Localization of Android applications using Google Sheets
I read the publication “Localization of Android applications using Google Sheets” and was surprised. The whole team is working on the project (translator, developer, author), but one of the priority tasks - product translation - is inconvenient to solve.
Paid services are good for everyone, except that they are paid. Translation involves many authors inherently - and the role of a convenient multi-user editor of one document immediately pops up Google Doc.
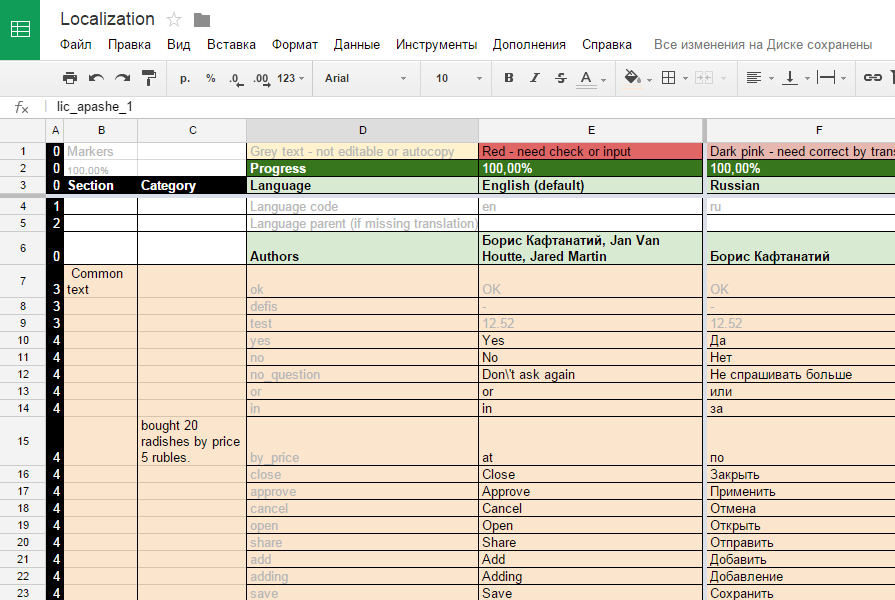
I am a developer of a small but proud Android application. As soon as the 3rd language was added to the project (after English and Russian), I immediately transferred the entire dictionary database to Google Sheets. I immediately felt the convenience of comparing multilingual strings - I had to pretty much adjust the lengths. The first few times I transferred translations manually to the xml files of the project resources. Then he spat and wrote a regular parser: from the exported TSV file of Google Sheet to a set of localization files ready to be immediately added to the project.
Why Delphi? - It was more convenient for me, not so long ago I was picking an old program for reformatting tricky files and for linear parsing of a text file into another. No extra files in the project.
Why TSV? - csv is not suitable because of collisions if the lines contain commas ... and then did not search.
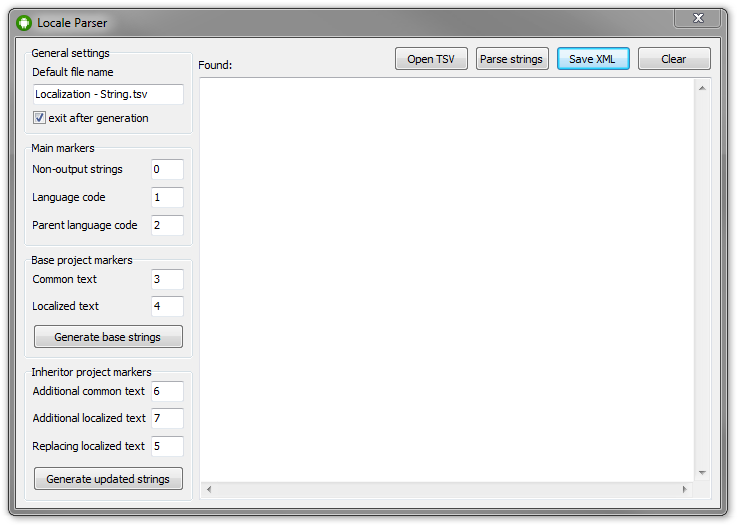
Since I am simultaneously developing two projects, and the second project is a more functional version, it seemed to me convenient to have a common vocabulary base for them. Sharing resources through tokens is the first column in the table.
There is nothing tricky about parsing. I export the file to a table separated by tabs, and in the parser I cast to the data columns. The first, as I already mentioned, is official and has labels on how to process the string:
The common line for the base project is universal for all localizations, stored in the shared values / folder in string_common.xml. The
unique line - unique for the language, fits into its localized values _ ** / strings.xml folder.
In the comments to the opposing article I saw a question about preparing resources for different platforms. With a separate tool for bringing Google Sheets to resource files, this is not a problem, but rather a free-night task.
I am developing in Eclipse on Windows and it’s convenient for me to simply replace the localization files. The whole context of the translation can be easily traced by the neighboring translations and the first columns - comments. The whole translation, and its more than 1000! rows performed by volunteers, grateful users. Each release of the program with an updated translation, whatever it may be. For questions and suggestions for help with translation, I just give a link to the table.
PS The project, as promised, combed and posted on GitHub .
Paid services are good for everyone, except that they are paid. Translation involves many authors inherently - and the role of a convenient multi-user editor of one document immediately pops up Google Doc.
I am a developer of a small but proud Android application. As soon as the 3rd language was added to the project (after English and Russian), I immediately transferred the entire dictionary database to Google Sheets. I immediately felt the convenience of comparing multilingual strings - I had to pretty much adjust the lengths. The first few times I transferred translations manually to the xml files of the project resources. Then he spat and wrote a regular parser: from the exported TSV file of Google Sheet to a set of localization files ready to be immediately added to the project.
Why Delphi? - It was more convenient for me, not so long ago I was picking an old program for reformatting tricky files and for linear parsing of a text file into another. No extra files in the project.
Why TSV? - csv is not suitable because of collisions if the lines contain commas ... and then did not search.
Since I am simultaneously developing two projects, and the second project is a more functional version, it seemed to me convenient to have a common vocabulary base for them. Sharing resources through tokens is the first column in the table.
There is nothing tricky about parsing. I export the file to a table separated by tabs, and in the parser I cast to the data columns. The first, as I already mentioned, is official and has labels on how to process the string:
- 0 - nothing, service information;
- 1 - language code, to replace the asterisks in values _ **;
- 2 - the language code of the parent from which the missing translations are taken, if indicated; for example, for Belarusian and Ukrainian it is Russian.
- 3 - a common line for the base project;
- 4 - a unique line for the base project;
- 5 - a unique line for the successor project, overwriting the line with the same key of the base project;
- 6 - a common line for the successor project;
- 7 - a unique line for the successor project;
The common line for the base project is universal for all localizations, stored in the shared values / folder in string_common.xml. The
unique line - unique for the language, fits into its localized values _ ** / strings.xml folder.
In the comments to the opposing article I saw a question about preparing resources for different platforms. With a separate tool for bringing Google Sheets to resource files, this is not a problem, but rather a free-night task.
I am developing in Eclipse on Windows and it’s convenient for me to simply replace the localization files. The whole context of the translation can be easily traced by the neighboring translations and the first columns - comments. The whole translation, and its more than 1000! rows performed by volunteers, grateful users. Each release of the program with an updated translation, whatever it may be. For questions and suggestions for help with translation, I just give a link to the table.
PS The project, as promised, combed and posted on GitHub .