Hash array mapped trie
Hash array mapped trie is an associative container that has the properties of hash tables and trie. The operations of inserting a key-value pair and searching by key are O (1) operations.
About trie on a habr already wrote .
Trie often stores strings, so there is a concept of the alphabet that elements can consist of. For optimization under x32, the alphabet size is limited to 32 (0 - 31).
Let's see what an array mapped trie looks like, it's AMT (taken from [1]):

AMT consists of a node and several segments connecting our node and other nodes. Each segment represents one of the possible characters of the alphabet.
A 32-bit structure (bitmap) is stored in the node, each bit of the structure reflects the state of one of 32 segments (0 - no, 1 - yes). Also in the node is a table that stores pointers to subtrees or the last characters in a given substring (leaves). The pointers in the table are stored in order, and each of the pointers corresponds to bit = 1 in the bit structure.
Example: to find the character 's', you need to go through the bit structure to the corresponding bit. While we go along the structure, we count bits = 1 (cocked bits). Suppose we counted 5 cocked bits, and the bit corresponding to 's' turned out to be the 6th cocked bit. Accordingly, we need the 6th pointer in the table of this node. If the bit turned out to be unset (= 0), then this symbol is absent.
Now let's move on to HAMT . Instead of the alphabet, the high bits of the hash are used. Here is what HAMT looks like (taken from [1]):
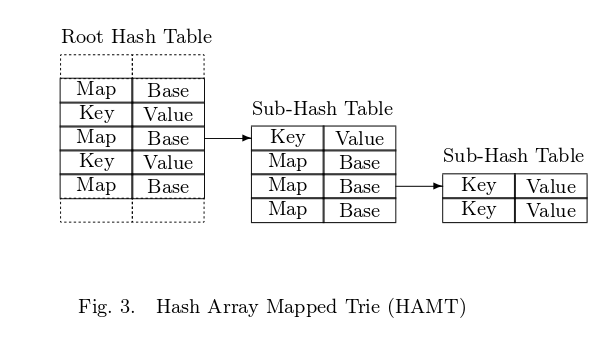
HAMT consists of a main hash of a table of size 2 ^ t, where usually t> = 5. Each element of the main table:
1. either the root node of the subtable tree with size 32
2. Or just a key-value pair
The choice of hash function depends on your data set. It is advisable to choose a hash function that gives the minimum number of collisions (more about collisions in [2]).
1. Generate a 32-bit hash for the key.
2. From the resulting hash we take t high bits (note: we take t high bits only for the first time, the rest - 5 bits each) and use them as an index in the table. There are 3 possible options:
a) there is nothing in the cell with such an index - there is no such key in the table;
b) there is one key / value pair in the cell. If the key matches - found an element, does not match - did not find;
c) a 32-bit bitmap and a table with pointers are stored in the cell. In this case, take the next 5 bits of the hash and use them again as an index in the bitmap. If the bit is not cocked, then there is no such key; if it is cocked, then we count all the cocked bits from the beginning to the current (as in AMT). Thus, we got the number of the required pointer in the table. We follow the pointer and repeat the algorithm.
Often, only a few iterations of this algorithm are needed (although this depends on the size of the tree). The key is compared only once - when we get into situation b. The absence of a key is detected too early.
Повторяем шаги из алгоритам вставки, пока не произойдет одна из 3 ситуаций:
a) в ячейке с таким индексом ничего нет;
b) в ячейке хранится 32-битный bitmap и таблица с указателями;
В обоих случаях алгоритам простой: если вставка происходит в главную таблицу — то просто вставляем пару ключ / значение. Если же вставка происходит в подтаблицу, то взводим соответствующий бит, аллоцируем новую таблицу указателей, копируем в неё указатели из старой таблицы и новый указатель на нашу пару, а старую таблицу удаляем.
В итоге у нас взведен бит соответствующей ячейки, в таблице указателей все старые указатели, а также в соответствующей ячейке новый указатель.
c) a collision occurred - that is, some part of the two hashes coincided. The solution is simple - create a new subtable, calculate the hash from the existing key and use the next 5 bits to find the desired cell. We cock a bit in this cell, insert a pointer to an existing key / value pair in the table of pointers, return to the inserted pair, take the next 5 bits, and look for the desired cell. We repeat this step with the creation of a new subtable until the collision disappears.
With each such step, the probability of collision is reduced by 32 times (the size of the pointer table and bitmap).
Sometimes we get a complete collision - all 32 bits of the hashes of two different keys are the same. Then we take the following hash function and hash it with two conflicting keys. As a result, when we look for an element by key, we will go through all the bits of the primary hash, see that we did not come to the sheet, but to the subtable, and calculate the new key hash using the second function.
In general, this is not the only way to resolve conflicts; in different implementations there are others. The author in his work suggests using the same hash function, just after a collision, give it the key and the level of the tree in which we are in this step of the algorithm (0 - the root table, etc.). If it is critical for the application that the time of the insert operation be limited from above (theoretically we can take two such keys that their hashes will coincide after several calls to the rehashing function, which means that the insert operation will last a very long time), then instead of rehashing the matching keys you can use the keys themselves.
We need pools from 1 to 32 elements (for tables of various sizes). We select memory blocks and divide them into the corresponding tables. In the process, fragmentation will gradually increase. In order to regain memory, it is necessary to defragment. You can set a limit on the amount of fragmented memory in percent, check it when an element is inserted, and if the limit is exceeded, defragment it. The defragmentation operation can be implemented as an O (1) operation.
At some point in time, the tree will grow so much that increasing the size of the root table will give a noticeable increase in speed. Each subtable has 32 elements, so the most logical change is from 2 ^ t to 2 ^ (t + 5). As the size increases, all the sub-tables of the first level fall into the root table. Moreover, rehashing is only necessary if we have tree leaves in the root table (we need to re-calculate the hash to determine the new position of the element). In other cases, just copy the elements from the subtable to the root table.
It is possible not to immediately copy all the sub-tables to the root table, but gradually. In this case, the transfer index is stored. All elements below the index are copied to the new table, and the index gradually moves through the old table. During the search, the first t bits of the hash are compared with the carry index - if the hash is greater, then the search is sent to the old table, otherwise to the new one. The insertion algorithm should also take into account the carry index.
When should you increase the root table? When the size of the new table will occupy 1 / f of the whole tree. The parameter f must be selected based on the specific situation.
The amount of memory depends on the transfer index. The author in his work cited a table showing this dependence (taken from [1])
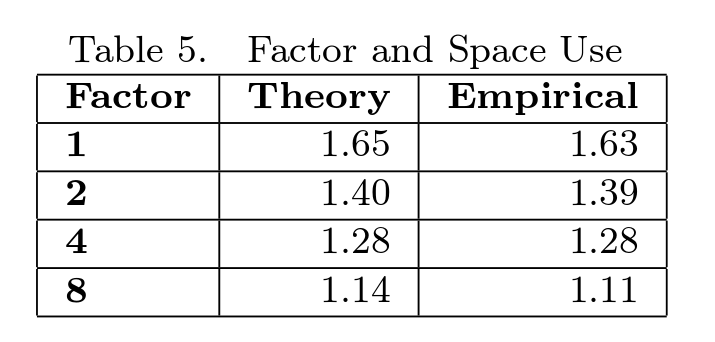
That is, if the transfer index = N / 4, where N is the number of key-value pairs inserted in the tree, then the occupied memory is proportional to 1.28 * N.
Two situations can arise during deletion:
a) we delete an element in the subtable with the number of elements greater than 2. Then we need to move all the other elements to a smaller subtable, and mark the current one empty.
b) delete the element in the subtable with the number of elements equal to 2. In this situation, the remaining element is simply transferred to the subtable one level higher, and the current one is marked empty.
I lost the link to the implementation from the author in C ((Whoever finds - write in the comment.
Github.com/yasm/yasm/blob/master/libyasm/hamt.c - an example of implementation in C. Links to examples of implementation in other languages can be found at 3].
[1] article from the author of the algorithm
[2] article on hash collisions on Wikipedia
[3] article on HAMT on Wikipedia
[4] good question on SO
[5] short introductory course on HAMT
Comments and inaccuracies write in comments, spelling errors and lost send punctuation marks in PM.
About trie on a habr already wrote .
Array mapped trie structure
Trie often stores strings, so there is a concept of the alphabet that elements can consist of. For optimization under x32, the alphabet size is limited to 32 (0 - 31).
Let's see what an array mapped trie looks like, it's AMT (taken from [1]):
AMT consists of a node and several segments connecting our node and other nodes. Each segment represents one of the possible characters of the alphabet.
A 32-bit structure (bitmap) is stored in the node, each bit of the structure reflects the state of one of 32 segments (0 - no, 1 - yes). Also in the node is a table that stores pointers to subtrees or the last characters in a given substring (leaves). The pointers in the table are stored in order, and each of the pointers corresponds to bit = 1 in the bit structure.
Example: to find the character 's', you need to go through the bit structure to the corresponding bit. While we go along the structure, we count bits = 1 (cocked bits). Suppose we counted 5 cocked bits, and the bit corresponding to 's' turned out to be the 6th cocked bit. Accordingly, we need the 6th pointer in the table of this node. If the bit turned out to be unset (= 0), then this symbol is absent.
Hash array mapped trie structure
Now let's move on to HAMT . Instead of the alphabet, the high bits of the hash are used. Here is what HAMT looks like (taken from [1]):
HAMT consists of a main hash of a table of size 2 ^ t, where usually t> = 5. Each element of the main table:
1. either the root node of the subtable tree with size 32
Index Node:
int bitmap (32 bits)
Node*[] table (max length of 32)
2. Or just a key-value pair
Key Value Node:
K key
V value
The choice of hash function depends on your data set. It is advisable to choose a hash function that gives the minimum number of collisions (more about collisions in [2]).
Element search
1. Generate a 32-bit hash for the key.
2. From the resulting hash we take t high bits (note: we take t high bits only for the first time, the rest - 5 bits each) and use them as an index in the table. There are 3 possible options:
a) there is nothing in the cell with such an index - there is no such key in the table;
b) there is one key / value pair in the cell. If the key matches - found an element, does not match - did not find;
c) a 32-bit bitmap and a table with pointers are stored in the cell. In this case, take the next 5 bits of the hash and use them again as an index in the bitmap. If the bit is not cocked, then there is no such key; if it is cocked, then we count all the cocked bits from the beginning to the current (as in AMT). Thus, we got the number of the required pointer in the table. We follow the pointer and repeat the algorithm.
Often, only a few iterations of this algorithm are needed (although this depends on the size of the tree). The key is compared only once - when we get into situation b. The absence of a key is detected too early.
Insert item
Повторяем шаги из алгоритам вставки, пока не произойдет одна из 3 ситуаций:
a) в ячейке с таким индексом ничего нет;
b) в ячейке хранится 32-битный bitmap и таблица с указателями;
В обоих случаях алгоритам простой: если вставка происходит в главную таблицу — то просто вставляем пару ключ / значение. Если же вставка происходит в подтаблицу, то взводим соответствующий бит, аллоцируем новую таблицу указателей, копируем в неё указатели из старой таблицы и новый указатель на нашу пару, а старую таблицу удаляем.
В итоге у нас взведен бит соответствующей ячейки, в таблице указателей все старые указатели, а также в соответствующей ячейке новый указатель.
c) a collision occurred - that is, some part of the two hashes coincided. The solution is simple - create a new subtable, calculate the hash from the existing key and use the next 5 bits to find the desired cell. We cock a bit in this cell, insert a pointer to an existing key / value pair in the table of pointers, return to the inserted pair, take the next 5 bits, and look for the desired cell. We repeat this step with the creation of a new subtable until the collision disappears.
With each such step, the probability of collision is reduced by 32 times (the size of the pointer table and bitmap).
Sometimes we get a complete collision - all 32 bits of the hashes of two different keys are the same. Then we take the following hash function and hash it with two conflicting keys. As a result, when we look for an element by key, we will go through all the bits of the primary hash, see that we did not come to the sheet, but to the subtable, and calculate the new key hash using the second function.
In general, this is not the only way to resolve conflicts; in different implementations there are others. The author in his work suggests using the same hash function, just after a collision, give it the key and the level of the tree in which we are in this step of the algorithm (0 - the root table, etc.). If it is critical for the application that the time of the insert operation be limited from above (theoretically we can take two such keys that their hashes will coincide after several calls to the rehashing function, which means that the insert operation will last a very long time), then instead of rehashing the matching keys you can use the keys themselves.
Memory allocation
We need pools from 1 to 32 elements (for tables of various sizes). We select memory blocks and divide them into the corresponding tables. In the process, fragmentation will gradually increase. In order to regain memory, it is necessary to defragment. You can set a limit on the amount of fragmented memory in percent, check it when an element is inserted, and if the limit is exceeded, defragment it. The defragmentation operation can be implemented as an O (1) operation.
Resize the root table
At some point in time, the tree will grow so much that increasing the size of the root table will give a noticeable increase in speed. Each subtable has 32 elements, so the most logical change is from 2 ^ t to 2 ^ (t + 5). As the size increases, all the sub-tables of the first level fall into the root table. Moreover, rehashing is only necessary if we have tree leaves in the root table (we need to re-calculate the hash to determine the new position of the element). In other cases, just copy the elements from the subtable to the root table.
It is possible not to immediately copy all the sub-tables to the root table, but gradually. In this case, the transfer index is stored. All elements below the index are copied to the new table, and the index gradually moves through the old table. During the search, the first t bits of the hash are compared with the carry index - if the hash is greater, then the search is sent to the old table, otherwise to the new one. The insertion algorithm should also take into account the carry index.
When should you increase the root table? When the size of the new table will occupy 1 / f of the whole tree. The parameter f must be selected based on the specific situation.
Amount of required memory
The amount of memory depends on the transfer index. The author in his work cited a table showing this dependence (taken from [1])
That is, if the transfer index = N / 4, where N is the number of key-value pairs inserted in the tree, then the occupied memory is proportional to 1.28 * N.
Delete item
Two situations can arise during deletion:
a) we delete an element in the subtable with the number of elements greater than 2. Then we need to move all the other elements to a smaller subtable, and mark the current one empty.
b) delete the element in the subtable with the number of elements equal to 2. In this situation, the remaining element is simply transferred to the subtable one level higher, and the current one is marked empty.
Source
I lost the link to the implementation from the author in C ((Whoever finds - write in the comment.
Github.com/yasm/yasm/blob/master/libyasm/hamt.c - an example of implementation in C. Links to examples of implementation in other languages can be found at 3].
References
[1] article from the author of the algorithm
[2] article on hash collisions on Wikipedia
[3] article on HAMT on Wikipedia
[4] good question on SO
[5] short introductory course on HAMT
Comments and inaccuracies write in comments, spelling errors and lost send punctuation marks in PM.