Parsing a Word document into pictures or a story about graduate workdays
I want to introduce you to a way to extract data from a word document in the form of pictures. Perhaps the ideas presented will be primitive and obvious to someone. But I had to spend a couple of sleepless nights before reaching a normal solution. So, I am starting.
It was the beginning of 2015. Winter. I was happy with the good weather and delightedly thought that I would finally finish the university (I’m lying, now I’m going to graduate school). I recently finished my diploma, so I was even happier. However, soon, by human nature, the state of serenity gradually began to be replaced by boredom. And here, as if on purpose, the silence was replaced by a telephone call.
Hello, how are you? - the voice of a friend sounded.
Intuition immediately determined that most likely the conversation would be on the topic of "tyzhprogramist." So it was. With a dull look, at first I listened about the difficult times of my acquaintance and about everything else, but her final request made me interested.
“Could you help me with a diploma? In general, it is necessary to create a website-simulator for mathematics, ”she said.
That was interesting. I'm just fascinated by the development of complex frontends. I immediately approved the request.
It took a total of no more than 2 days to implement the simulator. The site simulator allows you to pass tests in higher mathematics and view the theory. Tests can be performed in two modes: in training mode with highlighting of answers and in testing mode with output at the end. The implementation was done on ReactJS and Bootstrap and the process itself was quite enjoyable. But that was only the beginning. It was necessary how to fill in the data base of questions of tests, which were by no means in the form of ready-made ordered data.
While I was looking with satisfaction at the result of work, a friend called again. She notified me that she sent me a small archiver with questions in * .doc files to the mail. “If anything, I can help throw questions and answers into the database,” she added.
This spoiled my mood a bit, because I did not think that I would have to fill in the test questions database myself.
Okay. I went to open my GMail and here:
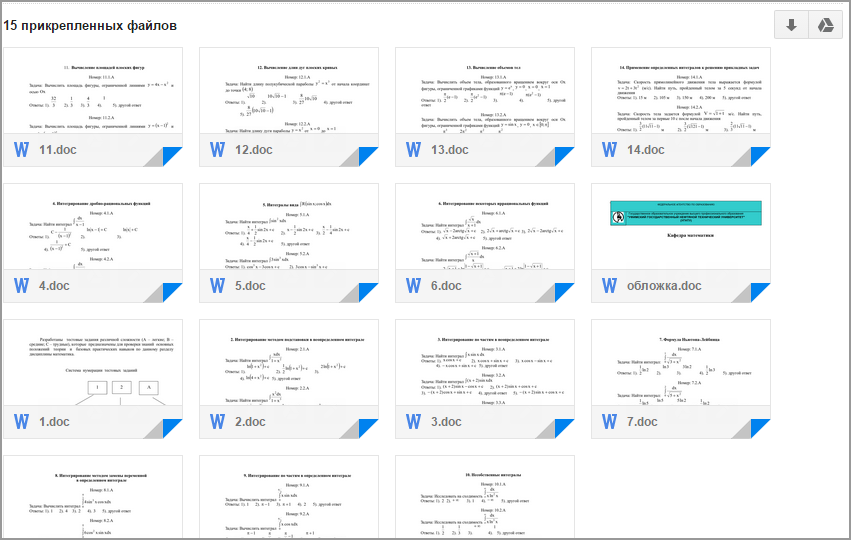
And in each file there are ~ 50 test tasks in the form:

Well, it’s unlikely that you can manually hammer all this into the database. By the way, each test task in the database was stored in the form of one picture-question, five picture-answers, difficulty level (A, B, C) and the number of the correct answer (1-5). Frustrated, I decided to postpone this question for a long time, good time was enough. But a few days later another message from a friend fell into the mail, and then another ... As a result, there were 4 sections on higher mathematics, each of the sections consisted of 14-23 sections, each section contained approximately 30-100 test tasks. And then I finally made sure that manually driving all this into the database would definitely fail.
By the way about the database. This is MySQL with three tables: sections, subsections, and test questions. Pictures of the question and five answers are stored directly in the database, in the BLOB column. It seems to me so convenient, because there are a lot of these pictures, and besides, they weigh a little. And they will all be stored in one place, along with other data.
So what was needed? In the best case, it was necessary to get ready corresponding records in the database from the folder with all the word files of the test tasks, which was practically obtained in the final result. We are interested in the main thing: directly extracting the pictures.
Input : word file with test tasks.
Output (e.g.): a folder with PNG images, where the task has a name of the form 1.png, and the answers have the names 1.1.png, 1.2.png, 1.3.png, 1.4.png, 1.5.png, plus the answer.txt file inside which i -th line contains a number from 1 to 5, corresponding to the correct answer of the i-th task.
I love Qt Creator. And why should I love him? Most likely because in the university we are trained precisely for it, I myself do not know. And while using it, I feel some kind of quiet delight. Well, in general, you understand what I began to write the parser program on.
At first, I wondered how to interact with this Word in order to somehow pull data out of there. All sorts of terrible thoughts came to mind like converting a word file into HTML with subsequent processing. But google immediately sent me on an adequate path, giving information about the VBA language. I was immediately struck by the abundance of ready-made functions, I learned what paragraphs, positions, etc., meanwhile, fucking awesome due to the complexity of the structure of the word document tree.
However, I was disappointed because I still did not understand how to turn a piece of text into a picture. At first I wanted to use something like text2png, after having pulled out the necessary piece of text. But what about formulas and pictures? There was no built-in function in VBA. At one point, a thought flashed inadvertently that it seemed like I had previously inserted excel cells in the form of pictures into the word document in the document. So it was! This was called a “special insert” and allowed to insert any part of the document as a picture. Suppose we entered into the clipboard a piece of the document, which must be saved as a picture. But how to save this picture to disk? Googling also helped find a solution. The code section below saves the contents of the clipboard to disk as a universal EMF vector file.
Excellent. However, what kind of beast is this EMF? It was necessary to turn it into PNG. I started looking for image converters. After going through a bunch, I did not find an adequate one. And here again (does anyone believe in intuition?) Some tricked-out image viewer that I put in the school years from the disc with Golden Software for fun, began to come to my mind. But like it was not a converter. However, it was necessary to make sure. Some sort of “Ifran” or “Irfan” was spinning in my head, in general, the program was found. Free, with batch image processing function, supports command line! And most importantly, it supports EMF. That was what we needed. The IrfanView executable file with the necessary DLLs and the parameters ini-file is in the same folder with the compiled program (I hope this does not violate the license) and is used through the function like this.
Now it remains to copy the necessary pieces from the word document to the buffer. To do this, you need to come up with an algorithm for breaking the source text into separate blocks with a task, with answers, with the number of the correct answer and the level of complexity.
The first attempt at implementation was as follows. We take the source document, replace the text of the form ([1-5]) \) with \ n $ 1 \) in it, i.e. before the beginning of each answer, add a newline. On VBA, replacement strings are written differently, I don’t remember. Now in the document settings we set the page width to maximum, and reduce the font for the entire document. As a result, it turns out that in the document each task will occupy exactly 8 lines, moreover:
Now, after this processing, there is nothing left but to go through the array of the collection of document lines, starting counter i, and depending on i% 8, save the picture of the task / answers or retrieve the number of the correct answer with the level of complexity.
But that did not fit. The long assignments are to blame, which, being written on one line, look terrible, shallow and do not always fit. In addition, sometimes replacing the text “1)” affects places other than response numbers. Saddened by the result, I again began to think about what could be done in this case. And then I remembered about finite state machines. I remembered the state, remembered the character input. Recalled the parser. Perhaps this was an obvious solution to others, but as a person far from complex algorithms, I was extremely happy with my idea.
Now it’s time to write and try the parser code based on the state machine. We have 7 states:
We implement using the conditions for the beginning of the next state. After testing the first version of the parser, everything went great. Pictures were obtained as in the word document itself, beautifully, large. But here ... From time to time, jambs appeared, for example, in one picture an extra piece was captured until the next block of the task. So the parser incorrectly recognized. What is the matter? Everything turned out to be simple - tasks in a word document were typed manually and therefore there was a human factor, for example:
It was a nightmare. Fortunately, the main mistakes were in writing the numbers of tasks; they were somehow taken into account by the parser. The remaining errors after extracting the images were detected by a quick look at the largest and smallest in size images, followed by correction and re-extraction.
The final piece of the parser is the code below. He is terrible, please do not judge strictly. To store VBA objects, a QAxObject is used.
The logic of the above code is slightly different from that described above. She also uses paragraph breaks. But this does not greatly change the main idea.
In this way, it turned out to “defeat” this Word!
As a result, all tasks in the amount of ~ 4 thousand were extracted. The necessary parser shell was written. A program for uploading and administering tasks to a remote database has also been written. The fee was received, her diploma is protected perfectly, mine is also protected perfectly.
Thank you for your attention, I hope this post will help someone in a similar problem. Or maybe someone knows a better implementation?
Update:
It was the beginning of 2015. Winter. I was happy with the good weather and delightedly thought that I would finally finish the university (I’m lying, now I’m going to graduate school). I recently finished my diploma, so I was even happier. However, soon, by human nature, the state of serenity gradually began to be replaced by boredom. And here, as if on purpose, the silence was replaced by a telephone call.
Hello, how are you? - the voice of a friend sounded.
Intuition immediately determined that most likely the conversation would be on the topic of "tyzhprogramist." So it was. With a dull look, at first I listened about the difficult times of my acquaintance and about everything else, but her final request made me interested.
“Could you help me with a diploma? In general, it is necessary to create a website-simulator for mathematics, ”she said.
That was interesting. I'm just fascinated by the development of complex frontends. I immediately approved the request.
It took a total of no more than 2 days to implement the simulator. The site simulator allows you to pass tests in higher mathematics and view the theory. Tests can be performed in two modes: in training mode with highlighting of answers and in testing mode with output at the end. The implementation was done on ReactJS and Bootstrap and the process itself was quite enjoyable. But that was only the beginning. It was necessary how to fill in the data base of questions of tests, which were by no means in the form of ready-made ordered data.
Formulation of the problem
While I was looking with satisfaction at the result of work, a friend called again. She notified me that she sent me a small archiver with questions in * .doc files to the mail. “If anything, I can help throw questions and answers into the database,” she added.
This spoiled my mood a bit, because I did not think that I would have to fill in the test questions database myself.
Okay. I went to open my GMail and here:
And in each file there are ~ 50 test tasks in the form:
Well, it’s unlikely that you can manually hammer all this into the database. By the way, each test task in the database was stored in the form of one picture-question, five picture-answers, difficulty level (A, B, C) and the number of the correct answer (1-5). Frustrated, I decided to postpone this question for a long time, good time was enough. But a few days later another message from a friend fell into the mail, and then another ... As a result, there were 4 sections on higher mathematics, each of the sections consisted of 14-23 sections, each section contained approximately 30-100 test tasks. And then I finally made sure that manually driving all this into the database would definitely fail.
By the way about the database. This is MySQL with three tables: sections, subsections, and test questions. Pictures of the question and five answers are stored directly in the database, in the BLOB column. It seems to me so convenient, because there are a lot of these pictures, and besides, they weigh a little. And they will all be stored in one place, along with other data.
So what was needed? In the best case, it was necessary to get ready corresponding records in the database from the folder with all the word files of the test tasks, which was practically obtained in the final result. We are interested in the main thing: directly extracting the pictures.
Input : word file with test tasks.
Output (e.g.): a folder with PNG images, where the task has a name of the form 1.png, and the answers have the names 1.1.png, 1.2.png, 1.3.png, 1.4.png, 1.5.png, plus the answer.txt file inside which i -th line contains a number from 1 to 5, corresponding to the correct answer of the i-th task.
Implementation
I love Qt Creator. And why should I love him? Most likely because in the university we are trained precisely for it, I myself do not know. And while using it, I feel some kind of quiet delight. Well, in general, you understand what I began to write the parser program on.
At first, I wondered how to interact with this Word in order to somehow pull data out of there. All sorts of terrible thoughts came to mind like converting a word file into HTML with subsequent processing. But google immediately sent me on an adequate path, giving information about the VBA language. I was immediately struck by the abundance of ready-made functions, I learned what paragraphs, positions, etc., meanwhile, fucking awesome due to the complexity of the structure of the word document tree.
However, I was disappointed because I still did not understand how to turn a piece of text into a picture. At first I wanted to use something like text2png, after having pulled out the necessary piece of text. But what about formulas and pictures? There was no built-in function in VBA. At one point, a thought flashed inadvertently that it seemed like I had previously inserted excel cells in the form of pictures into the word document in the document. So it was! This was called a “special insert” and allowed to insert any part of the document as a picture. Suppose we entered into the clipboard a piece of the document, which must be saved as a picture. But how to save this picture to disk? Googling also helped find a solution. The code section below saves the contents of the clipboard to disk as a universal EMF vector file.
#include
void clipboardDataToEmfFile(QString fileName){
OpenClipboard(0);
GetEnhMetaFileBits((HENHMETAFILE)GetClipboardData(14),0,0);
HENHMETAFILE returnValue = CopyEnhMetaFileA((HENHMETAFILE)GetClipboardData(14),
QDir::toNativeSeparators(fileName).toStdString().c_str());
EmptyClipboard();
CloseClipboard();
DeleteEnhMetaFile(returnValue);
}
Excellent. However, what kind of beast is this EMF? It was necessary to turn it into PNG. I started looking for image converters. After going through a bunch, I did not find an adequate one. And here again (does anyone believe in intuition?) Some tricked-out image viewer that I put in the school years from the disc with Golden Software for fun, began to come to my mind. But like it was not a converter. However, it was necessary to make sure. Some sort of “Ifran” or “Irfan” was spinning in my head, in general, the program was found. Free, with batch image processing function, supports command line! And most importantly, it supports EMF. That was what we needed. The IrfanView executable file with the necessary DLLs and the parameters ini-file is in the same folder with the compiled program (I hope this does not violate the license) and is used through the function like this.
void convertEmfsToPng(QString inFolder, QString outFolder){
QProcess proc;
QString exeStr = "\"" + QDir::toNativeSeparators(QDir::currentPath()+"/i_view32.exe") + "\"";
QString inFilesStr = "\"" + QDir::toNativeSeparators(inFolder + "*.emf") + "\"";
QString outFilesStr = "\"" + QDir::toNativeSeparators(outFolder + "*.png") + "\"";
QString iniFolderStr = "\"" + QDir::toNativeSeparators(QDir::currentPath()) + "\"";
proc.start(exeStr + " " + inFilesStr + " /advancedbatch /ini=" + iniFolderStr + " /convert=" + outFilesStr);
proc.waitForFinished(30*60*1000);
}
Now it remains to copy the necessary pieces from the word document to the buffer. To do this, you need to come up with an algorithm for breaking the source text into separate blocks with a task, with answers, with the number of the correct answer and the level of complexity.
The first attempt at implementation was as follows. We take the source document, replace the text of the form ([1-5]) \) with \ n $ 1 \) in it, i.e. before the beginning of each answer, add a newline. On VBA, replacement strings are written differently, I don’t remember. Now in the document settings we set the page width to maximum, and reduce the font for the entire document. As a result, it turns out that in the document each task will occupy exactly 8 lines, moreover:
- line 8 * i is the text with the number of the correct answer and the level of difficulty
- line 8 * i + 1 is the task
- line 8 * i + 2 is the answer option No. 1
- ...
- line 8 * i + 6 is a variant of answer No. 5
- line 8 * i + 7 - empty
Reapply What Jobs Look Like
Now, after this processing, there is nothing left but to go through the array of the collection of document lines, starting counter i, and depending on i% 8, save the picture of the task / answers or retrieve the number of the correct answer with the level of complexity.
But that did not fit. The long assignments are to blame, which, being written on one line, look terrible, shallow and do not always fit. In addition, sometimes replacing the text “1)” affects places other than response numbers. Saddened by the result, I again began to think about what could be done in this case. And then I remembered about finite state machines. I remembered the state, remembered the character input. Recalled the parser. Perhaps this was an obvious solution to others, but as a person far from complex algorithms, I was extremely happy with my idea.
Now it’s time to write and try the parser code based on the state machine. We have 7 states:
- reading space between jobs, starts with an empty line
- reading the line with the job number, in which the number of the correct answer and the level of difficulty, begins with "Number"
- reading the text of the task, begins with the "Task"
- reading the text of the answer No. 1, begins with “Answers: 1).”
- reading the text of the answer No. 2, begins with "2)."
- ...
- reading the text of the answer No. 5, begins with "5)."
We implement using the conditions for the beginning of the next state. After testing the first version of the parser, everything went great. Pictures were obtained as in the word document itself, beautifully, large. But here ... From time to time, jambs appeared, for example, in one picture an extra piece was captured until the next block of the task. So the parser incorrectly recognized. What is the matter? Everything turned out to be simple - tasks in a word document were typed manually and therefore there was a human factor, for example:
- instead of "Task" was written "Task"
- instead of "Answers" was written "Answer"
- instead of “1).” it was written "1)." or “1).” or “1).”
It was a nightmare. Fortunately, the main mistakes were in writing the numbers of tasks; they were somehow taken into account by the parser. The remaining errors after extracting the images were detected by a quick look at the largest and smallest in size images, followed by correction and re-extraction.
The final piece of the parser is the code below. He is terrible, please do not judge strictly. To store VBA objects, a QAxObject is used.
Explanation of variable names, state of the machine, additional functions used
- status - state of the machine:
- -3 - between tasks
- -2 - inside the job number
- -1 - inside the task
- 0 - after the word Answers
- 1 - inside answer 1
- 2 - inside answer 2
- 3 - inside answer 3
- 4 - inside answer 4
- 5 - inside answer 5
- startind - position of the beginning of the current block (task, answer, line with the number of the correct answer and difficulty level)
- n - serial number of the task
- nstr - job sequence number string with leading zeros up to three-digit
- str - string of the current block to the current position
- lineStart, lineEnd - position numbers of the beginning and end of the current paragraph
- lines - object of the paragraph collection of the document
- tline - object of the current paragraph
- line - Range object of the current paragraph
- ipar - current paragraph number
- tmpObj - Range object of the current character
- currChar - current character
- outdir - path line of the output picture folder
- getAnswerLine (QString) function - returns a string of two numbers: difficulty level (1-3) and the number of the correct answer (1-5), for example 24 - this is a task with difficulty level B and the correct answer under number 4
- rangeToEmfFile function (QString fname, int start, int end, QAxObject * activeDoc) - saves a piece of the document between the start and end positions of the activeDoc document as an EMF file with the name fname
Awful, long code.
QAxObject *activeDoc = wordApp->querySubObject("ActiveDocument");
int status = -3;
int startind = 0;
int n=0;
QString nstr;
QString str = "";
int lineStart, lineEnd;
QAxObject *lines = activeDoc->querySubObject("Paragraphs");
if (onlyAsnwers)
for (int ipar = 1; ipar <= lines->property("Count").toInt(); ipar++){
QAxObject *tline = lines->querySubObject("Item(QVariant)", ipar);
QAxObject *line = tline->querySubObject("Range");
QString str = line->property("Text").toString();
line->clear(); delete line;
tline->clear(); delete tline;
int ind = str.indexOf("Номер:");
if (ind != -1){
str = str.mid(ind+6);
answersTxt << getAnswerLine(str);
}
}
else
for (int ipar = 1; ipar <= lines->property("Count").toInt(); ipar++){
QAxObject *tline = lines->querySubObject("Item(QVariant)", ipar);
QAxObject *line = tline->querySubObject("Range");
lineStart = line->property("Start").toInt();
lineEnd = line->property("End").toInt();
line->clear(); delete line;
tline->clear(); delete tline;
str = "";
for (int j=lineStart; jquerySubObject("Range(QVariant,QVariant)", j, j+1);
QString currChar = tmpObj->property("Text").toString();
tmpObj->clear(); delete tmpObj;
str += currChar;
switch (status){
case -3:
if (j>=4 && str.right(5) == "Номер"){
status = -2;
startind = j+1;
}
break;
case -2:
if (str.right(6) == "Задача"){
n++; nstr = QString::number(n); while (nstr.length() < 3) nstr = "0" + nstr;
status = -1;
QAxObject *tmpObj = activeDoc->querySubObject("Range(QVariant,QVariant)", startind, j-6);
QString tmp = tmpObj->property("Text").toString();
tmpObj->clear(); delete tmpObj;
answersTxt << getAnswerLine(tmp);
startind = j+2;
} else if (str.right(7) == "Задание"){
n++; nstr = QString::number(n); while (nstr.length() < 3) nstr = "0" + nstr;
status = -1;
QAxObject *tmpObj = activeDoc->querySubObject("Range(QVariant,QVariant)", startind, j-7);
QString tmp = tmpObj->property("Text").toString();
tmpObj->clear(); delete tmpObj;
answersTxt << getAnswerLine(tmp);
startind = j+2;
}
break;
case -1:
if (str.right(7) == "Ответы:"){
status = 0;
rangeToEmfFile(outdir+nstr+".emf", startind, j-7, activeDoc);
startind = j+1;
} else if (str.right(6) == "Ответ:"){
status = 0;
rangeToEmfFile(outdir+nstr+".emf", startind, j-6, activeDoc);
startind = j+1;
}
break;
case 0:
if (str.right(2) == "1)" || str.right(3) == "1 )"){
status = 1;
startind = j+2;
}
break;
case 1:
if (str.right(2) == "2)"){
rangeToEmfFile(outdir+nstr+".1.emf", startind, j-2, activeDoc);
status = 2;
startind = j+2;
} else if (str.right(3) == "2 )"){
rangeToEmfFile(outdir+nstr+".1.emf", startind, j-3, activeDoc);
status = 2;
startind = j+2;
}
break;
case 2:
if (str.right(2) == "3)"){
rangeToEmfFile(outdir+nstr+".2.emf", startind, j-2, activeDoc);
status = 3;
startind = j+2;
} else if (str.right(3) == "3 )"){
rangeToEmfFile(outdir+nstr+".2.emf", startind, j-3, activeDoc);
status = 3;
startind = j+2;
}
break;
case 3:
if (str.right(2) == "4)"){
rangeToEmfFile(outdir+nstr+".3.emf", startind, j-2, activeDoc);
status = 4;
startind = j+2;
} else if (str.right(3) == "4 )"){
rangeToEmfFile(outdir+nstr+".3.emf", startind, j-3, activeDoc);
status = 4;
startind = j+2;
}
break;
case 4:
if (str.right(2) == "5)"){
rangeToEmfFile(outdir+nstr+".4.emf", startind, j-2, activeDoc);
status = 5;
startind = j+2;
} else if (str.right(3) == "5 )"){
rangeToEmfFile(outdir+nstr+".4.emf", startind, j-3, activeDoc);
status = 5;
startind = j+2;
}
break;
case 5:
if (j>=4 && str.right(5) == "Номер"){
rangeToEmfFile(outdir+nstr+".5.emf", startind, j-5, activeDoc);
status = -2;
str = "Номер";
} else if (lineEnd-lineStart < 2){
rangeToEmfFile(outdir+nstr+".5.emf", startind, j, activeDoc);
status = -3;
}
break;
}
}
if (status == 5)
rangeToEmfFile(outdir+nstr+".5.emf", startind, lineEnd, activeDoc);
}
lines->clear(); delete lines;
activeDoc->clear(); delete activeDoc;
The logic of the above code is slightly different from that described above. She also uses paragraph breaks. But this does not greatly change the main idea.
In this way, it turned out to “defeat” this Word!
Conclusion
As a result, all tasks in the amount of ~ 4 thousand were extracted. The necessary parser shell was written. A program for uploading and administering tasks to a remote database has also been written. The fee was received, her diploma is protected perfectly, mine is also protected perfectly.
Thank you for your attention, I hope this post will help someone in a similar problem. Or maybe someone knows a better implementation?
Update:
A couple of pictures of the result


