Support for DOM L3 XPath in Project Spartan
- Transfer
Note from the translator: I am a server-side Java programmer, but it has so historically developed that I work exclusively under Windows. Everyone on the team sits mainly on Mac or Linux, but someone should test the web interfaces of projects under real IE live, who cares? So I’ve been using it for quite some years now, both for work needs and, due to laziness, as the main browser. In my opinion, with each new version, starting with the ninth, it becomes more and more worthy, and Project Spartan promises to be excellent at all. At least technologically, on an equal footing with others. I bring to your attention a translation of an article from a developers blog, which gives some reason to hope for this.

Having set ourselves the task of providing a truly compatible and modern web platform in Windows 10, we are constantly working to improve support for standards, in particular with regard to the DOM L3 XPath . Today we would like to tell how we achieved this in Project Spartan.
Before we implemented support for the DOM L3 Core standard and native XML documents in IE9, we provided the MSXML library with the ActiveX engine for web developers . In addition to the XMLHttpRequest object, MSXML also provided partial support for the XPath query language through a set of its own APIs, selectSingleNode and selectNodes. From the point of view of applications using MSXML, this method just worked. However, it completely did not meet the W3C standards for interacting with XML or for working with XPath.
Library authors and website developers had to wrap XPath calls to switch between on-the-fly implementations. If you search online for tutorials or XPath examples, you'll immediately notice wrappers for IE and MSXML, for example,
For our new web-based engine without plugins, we needed to provide native XPath support.
We immediately began to evaluate the available options for translating such support. One could write it from scratch, or integrate it completely into the MSXML browser, or port System.XML from .NET, but all this would take too much time. Therefore, we decided to start by implementing support for some basic subset of XPath, while thinking about the full one.
To determine what initial subset of the standard is worth taking, we used an internal tool that collects statistics on requests from hundreds of thousands of the most popular sites. It turned out that the most common queries are of the following types:
Each of them perfectly corresponds to some CSS selector, which can be redirected to the very fast implementation of the CSS selectors API. Compare for yourself:
Thus, the first step in implementing XPath support was to write a converter from XPath requests to CSS selectors, and redirect the call to the right place. Having done this, we again used our telemetry to measure the percentage of successful requests, as well as to find out which of the unsuccessful ones are most often encountered.
It turned out that such an implementation covers as much as 94% of requests, and allows you to immediately earn a lot of sites. Of the unsuccessful, most were species
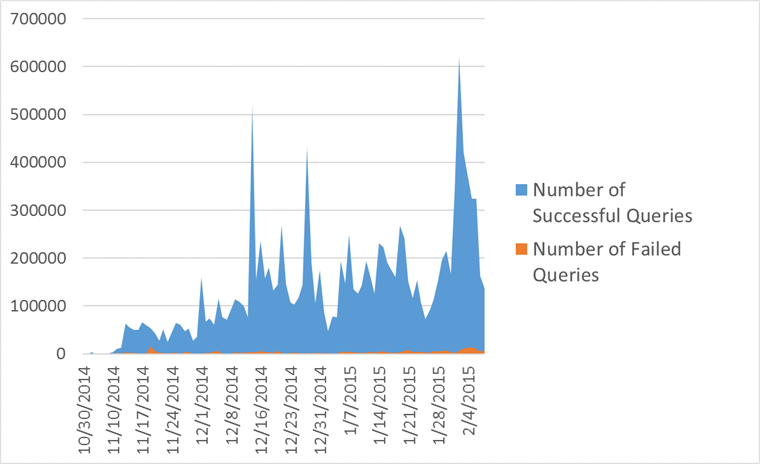
Telemetry Run Result for XPath Queries
Maintaining the vast majority of XPath queries with a simple conversion to CSS selectors is great, but still not enough, because you won’t be able to implement the remaining ones in a similar way. XPath grammar includes advanced things like functions, queries on non-DOM elements, document nodes, and complex predicates. Some authoritative sites (including MDN ) offer in such cases platforms that do not have adequate native XPath support to use polyfill libraries.
For example, wicked-good-xpath(WGX) which is written in pure JS. We tested it on our internal test suite for the XPath specification, and in comparison with native implementations it showed 91% compatibility, as well as very decent performance. So the idea of using WGX for the remaining 3% of sites seemed to us very attractive. Moreover, this is a project with source codes open under the MIT license, which is wonderfully combined with our intention to make an increasing contribution to the open source business. But we, however, have never used JavaScript polyfill inside IE to provide support for any web standard.
To enable WGX to work, and not to spoil the document context, we run it in a separate, isolated instance of the JS engine, passing it the request and the necessary data from the page to the input, and at the output we take the finished result. By modifying the WGX code to work in such a way "torn" from the document, we immediately improved the display of the content of many sites in our new browser.
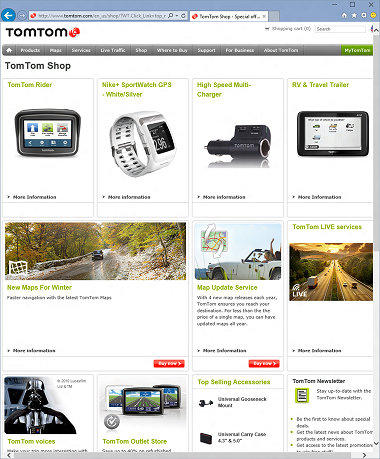

Sites before using WGX
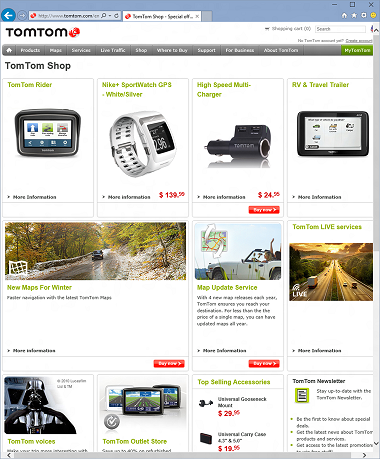

And this is after. Pay attention to the prices and numbers of winning tickets.
However, there were bugs in WGX that made it behave differently from the W3C specification and from other browsers. We plan to fix them all first, and then share the patches with the community.
Thus, as a result of some data mining on the Web, and with the help of an open source library, our new engine in a short time got powerful XPath support, and users will soon get better support for web standards. You can download the next Windows 10 Technical Preview , and see for yourself. You can also write through UserVoice how well we did it, or tweet to us, or comment on the original article .
PS from the translator: the tendency for JavaScript to become the language on which the platforms are written, as they say, is evident. Take Firefox's Shumway, or PDF.js. Now, Microsoft has translated its browser, at least partially, into JS.
Providing compatibility with DOM L3 XPath
Having set ourselves the task of providing a truly compatible and modern web platform in Windows 10, we are constantly working to improve support for standards, in particular with regard to the DOM L3 XPath . Today we would like to tell how we achieved this in Project Spartan.
A bit of history
Before we implemented support for the DOM L3 Core standard and native XML documents in IE9, we provided the MSXML library with the ActiveX engine for web developers . In addition to the XMLHttpRequest object, MSXML also provided partial support for the XPath query language through a set of its own APIs, selectSingleNode and selectNodes. From the point of view of applications using MSXML, this method just worked. However, it completely did not meet the W3C standards for interacting with XML or for working with XPath.
Library authors and website developers had to wrap XPath calls to switch between on-the-fly implementations. If you search online for tutorials or XPath examples, you'll immediately notice wrappers for IE and MSXML, for example,
// code for IE
if (window.ActiveXObject || xhttp.responseType == "msxml-document") {
xml.setProperty("SelectionLanguage", "XPath");
nodes = xml.selectNodes(path);
for (i = 0; i < nodes.length; i++) {
document.write(nodes[i].childNodes[0].nodeValue);
document.write("
");
}
}
// code for Chrome, Firefox, Opera, etc.
else if (document.implementation && document.implementation.createDocument) {
var nodes = xml.evaluate(path, xml, null, XPathResult.ANY_TYPE, null);
var result = nodes.iterateNext();
while (result) {
document.write(result.childNodes[0].nodeValue);
document.write("
");
result = nodes.iterateNext();
}
}For our new web-based engine without plugins, we needed to provide native XPath support.
Assessing Options
We immediately began to evaluate the available options for translating such support. One could write it from scratch, or integrate it completely into the MSXML browser, or port System.XML from .NET, but all this would take too much time. Therefore, we decided to start by implementing support for some basic subset of XPath, while thinking about the full one.
To determine what initial subset of the standard is worth taking, we used an internal tool that collects statistics on requests from hundreds of thousands of the most popular sites. It turned out that the most common queries are of the following types:
- // element1 / element2 / element3
- // element [@ attribute = "value"]
- .//* [contains (concat ("", @ class, ""), "classname")]
Each of them perfectly corresponds to some CSS selector, which can be redirected to the very fast implementation of the CSS selectors API. Compare for yourself:
- element1> element2> element3
- element [attribute = "value"]
- * .classname
Thus, the first step in implementing XPath support was to write a converter from XPath requests to CSS selectors, and redirect the call to the right place. Having done this, we again used our telemetry to measure the percentage of successful requests, as well as to find out which of the unsuccessful ones are most often encountered.
It turned out that such an implementation covers as much as 94% of requests, and allows you to immediately earn a lot of sites. Of the unsuccessful, most were species
- // element [contains (@ class, "className")]
- // element [contains (concat ("", normalize-space (@ class), ""), "className")]
Telemetry Run Result for XPath Queries
Providing support for the remaining 3% of sites
Maintaining the vast majority of XPath queries with a simple conversion to CSS selectors is great, but still not enough, because you won’t be able to implement the remaining ones in a similar way. XPath grammar includes advanced things like functions, queries on non-DOM elements, document nodes, and complex predicates. Some authoritative sites (including MDN ) offer in such cases platforms that do not have adequate native XPath support to use polyfill libraries.
For example, wicked-good-xpath(WGX) which is written in pure JS. We tested it on our internal test suite for the XPath specification, and in comparison with native implementations it showed 91% compatibility, as well as very decent performance. So the idea of using WGX for the remaining 3% of sites seemed to us very attractive. Moreover, this is a project with source codes open under the MIT license, which is wonderfully combined with our intention to make an increasing contribution to the open source business. But we, however, have never used JavaScript polyfill inside IE to provide support for any web standard.
To enable WGX to work, and not to spoil the document context, we run it in a separate, isolated instance of the JS engine, passing it the request and the necessary data from the page to the input, and at the output we take the finished result. By modifying the WGX code to work in such a way "torn" from the document, we immediately improved the display of the content of many sites in our new browser.
Sites before using WGX
And this is after. Pay attention to the prices and numbers of winning tickets.
However, there were bugs in WGX that made it behave differently from the W3C specification and from other browsers. We plan to fix them all first, and then share the patches with the community.
Thus, as a result of some data mining on the Web, and with the help of an open source library, our new engine in a short time got powerful XPath support, and users will soon get better support for web standards. You can download the next Windows 10 Technical Preview , and see for yourself. You can also write through UserVoice how well we did it, or tweet to us, or comment on the original article .
PS from the translator: the tendency for JavaScript to become the language on which the platforms are written, as they say, is evident. Take Firefox's Shumway, or PDF.js. Now, Microsoft has translated its browser, at least partially, into JS.