MIT course "Computer Systems Security". Lecture 12: "Network Security", part 3
- Transfer
- Tutorial
Massachusetts Institute of Technology. Lecture course # 6.858. "Security of computer systems." Nikolai Zeldovich, James Mykens. year 2014
Computer Systems Security is a course on the development and implementation of secure computer systems. Lectures cover threat models, attacks that compromise security, and security methods based on the latest scientific work. Topics include operating system (OS) security, capabilities, information flow control, language security, network protocols, hardware protection and security in web applications.
Lecture 1: “Introduction: threat models” Part 1 / Part 2 / Part 3
Lecture 2: “Control of hacker attacks” Part 1 / Part 2 / Part 3
Lecture 3: “Buffer overflow: exploits and protection” Part 1 /Part 2 / Part 3
Lecture 4: “Privilege Separation” Part 1 / Part 2 / Part 3
Lecture 5: “Where Security System Errors Come From” Part 1 / Part 2
Lecture 6: “Capabilities” Part 1 / Part 2 / Part 3
Lecture 7: “Native Client Sandbox” Part 1 / Part 2 / Part 3
Lecture 8: “Network Security Model” Part 1 / Part 2 / Part 3
Lecture 9: “Web Application Security” Part 1 / Part 2/ Part 3
Lecture 10: “Symbolic execution” Part 1 / Part 2 / Part 3
Lecture 11: “Ur / Web programming language” Part 1 / Part 2 / Part 3
Lecture 12: “Network security” Part 1 / Part 2 / Part 3
Student: Is there any kind of signature for non-existing top-level domains?
Professor: I think there is. A point domain is just another domain, and it implements the same mechanism. So the dot and dot com domains nowadays use the SEC DNS, and there are all these records that say, for example, that .in is a domain name that exists, and the dot name also exists, and there is nothing else between them. So in the top level domains there are all these things.

Student: Aside from the danger of DoS attacks, why do we care about domain name repetition within mit.edu?
Professor:I do not know for sure. In any case, AFS has a text file that lists all of these MIT domain names. But I think that in general, some companies feel a little embarrassed in this sense, because they often have internal names that are in the DNS and that cannot be given to outsiders. I think that in fact, this is a fuzzy area that has never been formalized and which does not clarify exactly what guarantees the DNS provides to users. Usually people assume that if there is a confidential name, then in the case of DNS it will not be disclosed.
I think this is another place where this system does not have a clear specification in terms of what it should or should not provide.
Student:Is it possible to establish the expiration date of a signature, highlighting it in some way?
Professor: these things have an expiration date, for example, you can sign that the given set of names is valid for a week, and then customers, if they have a synchronized clock, can reject the old signed messages.
So, we can assume that we have discussed attacks by guessing the sequence numbers of TCP SYN. Another interesting problem that concerns TCP is the DDoS attack, which exploits the fact that the server retains some state. If you look at this handshake that was drawn on the board earlier, you will see that when a client establishes a connection to the server, the server must remember the sequence number of the client SNc. Thus, the server must support some data structure in a separate block, which indicates that this sequence number is used for this connection.
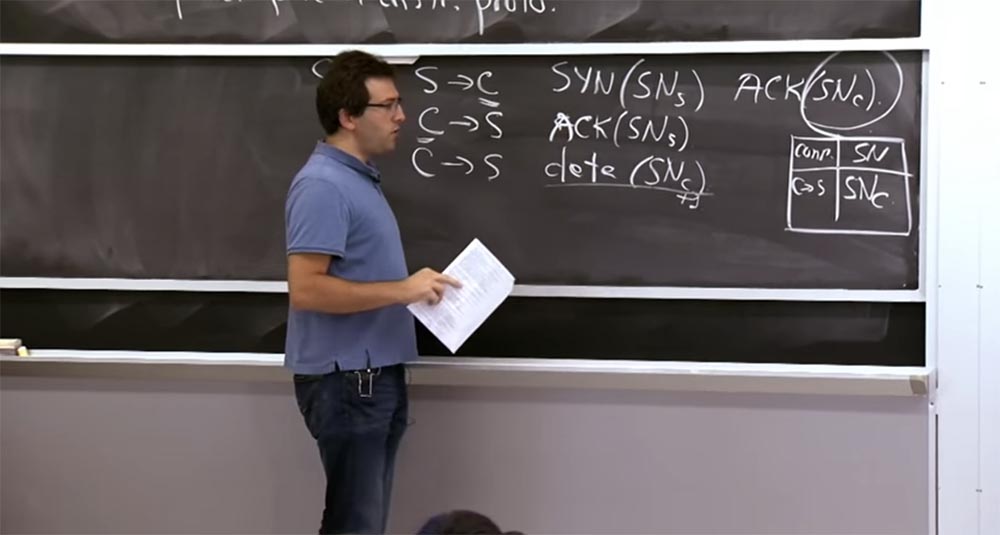
This is a kind of table where the serial number of the SN is stored and the fact that the client-server connection has the serial number of the SNc. The reason why the server should store this table is that the server has to figure out which correct value the SNc sequence number should accept later, for example, SNc + 1. In addition, the server also needs to store SNs numbers, which are much more important because they show the server that the connection is established with the “right guy”.
The problem is that this table has no real border. This way, you can get packets from some machine without even knowing who is sending them. You simply receive a packet that looks like C-> S with the source address, which states that it is C. In order to potentially accept this connection from this IP address, you need to create an entry in the table. Moreover, these records exist for a long time, because perhaps someone establishes a connection with you from a very distant place and at the same time many packets are lost. In the worst case, it may take, for example, a minute until someone finishes this TCP handshake. So you have to store this state on the TCP stack for a relatively long time, and there is no way to guess whether it will be valid or not.
Thus, the most common DoS attack against most TCP stacks that people have invented is the simple transfer of a large number of packets. If I’m an attacker, I’ll just send a huge number of SYN packets to a specific server and force it to overflow this table.
The problem is that at best, the attacker simply uses the same source IP address. In this case, you can simply say that each client is only allowed two entries, or something like that. And then the attacker can use a maximum of 2 two entries in the table.
The problem, of course, is that an attacker can fake clients' IP addresses, make them look random. Then it will be very difficult for the server to distinguish who is trying to establish a connection with it - an attacker or some kind of client that the server has never heard of before.
So, if you look at a site that should accept connections from anywhere in the world, this will be a big problem. Because either you are denying access to everyone, or you must be able to store state for most fake connection attempts.
So this is a problem both for TCP and for most protocols, which allow a kind of connection initiation, in which the server must save state. But there are some fixes implemented in TCP, which we'll talk about in a second, and they will try to deal with this problem, which is called SYN Flooding in TCP.

In general, this is a problem that is worth knowing and trying to avoid in any protocol that you are developing. You must specify that the server does not have to keep state until it can authenticate and identify the client. Because only after checking the client’s authenticity can one decide whether he is allowed to connect, for example, only once, in which case the server does not need to save the state for this connection.
The problem is that you guarantee the preservation of the state even before you find out who is connecting to you. Let's take a look at how to counteract the SYN Flooding “flood” attack, which is that the server accumulates too much state.
You could change TCP again, for example, fix it fairly easily with cryptography or something else, or change what is responsible for maintaining a state. But the fact is, we need to use TCP as it is. Could we solve this problem without changing the existing TCP protocol?
This, again, is an exercise in trying to figure out exactly which tricks we could perform or, more precisely, which assumptions we could leave alone and still stick to the existing TCP header format when working with them.
And the trick is to find a smart way to make a server stateless, so that it does not have to store this table in memory. This can be done by carefully selecting the SNs, that is, instead of the formula we considered earlier and where we should have added this function, we will choose the sequence numbers in a completely different way. I will give you the exact formula, and then we will talk about why it is really interesting and what good properties it has.
If the server detects that it is under attack of this kind, then it goes into a mode where it selects SNs using a formula with the same function F that we considered before.
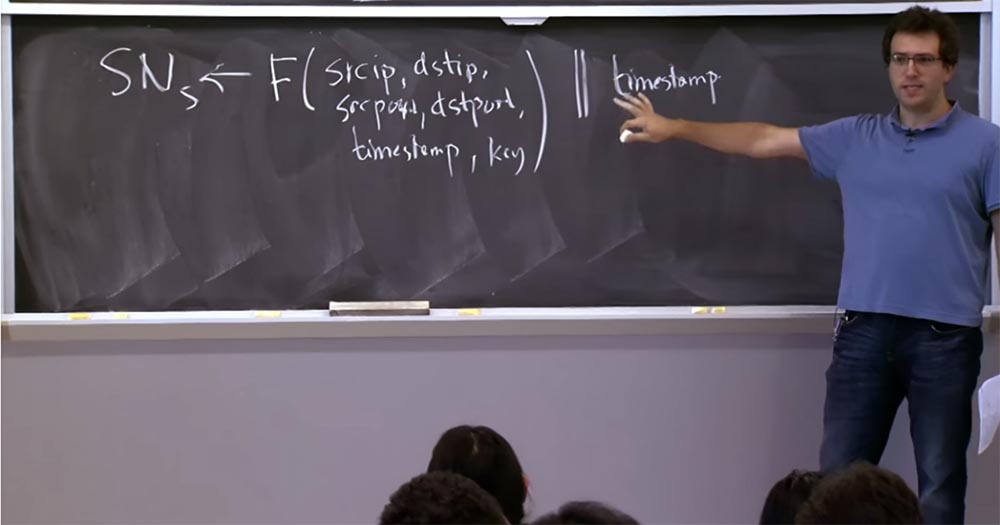
This function has the source IP address, the destination IP address, the same things as before — the source port, the destination port, the timestamp, and the key. And we are going to combine this function with a timestamp rather “coarse-grained”, the size of a few minutes. There is a separation between these two parts of the header — a function and a time stamp that does not need a lot of bits. I forgot exactly how this protocol works on a real computer, but you can imagine that the timestamp takes up 8 bits, and the rest of the sequence number formula is 24 bits.
So why is this a good plan? What is going on here at all? Why do we need this strange formula? You have to remember that we tried to get from the sequence numbers. Two things happen here.
The first is protection against duplicate packets. There is a diagram with an old-style ordinal on the board, to which we add a function to prevent duplication of packets from previous connections.
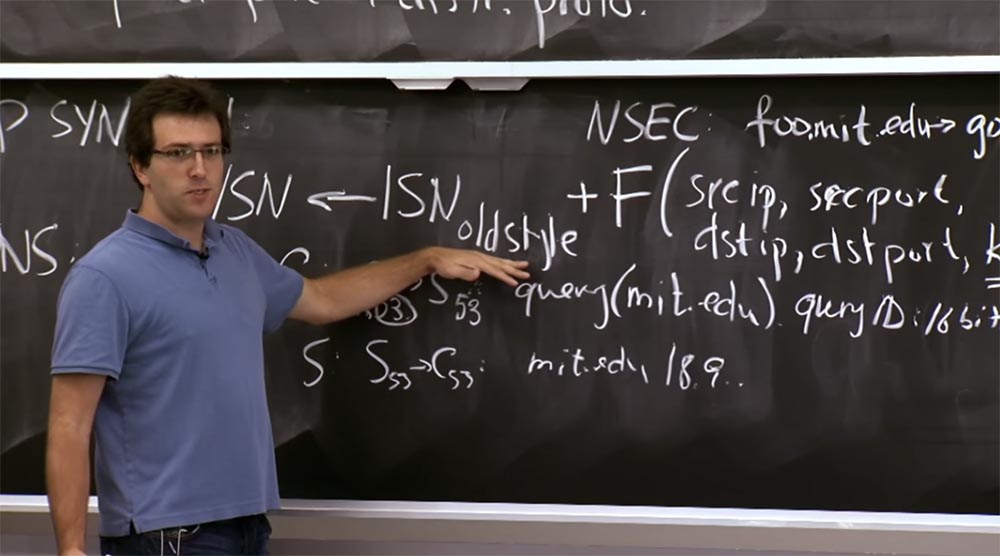
It turns out that people could not find a better way to protect themselves from attacks like SYN Flooding, except to use this action plan, which works well in some situations. It was one plan, but another plan - a function with a timestamp, where we abandoned this component of the old style. Instead, we will focus on making sure that if someone provides this ACK sequence number (SNs) in response to a packet, that someone will be the “right” customer.
You remember that to prevent IP spoofing attacks, we kind of rely on this value (SNs). After all, if the server sends the SNs value to the client in the second step, we expect that only this client will be able to send us the corrected SNs value back in the third step, completing the connection setup.
That is why you had to keep this sequence number in the table, because otherwise, how would you know if this is a real answer or a fake one? The reason for using this function F is that now we can not save this table in memory.
Instead, when an attempt is made to connect, shown in the first step, in the second step we calculate the SNs using this formula and simply send it back to the client who wants to contact us, and then forget about this connection.
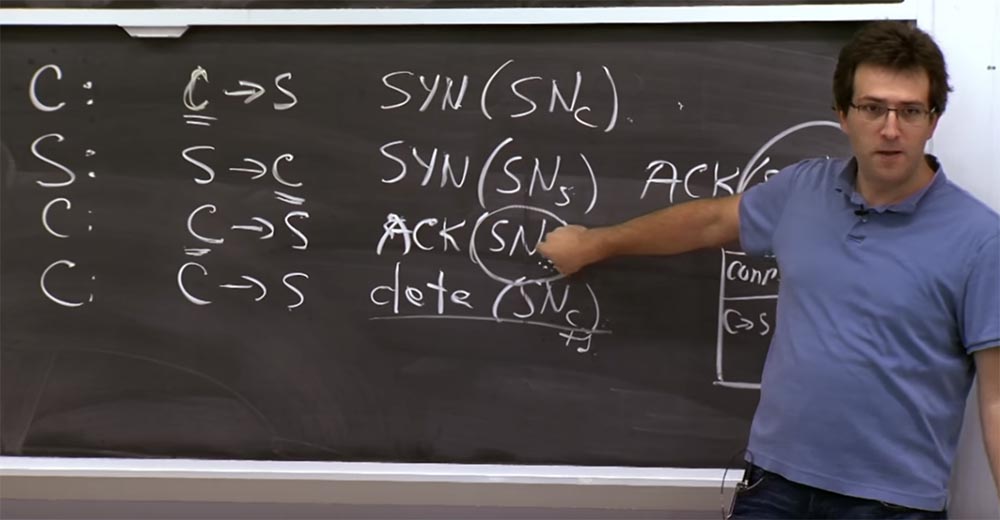
Then, when the third packet arrives and its value (SNs) matches what we expect to see, it means that someone received our answer in the second step and finally sent it to us. Finally, after this third step, we can put the real entry for this TCP connection in memory. This is the way to delay the saving of the server state until the client sends the exact value of the sequence number. Building such a construction allows you to make sure that the client sent the server exactly the answer that is expected of it, and not some arbitrary value.
Student: does the SNc save only limited time?
Professor:Yes, the server does not store the SNc value all the time, and this is not too good. I did not show this in the diagram, but here at the end of the third line there is a field that shows that this packet has no data, but it only includes the sequence number SNc because it has this field.
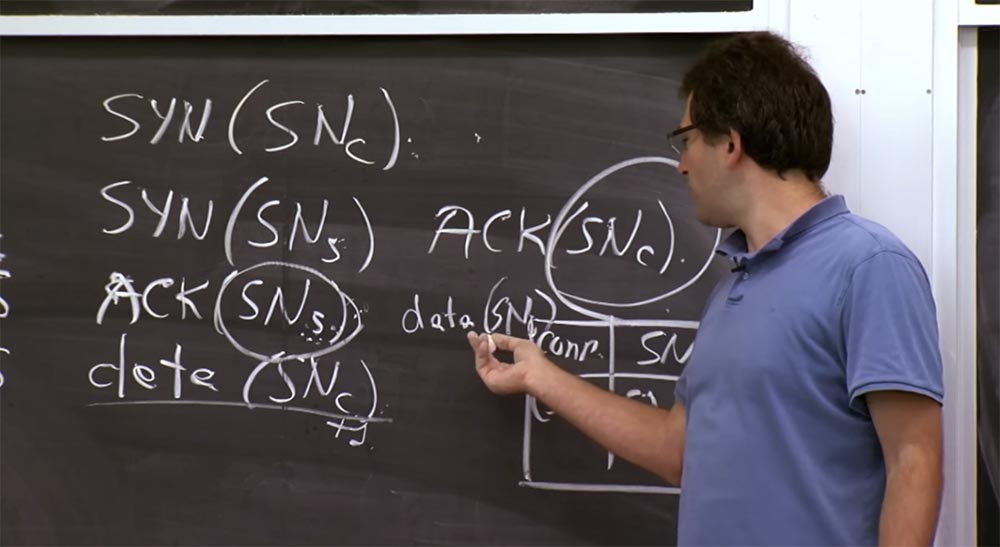
Thus, the server can restore the SNc value, because the client is going to include it in this package anyway. Previously, it did not matter, but now it seems to be relevant. We are not going to check anything here, but the existence of such a field is in itself a good thing. However, it has some sad consequences. For example, if you use some complex things that can be abused. But this is not as bad as overflowing the server with client requests.
Because the only thing that worries us is the release of the storage of this table and the confidence that the connections are established with genuine customers. And if this client establishes a million connections with me, I will simply stop receiving requests from him, it is quite simple. The problem is that the fake addresses are difficult to distinguish from the addresses of genuine customers.
Student: Do I need to store a timestamp?
Professor:Yes, there is a clever thing here! When we get the value of the SNs sequence number in the third step, we need to figure out how to calculate the input data for this function F to verify that this value is correct. Therefore, we take the time stamp located at the end of the packet and use it to calculate it inside the function. Everything else we can recover. We know who just sent us the third step and the package, we have all these fields and our key, which, again, is still secret, and the timestamp of the last 8 bits of the sequence. In this case, it may happen that we exclude too old timestamps by simply banning old connections.
Student: I believe that you use it when you are attacked, just because you lose 8 bits of security, or for some other reason?
Professor: yes, it is not very good, it has a lot of bad properties. In a sense, we really lose 8 bits of security. Because now the undeniable part is only 24 bits instead of 32.
Another problem is what happens if you lose certain packages? In TCP, it is assumed that if the third packet is lost, then the client may not wait for anything. Or, sorry, maybe the protocol that we run on top of this TCP connection is a protocol that assumes that the server initially has something to say, so I connect to it and just listen to the answer. And in SMTP, for example, the server should send me something like a greeting via the protocol. Suppose I connect to the SMTP server, send the third packet, I think that I did everything and just wait for the server to answer me, for example:
“Hello, this is an SMTP server, please send me your letter”!
So, this third package may be lost. In real TCP, the server remembers that in the second step, it responded to the client, but never received a response packet from it. Therefore, the server will send the second packet to the client again to restart the third packet. Of course, if the server does not store any state, it has no idea what to send. This makes the connection setup somewhat problematic, because both sides will wait for a response step from each other. The server does not even know that the client is waiting for a response from him, and the client is waiting for a server response, although he is not going to respond, because he does not store the state. Therefore, this is another reason why you do not constantly use the productive server mode.
Student:you may also have data loss if you set up two very short connections from one host immediately.
Professor: yes, definitely. Another thing is that we abandoned the use of this old-style ISN sequence number, which increased the independence of these multiple connections in a short time from each other. I think that there are a number of compromises, we just talked about three of them, so there are a few more reasons for concern.
If we could develop a protocol from scratch, striving for the best, we could just have a separate good 64-bit volume for the F function and a 64-bit volume for the time stamp, and then we could use it all the time, without giving up all these nice things.
Student:Should the SNs in the second and third step be the same?
Professor: of course, because otherwise the server will not be able to conclude that this client received our package. If the server did not verify that this SNs has the same meaning as before, then it may be even worse - after all, I could fake a connection from a random IP address in the first step, and then get this answer in the second step. Or I would not even get this reply, because it is sent to a different IP address. Then in the third step, I establish a connection from some other IP address. At the same time, the server would support the established connection, wait for me to send the data, and so on.
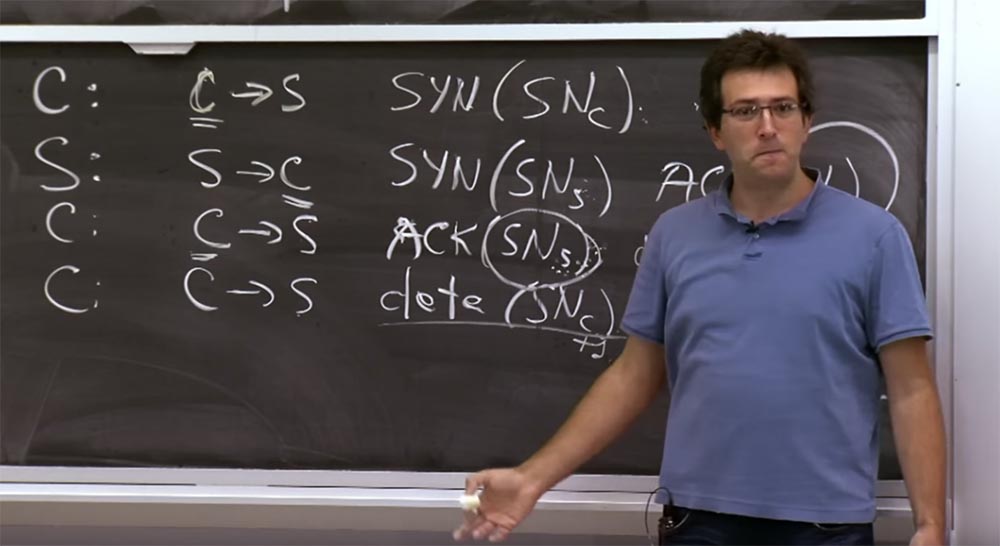
Student: but the timestamp will be different, right? How can the server recalculate this with the new timestamp if it does not store the state?
Professor: as I said, these time stamps are quite coarse-grained and graduated in minutes. If you connect at the same minute, then everything is fine; if you connect at the border of a minute, this is too bad.
Another problem with this scheme is that it is imperfect in many ways. But most production systems, including Linux, have ways to detect too many entries in this table. And when there is a threat of its overflow, the system switches to another scheme.
Student: if an attacker controls a large number of IP addresses and does what you said, even if you switch ...
Professor:yes, in fact you can do little. The reason we are so concerned about this scheme is that we wanted to filter or somehow distinguish between the attackers and the “good guys.” If an attacker has more IP addresses and simply controls more machines than the good guys, then he can connect to our server, request a lot of web pages, or keep in touch.
And then it will be very difficult for the server to determine whether requests are coming from legitimate clients or is it just that the attacker links server resources. So you are absolutely right. This scheme only works when an attacker has a small number of IP addresses and wants to achieve the effect.
And it is disturbing, because today some attackers control a large number of hacked computers of ordinary users. This allows them to create DoS using a fleet of machines located throughout the world, and it is rather difficult to protect against this.
I want to mention another interesting thing - the failure of the DoS service is bad in itself, but even worse when the protocols themselves contribute to the attack. The attacker is aware of this and primarily attacks systems with protocols such as DNS. The DNS protocol involves the client sending a request to the server, and the server sends the response back to the client. And in many cases the response volume in bytes far exceeds the request volume.

You asked about the mit.edu server. So, the answer to your request can be all the records that are on the server mit.edu - email address, the mail server for mit.edu, the assigned record, if it uses DNS SEC, and so on.
So the request can be 100 bytes, and the answer is more than 1000 bytes. Suppose you want to “flood” a guy with a large number of packets or use the entire bandwidth of his communication channel. You can use only a little of your bandwidth, but you can organize fake requests to the DNS server on behalf of this guy. You need to send only 100 bytes to a DNS server, pretending that the request originates from this poor fellow, and in response the server will send him 1000 bytes on your behalf.
This is a problematic feature of this protocol, since it allows you to increase the bandwidth of the attack. And partly for the same reason that we mentioned in the case of TCP SYN Flooding, it is very difficult for the DNS server to determine whether this request is valid or not. Because while continuing to exchange data, there is no authentication or sequence number, saying that the connection is established with the "right guy."
Today it is still a DNS problem. And this vulnerability is often used to attack by reducing the bandwidth of the client channel. If your bandwidth is limited to a specific value, then to work effectively you need to repel a similar attack from the DNS server. However, these servers are forced to respond to each request, because otherwise there will be a threat of rejection of legitimate requests. So in practice, this is a big problem.
Student: if you can see the attacker's request on the DNS server and not respond to it ...
Professor: yes, there is a certain possibility to modify the DNS server so that it stores some state.
Student:so why is this scheme used so far, if it does not provide for the preservation of the state?
Professor: I think that now some people are starting to modify the DNS server to try to save the state. However, there are so many DNS servers that it does not matter. Even if you make 10 requests to each DNS server, each packet is amplified by some significant factors, and the server must respond to them, because perhaps these requests come from a legitimate client. So this is a problem. Yes, you are right, if it was a single DNS server, then modifying it would not be so difficult.
The problem also lies in the fact that root DNS servers are not one machine, they are racks and server racks, because they are massively used, and therefore it is very difficult to store the state for such a large number of machines. However, the growth of malicious interventions leads to the fact that maintain state is becoming more and more appropriate.
I think that the general principle that you want to follow in any protocol, and it can be a good principle is to make the client do at least as much work as the server does. But the problem is that the client cannot do as much as the server does. Therefore, the server should help him in this.
If you created a DNS server from scratch and that would be your big problem, then you could solve it quite simply. The client would have to send a request that has additional padding bytes just to increase the bandwidth of the channel, and then the server will send back a response of the same size.
And if you want to receive a larger response, the server will say: “sorry, your addition was not big enough, send me more”! Thus, you guarantee that the DNS server cannot be used to amplify attacks by absorbing bandwidth.
In fact, this kind of problem happens at higher levels. Often, web applications have web services that perform many calculations on behalf of a single request. At this level, DoS attacks consist in the fact that opponents know about the resource intensity of a certain type of operation and simply send a request to perform this operation again and again. If you do not carefully develop your protocol and application so as to allow the client to prove that he performs no less work than the server, then it is rather difficult to protect yourself from such things.

The last thing I want to mention in this article is the routing attack. The reasons for these attacks are interesting because they bring to the surface the problems of the transport layer of the protocol and provide an opportunity to see what happens in an application in the wrong way.
A particularly interesting example is the routing protocol, for which trust in the user is the basis of the work, and often this is interpreted in the wrong way. Even today, there are no flawless authentication mechanisms.
Perhaps the most prominent example is DHCP, which is used to connect to a wireless or wired network. The computer simply sends the packet, saying that it wants an IP address. In this case, for example, the MIT DHCP server, after receiving your packet, sends it back, indicating that here is the IP address you need to use, here is the DNS server you need to use, and here are some other useful configuration data for this connection.
The problem is that the DHCP request packet simply broadcasts on the local network about trying to contact a DHCP server, because you really do not know in advance what the DHCP server is going to do. You simply connect to the network for the first time and send a request, and your client computer does not know what to do and who to trust. Consequently, any machine on the local network can intercept these DHCP requests and respond to the client from any IP address, saying, “hey, you should use my DNS server instead of real”! This allows the attacker to intercept future DNS requests from the client, and so on.
Therefore, I think these protocols are quite difficult to fix. Globally, protocols such as BGP allow any member of the network to advertise a specific IP address prefix in order to sort and route packets to an attacker. At the same time there were attacks in which the router participating in BGP said: “oh, I know a very fast way to reach this particular IP address!”, And then all the other routers answered him: “OK, of course, we will send you these packets “.

Probably, this is most often abused by spammers who want to send their spam, but their old IP addresses are blacklisted everywhere. Therefore, they simply select a random IP address and declare that yes, their IP address is now located here. Then they sort of announce this IP address on the network, send spam from it and turn it off. Now such cases are becoming less, but completely eradicate this is difficult. Because in order to fix this, you need to know who really owns this IP address. Without this, it is difficult to do when creating a global database of cryptographic keys for each provider in the world, but people make a lot of efforts to create this database.
The same applies to the DNS SEC. In order to know what signature to look for in the DNS, you must have a cryptographic key associated with all network entities in the world. Today it is not possible, but we should strive for this, because, of course, this is the biggest problem for the widespread use of the DNS SEC.
So, I believe that information from this article should be selected, which should not be done in the protocols at all. I want to focus your attention on one important thing: while security and integrity are important features and driving force of higher levels of abstraction, such as cryptographic protocols in the applications that we will consider in the next lecture, the main requirements for the network should be accessibility and DoS resistance to attacks. Because these properties are much more difficult to achieve in the stack at higher levels.
Thus, you should strive to avoid such things as, SYN Flooding attacks and RST attacks, allowing you to break the connection of an arbitrary network user. These are things that are really harmful at a low level and that are difficult to fix at a high level. But more or less to ensure the integrity and confidentiality of data can be using encryption. We will talk about how to do this in the next lecture about Cerberus.
Full version of the course is available here .
Thank you for staying with us. Do you like our articles? Want to see more interesting materials? Support us by placing an order or recommending to friends, 30% discount for Habr's users on a unique analogue of the entry-level servers that we invented for you: The whole truth about VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps from $ 20 or how to share the server? (Options are available with RAID1 and RAID10, up to 24 cores and up to 40GB DDR4).
VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps until December for free if you pay for a period of six months, you can order here .
Dell R730xd 2 times cheaper? Only here2 x Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 TV from $ 249 in the Netherlands and the USA! Read about How to build an infrastructure building. class c using servers Dell R730xd E5-2650 v4 worth 9000 euros for a penny?