Salesforce Data Migration with Pentaho Data Integration
Hi, Habr.
My name is Ilya Grebtsov, I work Java / JS Developer in DataArt. I want to share something useful with those who work with Salesforce.
In Salesforce, the task often arises of massively creating / changing / deleting a group of related records in several objects, analogs of tables in a relational database. For example, frequently used standard objects are Account (information about the client’s company), Contact (information about the client himself). The problem is that when you save the Contact record, you must specify the Id of the associated Account record, that is, the account must exist at the time of adding the contact record.
In reality, communications can be even more complicated, for example, an Opportunity object refers to both Account and Contact. Plus, links to any non-standard (custom) objects are possible. In any case, a record by reference must be created before the record that refers to it.
Consider solutions to this problem:
You need to prepare the APEX script, then run it in the Salesforce Developer Console. In the script, related objects are populated sequentially. In the example below, the test account Account is inserted, then Contact. When inserting Contact, the Id of the Account record is used, obtained after inserting Account.
Pros:
Minuses:
Thus, the method is only suitable for small, simple manual changes.
When you need to make changes to many records that are already inside Salesforce, you can use Batch APEX. Unlike the previous one, this method allows you to process up to 10,000 records, according to Salesforce Limits. Batch is a custom class inherited from Database.Batchable, written in APEX.
You can run the class manually from the Developer Console:
Or create a Job, with which the process starts at a certain time.
Thus, the method is suitable for large-scale data changes within Salesforce, but it is very laborious. When deploying from sandbox to a productive class, like any other APEX code, it must be covered by a unit test.
Data Loader is a standard Salesforce utility installed locally. Allows you to process up to 5 million records. Migrating with Data Loader is the best practise and most popular method for handling a large number of records. Unloading / loading records is carried out using the Salesforce API.
The utility allows you to select an object in Salesforce and export data to a CSV file. Alternatively, upload an object from CSV to Salesforce.
Processing existing data in Salesforce is as follows:
Point 2 here is a bottleneck not implemented by Data Loader itself. It is necessary to create third-party procedures for processing CSV files.
As an example, to insert multiple contact entries, the data should go to the associated Account and Contact. The action algorithm should be as follows:
Thus, the method is suitable for large-scale data changes both within Salesforce and using external data. But it is very laborious, especially if modification of the records is necessary.
Pentaho Data Integration also known as Kettle is a universal ETL utility. It is not a specialized Salesforce utility. The set includes Salesforce Input- and Output-connection methods, which allows you to transparently process Salesforce data as data from other sources: relational databases, SAP, XML files, CSV and others.
With Salesforce, the utility works through the Salesforce API, so it is possible to process up to 5 million records, as with Data Loader. Only in a more convenient way.
The main distinguishing feature is the graphical interface. The whole transformation is divided into separate simple steps: read data, sort, join, write data. Steps are displayed in the form of icons, between which arrows are drawn. Thus, it is clearly seen where it comes from and where it comes from.
There are at least two versions of the utility: paid with guaranteed support and free. The free Community Edition (Apache License v2.0) can be downloaded at http://community.pentaho.com/ .
Transformation development in the simplest case does not require programming skills. But if you wish, you can use steps that include routines written in Java or JavaScript.
Features of data migration using Pentaho Data Integration should be covered in more detail. Here I will describe my experience and difficulties that I encountered.
Connection parameters for Salesforce should be specified in the Transformation Properties parameters. Once made, the settings will be available in all steps, where necessary, in the form of variables.
I recommend specifying:
For security reasons, you can leave the username and password fields empty, in which case Data Integration will request them when starting the transformation.
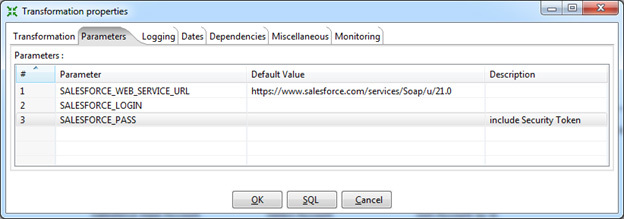
Data is sampled by the Salesforce Input step. In the settings of this step, you need to specify the connection parameters, in this case the variables created earlier are used. Also select an object and a list of fields to select, or specify a specific query using the SOQL query language (similar to the SQL query language used in relational databases).
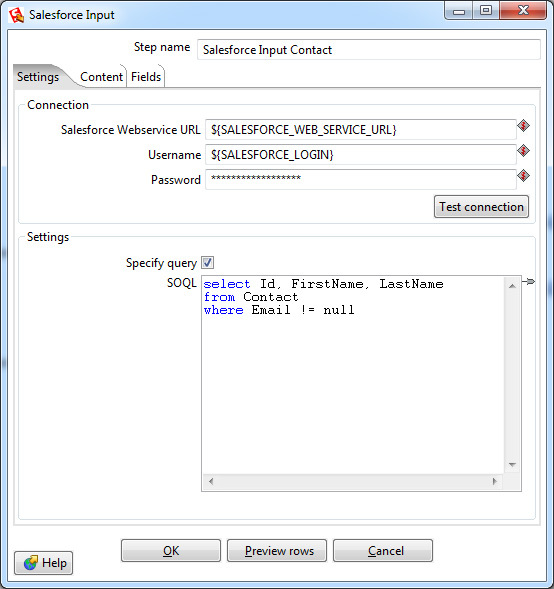
Data is inserted using one of several Output steps:
It is also possible to delete entries using
As in the Input step, you must specify the connection parameters, in this case, transformation variables are used. There is also a more fine-tuning - the parameters of the time out-connection, after which the transformation will fail. And the Salesforce-specific Batch Size parameter is the number of records transferred in one transaction. Increasing the Batch Size slightly increases the speed of the transformation, but can not be more than 200 (according to the restrictions of Salesforce). In addition, if there are triggers that provide additional data processing after insertion, unstable operation with a large Batch Size value is possible. The default value is 10.
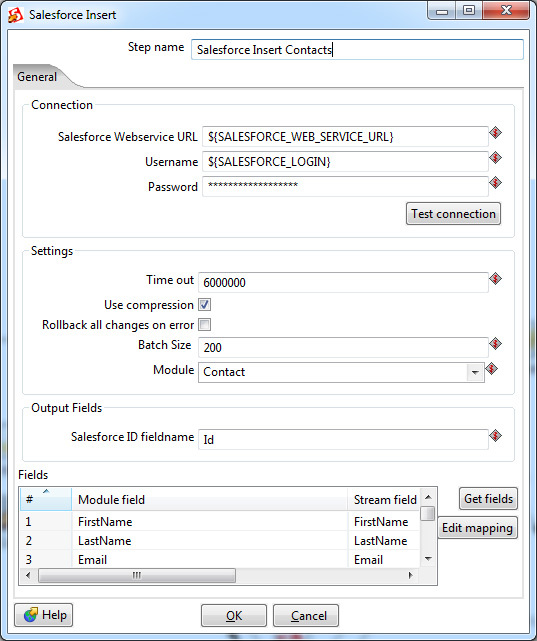
These two steps fully cover the capabilities of the Data Loader utility. All that is in between is the logic of data processing. And it can be implemented directly in Pentaho Data Integration.
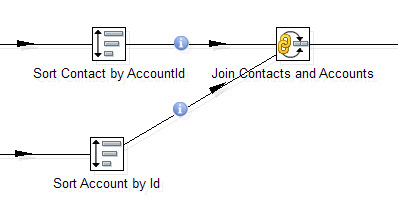
For example, one of the most requested steps is to join two data streams. The same join from SQL that is so lacking in SOQL. Here he is.
In the settings it is possible to select the type: Inner, Left Outer, Right Outer, Full Outer - and specify connection keys.
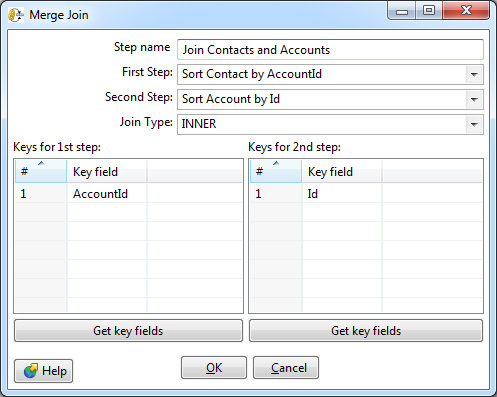
Mandatory requirement - the input for this step should be sorted by key fields. Data Integration uses a separate Sorter step for this.
Sorting is performed in RAM, however, it is possible that it will not be enough and the data will be saved in an intermediate file to disk. Most sorter settings are associated with this particular case. Ideally, you should avoid swap to disk: it is ten times slower than sorting in memory. To do this, you need to adjust the Sort size parameter - specify the upper limit of the number of lines that theoretically can pass through the sorter.
Also in the settings you can select one or more key fields by which sorting will be performed in ascending or descending order of values. If the field type is string, it makes sense to specify case sensitivity. The Presorted parameter indicates that the rows are already sorted by this field.
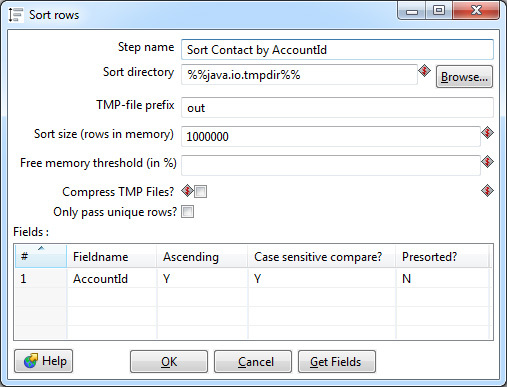
Join and Sorter form a bunch that occurs in almost every transformation.
Sorts and joins have the greatest effect on transformation performance. Extra sorting should be avoided if the data has already been sorted a few steps earlier and their order has not changed afterwards. But you need to be careful: if the data arrives unsorted in Join, Data Integration will not stop working and will not show an error, just the result will be incorrect.
As key fields you should always choose a short field. Data Integration allows you to select several key fields for sorting and joining, but the processing speed is significantly reduced. As a workaround, it is better to generate a surrogate key, as a result there will be only one field for the connection. In the simplest case, a surrogate key can be obtained by concatenating strings. For example, for joining in FirstName fields, LastName is better to join in FirstName + '' + LastName. If we go further, a hash (md5, sha2) can be calculated from the resulting string. Unfortunately, in Data Integration there is no built-in step for calculating the hash of a string; you can write it yourself using the User Defined Java Class.
In addition to the steps above, Data Integration includes many more. These are filters, switch, union, steps for processing strings, lookups for relational tables and web services. And many others. As well as two universal steps that allow you to execute code in Java or JavaScript. I will not dwell on them in detail.
An unpleasant feature of Data Integration's work with Salesforce is the slow speed of inserting records through the Salesforce API. About 50 records per second (as with the standard Data Loader, accessing the web service in itself is a slow operation), which makes it difficult to process thousands of lines. Fortunately, with Data Integration, you can insert into multiple threads. There is no standard solution, here is what I could come up with:
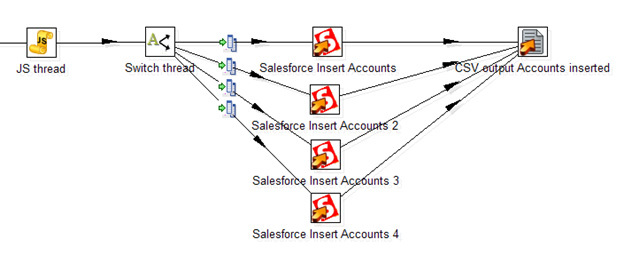
Here the JavaScript procedure generates a random stream number. Next, the Switch step distributes the threads according to its number. Four separate steps of Salesforce Insert insert records, thus increasing the total flow rate to 200 records per second. Ultimately, all inserted records with a filled ID field are saved in a CSV file.
Using parallel insertion, you can slightly speed up data processing. But flowing infinitely will not work: according to the limits of Salesforce, there can be no more than 25 open connections from one user.
The resulting transformation can be immediately started on the local machine. Mileage progress is displayed in Step Metrics. Here you can see which steps work, how many records were read at this step and passed on. As well as the speed of processing records at a specific step, which makes it easy to find the “bottleneck” of the transformation.

For regular conversions, Data Integration allows you to create a Job that runs on a condition or schedule on a local machine or dedicated server.
Thanks for attention. I hope Salesforce-developers will take such a useful tool into service.
My name is Ilya Grebtsov, I work Java / JS Developer in DataArt. I want to share something useful with those who work with Salesforce.
In Salesforce, the task often arises of massively creating / changing / deleting a group of related records in several objects, analogs of tables in a relational database. For example, frequently used standard objects are Account (information about the client’s company), Contact (information about the client himself). The problem is that when you save the Contact record, you must specify the Id of the associated Account record, that is, the account must exist at the time of adding the contact record.
In reality, communications can be even more complicated, for example, an Opportunity object refers to both Account and Contact. Plus, links to any non-standard (custom) objects are possible. In any case, a record by reference must be created before the record that refers to it.
Consider solutions to this problem:
Anonymous apex
You need to prepare the APEX script, then run it in the Salesforce Developer Console. In the script, related objects are populated sequentially. In the example below, the test account Account is inserted, then Contact. When inserting Contact, the Id of the Account record is used, obtained after inserting Account.
Account [] accounts;
accounts.add (new Account (
Name = 'test'
));
insert accounts;
Contact [] contacts;
contacts.add (new Contact (
AccountId = accounts [0] .Id,
FirstName = 'test',
LastName = 'test'
));
insert contacts;
Pros:
- The Developer Console is always at hand, nothing additional to install and configure is required.
- The script is written in APEX, which is close to Salesforce developers.
- Simple logic is easy to implement.
Minuses:
- Salesforce Limits allow up to 200 entries to be modified in this way.
- It’s hard to implement complex logic.
- The method is not suitable for data migration from outside Salesforce, all data must already be loaded.
Thus, the method is only suitable for small, simple manual changes.
Batch apex
When you need to make changes to many records that are already inside Salesforce, you can use Batch APEX. Unlike the previous one, this method allows you to process up to 10,000 records, according to Salesforce Limits. Batch is a custom class inherited from Database.Batchable, written in APEX.
You can run the class manually from the Developer Console:
Database.Batchablebatch = new myBatchClass ();
Database.executeBatch (batch);
Or create a Job, with which the process starts at a certain time.
Thus, the method is suitable for large-scale data changes within Salesforce, but it is very laborious. When deploying from sandbox to a productive class, like any other APEX code, it must be covered by a unit test.
Data loader
Data Loader is a standard Salesforce utility installed locally. Allows you to process up to 5 million records. Migrating with Data Loader is the best practise and most popular method for handling a large number of records. Unloading / loading records is carried out using the Salesforce API.
The utility allows you to select an object in Salesforce and export data to a CSV file. Alternatively, upload an object from CSV to Salesforce.
Processing existing data in Salesforce is as follows:
- Upload necessary data from Salesforce to CSV files.
- Change data in CSV files.
- Loading data into Salesforce from CSV files.
Point 2 here is a bottleneck not implemented by Data Loader itself. It is necessary to create third-party procedures for processing CSV files.
As an example, to insert multiple contact entries, the data should go to the associated Account and Contact. The action algorithm should be as follows:
- Prepare a CSV file with a list of new Account entries. Download to Salesforce using Data Loader. The result will be a list of Account IDs.
- Prepare a CSV file with a list of new Contact entries. In it, in the AccountId field, you must specify the ID from the list obtained in the 1st step. This can be done manually, or use any programming language.
- Download the obtained CSV with the Contacts list to Salesforce.
Thus, the method is suitable for large-scale data changes both within Salesforce and using external data. But it is very laborious, especially if modification of the records is necessary.
Pentaho Data Integration
Pentaho Data Integration also known as Kettle is a universal ETL utility. It is not a specialized Salesforce utility. The set includes Salesforce Input- and Output-connection methods, which allows you to transparently process Salesforce data as data from other sources: relational databases, SAP, XML files, CSV and others.
With Salesforce, the utility works through the Salesforce API, so it is possible to process up to 5 million records, as with Data Loader. Only in a more convenient way.
The main distinguishing feature is the graphical interface. The whole transformation is divided into separate simple steps: read data, sort, join, write data. Steps are displayed in the form of icons, between which arrows are drawn. Thus, it is clearly seen where it comes from and where it comes from.
There are at least two versions of the utility: paid with guaranteed support and free. The free Community Edition (Apache License v2.0) can be downloaded at http://community.pentaho.com/ .
Transformation development in the simplest case does not require programming skills. But if you wish, you can use steps that include routines written in Java or JavaScript.
Features of data migration using Pentaho Data Integration should be covered in more detail. Here I will describe my experience and difficulties that I encountered.
Connection parameters for Salesforce should be specified in the Transformation Properties parameters. Once made, the settings will be available in all steps, where necessary, in the form of variables.
I recommend specifying:
- URL to connect to Salesforce.
For the product, including Salesforce Developer Edition: https://www.salesforce.com/services/Soap/u/21.0
For test environments (sandbox): https://test.salesforce.com/services/Soap/u/21.0
Version The API (in this case 21.0) is modified as necessary. - Login. The user must have sufficient permissions to connect through the API. Ideally, this should be a System Administrator.
- Password. Importantly, in addition to the password itself, you must specify Security Token.
For security reasons, you can leave the username and password fields empty, in which case Data Integration will request them when starting the transformation.
Data is sampled by the Salesforce Input step. In the settings of this step, you need to specify the connection parameters, in this case the variables created earlier are used. Also select an object and a list of fields to select, or specify a specific query using the SOQL query language (similar to the SQL query language used in relational databases).
Data is inserted using one of several Output steps:
- Salesforce insert
- Salesforce update
- Salesforce Upsert (combines insert and update: if there is a record, it will be updated, otherwise a new one will be inserted)
It is also possible to delete entries using
- Salesforce Delete.
As in the Input step, you must specify the connection parameters, in this case, transformation variables are used. There is also a more fine-tuning - the parameters of the time out-connection, after which the transformation will fail. And the Salesforce-specific Batch Size parameter is the number of records transferred in one transaction. Increasing the Batch Size slightly increases the speed of the transformation, but can not be more than 200 (according to the restrictions of Salesforce). In addition, if there are triggers that provide additional data processing after insertion, unstable operation with a large Batch Size value is possible. The default value is 10.
These two steps fully cover the capabilities of the Data Loader utility. All that is in between is the logic of data processing. And it can be implemented directly in Pentaho Data Integration.
For example, one of the most requested steps is to join two data streams. The same join from SQL that is so lacking in SOQL. Here he is.
In the settings it is possible to select the type: Inner, Left Outer, Right Outer, Full Outer - and specify connection keys.
Mandatory requirement - the input for this step should be sorted by key fields. Data Integration uses a separate Sorter step for this.
Sorting is performed in RAM, however, it is possible that it will not be enough and the data will be saved in an intermediate file to disk. Most sorter settings are associated with this particular case. Ideally, you should avoid swap to disk: it is ten times slower than sorting in memory. To do this, you need to adjust the Sort size parameter - specify the upper limit of the number of lines that theoretically can pass through the sorter.
Also in the settings you can select one or more key fields by which sorting will be performed in ascending or descending order of values. If the field type is string, it makes sense to specify case sensitivity. The Presorted parameter indicates that the rows are already sorted by this field.
Join and Sorter form a bunch that occurs in almost every transformation.
Sorts and joins have the greatest effect on transformation performance. Extra sorting should be avoided if the data has already been sorted a few steps earlier and their order has not changed afterwards. But you need to be careful: if the data arrives unsorted in Join, Data Integration will not stop working and will not show an error, just the result will be incorrect.
As key fields you should always choose a short field. Data Integration allows you to select several key fields for sorting and joining, but the processing speed is significantly reduced. As a workaround, it is better to generate a surrogate key, as a result there will be only one field for the connection. In the simplest case, a surrogate key can be obtained by concatenating strings. For example, for joining in FirstName fields, LastName is better to join in FirstName + '' + LastName. If we go further, a hash (md5, sha2) can be calculated from the resulting string. Unfortunately, in Data Integration there is no built-in step for calculating the hash of a string; you can write it yourself using the User Defined Java Class.
In addition to the steps above, Data Integration includes many more. These are filters, switch, union, steps for processing strings, lookups for relational tables and web services. And many others. As well as two universal steps that allow you to execute code in Java or JavaScript. I will not dwell on them in detail.
An unpleasant feature of Data Integration's work with Salesforce is the slow speed of inserting records through the Salesforce API. About 50 records per second (as with the standard Data Loader, accessing the web service in itself is a slow operation), which makes it difficult to process thousands of lines. Fortunately, with Data Integration, you can insert into multiple threads. There is no standard solution, here is what I could come up with:
Here the JavaScript procedure generates a random stream number. Next, the Switch step distributes the threads according to its number. Four separate steps of Salesforce Insert insert records, thus increasing the total flow rate to 200 records per second. Ultimately, all inserted records with a filled ID field are saved in a CSV file.
Using parallel insertion, you can slightly speed up data processing. But flowing infinitely will not work: according to the limits of Salesforce, there can be no more than 25 open connections from one user.
The resulting transformation can be immediately started on the local machine. Mileage progress is displayed in Step Metrics. Here you can see which steps work, how many records were read at this step and passed on. As well as the speed of processing records at a specific step, which makes it easy to find the “bottleneck” of the transformation.
For regular conversions, Data Integration allows you to create a Job that runs on a condition or schedule on a local machine or dedicated server.
Thanks for attention. I hope Salesforce-developers will take such a useful tool into service.