Lemmatization in Excel, or “Recognition Robot 3.0”
Whoever worked with online advertising does not laugh at the circus that search engines sometimes give unexpected answers to requests or throw up completely different ads that may be interesting. In the latter case, the root of the problem often lies in the set of keywords that the advertiser uses in their campaigns. Thoughtless automation of the selection of keywords leads to sad consequences, among which the most depressing are empty impressions and clicks. Realweb Excel inventor and innovator Dmitry Tumaikin was puzzled by this problem and created another robot file, which he is happy to distribute to the world and Habr. We again pass the word to the author.

“In my previous article, we talked about clustering large semantic kernels using macros and formulas in MS Excel. This time we’ll talk about even more interesting things - word forms, lemmatization, Yandex, Google, Zalizniak’s dictionary, and again about Excel - its limitations, methods to bypass them, and incredible binary search speeds. The article, like the previous one, will be of interest to contextual advertising specialists and SEO specialists.
As you know, the key difference between Yandex search algorithms and Google search is the support of the morphology of the Russian language. That means: one of the greatest amenities is that in Yandex.Direct it is enough to specify one word form as a negative keyword (any), and the ad will not be displayed for any of all its word forms. He put the word “free” in the negative keywords - and there will be no impressions for the words “free”, “free”, “free”, “free”, etc. Conveniently? Of course!
However, not all so simple. More than one article was written on the topic of the oddities of Yandex morphology, including posts on the Habré itself, and I have repeatedly come across them in the course of my work. Disputes continue to this day, but I think this algorithm, despite everything, can be considered an advantage over Google logic.
The strange thing is that if the group of all word forms, say, a verb or an adjective, contains a homonym with a group of word forms of a noun, then Yandex actually “glues” them into a single set of word forms, all of which will display your ads.
Here is a good example, forgive me found :
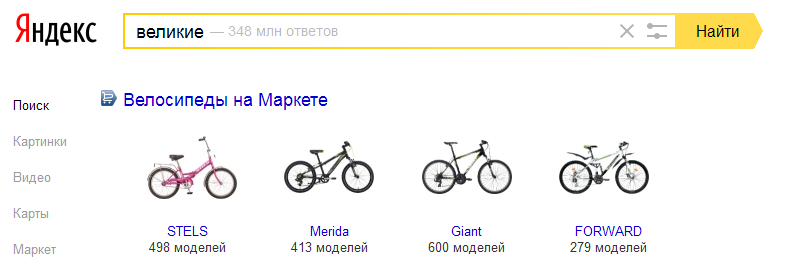
As everyone knows, the short form of the adjective "great", "led and to" is a homonym of the word "in th face", which, in turn - a synonym for the word "bicycle". At the very "in e face of" word forms "great", of course not, so show it on this request obviously wrong. In the language of linguists, Yandex mixed up paradigms.
The situation in natural output is much better, perhaps the algorithms there are more complex and optimized. Or maybe this is due to higher competition, because SEO is shareware (if the state has its own webmaster), and there are an order of magnitude fewer hunters to pay for each click in Yandex.Direct, despite the positive trends in contextual advertising. Maybe the VCG auction will fix everything? Wait and see.
However, a corporation of goodness has its own quirks. Googlespeaks Russian badlypractically does not recognize word forms. Unlike Yandex.Direct, you’ll need to exclude all negative keyword word forms from AdWords (which is a nuisance in itself). At the same time, the number of elements to be excluded at the level of one campaign according to the internal restrictions of the system is no more than 5,000, and in total for all campaigns in the account - no more than 1 million. It would seem a lot, and should be enough, but I am sure the owners of large advertising accounts it won’t seem so.
In general, the conclusion that I made for myself when working with Yandex.Direct and AdWords is that in order to achieve maximum results you will have to delve into word forms, whatever tool you use. Therefore, I needed a complete database of word forms, preferably the closest to Yandex algorithms. I was incredibly happy when I found out about what is still living, and God grant him still health and long life,Andrei Anatolyevich Zaliznyak , who created such a dictionary. This dictionary contains about 100,000 semantic paradigms, the most "multifaceted" of which 182 word forms. In total, the entire dictionary is just over 2.5 million words. He formed the basis of many morphology recognition systems. It was this dictionary in electronic tabular form that I found on the Internet and successfully integrated into Excel for work needs.
For curious people, the question may arise - why did you need to insert 2.5 million words into Excel?
And I have 5 reasons for this , I answer:
Therefore, I decided that I would create my own lemmatizer, with blackjack the notorious macros and formulas. In the process, I’ll clarify: lemmatization is the process of reducing a sloform to a lemma - the initial dictionary form (infinitive for the verb, nominative case of the singular - for nouns and adjectives).
The result of the efforts can be downloaded from the link: Recognition Robot - 3
Visually, the file is practically no different from the previous version. The only difference is that two additional sheets (dictionary) are added to it and a macro that searches for them and returns the initial form. Since the limitations of Excel are 2 in the 20th power of lines minus one line (a little over a million), I had to divide the dictionary into 2 sheets and compose a macro based on this feature. Initially, it was assumed that the data would take 3 sheets, but fortunately, a decent number of takes were in the dictionary. They are duplicates for the computer, for a person it can be different word forms of different paradigms.
At the heart of the file is a giant array by the standards of the Excel file. Processing such an array of data is resource intensive and can be quite slow. This problem was just solved by binary (binary) search in Excel, which I mentioned at the beginning. A linear search algorithm can line-by-line run through all 2.5 million + records - this will take a lot of time. Binary search allows you to process data arrays very quickly, as it performs four main steps:
Simply put, the binary search algorithm is similar to how we look up a word in a dictionary. We open the dictionary in the middle, look into which half the word we need will be. Let's say in the first. We open the first part in the middle, continue to half, until we find the right word. Unlike linear, where it will be necessary to do 2 to 20 degrees of operations (with the maximum occupancy of the column in Excel), with binary it will be necessary to do only 20, for example. Agree, impressive. You can verify the speed of the binary search by working with the file: 3 million cells each, it searches for each of the words in the queries in a matter of seconds
All formulas and macros work only in the original file, and will not work in others. And further. If you will supplement the dictionary in the file, then before processing the file, you need to sort the dictionary in alphabetical order - as you already understood, this requires the logic of binary search.
Of course, calling the solution the most elegant will not work, at least because of the use of a huge formula for 3215 characters. Those who want to see it with their own eyes and try to understand the logic can go in and see.
However, the huge formula is not the only problem that had to be encountered while working on the lemmatizer.
The problem of the lack of modern words is solved by adding words collected from various open sources. In particular, at the time of post publication, a database of 300,000 commercial requests has already been compiled, which will be compared with the database. Words that are missing in it will be added to the dictionary in the necessary word forms. It may seem that 300 thousand words is not enough, however, believe me, this is enough for a significant expansion of Zaliznyak’s dictionary.
In addition, in “Recognition Robot 2” there will not be the aforementioned errors of other lemmatizers, in which, for example, “Avito” is considered a word form and returns the verb “Avit” and numerous word forms of this non-existent verb are generated.
PS: Wishes and bug reports are welcome.
Now Dmitry is working on another tool that will perform the opposite operations: generate word forms for given words, and not return a lemma. We are waiting for another stream of macros and giant formulas. Along with contextual advertising automation systems , we at RealWeb are actively using recognition robots in Excel - this is a serious help in working with the semantic core necessary for working with the web in general and with online advertising in particular. L - this is a serious help in working with the semantic core necessary for working with the web in general and with online advertising in particular. We are sure that these tools will come in handy for you too!
“In my previous article, we talked about clustering large semantic kernels using macros and formulas in MS Excel. This time we’ll talk about even more interesting things - word forms, lemmatization, Yandex, Google, Zalizniak’s dictionary, and again about Excel - its limitations, methods to bypass them, and incredible binary search speeds. The article, like the previous one, will be of interest to contextual advertising specialists and SEO specialists.
So where did it all start?
As you know, the key difference between Yandex search algorithms and Google search is the support of the morphology of the Russian language. That means: one of the greatest amenities is that in Yandex.Direct it is enough to specify one word form as a negative keyword (any), and the ad will not be displayed for any of all its word forms. He put the word “free” in the negative keywords - and there will be no impressions for the words “free”, “free”, “free”, “free”, etc. Conveniently? Of course!
However, not all so simple. More than one article was written on the topic of the oddities of Yandex morphology, including posts on the Habré itself, and I have repeatedly come across them in the course of my work. Disputes continue to this day, but I think this algorithm, despite everything, can be considered an advantage over Google logic.
The strange thing is that if the group of all word forms, say, a verb or an adjective, contains a homonym with a group of word forms of a noun, then Yandex actually “glues” them into a single set of word forms, all of which will display your ads.
Here is a good example, forgive me found :
As everyone knows, the short form of the adjective "great", "led and to" is a homonym of the word "in th face", which, in turn - a synonym for the word "bicycle". At the very "in e face of" word forms "great", of course not, so show it on this request obviously wrong. In the language of linguists, Yandex mixed up paradigms.
The situation in natural output is much better, perhaps the algorithms there are more complex and optimized. Or maybe this is due to higher competition, because SEO is shareware (if the state has its own webmaster), and there are an order of magnitude fewer hunters to pay for each click in Yandex.Direct, despite the positive trends in contextual advertising. Maybe the VCG auction will fix everything? Wait and see.
However, a corporation of goodness has its own quirks. Google
In general, the conclusion that I made for myself when working with Yandex.Direct and AdWords is that in order to achieve maximum results you will have to delve into word forms, whatever tool you use. Therefore, I needed a complete database of word forms, preferably the closest to Yandex algorithms. I was incredibly happy when I found out about what is still living, and God grant him still health and long life,Andrei Anatolyevich Zaliznyak , who created such a dictionary. This dictionary contains about 100,000 semantic paradigms, the most "multifaceted" of which 182 word forms. In total, the entire dictionary is just over 2.5 million words. He formed the basis of many morphology recognition systems. It was this dictionary in electronic tabular form that I found on the Internet and successfully integrated into Excel for work needs.
For curious people, the question may arise - why did you need to insert 2.5 million words into Excel?
- Firstly, it was just curious what kind of dictionary. The fact is that Yandex started supporting word forms, taking it as a basis and using it as a database. Further, of course, Yandex programmers made significant progress, which is evident even from the latest version of Mystem , in which there is an algorithm for removing homonymy described above (as I understand it, the algorithm recognizes parts of speech of nearby words, and based on this information makes assumptions about part speech of the original "polysemous" word). Nevertheless, the main competitive advantage of our Internet giant is the support of the morphology of the “great and mighty” - the result of the work done and partly the work of the 80-year-old professor.
- Free lemmatizers (for example, from K50 or Andrey Kashin ) with a simple interface, which I know and are in the public domain, do not meet my requirements, because their issuance does not comply with Yandex algorithms. And to me, not being their developer, there is no way to fix this situation.
- Since the bulk of the work with text occurs in Excel tables, and web interfaces may not always be available or “slow down” on large amounts of data, it is more convenient for me to have all the tools “at hand”, locally.
- “Recognizer Robot 1.0” without built-in normalization was worthless, and I myself was aware of this. What is the point of a contextual advertising specialist clustering a non-normalized core? All the same, you have to go into the web interface, normalize requests there, copy and then process it in Excel.
- After I discovered binary search in Excel, I wanted to try it out in action, on really large amounts of data. And why are 2.5 million cells not a large volume for MS Excel?
The birth of a lemmatizer and binary search
Therefore, I decided that I would create my own lemmatizer, with blackjack the notorious macros and formulas. In the process, I’ll clarify: lemmatization is the process of reducing a sloform to a lemma - the initial dictionary form (infinitive for the verb, nominative case of the singular - for nouns and adjectives).
The result of the efforts can be downloaded from the link: Recognition Robot - 3
Visually, the file is practically no different from the previous version. The only difference is that two additional sheets (dictionary) are added to it and a macro that searches for them and returns the initial form. Since the limitations of Excel are 2 in the 20th power of lines minus one line (a little over a million), I had to divide the dictionary into 2 sheets and compose a macro based on this feature. Initially, it was assumed that the data would take 3 sheets, but fortunately, a decent number of takes were in the dictionary. They are duplicates for the computer, for a person it can be different word forms of different paradigms.
At the heart of the file is a giant array by the standards of the Excel file. Processing such an array of data is resource intensive and can be quite slow. This problem was just solved by binary (binary) search in Excel, which I mentioned at the beginning. A linear search algorithm can line-by-line run through all 2.5 million + records - this will take a lot of time. Binary search allows you to process data arrays very quickly, as it performs four main steps:
- The data array is divided in half and the reading position moves to the middle.
- The found value (let n) is compared with the one we are looking for (let m).
- If m> n, then the second part of the array is taken, if m <n is the first part.
- Next, steps 1-3 are repeated on the selected part of the data array.
Simply put, the binary search algorithm is similar to how we look up a word in a dictionary. We open the dictionary in the middle, look into which half the word we need will be. Let's say in the first. We open the first part in the middle, continue to half, until we find the right word. Unlike linear, where it will be necessary to do 2 to 20 degrees of operations (with the maximum occupancy of the column in Excel), with binary it will be necessary to do only 20, for example. Agree, impressive. You can verify the speed of the binary search by working with the file: 3 million cells each, it searches for each of the words in the queries in a matter of seconds
All formulas and macros work only in the original file, and will not work in others. And further. If you will supplement the dictionary in the file, then before processing the file, you need to sort the dictionary in alphabetical order - as you already understood, this requires the logic of binary search.
Of course, calling the solution the most elegant will not work, at least because of the use of a huge formula for 3215 characters. Those who want to see it with their own eyes and try to understand the logic can go in and see.
Look
СЖПРОБЕЛЫ(ЕСЛИ(substring(A1;" ";1)<«м»; ЕСЛИОШИБКА(ЕСЛИ(ВПР(substring(A1;" ";1);'А-Л'!$A:$B;1;1)<substring(A1;" ";1);substring(A1;" ";1); ВПР(substring(A1;" ";1);'А-Л'!$A:$B;2;1));""); ЕСЛИОШИБКА(ЕСЛИ(ВПР(substring(A1;" ";1);'М-Я'!$A:$B;1;1)<substring(A1;" ";1);substring(A1;" ";1); ВПР(substring(A1;" ";1);'М-Я'!$A:$B;2;1));""))&" "&ЕСЛИ(substring(A1;" ";2)<«м»; ЕСЛИОШИБКА(ЕСЛИ(ВПР(substring(A1;" ";2);'А-Л'!$A:$B;1;1)<substring(A1;" ";2);substring(A1;" ";2); ВПР(substring(A1;" ";2);'А-Л'!$A:$B;2;1));""); ЕСЛИОШИБКА(ЕСЛИ(ВПР(substring(A1;" ";2);'М-Я'!$A:$B;1;1)<substring(A1;" ";2);substring(A1;" ";2); ВПР(substring(A1;" ";2);'М-Я'!$A:$B;2;1));""))&" "&ЕСЛИ(substring(A1;" ";3)<«м»; ЕСЛИОШИБКА(ЕСЛИ(ВПР(substring(A1;" ";3);'А-Л'!$A:$B;1;1)<substring(A1;" ";3);substring(A1;" ";3); ВПР(substring(A1;" ";3);'А-Л'!$A:$B;2;1));""); ЕСЛИОШИБКА(ЕСЛИ(ВПР(substring(A1;" ";3);'М-Я'!$A:$B;1;1)<substring(A1;" ";3);substring(A1;" ";3); ВПР(substring(A1;" ";3);'М-Я'!$A:$B;2;1));""))&" "&ЕСЛИ(substring(A1;" ";4)<«м»; ЕСЛИОШИБКА(ЕСЛИ(ВПР(substring(A1;" ";4);'А-Л'!$A:$B;1;1)<substring(A1;" ";4);substring(A1;" ";4); ВПР(substring(A1;" ";4);'А-Л'!$A:$B;2;1));""); ЕСЛИОШИБКА(ЕСЛИ(ВПР(substring(A1;" ";4);'М-Я'!$A:$B;1;1)<substring(A1;" ";4);substring(A1;" ";4); ВПР(substring(A1;" ";4);'М-Я'!$A:$B;2;1));""))&" "&ЕСЛИ(substring(A1;" ";5)<«м»; ЕСЛИОШИБКА(ЕСЛИ(ВПР(substring(A1;" ";5);'А-Л'!$A:$B;1;1)<substring(A1;" ";5);substring(A1;" ";5); ВПР(substring(A1;" ";5);'А-Л'!$A:$B;2;1));""); ЕСЛИОШИБКА(ЕСЛИ(ВПР(substring(A1;" ";5);'М-Я'!$A:$B;1;1)<substring(A1;" ";5);substring(A1;" ";5); ВПР(substring(A1;" ";5);'М-Я'!$A:$B;2;1));""))&" "&ЕСЛИ(substring(A1;" ";6)<«м»; ЕСЛИОШИБКА(ЕСЛИ(ВПР(substring(A1;" ";6);'А-Л'!$A:$B;1;1)<substring(A1;" ";6);substring(A1;" ";6); ВПР(substring(A1;" ";6);'А-Л'!$A:$B;2;1));""); ЕСЛИОШИБКА(ЕСЛИ(ВПР(substring(A1;" ";6);'М-Я'!$A:$B;1;1)<substring(A1;" ";6);substring(A1;" ";6); ВПР(substring(A1;" ";6);'М-Я'!$A:$B;2;1));""))&" "&ЕСЛИ(substring(A1;" ";7)<«м»; ЕСЛИОШИБКА(ЕСЛИ(ВПР(substring(A1;" ";7);'А-Л'!$A:$B;1;1)<substring(A1;" ";7);substring(A1;" ";7); ВПР(substring(A1;" ";7);'А-Л'!$A:$B;2;1));""); ЕСЛИОШИБКА(ЕСЛИ(ВПР(substring(A1;" ";7);'М-Я'!$A:$B;1;1)<substring(A1;" ";7);substring(A1;" ";7); ВПР(substring(A1;" ";7);'М-Я'!$A:$B;2;1));""))&" "&ЕСЛИ(substring(A1;" ";8)<«м»; ЕСЛИОШИБКА(ЕСЛИ(ВПР(substring(A1;" ";8);'А-Л'!$A:$B;1;1)<substring(A1;" ";8);substring(A1;" ";8); ВПР(substring(A1;" ";8);'А-Л'!$A:$B;2;1));""); ЕСЛИОШИБКА(ЕСЛИ(ВПР(substring(A1;" ";8);'М-Я'!$A:$B;1;1)<substring(A1;" ";8);substring(A1;" ";8); ВПР(substring(A1;" ";8);'М-Я'!$A:$B;2;1));""))&" "&ЕСЛИ(substring(A1;" ";9)<«м»; ЕСЛИОШИБКА(ЕСЛИ(ВПР(substring(A1;" ";9);'А-Л'!$A:$B;1;1)<substring(A1;" ";9);substring(A1;" ";9); ВПР(substring(A1;" ";9);'А-Л'!$A:$B;2;1));""); ЕСЛИОШИБКА(ЕСЛИ(ВПР(substring(A1;" ";9);'М-Я'!$A:$B;1;1)<substring(A1;" ";9);substring(A1;" ";9); ВПР(substring(A1;" ";9);'М-Я'!$A:$B;2;1));""))&" "&ЕСЛИ(substring(A1;" ";10)<«м»; ЕСЛИОШИБКА(ЕСЛИ(ВПР(substring(A1;" ";10);'А-Л'!$A:$B;1;1)<substring(A1;" ";10);substring(A1;" ";10); ВПР(substring(A1;" ";10);'А-Л'!$A:$B;2;1));""); ЕСЛИОШИБКА(ЕСЛИ(ВПР(substring(A1;" ";10);'М-Я'!$A:$B;1;1)<substring(A1;" ";10);substring(A1;" ";10); ВПР(substring(A1;" ";10);'М-Я'!$A:$B;2;1));"")))
However, the huge formula is not the only problem that had to be encountered while working on the lemmatizer.
- Zalizniak’s dictionary is an old edition (1977) and among the word forms there are no some of the simplest and most familiar words for 2015, for example, “computer”. That is why Yandex is finalizing it, I am finalizing it and, if necessary, anyone can modify it. The problem is not completely resolved, but wait for the upcoming updates of the "Robot" - everything will be.
- There are no proper names in the dictionary - they also need to be added there. I worked on this and added names, countries of the world and cities of Russia.
The problem of the lack of modern words is solved by adding words collected from various open sources. In particular, at the time of post publication, a database of 300,000 commercial requests has already been compiled, which will be compared with the database. Words that are missing in it will be added to the dictionary in the necessary word forms. It may seem that 300 thousand words is not enough, however, believe me, this is enough for a significant expansion of Zaliznyak’s dictionary.
In addition, in “Recognition Robot 2” there will not be the aforementioned errors of other lemmatizers, in which, for example, “Avito” is considered a word form and returns the verb “Avit” and numerous word forms of this non-existent verb are generated.
PS: Wishes and bug reports are welcome.
Now Dmitry is working on another tool that will perform the opposite operations: generate word forms for given words, and not return a lemma. We are waiting for another stream of macros and giant formulas. Along with contextual advertising automation systems , we at RealWeb are actively using recognition robots in Excel - this is a serious help in working with the semantic core necessary for working with the web in general and with online advertising in particular. L - this is a serious help in working with the semantic core necessary for working with the web in general and with online advertising in particular. We are sure that these tools will come in handy for you too!