How we taught the neural network to define documents

This summer we taught the neural network to determine if there is a document in the image, and if so, which one.
What did it take
To unload employees and protect people from scammers. We use the new neural network in two areas: when the user recovers access to the page and to hide personal documents from the general search.
Restore access to pages. Photos of documents help to return accounts to their original owners. For example, a user could lose access to his phone number, or two-step authentication is connected to the page, and there is no longer a possibility to get a one-time code to confirm entry. New development speeds up consideration of appeals: moderators no longer have to return incorrectly filed applications every time. The system simply does not allow the visitor to send the form without the necessary images and asks to replace the random image with the document. Of course, we can still return access to the page itself only if there are real photos of the owner on it. We are talking about the security of accounts and the safety of personal data - it means there can be no blunders and accidents.
Filtering search results in the " Documents " section. All documents that users upload to this section or send via private messages are, by default, hidden from prying eyes and do not fall into the search results. But the level of privacy can be configured manually by yourself - for each individual file. Before the advent of the neural network, a decent amount of documents with sensitive data could be found by keywords. The owners of these files themselves have changed the privacy settings. We secured users and started removing photos from the public search where we can determine the presence of the document.
How we solved the problem
It seems that the easiest way to identify documents in an image is to set up a neural network or train it from scratch on a large sample. But not everything is so simple.
The sample should be representative. It is difficult to find a sufficient number of real samples for each option: there are no public databases with these documents in the public domain.
There are many systems that recognize and parsit documents. Usually they are aimed at obtaining specific information from a photograph and suggest the perfect quality of the original image. For example, the user may be required to align the passport along the edges of the template, as it works on the portal of state services.
For our tasks, such systems are not suitable. We separately clarify that when contacting us for the restoration of access, the user can closeon the document all the data, except photos, name, surname and print. At the same time, we still need to identify the document - even if the series and number are hidden on it, if the passport is removed together with the surrounding situation or, on the contrary, only a part of the document with a photo appeared on the image. Still need to take into account different lighting and angles. All such materials neural network must accept. The question is how to teach her this.

There are other difficulties. For example, a passport is difficult to separate from other types of documents, as well as from various handwritten and printed papers.
Attempting to go on a simple path was not very successful. The resulting classifier was weak, with a small error of the first kind and a large error of the second. For example, there were interesting cases when a person wrote the name and surname by hand, added a photograph, the cover of a passport - and the system blithely accepted such a document.
What we came to
In our situation, the best solution to the problem turned out to be using an ensemble of grids and face detectors to recognize the document and determine its type. We also added a differential classifier, which includes an encoder to highlight the characteristic features, and a form classifier, which allows us to distinguish document images from irrelevant files. In addition to this, pre-clustering of the training set takes place in order to normalize the dataset. Of the architectures, VGG and ResNet have proven their best .
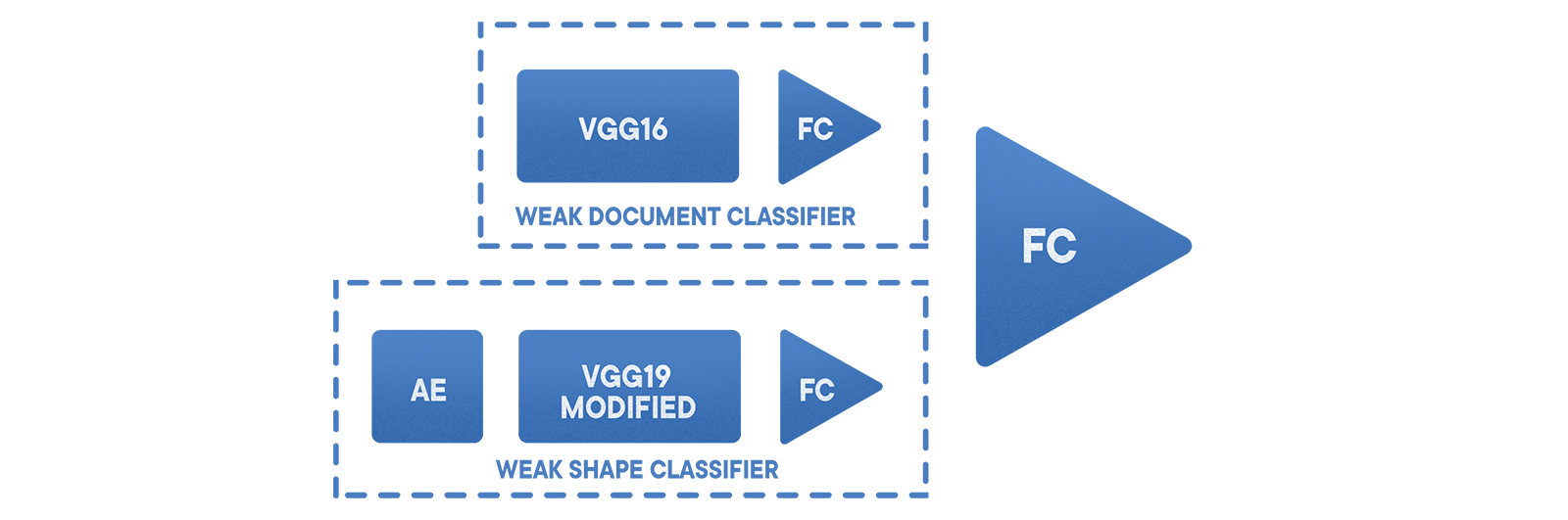
The basic document / non-document classifier works on the basis of a configured 19-layer VGG with a regional sample. Over it, a combined ensemble of classifiers is used, which reduce the error of the second kind and differentiate the result. First, there is a stratified sampling , then an encoder to extract the near-circuit information, then a modified VGG, and finally a single grid. This approach allowed us to minimize the errors of the first kind to a level of approximately 0.002. The probability of false negative depends on the chosen dataset and specific application.
Now we have learned how to automatically detect the presence of passports and driver's licenses in the picture. Recognition successfully occurs at any angle, with any background, even in poor light - the main thing is that the image contains a part of a document with a photo and a name. However, for identification of other types of documents, only relevant datasets will be required. We train the network on our own data, the sample size of documents is from five to ten thousand (but it is not representative). For other images, the sample is arbitrary, but there and there, there is a priori clustering.
From a technical point of view, the system is written in python / keras / tensorflow / glib / opencv. For practical application of the new system, it is enough to integrate it into the python-handlers of the machine learning infrastructure. At the same stage, the photo change detector in graphic editors is added, but this topic deserves a separate article.
What is the result
Now, 6% of applications for access restoration are automatically returned to the author with a request to add or replace a photo of the document, and 2.5% of applications are rejected. If you look at the analysis of images in general, including heuristics and the search for a person in the picture, then it automates up to 20% of the department’s work .
After the launch of the neural network, we were also able to calculate the number of passports that are loaded into the “Documents” section. It turned out that in the general search results every day there were about two thousand identity cards. Now the likelihood that they will fall into extraneous hands, is minimal.
Neural networks are already helping us fight spam and various types of fraud. We do not stop the experiments and continue to talk about them in our blog.