Reading old articles of Habr with pictures
- Tutorial
 Some time ago, I decided to refresh my knowledge and read something about graphs. “Well, of course, there should be good articles on Habré!” I thought, and I was right. There are articles and there are many of them. But they mostly look like this: one , two , three . Open and guess with one attempt why it is completely impossible to understand something from these articles, although it is written in a completely understandable language. No pictures! But how to study graphs without pictures? No way.
Some time ago, I decided to refresh my knowledge and read something about graphs. “Well, of course, there should be good articles on Habré!” I thought, and I was right. There are articles and there are many of them. But they mostly look like this: one , two , three . Open and guess with one attempt why it is completely impossible to understand something from these articles, although it is written in a completely understandable language. No pictures! But how to study graphs without pictures? No way. The newcomer on Habr will be perplexed asks: "How so - there are no pictures? There is habrastorage.org! ” Yes there is. But he wasn’t always there, and automatically pictures were poured onto him and only began in July 2013. And before that, the pictures were hosted anywhere - on all kinds of radicals, image hacks, even on dropboxs, it happened that people naively tried to spread something. As a result, we have on Habré a bunch of articles from 2006-2013 with missing pictures.
Let's fix it!
Plan
The first tasks we face are the following:
- Download all the articles from the emergence of Habr to the aforementioned post 188436, which roughly marks the beginning of the forced re-upload of pictures on habrastorage.org
- Find in the text of articles links to all pictures that are not on the Habré, Giktayms, Megamind or Habrastoraj
- Check the availability of these images (GET is not necessary, a HEAD request with a check of the return code and type of content is enough)
- Export a list of inaccessible pictures to a file
Implementation
In general, only the lazy have not yet parsed Habr, but we are not lazy. Especially since there in Python + requests write:
We upload the code to the virtual machine in the cloud, start it, return in 2 days (of course, you could parse it into several threads - but I remember somewhere in the FAQ Habr asked me not to pull it with bots more than 2 times per second).
results
In total, in the articles “Before the Coming of Habrastoraj”, 157601 images were found posted on the “left” image hosting sites . Of these, 92549 links are still valid, and 65052 links are no longer there.
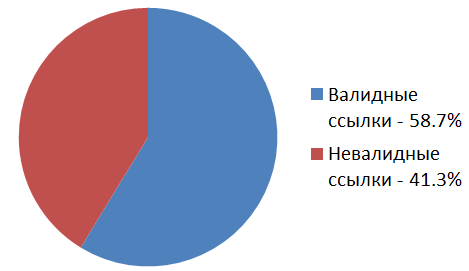
Well, ok, we have links to 65052 inaccessible images in articles on Habré. What to do with it? Get them from archive.org cache , of course! He was thought up for that!
You can check the availability of the image in the web archive with a simple request:
http://archive.org/wayback/available?url=%image_url%
For example, the link to the image img513.imageshack.us/img513/3580/pic1e.jpg missing in the article habrahabr.ru/post/63982 is quite accessible at the link http://web.archive.org/web/20131103061340/http:// img513.imageshack.us/img513/3580/pic1e.jpg There is, however, one misfortune. Sometimes the online archive claims that it has a link to a cached image, but in fact it does not. Lies, in general. Those. we will have to check every link to the cached image. Well, nothing, check . Fill, run, wait half a day.
{kind=link}
{kind=link}
results
13863 pictures from those which are no longer available on the original links in articles on the Habré were available in the web archive .
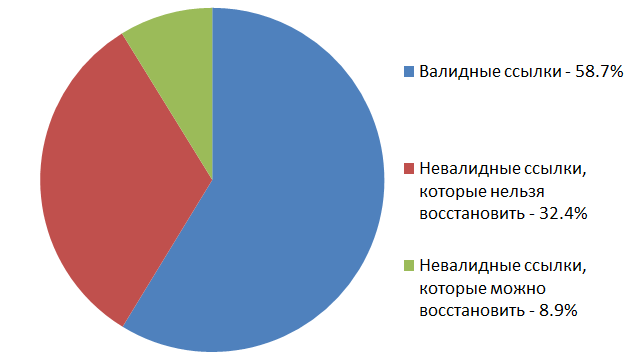
This whole experiment gave us a good “average temperature in the hospital”: we now know that a picture uploaded for random hosting has a chance of about 58% surviving over the next 2-9 years. We also know that archive.org is a useful thing and sometimes helps, but the chances of restoring with it a broken link to a picture on the Habré are 21.3%.
Conclusions to the first part of the article
So, now we have an array with still valid links to images and a second array , with broken links and their corresponding links to available images in the web archive. At this point, you could ask the Habr administration to take this data and write 4 lines of code to reload it all on habrastorage.org and update the links in existing articles, but I don’t know if they will do it. And I want to read articles in the normal form! And so we will go our own way. You can, of course, say “Read articles directly from the web archive!”, But this is somehow not very instructive, and what would all this data collection be.
The second impulse may be the desire to write an extension for Chrome, replacing bad links with good ones, but I don’t want to do this for a number of reasons:
- It is not very interesting, on Habré there were already a hundred articles about writing extensions to Chrome
- Extensions now seem to be necessarily placed in the market
- Firefox will have to write a separate extension, but with IE it’s not clear what to do (write BHO? Brrrrr!). Well, plus all sorts of Opera, Vivaldi, Safari, Yandex.browsers and the rest of the zoo.
- It is completely incomprehensible how this will help in reading from a mobile phone or tablet.
Therefore, we will go the other way and write something that solves all of the above problems. What exactly? And you will learn about this from the next article .
PS A logical separation into two articles has been added for readability, since the method used in the second article has nothing to do with pictures on the Habré, and vice versa.
UPD. As correctly prompted in the comments - you need to check and redirects. The script is fixed (thanks to the encyclopedist ) and run again. As a result, another 10,683 valid links to images were received. Files with new data are uploaded to GitHub (see links in the article).