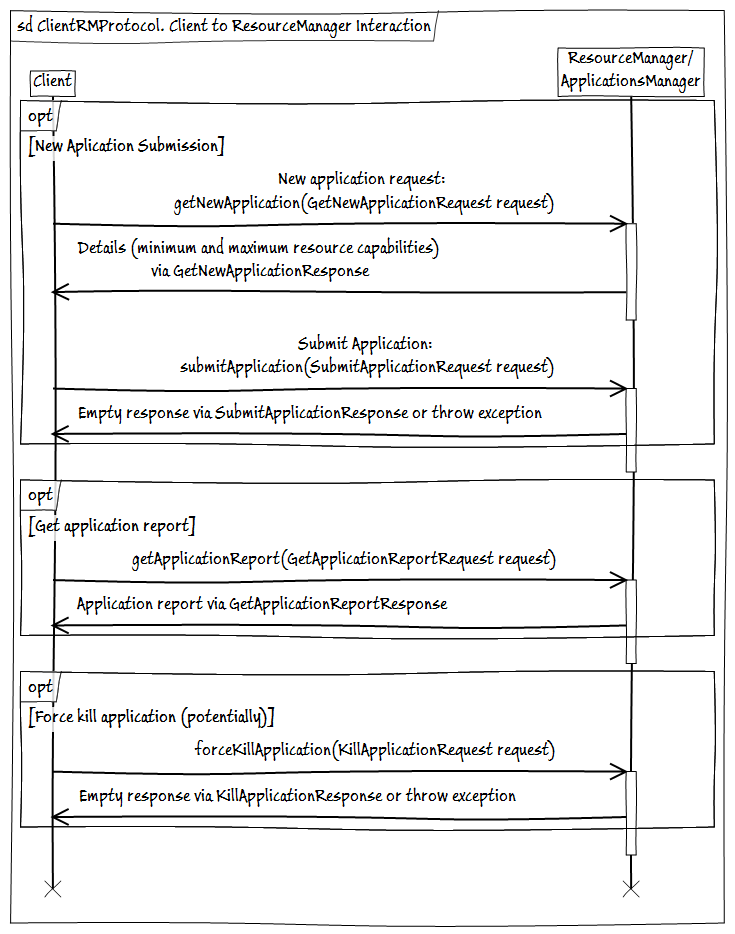
- AMRMProtocol is a protocol for communicating ApplicationMaster instances with a ResourceManager for subscribing / unsubscribing AM, sending a request and receiving resources from RM.
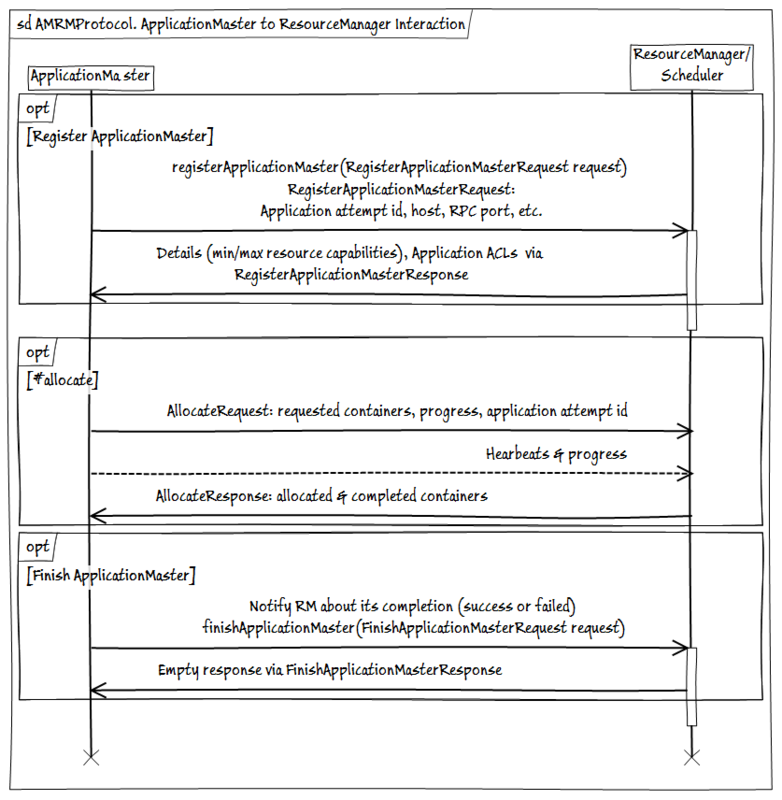
- ContainerManager - ApplicationMaster interaction protocol with NodeManager to start / stop and obtain the status of containers under NM control.

3. Hadoop MapReduce. Vis-à-vis
Part 1 of Hadoop MapReduce Classic gave an introduction to the Hadoop platform and describes the main limitations of the platform. Part 2 of Hadoop MapReduce Next described the concepts and components introduced into the new version of the Hadoop MapReduce distributed computing framework.
We will discuss how the YARN, MR2 concepts and components implementing these concepts changed the distributed computing architecture on the Hadoop platform, and how these changes helped (or not) get around the existing limitations of the platform.
- About terminology.
As further we will talk about the comparison of the classic and "2.0" versions of Hadoop MapReduce, in order to avoid:
- ambiguities associated with the discussed version, and / or
- endless updates of the version in question
- Hadoop MapReduce 1.0 - “classic” plain (unless otherwise noted) Hadoop MapReduce;
- Hadoop MapReduce 2.0 is YARN and MapReduce v2.0.
Architecture
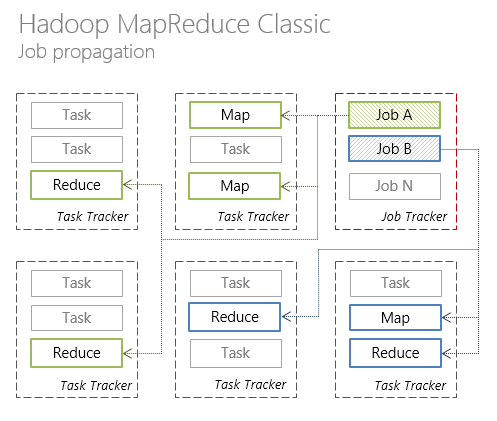
In Hadoop MapReduce 1.0, the cluster has a single JobTracker node that distributes tasks across multiple TaskTracker nodes that directly perform tasks.
In the new Hadoop MapReduce architecture, the responsibility for resource management and scheduling / coordination over the application lifecycle is divided between ResourceManager (per-cluster) and ApplicationMaster (per-application), respectively.
Each compute node is divided into an arbitrary number of Containers containing a predetermined number of resources: CPU, RAM, etc. Monitoring containers is conducted by NodeManager (per-node).
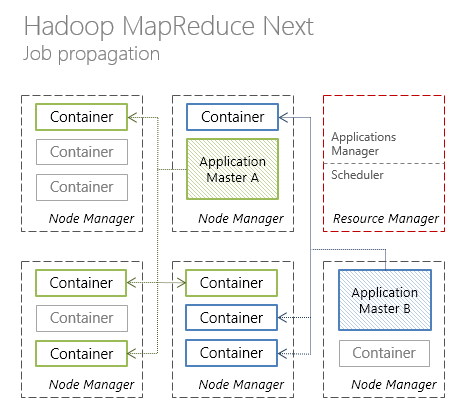
Below is an illustration of the interaction of the individual components of Hadoop MapReduce in the classic version of the architecture.
and YARN-like architecture (new types of communication between components are highlighted in bold).
Next, we consider how the new architecture of Hadoop MapReduce influenced such aspects of the platform as availability, scalability, and resource utilization.
Availability
In Hadoop MapReduce 1.0, a JobTracker crash causes JobTracker to restart with reading the status from special logs, which ultimately leads to cluster downtime.
In the new version of the accessibility solution, although they have not risen to a qualitatively new level, still things are no worse. Hadoop MapReduce 2.0 high availability task is solved in the following way: the state of the components ResourceManager and ApplicationMaster is saved and the system of automatic restart of the listed components is ensured in the event of a failure with loading the last successfully saved state.
For ResourceManager, Apache ZooKeeper is maintaining state. And if the resource manager fails, a new RM process is created with a state that was before the failure. Thus, the consequences of RM failure are reduced to the fact that all scheduled and running applications will be restarted.
ApplicationMaster uses its own checkpoint mechanism. During operation, AM maintains its state in HDFS. If AM becomes unavailable, then RM restarts it with a state from snapshot.
Scalability
Developers working with Hadoop MapReduce 1.0 have repeatedly pointed out that the limit of scalability of the Hadoop cluster lies in the area of 4K machines. The main reason for this limitation is that the JobTracker node spends a considerable amount of its resources on tasks related to the application life cycle. The latter can be attributed to tasks specific to a particular application, and not to the cluster as a whole.
The division of responsibility for tasks related to different levels between ResourceManager and ApplicationMaster was, perhaps, the main know-how of Hadoop MapReduce 2.0.
It is planned that Hadoop MapReduce 2.0 can work on clusters of up to 10K + compute nodes, which is a significant advance in comparison with the classic version of Hadoop MapReduce.
Recycling
Low utilization of resources due to the hard division of cluster resources into map- and reduce-slots is often also the object of criticism of the classical Hadoop MapReduce. The concept of slots in MapReduce 1.0 has been replaced by the concept of universal containers - a set of interchangeable isolated resources.
The introduction of the concept of “ Container ” in Hadoop MapReduce 2.0, in fact, added another feature to the Hadoop platform - multi - tenancy . Attitude to cluster nodes as computational resources will eliminate the negative effect of slots on resource utilization.
Connectedness
One of the architectural problems of Hadoop MapReduce 1.0 was the strong connectivity of 2, in fact, not interdependent systems: a framework for distributed computing and client libraries that implement a distributed algorithm.
This connectivity has led to the inability to run on an MPI Hadoop cluster or other alternative distributed map / reduce algorithms.
In the new architecture, the YARN distributed computing framework and the computing framework within the map / reduce software model based on the YARN-MR2 framework were selected.
MR2 is an application-specific framework provided by ApplicationMaster, while YARN is “represented” by the ResourceManager and NodeManager components and is completely independent of the specificity of the distributed algorithm.
Behind the scenes
There will not be a holistic picture, if not to mention 2 aspects:
1. The article considered only the distributed computing framework.
Beyond the scope of this article are changes related to the data warehouse. The most notable of these are the high availability of the HDFS name node and the HDFS name node federation.
2. The above will be implemented only in Hadoop v2.0 (an alfa version is available at the time of writing this article). So YARN and MR2 are already available in Hadoop v0.23, but without the support of high availability NameNode.
Separately, I note that at the June 2012 Chicago HUG conference, which I mentioned in the introduction, Tom White said that Hadoop 2.0 Alpha still has work related to performance, security, and ResourceManager.
Conclusion
The Hadoop project in 2010 was pleasantly surprised by the ideas , in 2011 - by the speed of distribution , in 2012 I was struck by the scale of the changes .
I will not waste your time on a “traditional” summary of what YARN and MR2 have changed in the Hadoop platform. This is no doubt a qualitative leap platform.
Now Hadoop looks like a de-facto industry standard in tasks related to Big Data. The future release of version 2.0 will give developers an open, fault-tolerant, superbly scalable, extensible tool for mass-parallel processing, not “fixated” solely on the map / reduce software model.
Sounds unbelievable. It is even more incredible that this is a very near reality. Only one thing remains - to be ready for this reality..
List of sources
[1] Apache Hadoop NextGen MapReduce (YARN) . Apache Software Foundation, 2011.
[2] Arun C Murthy. The Next Generation of Apache Hadoop MapReduce . Yahoo 2011.
[3] Ahmed Radwan. MapReduce 2.0 in Hadoop 0.23 . Cloudera, 2012.
[4] Tom White. Hadoop: The Definitive Guide, 3rd Edition. O'Reilly Media / Yahoo Press, 2012.
[5] Apache Hadoop Main 2.0.2-alpha API . Apache Software Foundation, 2012.
Postscript and other experiences of the author
* Cloudera allows you to download the CDH4 distribution (with YARN support) to run on a local machine in pseudo-distributed mode. Distribution and instructions .