Machine learning in navigation devices: we determine the maneuvers of the machine according to the accelerometer and gyroscope
The programs that are available to us today for car navigation are of great help to drivers. They help us navigate in unfamiliar areas and go around traffic jams. This is a great work of people from all over the world, which has made our life easier. But you can not stop there, technology is moving forward and the quality of programs should also grow.

Today, in my opinion, one of the problems with navigation devices is that they do not lead the user in bands. This problem increases travel time, traffic jams and accident rate. Recently, google maps began to display the road markings before the turn, which is already a good result, but much can be improved here. Maps don’t know in which lane the car is currently located, it’s problematic using gps tools, gps has too much error for this. If we knew the current lane, we would know the speed of the lanes and could long tell the user in an explicit form what lane and when it is better to change lane. For example, the navigator would say, “Continue to keep this lane to the intersection” or “Change to the far left lane.”
In this article we will try to tell how we are trying to determine the changes, the current lane of the car, turns, overtaking, and also other maneuvers using machine learning according to the accelerometer and gyroscope.
It is possible to recommend rebuilding, not only if the movement along the lane is slow, say, because cars are turning from the left lane. Also, it is possible to recommend rebuilding if there is an accident in the current lane. Now accidents and road problems are caused by users manually. One could make an algorithm that would put them on the map automatically, looking at the maneuvers of cars. If cars in the same place massively make a detour, then, apparently, there was some kind of problem. Knowing this, the system could alert drivers to change lanes in advance if they no longer occupy it.
Another problem associated with the rather low accuracy of gps in the yards is that it is quite difficult to determine the position of the car on the winding paths of the house adjoining territories. The position is issued with an accuracy of plus or minus 10 meters and it is unclear whether the car has already passed a turn or not. And in an unfamiliar courtyard, this is critical, because we focus on the navigator, and he essentially does not always know where we are now. If we could reliably accurately determine the rotation, we could guide the user not only by gps, but also help the positioning system with data on the turns and would know exactly where the user is.
GPS also can not immediately determine the reversal of the car. She must drive a few meters back before it becomes clear that the maneuver was completed. If we could determine the U-turn right away, then the new rebuilt route would be much faster for the user.
Rebuilding into a pocket from the main road is also a controversial issue in the case of Gps, only according to its data it is now difficult to say whether the user was rebuilt or not, especially if the pocket is not deep. If there was an algorithm that would transmit this information in an alternative way, then combining it with Gps, the accuracy could be significantly improved.
In my free time, I and several students at the Computer Science Center make an open source project to determine traffic events using an accelerometer and a gyroscope. As a result, we want to make an accessible library with an open license that will allow, receiving data from the sensors of a mobile phone or some other device to the input, to output such events as a lane change, overtaking, obstacle avoidance, turning and turning. The library user will have to implement the switch in his program and correctly react to certain events.
In principle, not only telephones can use the library, but also, say, microcontroller-based devices that monitor transport. I will say right away that we are in the middle of the road and so far there is no certainty that we will be able to determine all the events, but it seems that something can work out for us.
Events are indicated by broken vertical lines:
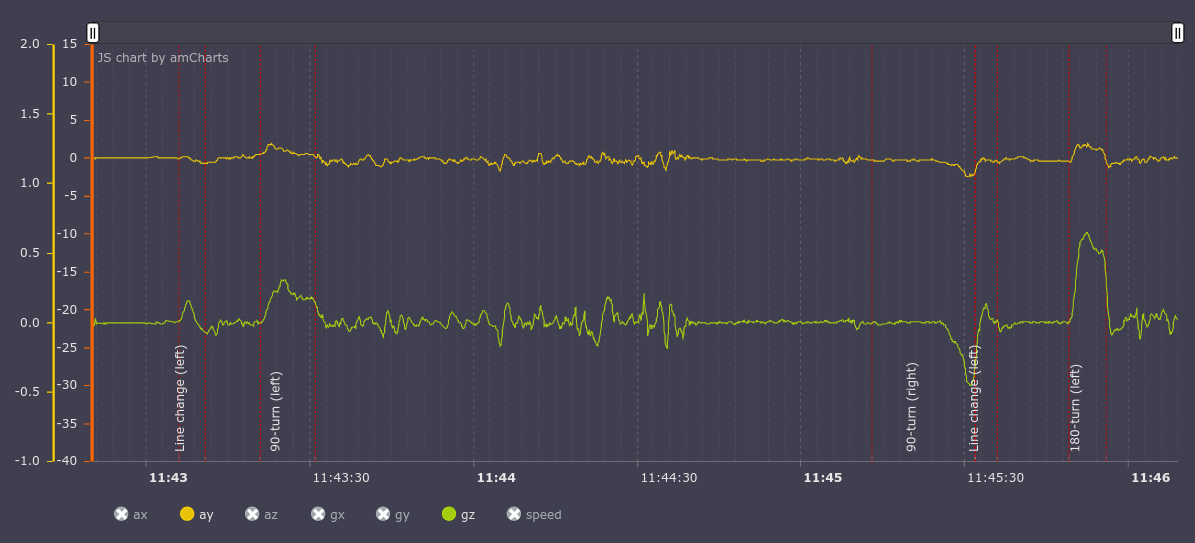
Leaving only the y axis for the accelerometer (lateral overloads, upper graph) and the z-axis of the gyroscope (machine rotation, top view, lower graph) active, you can notice how turns and turns are accompanied by increased lateral overloads and increasing rotation around the axis Z. When rebuilding, the gyroscope and accelerometer quickly change their indicators from positive to negative.
It seems that a person looking at these graphs can more or less understand what type of event took place; accordingly, a classifier based on a machine learning algorithm should also not have problems.
We collected the initial data: this is about 1000 kilometers of video recordings and telemetry collected from the phone on the roads of St. Petersburg and Moscow.
We made an environment for convenient work with video and data, which looks like this:
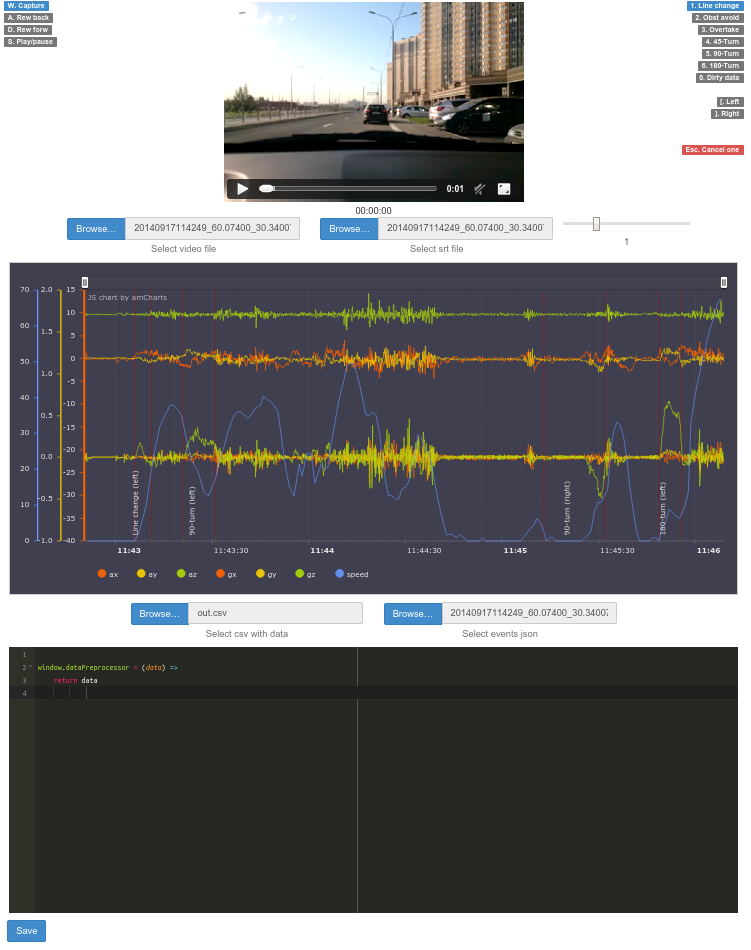
It consists of three parts. At the very top, watching a video with the movement of the car. In the center is a graph where you can watch data from the accelerometer, gyroscope and current speed. In the window below, you can modify the data with a script (coffescript) on the fly to display on the graph (for example, we need a smoothed graph).
In addition, the dashboard provides the ability to mark events on the video, save them to a file and see them later marked on the graph with annotations.
Perhaps one of you in your tasks also compares the video sequence with the sensor data, or just looks at the sensor data. If so, you might find the dashboard we use at github.com/blindmotion/dashboard useful . It is quite convenient, allows you to scale, modify data on the fly with a script and it has an open license, which means it can be freely used and modified.
The phone can be located anywhere in the car, while its position may vary. We need to bring all the data to one denominator to transfer our model. For this, a person from our team wrote a normalizer, a library that, regardless of the orientation of the device, always yields the z axis perpendicular to the Earth, the x axis coincides with the direction of the car, and the y axis perpendicular to the direction of movement is tangent to the Earth. It looks something like this:
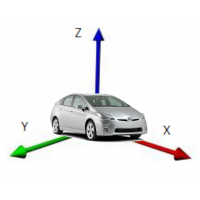
In order for this to work, we first focus on the vector of gravity and construct the rotation matrix so that our z axis after rotation coincides with this vector. The rotation matrix for the correct orientation of x and y is constructed in a slightly more complicated way.
Before normalization, the data looks like this:
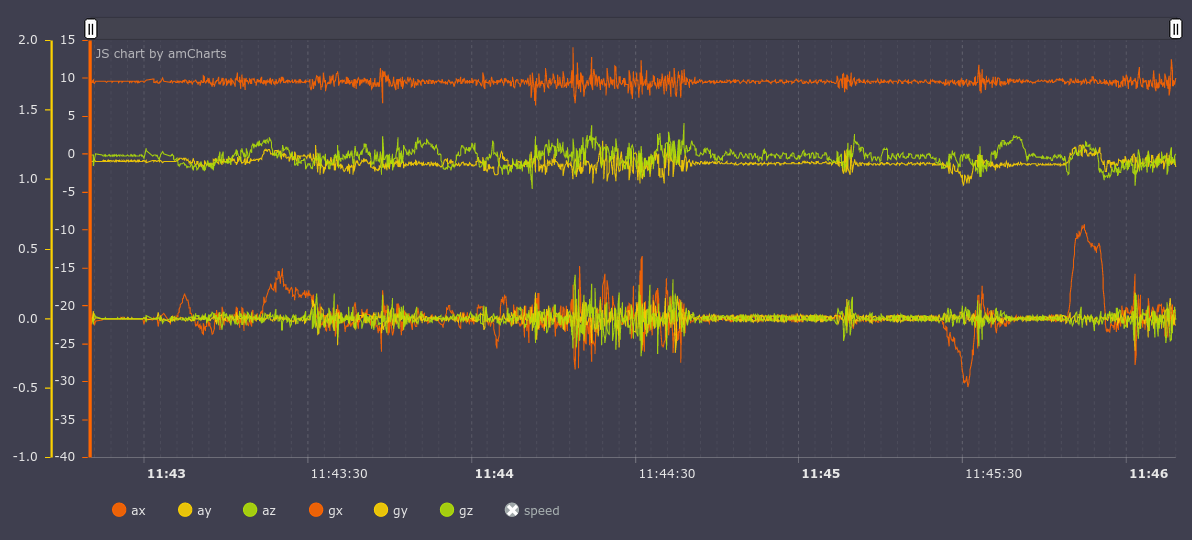
On the graph of the accelerometer, we see that the X axis (on the graph of ax; a is the accelerometer, g is the gyroscope) has an almost constant value of approximately 10g, which is incorrect, since the X axis is parallel to the Earth. We perform normalization and get the following graph:
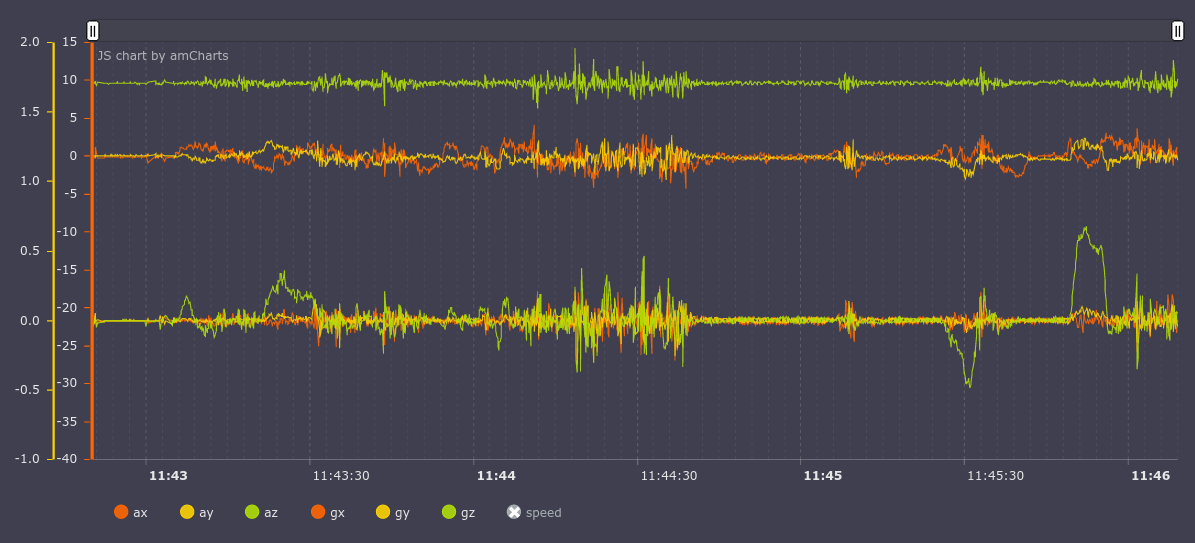
Now everything is in its place, the value along the Z (az) axis is 10g, and X and Y are the corresponding values for the movement of the car.
The normalizer can also be useful in other projects that are not related to the classification of events on the road, but related to the processing of data from sensors.
Now the feedforward neural network with three hidden layers is used for classification and it looks something like this:
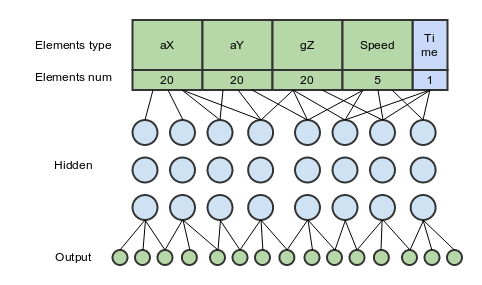
66 elements are input:
20 - readings of the accelerometer along the normalized X axis (lateral acceleration)
20 - readings from the accelerometer along the normalized Y axis (longitudinal acceleration)
20 - gyro readings along the normalized Z axis (rotation around the axis perpendicular to the Earth)
5 - speedometer readings gps
1 - time of the entire maneuver
In this configuration, at first glance, an optimal ratio of input data and result is obtained, although adding e other axes very little improves accuracy.
As I already said, the accelerometer and gyroscope readings and exactly 20 elements of each are fed to the input. That is, we take a period of time, for this period we take the readings of the accelerometer along the X axis, along the Y axis and the gyroscope along the Z axis. We get three data arrays and they do not have 20 elements initially. By 20, we bring them by extrapolation or interpolation.
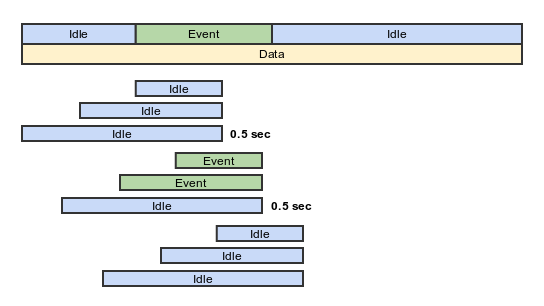
I spoke about a period of time. How to choose it? Here we have the data for the day. Above, I talked about a dashboard in which we mark up events. That is, in simple terms, we indicate there that from 12:00:34 to 12:00:41 we had a lane to the left. So we indicate all the events that have occurred and get some set of events (events). In addition to events, idle occupies the rest of the space, that is, those periods of time during which there were no rearrangements, no turns, or any other events.
Having received many events in this way, we then train the model sequentially with each of these events. We transfer these events to her and say that this was an overtaking, say.
The model also learns what absence of events is. The entire remaining time interval, where there are no events, we divide into some intervals and also give models, saying that there is nothing here.
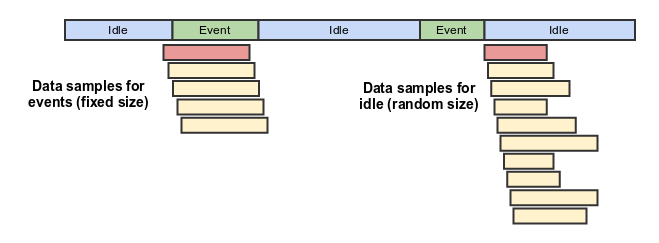
The figure shows this process. At the top of the line is the data along the time axis. Here we had nothing (idle), then an event (event), then again nothing, another event, and again nothing. Below this line are the samples (yellow squares) that are transferred to the model for training.
Having an already trained network, we can classify events with its help. A mobile phone transmits to us a constant stream of data from sensors. We keep the history of all readings for the last 30 seconds and pass this story to our model in the hope that she can find something there. The segments of length 2, 4, 6, 8, 10, 15, 20, 25, 30 seconds (figuratively) are transmitted and for each of the segments the probability of one or another event predicted by the model is determined.
For example, segments:
[from “current time” to “2 seconds ago”] - probabilities: idle 51%, turn left 23%, turn right 52%
[current time - 4 seconds ago] - idle 62%, turn left 21% , turn right 60%
[current time - 6 seconds ago] - idle 50%, turn left 27%, turn right 91%
[current time - 8 seconds ago] - idle 52%, turn left 17%, turn right 72%
Here, for a period of time from the current moment up to 6 seconds ago, the model gives a probability of 91% for turn right. Let's say this is more than our threshold of 90% and we add the right turn event for this time to the event map.
As a result, we get a map of classified events, from which we can try to make a conclusion about what events did occur. In practice, the same event, if we take measurements in half-second increments for each of the intervals (that is, every half second we repeat the above algorithm with segments) can be determined several times (the figure shows 2 times, two green events in the center of the picture). To deal with them, we will use the clustering algorithm. I used density-based clustering (DBSCAN). His idea is something like this:
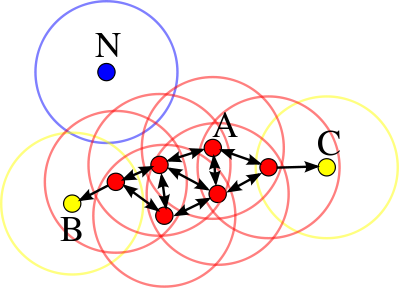
That is, if we were predicted at some point 8 times that there is a perestroika to the left, then we understand that yes, the perestroika really happened. In the figure, the horizontal axis is time, and the red dots are the left-defined rearrangement of the model for different segments close to each other.
The results of the work can be visually compared by seeing the markup of events made by a person and the algorithm.
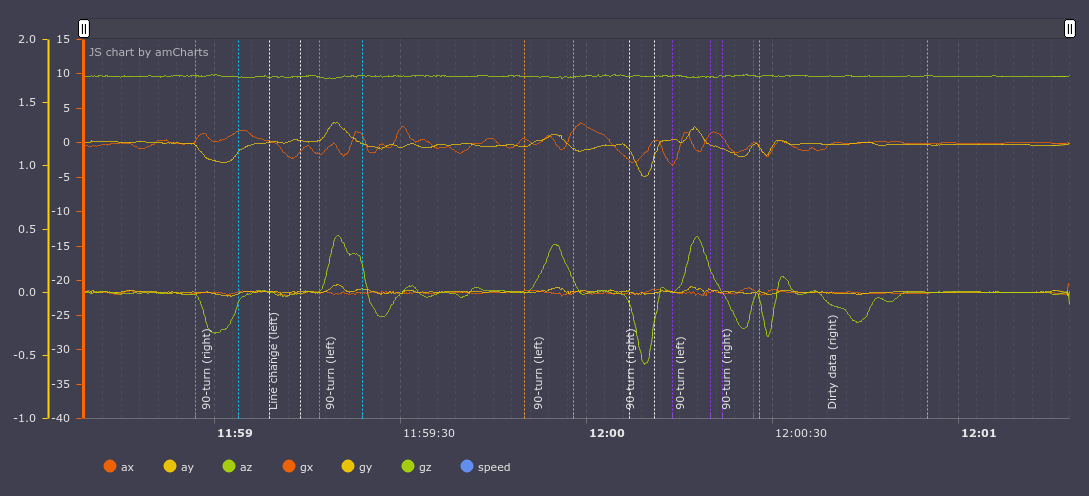
Events marked up by a man:
And by the model:
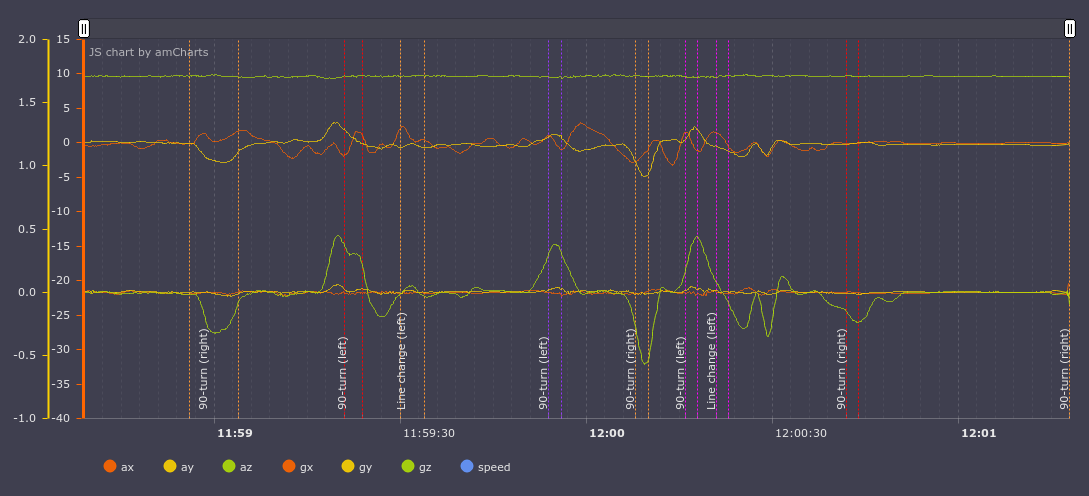
Here it is clear that the model missed the rebuild to the left after the first turn to the right and added the rebuild to the left after turning to the left. But, after watching the video, there this situation seems controversial, the trajectory really looks like a rearrangement to the left. Well, then I missed the turn and at the time of parking the car decided that I was turning.
Here is the video of this section (it is better to watch in hd so that the graph is visible):
Here are the numbers for all the events that were made by the machine in two hours: all rearrangements, turns, overtaking. The number of correctly and incorrectly defined events.
Test set is data on which we did not study and on which we did not correct in any way our model and clustering algorithm.
Correct type:
59 - so many events were correctly
detected Wrong type:
16 - so many events were determined but not correctly
False positive:
17 - so many events were invented by the neural network itself, in fact they should not be
False negative:
26 are events that were not determined by the model, but which actually have
Correct percent
0.5 - the percentage of accuracy including False negative
0.6413043478260869 - percentage of accuracy not including False negative. A metric with this approach: “missed something and God bless him, if only she hadn’t spoken incorrectly”
In general, it’s not bad, considering that there are 10 events (5 different, which are divided into left and right), the random number generator would give us accuracy order, say 10 percent accuracy. And then 50, which is already good.
Of course, the numbers do not yet allow us to talk about using the library in real time, but it already allows us to collect aggregated statistics and draw some conclusions on its basis, but there are still a lot of errors in terms of real-time.
By real time, I understand that when working on a phone or other device, the algorithm can reliably tell the program that the rebuild has just been performed. By aggregated statistics, I understand a certain algorithm on the server that collects these events from all devices and draws some conclusions based on this.
There is a big field for improvements and I think that in 6-9 months the algorithm may become quite suitable for use in real time.
This is how events generally look through the eyes of a neural network. This is a very generalized representation, in fact, inside it is much more multifaceted, but leading to one plane we get something like this:
These are graphs of lateral acceleration (remember, the Y axis). The top row is rebuilding: left and right. You can see that during the rebuild, the acceleration changes from one side to another.
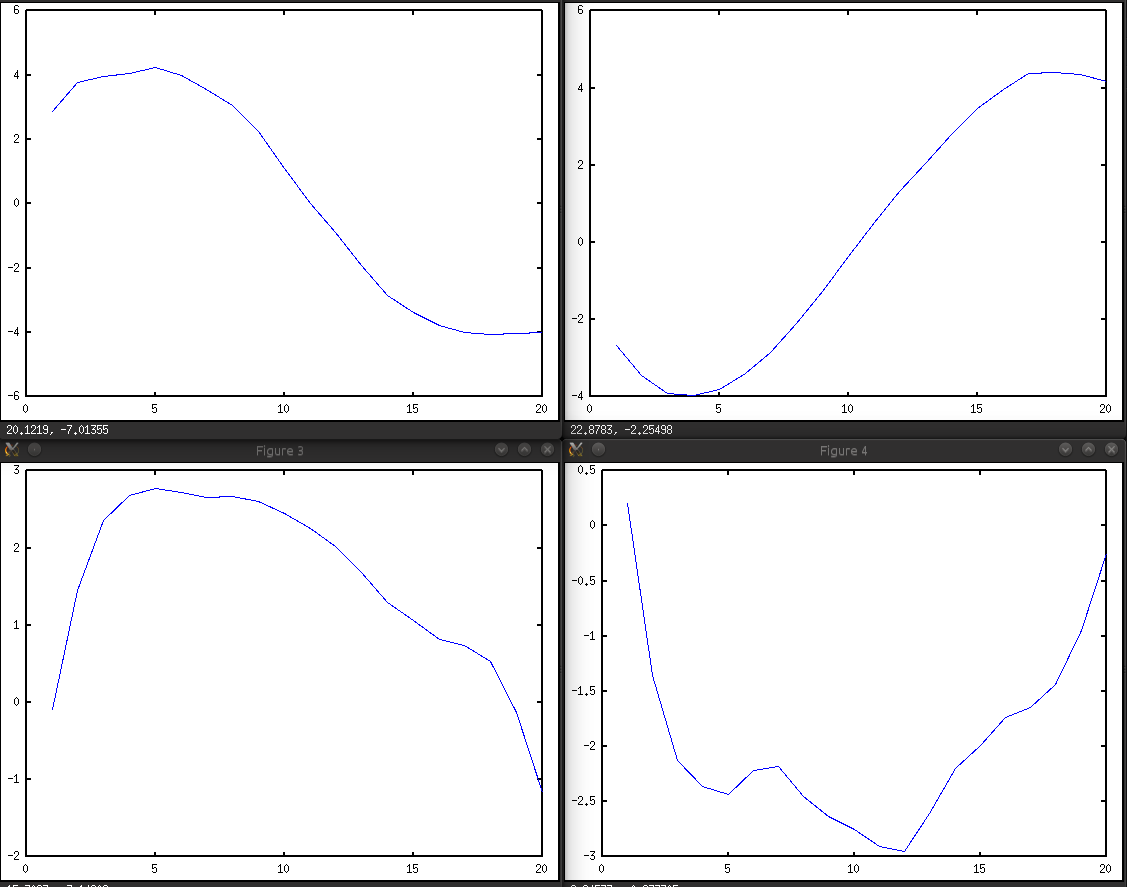
The bottom row - turns left and right, the acceleration increases to some value and then decreases towards the end of the maneuver.
The project is here github.com/blindmotion/docs/wiki and we would be glad if it were useful to you. It consists of a fairly large number of parts, each of them in a separate repository, the documentation is on the above link.
Further we plan to improve the classifier so that it can more accurately determine events. When this happens, then, probably, we will try to make a simple application for android, which will talk about the event. Say you are rebuilt or turned and the application reported this.
Our project is an open source project. First of all, you can help us with the data. If you can install a video recorder and a program for recording sensor values on your phone and turn them on when you are driving, we would be very grateful and would add you to the list of data contributors on the github. We really need data from other people, because you most likely have a different phone, a different car and a different driving style. This will allow the model to learn from a variety of data.
You can also help us with markup of this data in our dashboard, this is not the most exciting activity, you need to mark out events such as rearrangements, turns, etc. on video, but if you have a desire to help in this way, then welcome.
And of course, you can take part in the development of the model itself and the final library. To work on a model, the entry threshold is the ability to independently create a model that would work in much the same way as the existing one or better in terms of accuracy. Naturally, I will tell you where to get already marked data for my own model.
If you want to help in any of the ways, feel free to write in private or on github.
I will be glad to answer your questions in the comments. Thanks for attention.
We do not set ourselves the goal of determining pits and bumps on the roads, this has already been done before us. But in general, on the basis of this platform, it seems that this is done easily.
Today, in my opinion, one of the problems with navigation devices is that they do not lead the user in bands. This problem increases travel time, traffic jams and accident rate. Recently, google maps began to display the road markings before the turn, which is already a good result, but much can be improved here. Maps don’t know in which lane the car is currently located, it’s problematic using gps tools, gps has too much error for this. If we knew the current lane, we would know the speed of the lanes and could long tell the user in an explicit form what lane and when it is better to change lane. For example, the navigator would say, “Continue to keep this lane to the intersection” or “Change to the far left lane.”
In this article we will try to tell how we are trying to determine the changes, the current lane of the car, turns, overtaking, and also other maneuvers using machine learning according to the accelerometer and gyroscope.
It is possible to recommend rebuilding, not only if the movement along the lane is slow, say, because cars are turning from the left lane. Also, it is possible to recommend rebuilding if there is an accident in the current lane. Now accidents and road problems are caused by users manually. One could make an algorithm that would put them on the map automatically, looking at the maneuvers of cars. If cars in the same place massively make a detour, then, apparently, there was some kind of problem. Knowing this, the system could alert drivers to change lanes in advance if they no longer occupy it.
Another problem associated with the rather low accuracy of gps in the yards is that it is quite difficult to determine the position of the car on the winding paths of the house adjoining territories. The position is issued with an accuracy of plus or minus 10 meters and it is unclear whether the car has already passed a turn or not. And in an unfamiliar courtyard, this is critical, because we focus on the navigator, and he essentially does not always know where we are now. If we could reliably accurately determine the rotation, we could guide the user not only by gps, but also help the positioning system with data on the turns and would know exactly where the user is.
GPS also can not immediately determine the reversal of the car. She must drive a few meters back before it becomes clear that the maneuver was completed. If we could determine the U-turn right away, then the new rebuilt route would be much faster for the user.
Rebuilding into a pocket from the main road is also a controversial issue in the case of Gps, only according to its data it is now difficult to say whether the user was rebuilt or not, especially if the pocket is not deep. If there was an algorithm that would transmit this information in an alternative way, then combining it with Gps, the accuracy could be significantly improved.
How are you supposed to solve these problems?
In my free time, I and several students at the Computer Science Center make an open source project to determine traffic events using an accelerometer and a gyroscope. As a result, we want to make an accessible library with an open license that will allow, receiving data from the sensors of a mobile phone or some other device to the input, to output such events as a lane change, overtaking, obstacle avoidance, turning and turning. The library user will have to implement the switch in his program and correctly react to certain events.
In principle, not only telephones can use the library, but also, say, microcontroller-based devices that monitor transport. I will say right away that we are in the middle of the road and so far there is no certainty that we will be able to determine all the events, but it seems that something can work out for us.
What do the various events look like if displayed on a chart?
Events are indicated by broken vertical lines:
Leaving only the y axis for the accelerometer (lateral overloads, upper graph) and the z-axis of the gyroscope (machine rotation, top view, lower graph) active, you can notice how turns and turns are accompanied by increased lateral overloads and increasing rotation around the axis Z. When rebuilding, the gyroscope and accelerometer quickly change their indicators from positive to negative.
It seems that a person looking at these graphs can more or less understand what type of event took place; accordingly, a classifier based on a machine learning algorithm should also not have problems.
What has already been implemented
We collected the initial data: this is about 1000 kilometers of video recordings and telemetry collected from the phone on the roads of St. Petersburg and Moscow.
We made an environment for convenient work with video and data, which looks like this:
It consists of three parts. At the very top, watching a video with the movement of the car. In the center is a graph where you can watch data from the accelerometer, gyroscope and current speed. In the window below, you can modify the data with a script (coffescript) on the fly to display on the graph (for example, we need a smoothed graph).
In addition, the dashboard provides the ability to mark events on the video, save them to a file and see them later marked on the graph with annotations.
Perhaps one of you in your tasks also compares the video sequence with the sensor data, or just looks at the sensor data. If so, you might find the dashboard we use at github.com/blindmotion/dashboard useful . It is quite convenient, allows you to scale, modify data on the fly with a script and it has an open license, which means it can be freely used and modified.
We also made a normalizer for the accelerometer and gyroscope.
The phone can be located anywhere in the car, while its position may vary. We need to bring all the data to one denominator to transfer our model. For this, a person from our team wrote a normalizer, a library that, regardless of the orientation of the device, always yields the z axis perpendicular to the Earth, the x axis coincides with the direction of the car, and the y axis perpendicular to the direction of movement is tangent to the Earth. It looks something like this:
In order for this to work, we first focus on the vector of gravity and construct the rotation matrix so that our z axis after rotation coincides with this vector. The rotation matrix for the correct orientation of x and y is constructed in a slightly more complicated way.
Before normalization, the data looks like this:
On the graph of the accelerometer, we see that the X axis (on the graph of ax; a is the accelerometer, g is the gyroscope) has an almost constant value of approximately 10g, which is incorrect, since the X axis is parallel to the Earth. We perform normalization and get the following graph:
Now everything is in its place, the value along the Z (az) axis is 10g, and X and Y are the corresponding values for the movement of the car.
The normalizer can also be useful in other projects that are not related to the classification of events on the road, but related to the processing of data from sensors.
Classifier passed
Now the feedforward neural network with three hidden layers is used for classification and it looks something like this:
66 elements are input:
20 - readings of the accelerometer along the normalized X axis (lateral acceleration)
20 - readings from the accelerometer along the normalized Y axis (longitudinal acceleration)
20 - gyro readings along the normalized Z axis (rotation around the axis perpendicular to the Earth)
5 - speedometer readings gps
1 - time of the entire maneuver
In this configuration, at first glance, an optimal ratio of input data and result is obtained, although adding e other axes very little improves accuracy.
More details on how training is organized.
As I already said, the accelerometer and gyroscope readings and exactly 20 elements of each are fed to the input. That is, we take a period of time, for this period we take the readings of the accelerometer along the X axis, along the Y axis and the gyroscope along the Z axis. We get three data arrays and they do not have 20 elements initially. By 20, we bring them by extrapolation or interpolation.
I spoke about a period of time. How to choose it? Here we have the data for the day. Above, I talked about a dashboard in which we mark up events. That is, in simple terms, we indicate there that from 12:00:34 to 12:00:41 we had a lane to the left. So we indicate all the events that have occurred and get some set of events (events). In addition to events, idle occupies the rest of the space, that is, those periods of time during which there were no rearrangements, no turns, or any other events.
Having received many events in this way, we then train the model sequentially with each of these events. We transfer these events to her and say that this was an overtaking, say.
The model also learns what absence of events is. The entire remaining time interval, where there are no events, we divide into some intervals and also give models, saying that there is nothing here.
The figure shows this process. At the top of the line is the data along the time axis. Here we had nothing (idle), then an event (event), then again nothing, another event, and again nothing. Below this line are the samples (yellow squares) that are transferred to the model for training.
Suppose we were trained, what's next? We turn to the definition of events on new data, that is, classification.
Having an already trained network, we can classify events with its help. A mobile phone transmits to us a constant stream of data from sensors. We keep the history of all readings for the last 30 seconds and pass this story to our model in the hope that she can find something there. The segments of length 2, 4, 6, 8, 10, 15, 20, 25, 30 seconds (figuratively) are transmitted and for each of the segments the probability of one or another event predicted by the model is determined.
For example, segments:
[from “current time” to “2 seconds ago”] - probabilities: idle 51%, turn left 23%, turn right 52%
[current time - 4 seconds ago] - idle 62%, turn left 21% , turn right 60%
[current time - 6 seconds ago] - idle 50%, turn left 27%, turn right 91%
[current time - 8 seconds ago] - idle 52%, turn left 17%, turn right 72%
Here, for a period of time from the current moment up to 6 seconds ago, the model gives a probability of 91% for turn right. Let's say this is more than our threshold of 90% and we add the right turn event for this time to the event map.
As a result, we get a map of classified events, from which we can try to make a conclusion about what events did occur. In practice, the same event, if we take measurements in half-second increments for each of the intervals (that is, every half second we repeat the above algorithm with segments) can be determined several times (the figure shows 2 times, two green events in the center of the picture). To deal with them, we will use the clustering algorithm. I used density-based clustering (DBSCAN). His idea is something like this:
That is, if we were predicted at some point 8 times that there is a perestroika to the left, then we understand that yes, the perestroika really happened. In the figure, the horizontal axis is time, and the red dots are the left-defined rearrangement of the model for different segments close to each other.
Classifier Results
The results of the work can be visually compared by seeing the markup of events made by a person and the algorithm.
Events marked up by a man:
And by the model:
Here it is clear that the model missed the rebuild to the left after the first turn to the right and added the rebuild to the left after turning to the left. But, after watching the video, there this situation seems controversial, the trajectory really looks like a rearrangement to the left. Well, then I missed the turn and at the time of parking the car decided that I was turning.
Here is the video of this section (it is better to watch in hd so that the graph is visible):
What is the accuracy of the classifier? For test set, the numbers are as follows
Here are the numbers for all the events that were made by the machine in two hours: all rearrangements, turns, overtaking. The number of correctly and incorrectly defined events.
Test set is data on which we did not study and on which we did not correct in any way our model and clustering algorithm.
Correct type:
59 - so many events were correctly
detected Wrong type:
16 - so many events were determined but not correctly
False positive:
17 - so many events were invented by the neural network itself, in fact they should not be
False negative:
26 are events that were not determined by the model, but which actually have
Correct percent
0.5 - the percentage of accuracy including False negative
0.6413043478260869 - percentage of accuracy not including False negative. A metric with this approach: “missed something and God bless him, if only she hadn’t spoken incorrectly”
In general, it’s not bad, considering that there are 10 events (5 different, which are divided into left and right), the random number generator would give us accuracy order, say 10 percent accuracy. And then 50, which is already good.
Of course, the numbers do not yet allow us to talk about using the library in real time, but it already allows us to collect aggregated statistics and draw some conclusions on its basis, but there are still a lot of errors in terms of real-time.
By real time, I understand that when working on a phone or other device, the algorithm can reliably tell the program that the rebuild has just been performed. By aggregated statistics, I understand a certain algorithm on the server that collects these events from all devices and draws some conclusions based on this.
There is a big field for improvements and I think that in 6-9 months the algorithm may become quite suitable for use in real time.
How do different events look through the eyes of a neural network
This is how events generally look through the eyes of a neural network. This is a very generalized representation, in fact, inside it is much more multifaceted, but leading to one plane we get something like this:
These are graphs of lateral acceleration (remember, the Y axis). The top row is rebuilding: left and right. You can see that during the rebuild, the acceleration changes from one side to another.
The bottom row - turns left and right, the acceleration increases to some value and then decreases towards the end of the maneuver.
Where to look at the project
The project is here github.com/blindmotion/docs/wiki and we would be glad if it were useful to you. It consists of a fairly large number of parts, each of them in a separate repository, the documentation is on the above link.
What's next
Further we plan to improve the classifier so that it can more accurately determine events. When this happens, then, probably, we will try to make a simple application for android, which will talk about the event. Say you are rebuilt or turned and the application reported this.
How can you help
Our project is an open source project. First of all, you can help us with the data. If you can install a video recorder and a program for recording sensor values on your phone and turn them on when you are driving, we would be very grateful and would add you to the list of data contributors on the github. We really need data from other people, because you most likely have a different phone, a different car and a different driving style. This will allow the model to learn from a variety of data.
You can also help us with markup of this data in our dashboard, this is not the most exciting activity, you need to mark out events such as rearrangements, turns, etc. on video, but if you have a desire to help in this way, then welcome.
And of course, you can take part in the development of the model itself and the final library. To work on a model, the entry threshold is the ability to independently create a model that would work in much the same way as the existing one or better in terms of accuracy. Naturally, I will tell you where to get already marked data for my own model.
If you want to help in any of the ways, feel free to write in private or on github.
I will be glad to answer your questions in the comments. Thanks for attention.
FAQ
We do not set ourselves the goal of determining pits and bumps on the roads, this has already been done before us. But in general, on the basis of this platform, it seems that this is done easily.