Visualization of equipment performance statistics with R - Shiny
“Illiteracy in the 21st century will not be those
who cannot read and write,
but those who cannot learn,
unlearn and relearn”
Alvin Toffler
IT professionals may have tasks related to analyzing the performance of equipment or analyzing the results of various load generators (ioMeter, Vdbench, etc.). In most cases, Excel is used for these purposes with the construction of time series, finding the main descriptive statistics and trying to somehow analyze it all. There is an alternative tool for faster and more convenient analysis of descriptive statistics with a variety of diagrams and the ability to create a web application for general access. I will not touch on real statistics with various methods of data analysis, only basic descriptive statistics (there will be no p-value without checking tests) and different diagrams.
In this article I will describe one of the options for how to analyze such information, present it in the form of diagrams ( traffic! ), And all this in the form of a web application. As the name of the article implies - it is implemented in R, with a package (framework) for web applications for R - Shiny .
In the case when there are few nominal variables (LUN, RAID groups, load profiles, etc.), using Excel is not difficult. But when their number increases and it is necessary to compare different quantitative characteristics within the same variable or, especially, between different variables, then using Excel and, moreover, only time series is irrational - the probability of making false assumptions, finding something that is missing or overlooking the obvious is great. Not to mention the time spent, the efforts, the abundance of sheets, dozens - hundreds of graphs on these sheets, about data sources that you forget the next day. Many (very revealing) types of diagrams in Excel cannot be built at all, others require the use of add-ons or writing voluminous code in VBA, or with a dozen manual steps for setting up charts. But even in the simple case, analyzing, identifying dependencies by classical time series is not a good idea, since they primarily serve other purposes - assessing the development of a variable’s change in time, decomposing the time series into components, and predicting these series. And not at all in order to place several graphs on one diagram, and even with two different axes and try to find the dependencies between the variables. In particular, the creator of the package And not at all in order to place several graphs on one diagram, and even with two different axes and try to find the dependencies between the variables. In particular, the creator of the package And not at all in order to place several graphs on one diagram, and even with two different axes and try to find the dependencies between the variables. In particular, the creator of the packageggplot2 Hadley Wickham (statistician) wrote the following in 2008: " I'm against this technique because I believe it leads to serious visual distortions and meaningless graphics ."
Previously, I performed data analysis (for personal projects) using Excel (including writing VBA code), and from time to time I heard about R, but I was skeptical, thinking that Excel was enough for me. When interest exceeded skepticism, I was pleasantly surprised how quickly and easily you can manipulate data, evaluate various models and build a variety of diagrams with many independent variables, literally in a few commands. Most operations are vectorized, so operations are performed promptly and there is no need for cycles in most cases. It is also worth noting the wide international community on R, which opens up great opportunities for resolving some issues.
Information is loaded by the basic function read.table () with the necessary parameters (column delimiter, fractional delimiter, row header).
Sometimes it is necessary to organize the data, and depending on the goals, a different type of data presentation (narrow - variables of one dimension are indicated in one column, but with nominal parameters in other columns, or wide - each variable in different columns) may be more convenient than the other. For example, to build diagrams of the ggplot2 package, the narrow format is more convenient, but there are no difficulties with the wide format. The tidyr and dplyr packages have convenient means for converting tables into different formats and manipulating data .
The main parameters are the minimum (Min) and maximum (Max) value of the variable, its median (Median), its arithmetic mean (Mean), first (1st Qu.) And third (3rd Qu.) Quartile. All these parameters can be calculated by the summary () function , and using it together with the tapply () function , it is possible to obtain results separately for any observed variable with certain conditions, or for greater flexibility, you can use the describe () function ( describeBy () ) which It displays great statistical information, but allows you to conveniently group the source data.
“... there is no statistical method more powerful
than a well-chosen graph.”
J. Chambers
One of the main advantages of R is the variety of types of diagrams that he can build. Diagrams are an integral part of exploratory data analysis; they reveal patterns and trends in complex data sets. In this section, I will provide nine basic conceptually different diagrams, a brief description and an example of their use. Of course, each study makes its own assumption of variables, in which the use of specific diagrams is more indicative, and it is not always necessary to use all of them, but in some cases this set will not be enough (in general, there are more than 1,000 diagrams in different packages in R) . Many diagrams have very flexible parameters that allow you to customize the result of the diagram in the desired form and in the design (axes, axis labels, name, colors).
The familiar time series is a series of data in which measurements of indicators are repeated at certain time intervals. As mentioned above, these graphs are good for visual assessment of one of the studied variables and its development over time. But in the general case, in addition to visual analysis, such diagrams are designed to decompose a series into components, and possible further forecasting of the development of a trend. If there is no time reference, when comparing different variables, it is more expedient to use the diagrams given below, thereby eliminating one of the dimensions - time (if you need to use time, use time as a nominal variable by coloring it with color or using panel diagrams).

These charts are graphs on which points are used to display the values of some quantitative variables, which can be further divided into groups in accordance with the levels of some nominal (or quantitative) variables (these groups are determined by color and / or size). This example depicts the dependence of the delay (ms) and performance (IOps) values across all measurements of different profiles, divided into groups (cache size - encrypted at the point size, and RAID group type - encrypted colors). Thus, in this diagram 4 different variables are displayed at once:

The analyzed data is divided into separate categories and for each of them is built its own chart (panel) of a certain type. All these diagrams are then combined in one drawing (vertically, horizontally, with a grid), which greatly facilitates the identification of statistical patterns and structures in the data. This diagram uses Example No. 2, it can be seen that the data layer for RAID groups was moved to two separate panels (left and right), but now the cache size is used as a grouping parameter (it is colored in color). And now it is additionally possible to add one group (additional variable) - the size of the point, thereby increasing the number of independent variables to five, in a single diagram, without losing clarity.

The histogram (density - the curve smoothing the histogram (line of bars)) allows you to visualize the distribution of the values of the analyzed variable, as well as the combination of variables on one diagram, which can additionally be divided into groups in accordance with the levels of some nominal (or quantitative) variables, to compare the frequency of occurrence . This example, for example, depicts the density of the performance distribution (IOps) of one variable depending on the type of RAID created.

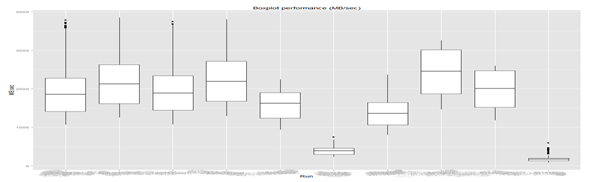
This chart is suitable for reflecting the main robust (stable) characteristics of the sample, this function also allows you to display multiple box-slots at the same time, which allows you to quickly and efficiently evaluate descriptive statistics for different factor variables. In this example, for example, we show the statistics of the distribution of productivity (MB / c) for different load profiles (in fact, this is an analogue of the conclusions of the summary ( ) function , but in graphical form, and with the addition of outliers, which is more indicative):
This graph is a family of scatter diagrams (Clause 2), which reflect in pairs the dependence of the values of each variable on each other variable. In this example, pairwise dependencies of all 5 variables are shown; it is also possible to add another 6 variables by coloring one of the factors with color.

This graph allows you to compare a significant number of independent variables for each nominal value, and show a pairwise relationship between them, and color one of the nominal variables with color. Despite the unusual appearance, in many cases, these charts can help quickly classify a multidimensional data set. So, in this example, the diagram shows that one load profile (orange) with high input-output operations does not entail an increase in load, and some (blue) vice versa; part of the profiles (green) stably show a high delay, it is also visible that some profiles fall in the same place on each characteristic, it is visible where (small or large values) many features are shifted, etc.

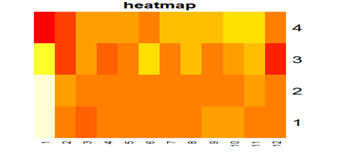
This diagram displays the value of a particular variable in its color; this diagram will be useful for displaying any characteristics in relation to the actual physical placement of equipment components. For example, display hotter (in performance, time, rotation frequency, etc.) drives in the shelves (as in this example: horizontally — slot numbers, vertically — shelf numbers), or display hotter RAID groups or pools associated with their physical disks in an array.
Also, different pictograms (stars, Chernov’s faces) can be used to analyze aggregated multidimensional data.
The idea of such diagrams is that people distinguish objects well, in this case faces (and not a set of dozens of values from 10-20 digits). In the above example, each person corresponds to one load profile, which in aggregated (median) form reflects the characteristics of the values of the attributes (performance (two types), delay (three types)). A quick look at this diagram will allow you to quickly determine whether the characteristics of the profiles significantly differ (coincide), with a detailed review (facial features) it will be clear in which features (each facial feature is a separate feature of the original data set) similarity, and what is the difference.

All the code for loading data, transforming data and displaying diagrams is written in R-Studio , a convenient graphical shell for R, which is quite enough to get fast results and write reports. But a situation may arise in a flexible, dynamic means of adjusting the results (selection of axes, diagrams, scaling, saving the results in graphic files and much more), and / or in the case of demonstrating the results to a wide circle of colleagues, customers, partners. In this case, it is quite convenient to bind the existing code (or immediately write new) to the input-output elements of the web application using the Shiny package . Shiny- a package (framework) for the rapid development of web applications. I stumbled upon it quite by accident, and my surprise at using R - was transferred also to it: several types of basic input-output elements, convenient binding of calculation code to input-output elements, dynamic change of input elements, reactive variables and functions - everything turned out much easier than i thought. An excellent solution for hiding the code and showing only “twirls and skewers” and pictures.
As in the case of using Shiny , and without it, all the R code is in text files with the extension R. The only difference in the case of Shiny is that there are two such files - ui.R (description of I / O elements) and server.R (all calculations ) (although you can make Shiny applications in one file, but for me it’s more convenient to leave two). Therefore, the distribution of the results is as follows:
For R users:
1. Direct distribution of R files (separately or in an archive)
2. Placing R files using Github. To receive files, in R it is enough to execute one command and the files will be downloaded locally, and it becomes possible to run them.
For everyone (in these cases, there is no need to have R installed, launching Shiny applications is carried out from the browser):
1) placing the Shiny application on its local Shiny server (there are two options - free and paid (with authentication and SSL));
2) hosting Shiny applications in cloud hosting (on R-Studio servers), at the moment there are four tariff plans: from free (with restrictions on the number of applications and the time of the running application per month) to paid (with removed restrictions, authentication capabilities (SSL)).
1. First, the file selected by the user is opened;
2. Based on existing load profiles, unique values are generated, the drop-down list is updated;
3. When selecting a profile from the drop-down list, a new set is created and based on it the charts, descriptive statistics and initial data are changed (for comparison);
4. Of course, you can make a choice of several profiles (controls allow this), analyze them on different diagrams, colorize the nominal parameters, save diagrams in various formats (vector and raster).
Below are some screenshots of my ShinyVdbench unloading performance analysis applications, with individual profile selection, dynamic adjustment of axis ranges, display of certain types of diagrams (rebuild in less than a second). All this is implemented exclusively on the basic Shiny elements , although there are options for customizing and styling the application using directly both HTML, CSS, JavaScript and jQuery.

1 panel

2 panel

3 panel

4 panel
As a result, we can say that I figured out the basic graphical capabilities of ggplot2 and the design of diagrams (previously, basically building the diagrams themselves was enough for me, without much design) - a really convenient tool for building different diagrams, and of course I studied Shiny . For the initial exploratory analysis of resource productivity data - R is a very suitable tool, at least in terms of ease of use, speed of obtaining results, and the graphical results themselves. Additional use of Shiny (either your own server or a cloud server) will allow you to demonstrate the results of the analysis in a more convenient form, both to internal employees and customers.
who cannot read and write,
but those who cannot learn,
unlearn and relearn”
Alvin Toffler
IT professionals may have tasks related to analyzing the performance of equipment or analyzing the results of various load generators (ioMeter, Vdbench, etc.). In most cases, Excel is used for these purposes with the construction of time series, finding the main descriptive statistics and trying to somehow analyze it all. There is an alternative tool for faster and more convenient analysis of descriptive statistics with a variety of diagrams and the ability to create a web application for general access. I will not touch on real statistics with various methods of data analysis, only basic descriptive statistics (there will be no p-value without checking tests) and different diagrams.
In this article I will describe one of the options for how to analyze such information, present it in the form of diagrams ( traffic! ), And all this in the form of a web application. As the name of the article implies - it is implemented in R, with a package (framework) for web applications for R - Shiny .
Excel Limitations
In the case when there are few nominal variables (LUN, RAID groups, load profiles, etc.), using Excel is not difficult. But when their number increases and it is necessary to compare different quantitative characteristics within the same variable or, especially, between different variables, then using Excel and, moreover, only time series is irrational - the probability of making false assumptions, finding something that is missing or overlooking the obvious is great. Not to mention the time spent, the efforts, the abundance of sheets, dozens - hundreds of graphs on these sheets, about data sources that you forget the next day. Many (very revealing) types of diagrams in Excel cannot be built at all, others require the use of add-ons or writing voluminous code in VBA, or with a dozen manual steps for setting up charts. But even in the simple case, analyzing, identifying dependencies by classical time series is not a good idea, since they primarily serve other purposes - assessing the development of a variable’s change in time, decomposing the time series into components, and predicting these series. And not at all in order to place several graphs on one diagram, and even with two different axes and try to find the dependencies between the variables. In particular, the creator of the package And not at all in order to place several graphs on one diagram, and even with two different axes and try to find the dependencies between the variables. In particular, the creator of the package And not at all in order to place several graphs on one diagram, and even with two different axes and try to find the dependencies between the variables. In particular, the creator of the packageggplot2 Hadley Wickham (statistician) wrote the following in 2008: " I'm against this technique because I believe it leads to serious visual distortions and meaningless graphics ."
R benefits
Previously, I performed data analysis (for personal projects) using Excel (including writing VBA code), and from time to time I heard about R, but I was skeptical, thinking that Excel was enough for me. When interest exceeded skepticism, I was pleasantly surprised how quickly and easily you can manipulate data, evaluate various models and build a variety of diagrams with many independent variables, literally in a few commands. Most operations are vectorized, so operations are performed promptly and there is no need for cycles in most cases. It is also worth noting the wide international community on R, which opens up great opportunities for resolving some issues.
Performance analysis sequence:
I. Data loading
Information is loaded by the basic function read.table () with the necessary parameters (column delimiter, fractional delimiter, row header).
II. Data sequencing
Sometimes it is necessary to organize the data, and depending on the goals, a different type of data presentation (narrow - variables of one dimension are indicated in one column, but with nominal parameters in other columns, or wide - each variable in different columns) may be more convenient than the other. For example, to build diagrams of the ggplot2 package, the narrow format is more convenient, but there are no difficulties with the wide format. The tidyr and dplyr packages have convenient means for converting tables into different formats and manipulating data .
III. The main parameters of descriptive statistics
The main parameters are the minimum (Min) and maximum (Max) value of the variable, its median (Median), its arithmetic mean (Mean), first (1st Qu.) And third (3rd Qu.) Quartile. All these parameters can be calculated by the summary () function , and using it together with the tapply () function , it is possible to obtain results separately for any observed variable with certain conditions, or for greater flexibility, you can use the describe () function ( describeBy () ) which It displays great statistical information, but allows you to conveniently group the source data.
IV. Charts
“... there is no statistical method more powerful
than a well-chosen graph.”
J. Chambers
One of the main advantages of R is the variety of types of diagrams that he can build. Diagrams are an integral part of exploratory data analysis; they reveal patterns and trends in complex data sets. In this section, I will provide nine basic conceptually different diagrams, a brief description and an example of their use. Of course, each study makes its own assumption of variables, in which the use of specific diagrams is more indicative, and it is not always necessary to use all of them, but in some cases this set will not be enough (in general, there are more than 1,000 diagrams in different packages in R) . Many diagrams have very flexible parameters that allow you to customize the result of the diagram in the desired form and in the design (axes, axis labels, name, colors).
1. Time series
The familiar time series is a series of data in which measurements of indicators are repeated at certain time intervals. As mentioned above, these graphs are good for visual assessment of one of the studied variables and its development over time. But in the general case, in addition to visual analysis, such diagrams are designed to decompose a series into components, and possible further forecasting of the development of a trend. If there is no time reference, when comparing different variables, it is more expedient to use the diagrams given below, thereby eliminating one of the dimensions - time (if you need to use time, use time as a nominal variable by coloring it with color or using panel diagrams).
2. Scatter plots (scatter plots)
These charts are graphs on which points are used to display the values of some quantitative variables, which can be further divided into groups in accordance with the levels of some nominal (or quantitative) variables (these groups are determined by color and / or size). This example depicts the dependence of the delay (ms) and performance (IOps) values across all measurements of different profiles, divided into groups (cache size - encrypted at the point size, and RAID group type - encrypted colors). Thus, in this diagram 4 different variables are displayed at once:
3. Panel (categorized) graphics
The analyzed data is divided into separate categories and for each of them is built its own chart (panel) of a certain type. All these diagrams are then combined in one drawing (vertically, horizontally, with a grid), which greatly facilitates the identification of statistical patterns and structures in the data. This diagram uses Example No. 2, it can be seen that the data layer for RAID groups was moved to two separate panels (left and right), but now the cache size is used as a grouping parameter (it is colored in color). And now it is additionally possible to add one group (additional variable) - the size of the point, thereby increasing the number of independent variables to five, in a single diagram, without losing clarity.
4. Histogram (density) distribution
The histogram (density - the curve smoothing the histogram (line of bars)) allows you to visualize the distribution of the values of the analyzed variable, as well as the combination of variables on one diagram, which can additionally be divided into groups in accordance with the levels of some nominal (or quantitative) variables, to compare the frequency of occurrence . This example, for example, depicts the density of the performance distribution (IOps) of one variable depending on the type of RAID created.
5. Span diagrams (boxplot, “mustache box”)
This chart is suitable for reflecting the main robust (stable) characteristics of the sample, this function also allows you to display multiple box-slots at the same time, which allows you to quickly and efficiently evaluate descriptive statistics for different factor variables. In this example, for example, we show the statistics of the distribution of productivity (MB / c) for different load profiles (in fact, this is an analogue of the conclusions of the summary ( ) function , but in graphical form, and with the addition of outliers, which is more indicative):
6. Matrix plot (pair scatterplots)
This graph is a family of scatter diagrams (Clause 2), which reflect in pairs the dependence of the values of each variable on each other variable. In this example, pairwise dependencies of all 5 variables are shown; it is also possible to add another 6 variables by coloring one of the factors with color.
7. The graph of parallel coordinates
This graph allows you to compare a significant number of independent variables for each nominal value, and show a pairwise relationship between them, and color one of the nominal variables with color. Despite the unusual appearance, in many cases, these charts can help quickly classify a multidimensional data set. So, in this example, the diagram shows that one load profile (orange) with high input-output operations does not entail an increase in load, and some (blue) vice versa; part of the profiles (green) stably show a high delay, it is also visible that some profiles fall in the same place on each characteristic, it is visible where (small or large values) many features are shifted, etc.
8. Heat map
This diagram displays the value of a particular variable in its color; this diagram will be useful for displaying any characteristics in relation to the actual physical placement of equipment components. For example, display hotter (in performance, time, rotation frequency, etc.) drives in the shelves (as in this example: horizontally — slot numbers, vertically — shelf numbers), or display hotter RAID groups or pools associated with their physical disks in an array.
9. Pictograms (stars, Chernov’s faces)
Also, different pictograms (stars, Chernov’s faces) can be used to analyze aggregated multidimensional data.
The idea of such diagrams is that people distinguish objects well, in this case faces (and not a set of dozens of values from 10-20 digits). In the above example, each person corresponds to one load profile, which in aggregated (median) form reflects the characteristics of the values of the attributes (performance (two types), delay (three types)). A quick look at this diagram will allow you to quickly determine whether the characteristics of the profiles significantly differ (coincide), with a detailed review (facial features) it will be clear in which features (each facial feature is a separate feature of the original data set) similarity, and what is the difference.
V. Dynamic control (Shiny)
All the code for loading data, transforming data and displaying diagrams is written in R-Studio , a convenient graphical shell for R, which is quite enough to get fast results and write reports. But a situation may arise in a flexible, dynamic means of adjusting the results (selection of axes, diagrams, scaling, saving the results in graphic files and much more), and / or in the case of demonstrating the results to a wide circle of colleagues, customers, partners. In this case, it is quite convenient to bind the existing code (or immediately write new) to the input-output elements of the web application using the Shiny package . Shiny- a package (framework) for the rapid development of web applications. I stumbled upon it quite by accident, and my surprise at using R - was transferred also to it: several types of basic input-output elements, convenient binding of calculation code to input-output elements, dynamic change of input elements, reactive variables and functions - everything turned out much easier than i thought. An excellent solution for hiding the code and showing only “twirls and skewers” and pictures.
VI. Dissemination of results
As in the case of using Shiny , and without it, all the R code is in text files with the extension R. The only difference in the case of Shiny is that there are two such files - ui.R (description of I / O elements) and server.R (all calculations ) (although you can make Shiny applications in one file, but for me it’s more convenient to leave two). Therefore, the distribution of the results is as follows:
For R users:
1. Direct distribution of R files (separately or in an archive)
2. Placing R files using Github. To receive files, in R it is enough to execute one command and the files will be downloaded locally, and it becomes possible to run them.
For everyone (in these cases, there is no need to have R installed, launching Shiny applications is carried out from the browser):
1) placing the Shiny application on its local Shiny server (there are two options - free and paid (with authentication and SSL));
2) hosting Shiny applications in cloud hosting (on R-Studio servers), at the moment there are four tariff plans: from free (with restrictions on the number of applications and the time of the running application per month) to paid (with removed restrictions, authentication capabilities (SSL)).
Briefly on implementation and results
1. First, the file selected by the user is opened;
2. Based on existing load profiles, unique values are generated, the drop-down list is updated;
3. When selecting a profile from the drop-down list, a new set is created and based on it the charts, descriptive statistics and initial data are changed (for comparison);
4. Of course, you can make a choice of several profiles (controls allow this), analyze them on different diagrams, colorize the nominal parameters, save diagrams in various formats (vector and raster).
Below are some screenshots of my ShinyVdbench unloading performance analysis applications, with individual profile selection, dynamic adjustment of axis ranges, display of certain types of diagrams (rebuild in less than a second). All this is implemented exclusively on the basic Shiny elements , although there are options for customizing and styling the application using directly both HTML, CSS, JavaScript and jQuery.
1 panel
2 panel
3 panel
4 panel
Conclusion
As a result, we can say that I figured out the basic graphical capabilities of ggplot2 and the design of diagrams (previously, basically building the diagrams themselves was enough for me, without much design) - a really convenient tool for building different diagrams, and of course I studied Shiny . For the initial exploratory analysis of resource productivity data - R is a very suitable tool, at least in terms of ease of use, speed of obtaining results, and the graphical results themselves. Additional use of Shiny (either your own server or a cloud server) will allow you to demonstrate the results of the analysis in a more convenient form, both to internal employees and customers.