Recognizing it is impossible to leave a picture, or something about complex cases of optical text recognition
This post was prompted by an interview that our European office gave to a computer magazine. It was about ABBYYFineReader and recognition technologies. Among the questions was something like this:
What were the main challenges to be overcome when developing the software? Were there any particularly knotty problems?
In response, I would like to give out a service tirade about the fact that the images are very different, the photos are blurry, the resolution is low, the paper is dirty, the letters are fanciful ... In general, without even knowing anything or almost nothing about our technologies, we can say something plausible.
And there is reason to think. Still, from the point of view of the complexity of the tasks, it’s not so interesting - low image quality and decorative fonts. We could say roughly the same thing five years ago, and ten, and twenty. Yes, undoubtedly, there is progress - and for most of the versions, the famous browser and our old friend Sergei Golubitsky found exactly those pictures that were at the “forefront” of our technologies - so that their new version of FineReader would process almost perfectly, while the old one "Stumbled."
But to talk about what difficulties we still face, it is worth resorting to a small metaphor. Here are the difficulties you have to solve the following problem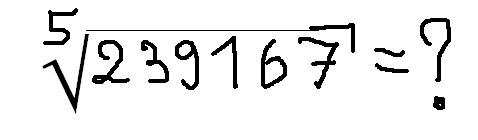
Hmm ... Most likely, most normal people will think that it is not so easy to extract the fifth degree roots. And if you ask “what difficulties do you have with solving this problem”, I’d like to tell you how to extract fifth-degree roots by expanding the number in a row and using vector operations ... But for “artificial intelligence”, extracting the root will be almost the easiest of its actions . The real difficulties will be different:
You may notice that in this example, the simpler the part of the task for a person, the more difficult it is for “artificial intelligence”. You can’t insert it into marketing materials or say in an interview ... "We have become less mistaken in parsing the formula" - "Gee-gee-gee, every fool can figure out the formula, you are doing nonsense."
And with the last paragraph there is a special catch. How to understand what should be done here? Who can promise that we will have to solve a similar problem at least once?
We have just come to the connection of metaphor and recognition tasks. The very phrase “recognition task” is a trap. Because when the task of recognizing something is already set, then it is a well-formulated question. And as we know , asking the right question is already an essential part of solving the problem.
As an example, let us cite the problem of correcting skew in photographs of text. At first glance, it does not look very complicated. We need to find what seems to us like lines of text, determine the angle of inclination, rotate the image - that’s all.

The trouble is that often there are several directions of text strings in one image. Which one is most important for the task director? In the latest versions of FineReader, the skew correction algorithm estimates how many directions of text lines can be selected, which of them is the most informative, and rotates the document so that the recognizer can read the "main" text. Unfortunately, sometimes he is “basic” not in terms of the questioner.
But in addition to skewing the image, there may be promising distortions, and then the problem cannot be solved with one turn. Photographs of two-page documents, for example, passports, have perspective distortions for each page. Curved lines on a magazine spread can occur both as a result of curvature of the sheet, and because of the "artistic" layout. Do I need to unbend them in the latter case and try to recognize? We can’t do without more complex document models, and in order to determine which one is suitable for the image, we need an appropriate classifier. We have already learned to deal with promising distortions, and with the remaining cases there is still a long way to perfection.
Next, we began to learn to segment the page. Select columns of text, pictures, tables ... How to distinguish text from pictures? Yes, there is nothing easier at our service Over9000 articles on this topic. We implemented it, everything is fine, we start it and we see the following picture:

In earlier versions of FineReader, our smart text classifier happily informed us that there was a bunch of well-organized text, and the table analyzer joyfully painted a very well-segmented table on it ... But to the person who I translated the textbook on databases into electronic format, it seems that this is not necessary at all: in this case we just need an example of a MS Access screenshot, and no one was going to recognize the table and somehow use the data from it. In the latest versions, we taught FineReader not to touch the contents of the screenshot and leave it as a picture.
Or such a surprise.
Clear business, before us is the text. Several blocks of text. But even a not very attentive reader may notice that there is something else.
In a good way, of course, this diagram should be parsed, the whole text recognized, and the frames drawn with vector commands. But this is bad luck, we don’t know in advance in which format it will be written and which commands will be available to us. Therefore, it is often wise to save this diagram as a picture. Yes, text, yes, like a picture. Artificial intelligence came in complete confusion, spat on these people and went off to routinely calculate the roots of the fifth degree.
The question is, and what to do about it?
What matters here is not even the answer to the previous question. Even if we understand him, we will ask ourselves another question:
And how often will it be necessary to solve such problems? Yes, the question is the same as in the example with the formula. And the answer is not always simple.
It turned out for us that among the problems with page segmentation, the proportion of those caused by our inadequate perception of the screenshot and diagram is quite large. Therefore, in the latest versions we “explained” to our engine that such objects happen, how they are arranged and how they differ from tables, blocks of text and just pictures. But if we thought that the problem was rare and “exotic,” we probably wouldn’t do anything - what would have caused fury among those who process pages with a large number of screenshots and diagrams.
Think only with unusual objects such problems? Nothing of the kind - in the same segmentation there are examples with text only. Say, most of the currently popular page segmentation algorithms (the question immediately is — would it be interesting if we write a short review on them?) They say that if there are two groups of texts at a respectful distance from each other, then they should appear in different blocks. Logically, damn it - do not mix two columns into one block. “Please, welcome,” the universe tells us:

“Well ...”, the developer says, “we make sure that the list numbers do not fall off the list ... Say, we will try to attach columns of the same numbers to the normal text.” “Ah well done!” - says the universe:

Here we will no longer be able to stick numbers (line numbers) to the text without breaking its connectivity and the possibility of further use - that is why the user launched our program. But nothing, spitting on their hands, in the next version coped with this.
Why is this all? It seems that one of the challenges for us, the creators of the recognition system, is the variability and, as a result, the incomplete formulation of the tasks before us. Moreover, we can assume that this is one of the important differences between artificial intelligence and natural intelligence. Because the incomplete task is a familiar environment for the natural mind and a curse for the scientist and engineer. Returning to the recognition system, one of the directions of development is just a more thorough and verified formulation of the problem, and most of the subtasks have already been solved long ago or are not particularly difficult. And the only question for us can be what kind of tasks are currently needed by our users. It so happened that this is not a “feature of the program”, but the development of technology.
(together with logicview )
What were the main challenges to be overcome when developing the software? Were there any particularly knotty problems?
In response, I would like to give out a service tirade about the fact that the images are very different, the photos are blurry, the resolution is low, the paper is dirty, the letters are fanciful ... In general, without even knowing anything or almost nothing about our technologies, we can say something plausible.
And there is reason to think. Still, from the point of view of the complexity of the tasks, it’s not so interesting - low image quality and decorative fonts. We could say roughly the same thing five years ago, and ten, and twenty. Yes, undoubtedly, there is progress - and for most of the versions, the famous browser and our old friend Sergei Golubitsky found exactly those pictures that were at the “forefront” of our technologies - so that their new version of FineReader would process almost perfectly, while the old one "Stumbled."
But to talk about what difficulties we still face, it is worth resorting to a small metaphor. Here are the difficulties you have to solve the following problem
Hmm ... Most likely, most normal people will think that it is not so easy to extract the fifth degree roots. And if you ask “what difficulties do you have with solving this problem”, I’d like to tell you how to extract fifth-degree roots by expanding the number in a row and using vector operations ... But for “artificial intelligence”, extracting the root will be almost the easiest of its actions . The real difficulties will be different:
- Recognize handwritten numbers
- Parse and decompose the formula
- In general, somehow guess that you need to do this
You may notice that in this example, the simpler the part of the task for a person, the more difficult it is for “artificial intelligence”. You can’t insert it into marketing materials or say in an interview ... "We have become less mistaken in parsing the formula" - "Gee-gee-gee, every fool can figure out the formula, you are doing nonsense."
And with the last paragraph there is a special catch. How to understand what should be done here? Who can promise that we will have to solve a similar problem at least once?
We have just come to the connection of metaphor and recognition tasks. The very phrase “recognition task” is a trap. Because when the task of recognizing something is already set, then it is a well-formulated question. And as we know , asking the right question is already an essential part of solving the problem.
As an example, let us cite the problem of correcting skew in photographs of text. At first glance, it does not look very complicated. We need to find what seems to us like lines of text, determine the angle of inclination, rotate the image - that’s all.
The trouble is that often there are several directions of text strings in one image. Which one is most important for the task director? In the latest versions of FineReader, the skew correction algorithm estimates how many directions of text lines can be selected, which of them is the most informative, and rotates the document so that the recognizer can read the "main" text. Unfortunately, sometimes he is “basic” not in terms of the questioner.
But in addition to skewing the image, there may be promising distortions, and then the problem cannot be solved with one turn. Photographs of two-page documents, for example, passports, have perspective distortions for each page. Curved lines on a magazine spread can occur both as a result of curvature of the sheet, and because of the "artistic" layout. Do I need to unbend them in the latter case and try to recognize? We can’t do without more complex document models, and in order to determine which one is suitable for the image, we need an appropriate classifier. We have already learned to deal with promising distortions, and with the remaining cases there is still a long way to perfection.
Next, we began to learn to segment the page. Select columns of text, pictures, tables ... How to distinguish text from pictures? Yes, there is nothing easier at our service Over9000 articles on this topic. We implemented it, everything is fine, we start it and we see the following picture:
In earlier versions of FineReader, our smart text classifier happily informed us that there was a bunch of well-organized text, and the table analyzer joyfully painted a very well-segmented table on it ... But to the person who I translated the textbook on databases into electronic format, it seems that this is not necessary at all: in this case we just need an example of a MS Access screenshot, and no one was going to recognize the table and somehow use the data from it. In the latest versions, we taught FineReader not to touch the contents of the screenshot and leave it as a picture.
Or such a surprise.
Clear business, before us is the text. Several blocks of text. But even a not very attentive reader may notice that there is something else.
In a good way, of course, this diagram should be parsed, the whole text recognized, and the frames drawn with vector commands. But this is bad luck, we don’t know in advance in which format it will be written and which commands will be available to us. Therefore, it is often wise to save this diagram as a picture. Yes, text, yes, like a picture. Artificial intelligence came in complete confusion, spat on these people and went off to routinely calculate the roots of the fifth degree.
The question is, and what to do about it?
What matters here is not even the answer to the previous question. Even if we understand him, we will ask ourselves another question:
And how often will it be necessary to solve such problems? Yes, the question is the same as in the example with the formula. And the answer is not always simple.
It turned out for us that among the problems with page segmentation, the proportion of those caused by our inadequate perception of the screenshot and diagram is quite large. Therefore, in the latest versions we “explained” to our engine that such objects happen, how they are arranged and how they differ from tables, blocks of text and just pictures. But if we thought that the problem was rare and “exotic,” we probably wouldn’t do anything - what would have caused fury among those who process pages with a large number of screenshots and diagrams.
Think only with unusual objects such problems? Nothing of the kind - in the same segmentation there are examples with text only. Say, most of the currently popular page segmentation algorithms (the question immediately is — would it be interesting if we write a short review on them?) They say that if there are two groups of texts at a respectful distance from each other, then they should appear in different blocks. Logically, damn it - do not mix two columns into one block. “Please, welcome,” the universe tells us:
“Well ...”, the developer says, “we make sure that the list numbers do not fall off the list ... Say, we will try to attach columns of the same numbers to the normal text.” “Ah well done!” - says the universe:
Here we will no longer be able to stick numbers (line numbers) to the text without breaking its connectivity and the possibility of further use - that is why the user launched our program. But nothing, spitting on their hands, in the next version coped with this.
Why is this all? It seems that one of the challenges for us, the creators of the recognition system, is the variability and, as a result, the incomplete formulation of the tasks before us. Moreover, we can assume that this is one of the important differences between artificial intelligence and natural intelligence. Because the incomplete task is a familiar environment for the natural mind and a curse for the scientist and engineer. Returning to the recognition system, one of the directions of development is just a more thorough and verified formulation of the problem, and most of the subtasks have already been solved long ago or are not particularly difficult. And the only question for us can be what kind of tasks are currently needed by our users. It so happened that this is not a “feature of the program”, but the development of technology.
(together with logicview )