Search for texts that are not relevant to the topic and finding similar articles
I have a website with articles on a similar topic. There were two problems on the site: spam messages and duplicate articles, and duplicates were often not exact copies.
This post tells how I solved these problems.
Given:
Objective: get rid of spam and duplicates, as well as prevent their further occurrence.

All articles on my site are related to the same topic and, as a rule, spammers / advertising messages are decently different in content. I decided to manually sort a number of articles. And on their basis to build a classifier. For classification, we consider the cosine distance between the vector of the article being checked and the vectors of two groups (spam / non-spam). Which group the article being reviewed is closer to will group the article as well.
First you need to manually categorize the articles. I sketched a checkbox form for this and collected 650 spam articles and 2,000 non-spam articles in a few hours.
All posts are cleared of garbage - noise words that do not carry a payload (communion, interjection, etc.). To do this, I collected from different dictionaries that I found on the Internet, myvocabulary of noise words .
To minimize the number of different forms of a single word, you can use Porter's stemmm . I took the finished Java implementation from here . Thank you, Edunov.
From the words of classified articles, cleared of noise words and driven through stemming, you need to compile a dictionary.
From the dictionary we delete the words that are found in only one article.
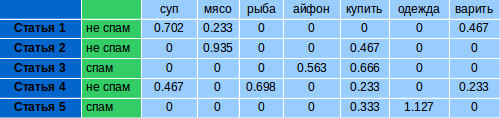
For each manually classified article, we count the number of occurrences of each word from the dictionary. We get vectors similar to the following: We

strengthen the word weights in each vector, counting TF-IDF for them . TF-IDF is considered separately for each spam / non-spam group.
First, we consider TF (term frequency) for each article. This is the ratio of the number of occurrences of a particular word to the total number of words in the article:

where n i is the number of occurrences of the word in the document, and the denominator is the total number of words in this document.

Next, consider IDF (inverse document frequency). Inverse of the frequency with which a certain word occurs in group documents (spam / non-spam). IDF reduces the weight of words that are often used in a group. It is considered for each group.

Where

We consider TF-IDF:
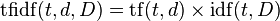
Words with high frequency within a specific document and with a low frequency of use in other documents will receive a lot of weight in TF-IDF.
For each group we form one vector, taking the arithmetic mean of each parameter within the group:

To check the article for spam, you need to get for it the number of occurrences of words from the dictionary. Count for these words TF-IDF for spam and not spam. You will get two vectors (TF-IDF is not spam and TF-IDF is spam). IDF for calculations, take the one that was considered for the classification sample.

For each vector, we consider the cosine distance with the vectors for spam and non-spam, respectively. The cosine distance is a measure of the similarity of two vectors. The scalar product of vectors and the cosine of the angle θ between them are related by the following relation:

Having two vectors A and B, we obtain the cosine distance - cos (θ)

The result is a range from -1 to 1. -1 means that the vectors are completely opposite, 1, that they are the same.
Which of the obtained values (for spam and not spam) will be closer to 1, and we will relate the article to that group.
When checking for similarity to non-spam, the result is the number 0.87:

for spam - 0.62:

Therefore, we believe that the article is not spam.
For testing, I manually selected another 700 records. The accuracy of the results was 98%. At the same time, what was classified erroneously, even it was difficult for me to attribute to this or that category.
After clearing spam, 118,000 articles remained.
To find duplicates, I decided to use an inverted index ( Inverted index ). An index is a data structure where for each word it is indicated in which documents it is contained. Accordingly, if we have a set of words, we can easily request documents containing these words.
Wiki example. Let's say we have the following documents:
For these documents, we construct an index by indicating which document contains the word:
All the words “what”, “is” and “it” are in documents 0 and 1:
I saved the index in the MySQL database. Indexing took about 2 days.
To search for similar articles, it is not necessary that all words coincide, therefore, when querying by index, we get all articles that have at least 75% matching words. The found ones contain similar duplicates, as well as other articles that include 75% of the original words, for example, these can be very long articles.
To weed out what is not a duplicate, you need to calculate the cosine distance between the original and those found. That which matches more than 75% is considered a duplicate. The number in 75% was derived empirically. It allows you to find sufficiently modified versions of the same article.
Full cleaning took about 5 hours.
To update the index to find duplicates, you do not need to rebuild existing data. The index is incremented.
Due to the limited amount of RAM on the server, I have no way to keep the index in memory, which is why I keep it in MySQL where the articles themselves are stored. Checking one article, if you do not load everything into memory, takes about 9 seconds for the program. It's a long time, but because only a few dozen new articles appear per day, I decided not to bother with speed until this is needed.
This post tells how I solved these problems.
Given:
- total number of articles 140,000;
- spam: approximately 16%;
- number of unclear duplicates: approximately 63%;
Objective: get rid of spam and duplicates, as well as prevent their further occurrence.
Part 1. Spam / non-spam classification
All articles on my site are related to the same topic and, as a rule, spammers / advertising messages are decently different in content. I decided to manually sort a number of articles. And on their basis to build a classifier. For classification, we consider the cosine distance between the vector of the article being checked and the vectors of two groups (spam / non-spam). Which group the article being reviewed is closer to will group the article as well.
First you need to manually categorize the articles. I sketched a checkbox form for this and collected 650 spam articles and 2,000 non-spam articles in a few hours.
All posts are cleared of garbage - noise words that do not carry a payload (communion, interjection, etc.). To do this, I collected from different dictionaries that I found on the Internet, myvocabulary of noise words .
To minimize the number of different forms of a single word, you can use Porter's stemmm . I took the finished Java implementation from here . Thank you, Edunov.
From the words of classified articles, cleared of noise words and driven through stemming, you need to compile a dictionary.
From the dictionary we delete the words that are found in only one article.
For each manually classified article, we count the number of occurrences of each word from the dictionary. We get vectors similar to the following: We
strengthen the word weights in each vector, counting TF-IDF for them . TF-IDF is considered separately for each spam / non-spam group.
First, we consider TF (term frequency) for each article. This is the ratio of the number of occurrences of a particular word to the total number of words in the article:
where n i is the number of occurrences of the word in the document, and the denominator is the total number of words in this document.
Next, consider IDF (inverse document frequency). Inverse of the frequency with which a certain word occurs in group documents (spam / non-spam). IDF reduces the weight of words that are often used in a group. It is considered for each group.
Where
- | D | - the number of documents in the group;
- d i ⊃t i - the number of documents in which t i occurs (when n i ≠ 0).
We consider TF-IDF:
Words with high frequency within a specific document and with a low frequency of use in other documents will receive a lot of weight in TF-IDF.
For each group we form one vector, taking the arithmetic mean of each parameter within the group:
To check the article for spam, you need to get for it the number of occurrences of words from the dictionary. Count for these words TF-IDF for spam and not spam. You will get two vectors (TF-IDF is not spam and TF-IDF is spam). IDF for calculations, take the one that was considered for the classification sample.
For each vector, we consider the cosine distance with the vectors for spam and non-spam, respectively. The cosine distance is a measure of the similarity of two vectors. The scalar product of vectors and the cosine of the angle θ between them are related by the following relation:
Having two vectors A and B, we obtain the cosine distance - cos (θ)
Java code
public static double cosine(double[] a, double[] b) {
double dotProd = 0;
double sqA = 0;
double sqB = 0;
for (int i = 0; i < a.length; i++) {
dotProd += a[i] * b[i];
sqA += a[i] * a[i];
sqB += b[i] * b[i];
}
return dotProd/(Math.sqrt(sqA)*Math.sqrt(sqB));
}
The result is a range from -1 to 1. -1 means that the vectors are completely opposite, 1, that they are the same.
Which of the obtained values (for spam and not spam) will be closer to 1, and we will relate the article to that group.
When checking for similarity to non-spam, the result is the number 0.87:
for spam - 0.62:
Therefore, we believe that the article is not spam.
For testing, I manually selected another 700 records. The accuracy of the results was 98%. At the same time, what was classified erroneously, even it was difficult for me to attribute to this or that category.
Part 2. Search for fuzzy duplicates
After clearing spam, 118,000 articles remained.
To find duplicates, I decided to use an inverted index ( Inverted index ). An index is a data structure where for each word it is indicated in which documents it is contained. Accordingly, if we have a set of words, we can easily request documents containing these words.
Wiki example. Let's say we have the following documents:
T[0] = "it is what it is"
T[1] = "what is it"
T[2] = "it is a banana"
For these documents, we construct an index by indicating which document contains the word:
"a": {2}
"banana": {2}
"is": {0, 1, 2}
"it": {0, 1, 2}
"what": {0, 1}
All the words “what”, “is” and “it” are in documents 0 and 1:
{0,1} ∩ {0,1,2} ∩ {0,1,2} = {0,1}
I saved the index in the MySQL database. Indexing took about 2 days.
To search for similar articles, it is not necessary that all words coincide, therefore, when querying by index, we get all articles that have at least 75% matching words. The found ones contain similar duplicates, as well as other articles that include 75% of the original words, for example, these can be very long articles.
To weed out what is not a duplicate, you need to calculate the cosine distance between the original and those found. That which matches more than 75% is considered a duplicate. The number in 75% was derived empirically. It allows you to find sufficiently modified versions of the same article.
An example of duplicates found:
Option 1:
Cheesecake with condensed milk (without baking)
Ingredients:
* 450 grams Sour cream from 20% fat content
* 300 grams of biscuits
* 100 grams of melted butter
* 300 grams of good condensed milk
* 10 grams of instant gelatin
* 3/4 cup cold boiled water
Preparation :
Line the collapsible form with parchment paper.
Mix the cookies crushed into small crumbs with melted butter. The mixture should not be oily, but not dry. Put the mixture into the mold and tighten well. Put in the refrigerator for 30 minutes.
Mix sour cream with condensed milk.
Pour gelatin into 3/4 cup of water and swell for 10 minutes. Then melt it in a water bath so that it dissolves completely.
Gently pour gelatin into the mixture of condensed milk and sour cream, stirring thoroughly. Then pour into the form. And put in the refrigerator until completely solidified for about 2-3 hours.
When hardening, you can add fresh cranberries or sprinkle with grated chocolate or nuts.
Bon Appetit!
Option 2:
Cheesecake without baking with condensed milk
Ingredients:
Sour cream from 20% fat 450 g
-300 g cookies (I used oat)
100 g melted butter
300 g high-quality condensed milk
10 g instant gelatin
-3/4 cup cold boiled water
Preparation:
1). Cover the shape (preferably detachable) with parchment paper.
2). Grind cookies in small crumbs and mix with melted butter. The mass should not be oily, but not too dry. Put the mass in the mold and tamp well. Refrigerate for half an hour.
3). Mix sour cream with condensed milk (you can add more or less condensed milk, this is a matter of taste).
4) Pour gelatin 3/4 cup of water and leave for 10 minutes. to swell. Then melt it in a water bath so that it is completely dissolved.
5) Gelatin is slowly introduced into the sour cream-condensed mass, stirring well. Then pour into the form. And send to the refrigerator until completely solidified. I froze quickly. About 2 hours.
When hardening, I added more berries of fresh cranberries - this added piquancy and sourness. You can sprinkle with grated chocolate or nuts.
Cheesecake with condensed milk (without baking)
Ingredients:
* 450 grams Sour cream from 20% fat content
* 300 grams of biscuits
* 100 grams of melted butter
* 300 grams of good condensed milk
* 10 grams of instant gelatin
* 3/4 cup cold boiled water
Preparation :
Line the collapsible form with parchment paper.
Mix the cookies crushed into small crumbs with melted butter. The mixture should not be oily, but not dry. Put the mixture into the mold and tighten well. Put in the refrigerator for 30 minutes.
Mix sour cream with condensed milk.
Pour gelatin into 3/4 cup of water and swell for 10 minutes. Then melt it in a water bath so that it dissolves completely.
Gently pour gelatin into the mixture of condensed milk and sour cream, stirring thoroughly. Then pour into the form. And put in the refrigerator until completely solidified for about 2-3 hours.
When hardening, you can add fresh cranberries or sprinkle with grated chocolate or nuts.
Bon Appetit!
Option 2:
Cheesecake without baking with condensed milk
Ingredients:
Sour cream from 20% fat 450 g
-300 g cookies (I used oat)
100 g melted butter
300 g high-quality condensed milk
10 g instant gelatin
-3/4 cup cold boiled water
Preparation:
1). Cover the shape (preferably detachable) with parchment paper.
2). Grind cookies in small crumbs and mix with melted butter. The mass should not be oily, but not too dry. Put the mass in the mold and tamp well. Refrigerate for half an hour.
3). Mix sour cream with condensed milk (you can add more or less condensed milk, this is a matter of taste).
4) Pour gelatin 3/4 cup of water and leave for 10 minutes. to swell. Then melt it in a water bath so that it is completely dissolved.
5) Gelatin is slowly introduced into the sour cream-condensed mass, stirring well. Then pour into the form. And send to the refrigerator until completely solidified. I froze quickly. About 2 hours.
When hardening, I added more berries of fresh cranberries - this added piquancy and sourness. You can sprinkle with grated chocolate or nuts.
Full cleaning took about 5 hours.
To update the index to find duplicates, you do not need to rebuild existing data. The index is incremented.
Due to the limited amount of RAM on the server, I have no way to keep the index in memory, which is why I keep it in MySQL where the articles themselves are stored. Checking one article, if you do not load everything into memory, takes about 9 seconds for the program. It's a long time, but because only a few dozen new articles appear per day, I decided not to bother with speed until this is needed.