Internet keepers
- Transfer
“Some people call us" Plyushins "- I like to say that we are archivists."
Director Wayback Machine Mark Graham outlined the scale of the beloved archive

View the Wayback Machine at the Online News Association 2018
Austin, TX conference . No matter how much the subscriber services would like to convince you of this, but not everything can be found on Amazon or Netflix. Want, for example, to read the book of Judge Brett Cavanaugh (or even their notorious yearbook )? Curious to see a bunch of vintage advertising posters with smoking ? How about viewing the largest collection of Tibetan Buddhist literature in the world ? Today there is one place where you can do all this, and this is not Google or some pirated sites that you probably (often) visit.
“I have a government video on how to wash hands or prepare for a nuclear war ,” said Mark Graham, director of the Wayback Machine on the Internet Archive. "We could easily make a list of .ppt files on all sites with the domain .mil, Military Industrial PowerPoint Complex."
Graham recently spoke with several small groups of participants at the Online News Association 2018 conference and Ars Technica was lucky to be there. Later he made a full presentation of the conference, which is now available in audio format . And the basic idea is that the scale of the Internet Archive today can be as difficult to understand as the scale of the Internet itself.
The non-commercial physical space is still easy to understand, at least as Graham intended it. Today, all the activities of the Internet Archive are conducted from one old church (even the benches were not removed) in San Francisco with about two hundred people. The archive also contains the nearest warehouse for storing physical media, not only books, but also such things as vinyl records. Graham jokes that the basic unit of measurement is the “delivery container”. The archive receives this amount of material every two weeks.
The company is currently the second largest book scanner in the world, after Google. Graham ensured that the current amount of scans totaled over four million. The archive even has a wish list for its next 1.5 million scans, including everything cited on Wikipedia. Wayback Machine is trying to protect you from the fact that a 404 error will jump out during the transition on Wikipedia links (Graham recently told the BBC that Wayback bots recovered nearly six million pages lost due to link failures for this). Today, books published before 1923 can be downloaded for free via the Internet Archive, and you can later borrow a digital copy of many of these books.
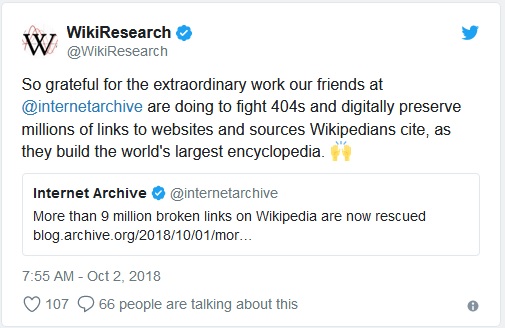
Translation tweet:
of Internet the Archive: More than 9 million incorrect references in Wikipedia corrected
WikiResearch: So grateful for the extraordinary work being done by our friends at @internetarchive to counter 404 and digitally preserve millions of links to websites and sources that cite vikipediane, because they create the world's largest encyclopedia.
Of course, these days the Internet Archive offers much more than just text. His collection of news covers more than 1.6 million news programs with tools such as the ability to search for words in credits and access to the latest news (broadcasts become available 24 hours later and are provided to visitors in the form of two-minute passages with searchability). The growing audio and music content of the Internet Archive covers radio news, podcasting and physical media (for example, a collection of 200,000 copies from 78s recently donated by the Boston library). And, according to Ars, the organization boasts an extensive classic collection of video gameswhich anyone can upload to a browser-based emulator for research or leisure. Officially, this section includes about 300,000+ titles, “so you can actually play Oregon Trail on the old Apple C computer in the browser right now - there are no ads, no user tracking,” says Graham.
“Some may call us" Plyushkina "," he says. "I like to say that we are archivists."
In general, Graham says that four petabytes of information per year is added to the Internet Archive (four million gigabytes for the context). The current organization’s data is 22 petabytes, but the Internet Archive actually owns 44 petabytes. “Because we are paranoid,” Graham says. "Machines can fail, and we have a reputation." This credo in the spirit of NASA helped a non-profit organization survive the damage caused by fire, which cost almost $ 600,000 — all without losing historical data.
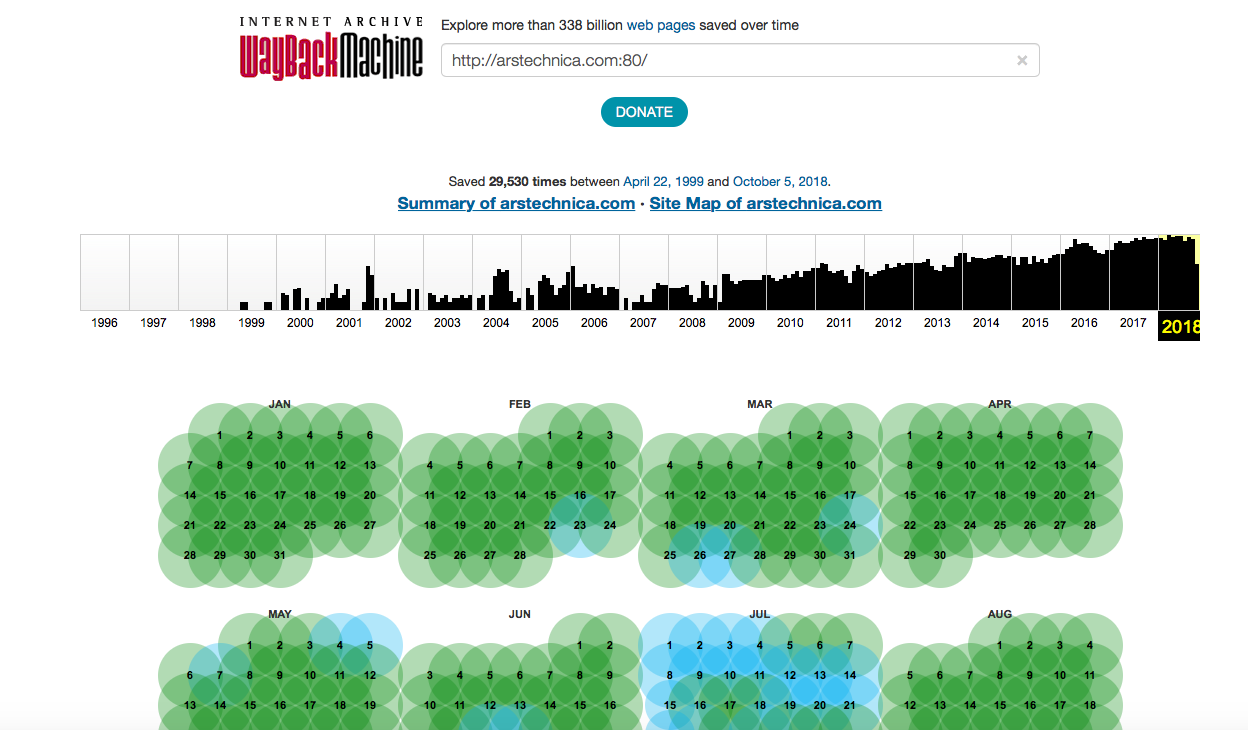
30,000 input data? Not bad, and it seems that the Wayback Machine bots have certainly increased their attachment to Ars.
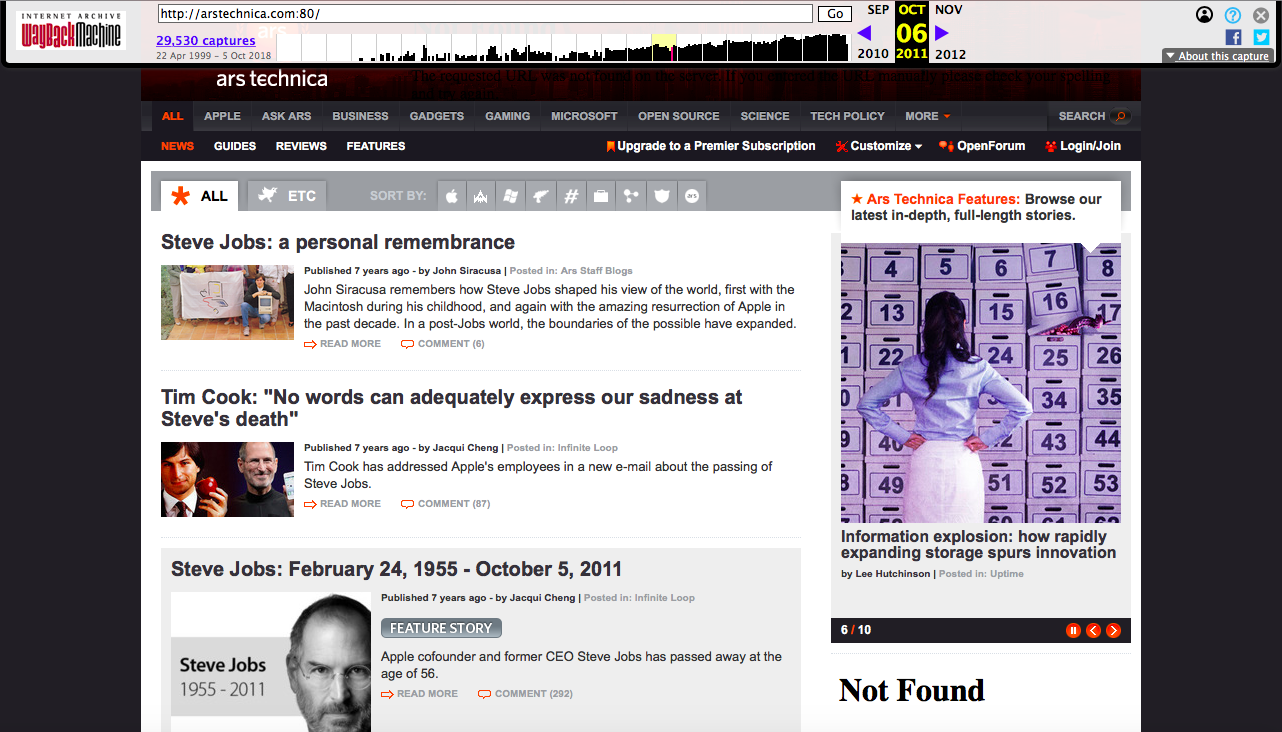
With the help of the Wayback Machine you can remember and think about how Ars hid the death of Steve Jobs back in October 2011.
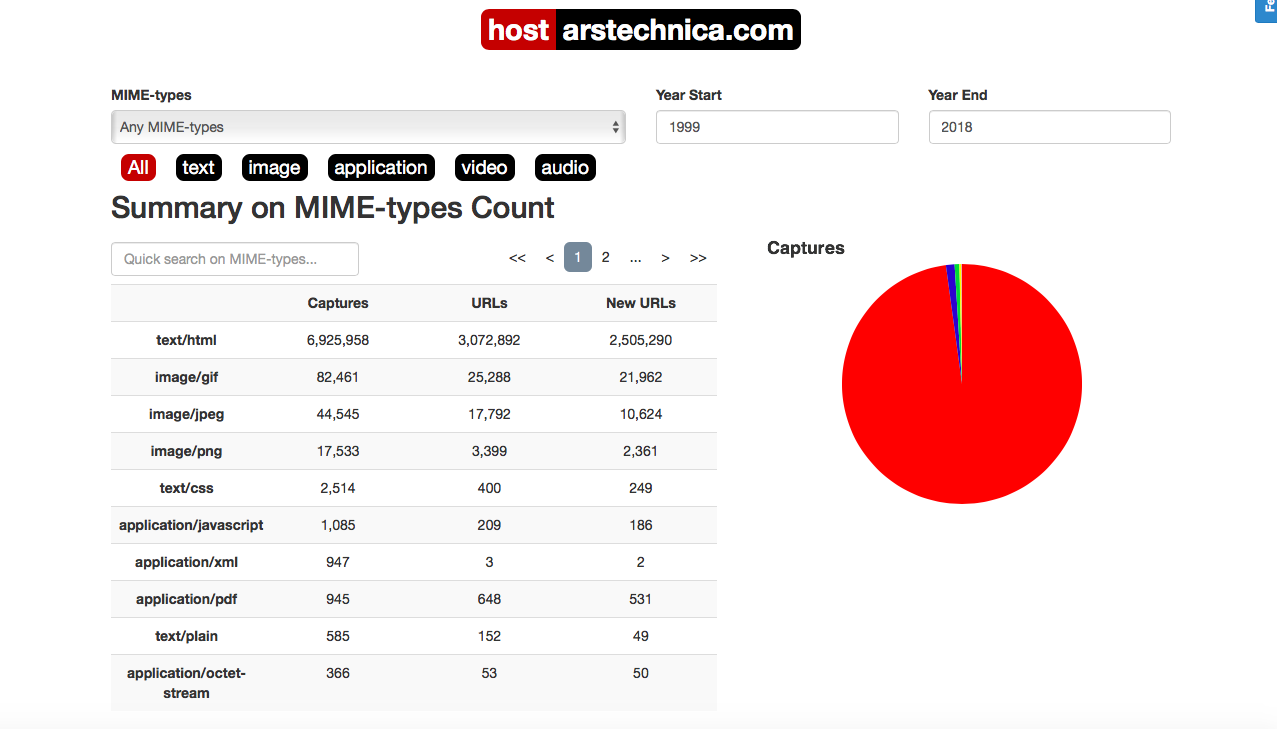
Hmm ... maybe I still have a chance to become Arsian / Arsianin to download the 1000th PDF file captured by the Internet Archive.
Universal access to knowledge (and to facts, to a huge amount of facts)
The overall concept of the Internet Archive over the past 22 years has been simple: “universal access to all knowledge” . In the era of the Internet, this means, of course, the introduction of a small army of bots, and Graham notes that in the Internet Archive there is always software collecting content. Approximately 7,000 simultaneous processes cover the entire network in order to ultimately receive 1.5 billion different things per week. Some things, such as the Google or The New York Times home pages, can be viewed many times a day; others can be viewed less frequently.
“We’re trying to get everything, but it’s hard,” Graham notes. “Embeds, Javascripts, interactive applications — we cannot get some of these materials, but we are working on it.”
The cache memory of the things we are working on includes ephemeral media such as Snapchat or public Telegram groups, and the Wayback Machine maintains local contacts in places where some media archives or servers may be at risk (recently Graham says partners in Egypt, for example).
The result of all this is that the Wayback Machine has evolved into something much more rewarding than just past fun trips to LiveJournals. Ars has used it many times for different purposes, ranging from intercepting changes in Comcast's net neutrality , ending with the fact that Defense Distributed's organizational description has evolved. And Graham points to the recent controversy of 2018.when President Trump tweeted that Google does not promote good visibility for the United States of America on its homepage (as it was in the past). Before Google could respond to this, the company turned to the Internet Archive with a simple question - is there a copy?
“I love Google, but their job is not to make copies of the home page every 10 minutes,” says Graham. "This is our job."
Graham shared information that the Wayback Machine actually captured 835 copies of the Google homepage in January 2018. “So we were able to help raise the records. We do not take sides, but we are for the truth. ”
The site played a similar role when the White House recently deleted all the archives of its bulletins , and a number of organizations (not only news, but also environmental organizations or ACLU) needed them. And materials from the Wayback Machine were used as evidence in court.. “There are many events that happen in terms of time,” he adds. As a former vice president of NBC News (hence his desire to attend ONA, perhaps), Graham also proudly points out that the site is referenced about five times a day in the media.
Graham says that in order to improve the site, the Wayback Machine is working hard to improve its user tools. On the lower left side of the main Wayback Machine homepage, you will find, for example, public APIs . Graham points out that people use them to create things like a differentiator.where you can take two scans, put side by side and see the changes. Another user-created tool that caught his attention allows you to take a look at the site and make a radial tree diagram to see how its structure changes over time .
Although perhaps the easiest and most effective tool for everyone is the technology directly from the Wayback Machine - the site allows someone to manually send a link to the Internet Archive for archiving directly from their home page. “If I walk my cat in the garden, and I see the story on Google News, you can send it to print. But today you can also send it to the Internet Archive, ”says Graham. According to his estimates, the result may be about a million shots per week.
“We search for information in a really large network without deception,” he says. And regardless of whether bots find something or a dedicated amateur user of the archive, everyone else can simply evaluate the ability to find content, which by the way is the original mission of Ars Technica . (Fortunately, 20 years later, no one has yet told us about " very bad things , such as NT, Linux and BeOS-content under the same roof.")
Translation: Diana Sheremyeva

About #philtech
#philtech (технологии + филантропия) — это открытые публично описанные технологии, выравнивающие уровень жизни максимально возможного количества людей за счёт создания прозрачных платформ для взаимодействия и доступа к данным и знаниям. И удовлетворяющие принципам филтеха:
1. Открытые и копируемые, а не конкурентно-проприетарные.
2. Построенные на принципах самоорганизации и горизонтального взаимодействия.
3. Устойчивые и перспективо-ориентированные, а не преследующие локальную выгоду.
4. Построенные на [открытых] данных, а не традициях и убеждениях
5. Ненасильственные и неманипуляционные.
6. Инклюзивные, и не работающие на одну группу людей за счёт других.
Акселератор социальных технологических стартапов PhilTech — программа интенсивного развития проектов ранних стадий, направленных на выравнивание доступа к информации, ресурсам и возможностям. Второй поток: март–июнь 2018.
Чат в Telegram
Сообщество людей, развивающих филтех-проекты или просто заинтересованных в теме технологий для социального сектора.
#philtech news
Телеграм-канал с новостями о проектах в идеологии #philtech и ссылками на полезные материалы.
Подписаться на еженедельную рассылку
1. Открытые и копируемые, а не конкурентно-проприетарные.
2. Построенные на принципах самоорганизации и горизонтального взаимодействия.
3. Устойчивые и перспективо-ориентированные, а не преследующие локальную выгоду.
4. Построенные на [открытых] данных, а не традициях и убеждениях
5. Ненасильственные и неманипуляционные.
6. Инклюзивные, и не работающие на одну группу людей за счёт других.
Акселератор социальных технологических стартапов PhilTech — программа интенсивного развития проектов ранних стадий, направленных на выравнивание доступа к информации, ресурсам и возможностям. Второй поток: март–июнь 2018.
Чат в Telegram
Сообщество людей, развивающих филтех-проекты или просто заинтересованных в теме технологий для социального сектора.
#philtech news
Телеграм-канал с новостями о проектах в идеологии #philtech и ссылками на полезные материалы.
Подписаться на еженедельную рассылку