Active failover geographically dispersed cluster running Active-Active on IBM zEnterprise EC 12 mainframe
In many areas of human activity, increased demands are placed on the performance and accessibility of services offered by information technology. An example of such areas is, for example, banking. If a major bank in the country refuses card processing for several hours, this will affect the daily needs and concerns of millions of users across the country, which will lead to a decrease in their loyalty until the decision is made to refuse the services of such a credit organization. The situation is similar with the performance and availability of many other information systems.
The solution to problems with performance and availability is, in principle, known: duplicate nodes that provide data processing, and combine them into clusters. At the same time, to ensure maximum load of available resources and reduce system downtime in case of failure of one of the nodes, the cluster should work according to the Active-Active scheme. Also, the level of accessibility provided by a cluster located entirely in one data center may be insufficient (for example, during a power outage in entire areas of large cities). Then the cluster nodes must be geographically distributed.
In this article, we will talk about the problems of building a fault-tolerant geographically dispersed cluster and the solutions offered by IBM on the basis of mainframes, as well as share the results of our testing of the performance and high availability of a real banking application in a cluster configuration, with nodes spaced up to 70 km .
Conventionally, the problems in building any Active-Active cluster can be divided into clustering problems of the application and clustering problems of the DBMS / message queue subsystem. For example, for the application we tested, there was a requirement for strict observance of the payment execution procedure from one participant. It is clear that ensuring that this requirement is met in Active-Active cluster mode has led to the need for significant changes to the application architecture. The problem was aggravated by the fact that in addition to performance in Active-Active mode, it was necessary to ensure high availability of standard middleware or operating system software. The details of how we achieved our goals are worthy of a separate article.
Modern approaches to clustering DBMSs are usually based on the shared disk architecture. The main objective of this approach is to provide synchronized access to shared data. Implementation details are highly dependent on the specific DBMS, but the most popular is the messaging approach.between cluster nodes. This solution is purely software, receiving and sending messages requires interrupting the operation of applications (accessing the network stack of the operating system). Also, with active access to shared data, the overhead can become significant, which is especially evident if the distance between active nodes increases. As a rule, the scalability coefficient of such solutions does not exceed ¾ (a cluster of four nodes, each of which has a capacity of N, provides a total performance of ¾ N).
In the case of remoteness of cluster nodes from each other, the distance has a significant impact on the performance and allowable recovery time (RTO) of the solution. As you know, the speed of light in optics is approximately 200,000 km / s, which corresponds to a delay of 10 μs per kilometer of optical fiber.
IBM mainframes use a different approach to clustering DB2 DBMS and WebSphere MQ queue managers, which is not based on programmatic messaging between cluster nodes. The solution is called Parallel Sysplex and allows you to cluster up to 32 logical partitions (LPARs) running on one or more mainframes running the z / OS operating system. Given that the new z13 mainframe can have more than 140 processors on board, the maximum achievable cluster performance cannot fail to impress.
Parallel Sysplex is based on Coupling Facility, which is dedicated logical partitions (LPAR), using processors that can run special cluster software - Coupling Facility Control Code (CFCC). The Coupling Facility in its memory stores shared data structures shared by the nodes of the Parallel Sysplex cluster. Data exchange between CF and connected systems is organized on the principle of "memory-memory" (similar to DMA), while the processors that run the application are not involved.
To ensure high availability of CF structures, synchronous and asynchronous data replication mechanisms are used between them using the z / OS operating system and the DB2 DBMS.
Those. IBM's approach is based not on a software, but on a hardware-software solution that provides data exchange between cluster nodes without interrupting running applications. Thus, a scalability coefficient close to unity is achieved , which is confirmed by the results of our load testing.
To demonstrate the scalability of the system and assess the impact of distance on performance indicators, we conducted a series of tests, the results of which we want to share with you.
One physical server zEnterprise EC 12 was used as a test bench. Two logical partitions (LPARs) MVC1 and MVC2 were deployed on this server, each of which was running the z / OS 2.1 operating system and contained 5 general-purpose processors (CP ) and 5 specialized zIIP processors designed to execute DB2 DBMS code and run Java applications. These logical partitions were clustered using the Parallel Sysplex mechanism.
For operation of the Coupling Facility mechanism, dedicated logical partitions (LPARs) CF1 and CF2 were used, each containing 2 ICF processors. The distance between CF1 and CF2 over the communication channels according to the testing scenario varied discretely, ranging from 0 to 70 km.
MVC1 was connected to CF1 via virtual channels of the ICP type, while physical channels of the Infiniband type were used to access CF2. Connecting MVC2 to CF1 and CF2 was carried out in the same way: via ICP channels to CF2 and using Infiniband to CF1.
For data storage, the IBM DS 8870 disk array was used, in which two sets of disks were created and synchronous data replication between them was set using Metro Mirror technology. The distance between the sets of discs over the communication channels according to the test scenario varied discretely, ranging from 0 to 70 km. The necessary distance between the components of the stand was provided by the use of specialized DWDM devices (ADVA) and fiber optic cables of the required length.
Each of the logical partitions MVC1 and MVC2 was connected to disk arrays using two FICON channels with a throughput of 8 GB / s.
A detailed diagram of the stand (in the version with a distance between cluster nodes of 50 km.) Is presented in the figure.
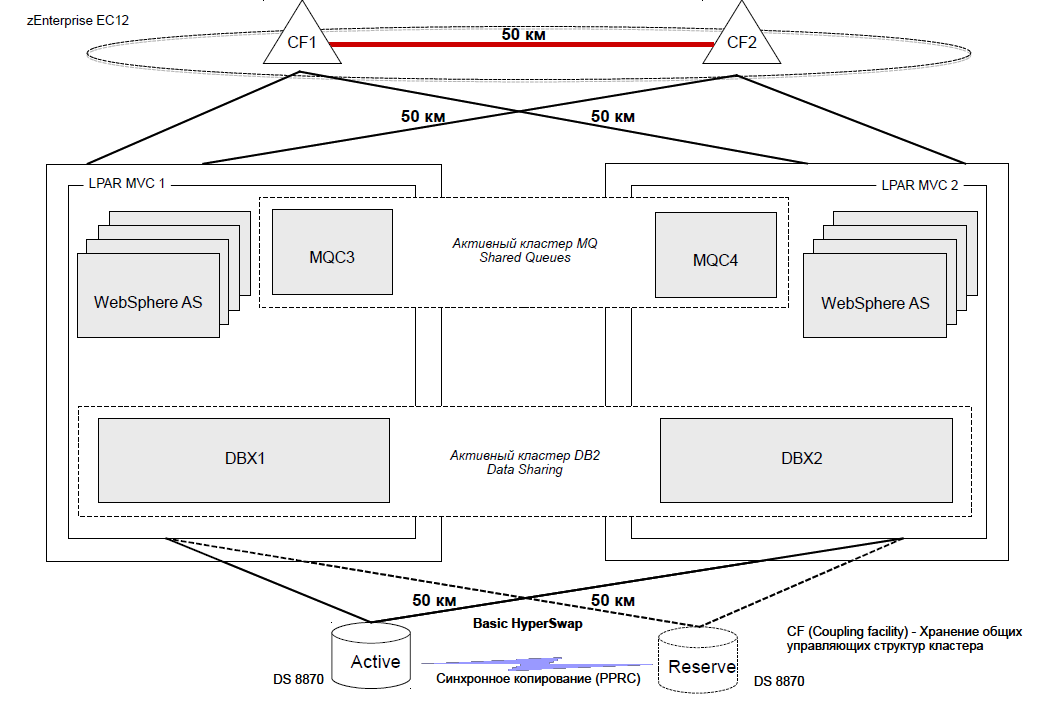
As a test application, the cluster nodes were deployedA bank payment system that uses the following IBM software for its work: DB2 z / OS DBMS, WebSphere MQ message queue managers, WebSphere Application Server for z / OS application server.
Work on setting up a test stand and installing a payment system took about three weeks.
Separately, it is necessary to talk about the principle of the application and the load profile. All processed payments can be divided into two types: urgent and non-urgent. Urgent payments are made immediately after they are read from the input queue. In the process of processing non-urgent payments, three consecutive phases can be distinguished. The first phase - the reception phase - payments are read from the input queue of the system and registered in the database. Second phase -phase of multilateral offsetting - starts on the timer several times a day and is performed strictly in single-threaded mode. At this phase, all accepted non-urgent payments are posted, while the mutual obligations of the system participants are taken into account (if Petya transfers 500 rubles to Vasya and 300 rubles to Sveta, and Vasya transfers 300 rubles to Sveta, it makes sense to immediately increase the value of Sveta's account by 600 rubles, and Vasya - for 200 rubles than to make real transactions). Third phase - the notification phase- starts automatically after the completion of the second phase. At this phase, the formation and distribution of information messages (receipts) for all accounts involved in multilateral netting is carried out. Each phase represents one or more global transactions, which are a complex sequence of actions performed by WebSphere MQ queue managers and DB2 DBMSs. Each global transaction ends with a two-phase commit, because several resources participate in it (queue - database - queue).
An important feature of the payment system is the ability to make urgent payments against the background of multilateral netting.
The load profile during testing repeated the load profile of a really working system. 2 million non-urgent payments, combined in packages of 500/1000/5000 payments, were sent to the entrance, each package corresponded to one electronic message. These packets were fed to the system input with an interval of 4 ms between each subsequent message. At the same time, about 16 thousand urgent payments were submitted, each of which corresponded to its own electronic message. These electronic messages were submitted at intervals of 10 ms. between each subsequent message.
During the load testing, the distance along the communication channels between the sets of disks, as well as between the logical partitions of the CF, changed discretely, ranging from 0 to 70 km. During the tests, the following results were recorded:
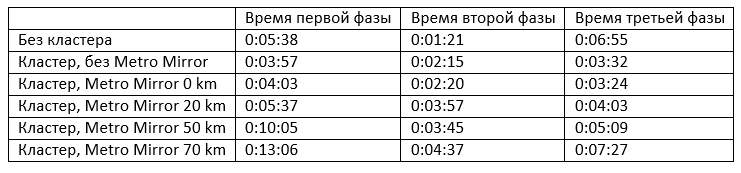
It is interesting to compare the first two lines showing the scalability of the system. It can be seen that the execution time of the first phase when using a cluster of two nodes is reduced by 1.4 times (the “nonlinearity” of scaling the first phase is explained by the peculiarities of the implementation of the requirement to comply with the payment order from one participant), and the execution time of the third phase is almost 2 times. Multilateral netting is performed in one thread. The time it takes to run in cluster mode increases because of the need to forward DB2 locks to CFs when performing bulk DML operations.
When you enable the mechanism of data replication on disks (Metro Mirror), the execution time of each phase increases slightly, by 3 - 4%. With a further increase in the distance along the communication channels between disks and between logical partitions CF, the execution time of each phase increases more intensively.
It is interesting to compare the time characteristics of processing urgent payments in extreme cases: without a cluster and in a cluster whose nodes are spaced 70 km apart.

The maximum payment processing time increased by 40%, while the average changed only by 7.6%. At the same time, the utilization of the processor resource changes slightly due to the increase in access time to CF structures.
In the article, we examined the problems that arise when building a geographically distributed cluster operating in Active-Active mode, and figured out how to avoid them by building a cluster based on IBM mainframes. Statements about the high scalability of solutions based on the Parallel Sysplex cluster are demonstrated by the results of load testing. At the same time, we checked the behavior of the system at different distances between cluster nodes: 0, 20, 50, and 70 km.
The most interesting results are demonstrated close to unity.system scalability coefficient, as well as the revealed dependence of payment processing time on the distance between cluster nodes. The smaller the distance affects key performance indicators of the system, the farther apart the cluster nodes can be from each other, thereby ensuring greater disaster tolerance.
If the topic of constructing a geographically dispersed cluster of mainframes will arouse interest among hawkeepers, then in the next article we will describe in detail the tests of high availability of the system and the results obtained. If you are interested in other questions regarding mainframes, or just want to argue, then welcome to comment. It will also be useful if someone shares their experience in building fault-tolerant solutions.
The solution to problems with performance and availability is, in principle, known: duplicate nodes that provide data processing, and combine them into clusters. At the same time, to ensure maximum load of available resources and reduce system downtime in case of failure of one of the nodes, the cluster should work according to the Active-Active scheme. Also, the level of accessibility provided by a cluster located entirely in one data center may be insufficient (for example, during a power outage in entire areas of large cities). Then the cluster nodes must be geographically distributed.
In this article, we will talk about the problems of building a fault-tolerant geographically dispersed cluster and the solutions offered by IBM on the basis of mainframes, as well as share the results of our testing of the performance and high availability of a real banking application in a cluster configuration, with nodes spaced up to 70 km .
Problems in building a geographically dispersed cluster operating on the Active-Active scheme
Conventionally, the problems in building any Active-Active cluster can be divided into clustering problems of the application and clustering problems of the DBMS / message queue subsystem. For example, for the application we tested, there was a requirement for strict observance of the payment execution procedure from one participant. It is clear that ensuring that this requirement is met in Active-Active cluster mode has led to the need for significant changes to the application architecture. The problem was aggravated by the fact that in addition to performance in Active-Active mode, it was necessary to ensure high availability of standard middleware or operating system software. The details of how we achieved our goals are worthy of a separate article.
Modern approaches to clustering DBMSs are usually based on the shared disk architecture. The main objective of this approach is to provide synchronized access to shared data. Implementation details are highly dependent on the specific DBMS, but the most popular is the messaging approach.between cluster nodes. This solution is purely software, receiving and sending messages requires interrupting the operation of applications (accessing the network stack of the operating system). Also, with active access to shared data, the overhead can become significant, which is especially evident if the distance between active nodes increases. As a rule, the scalability coefficient of such solutions does not exceed ¾ (a cluster of four nodes, each of which has a capacity of N, provides a total performance of ¾ N).
In the case of remoteness of cluster nodes from each other, the distance has a significant impact on the performance and allowable recovery time (RTO) of the solution. As you know, the speed of light in optics is approximately 200,000 km / s, which corresponds to a delay of 10 μs per kilometer of optical fiber.
IBM Mainframe Approach
IBM mainframes use a different approach to clustering DB2 DBMS and WebSphere MQ queue managers, which is not based on programmatic messaging between cluster nodes. The solution is called Parallel Sysplex and allows you to cluster up to 32 logical partitions (LPARs) running on one or more mainframes running the z / OS operating system. Given that the new z13 mainframe can have more than 140 processors on board, the maximum achievable cluster performance cannot fail to impress.
Parallel Sysplex is based on Coupling Facility, which is dedicated logical partitions (LPAR), using processors that can run special cluster software - Coupling Facility Control Code (CFCC). The Coupling Facility in its memory stores shared data structures shared by the nodes of the Parallel Sysplex cluster. Data exchange between CF and connected systems is organized on the principle of "memory-memory" (similar to DMA), while the processors that run the application are not involved.
To ensure high availability of CF structures, synchronous and asynchronous data replication mechanisms are used between them using the z / OS operating system and the DB2 DBMS.
Those. IBM's approach is based not on a software, but on a hardware-software solution that provides data exchange between cluster nodes without interrupting running applications. Thus, a scalability coefficient close to unity is achieved , which is confirmed by the results of our load testing.
Cluster Load Testing
To demonstrate the scalability of the system and assess the impact of distance on performance indicators, we conducted a series of tests, the results of which we want to share with you.
One physical server zEnterprise EC 12 was used as a test bench. Two logical partitions (LPARs) MVC1 and MVC2 were deployed on this server, each of which was running the z / OS 2.1 operating system and contained 5 general-purpose processors (CP ) and 5 specialized zIIP processors designed to execute DB2 DBMS code and run Java applications. These logical partitions were clustered using the Parallel Sysplex mechanism.
For operation of the Coupling Facility mechanism, dedicated logical partitions (LPARs) CF1 and CF2 were used, each containing 2 ICF processors. The distance between CF1 and CF2 over the communication channels according to the testing scenario varied discretely, ranging from 0 to 70 km.
MVC1 was connected to CF1 via virtual channels of the ICP type, while physical channels of the Infiniband type were used to access CF2. Connecting MVC2 to CF1 and CF2 was carried out in the same way: via ICP channels to CF2 and using Infiniband to CF1.
For data storage, the IBM DS 8870 disk array was used, in which two sets of disks were created and synchronous data replication between them was set using Metro Mirror technology. The distance between the sets of discs over the communication channels according to the test scenario varied discretely, ranging from 0 to 70 km. The necessary distance between the components of the stand was provided by the use of specialized DWDM devices (ADVA) and fiber optic cables of the required length.
Each of the logical partitions MVC1 and MVC2 was connected to disk arrays using two FICON channels with a throughput of 8 GB / s.
A detailed diagram of the stand (in the version with a distance between cluster nodes of 50 km.) Is presented in the figure.
As a test application, the cluster nodes were deployedA bank payment system that uses the following IBM software for its work: DB2 z / OS DBMS, WebSphere MQ message queue managers, WebSphere Application Server for z / OS application server.
Work on setting up a test stand and installing a payment system took about three weeks.
Separately, it is necessary to talk about the principle of the application and the load profile. All processed payments can be divided into two types: urgent and non-urgent. Urgent payments are made immediately after they are read from the input queue. In the process of processing non-urgent payments, three consecutive phases can be distinguished. The first phase - the reception phase - payments are read from the input queue of the system and registered in the database. Second phase -phase of multilateral offsetting - starts on the timer several times a day and is performed strictly in single-threaded mode. At this phase, all accepted non-urgent payments are posted, while the mutual obligations of the system participants are taken into account (if Petya transfers 500 rubles to Vasya and 300 rubles to Sveta, and Vasya transfers 300 rubles to Sveta, it makes sense to immediately increase the value of Sveta's account by 600 rubles, and Vasya - for 200 rubles than to make real transactions). Third phase - the notification phase- starts automatically after the completion of the second phase. At this phase, the formation and distribution of information messages (receipts) for all accounts involved in multilateral netting is carried out. Each phase represents one or more global transactions, which are a complex sequence of actions performed by WebSphere MQ queue managers and DB2 DBMSs. Each global transaction ends with a two-phase commit, because several resources participate in it (queue - database - queue).
An important feature of the payment system is the ability to make urgent payments against the background of multilateral netting.
The load profile during testing repeated the load profile of a really working system. 2 million non-urgent payments, combined in packages of 500/1000/5000 payments, were sent to the entrance, each package corresponded to one electronic message. These packets were fed to the system input with an interval of 4 ms between each subsequent message. At the same time, about 16 thousand urgent payments were submitted, each of which corresponded to its own electronic message. These electronic messages were submitted at intervals of 10 ms. between each subsequent message.
Stress test results
During the load testing, the distance along the communication channels between the sets of disks, as well as between the logical partitions of the CF, changed discretely, ranging from 0 to 70 km. During the tests, the following results were recorded:
It is interesting to compare the first two lines showing the scalability of the system. It can be seen that the execution time of the first phase when using a cluster of two nodes is reduced by 1.4 times (the “nonlinearity” of scaling the first phase is explained by the peculiarities of the implementation of the requirement to comply with the payment order from one participant), and the execution time of the third phase is almost 2 times. Multilateral netting is performed in one thread. The time it takes to run in cluster mode increases because of the need to forward DB2 locks to CFs when performing bulk DML operations.
When you enable the mechanism of data replication on disks (Metro Mirror), the execution time of each phase increases slightly, by 3 - 4%. With a further increase in the distance along the communication channels between disks and between logical partitions CF, the execution time of each phase increases more intensively.
It is interesting to compare the time characteristics of processing urgent payments in extreme cases: without a cluster and in a cluster whose nodes are spaced 70 km apart.
The maximum payment processing time increased by 40%, while the average changed only by 7.6%. At the same time, the utilization of the processor resource changes slightly due to the increase in access time to CF structures.
conclusions
In the article, we examined the problems that arise when building a geographically distributed cluster operating in Active-Active mode, and figured out how to avoid them by building a cluster based on IBM mainframes. Statements about the high scalability of solutions based on the Parallel Sysplex cluster are demonstrated by the results of load testing. At the same time, we checked the behavior of the system at different distances between cluster nodes: 0, 20, 50, and 70 km.
The most interesting results are demonstrated close to unity.system scalability coefficient, as well as the revealed dependence of payment processing time on the distance between cluster nodes. The smaller the distance affects key performance indicators of the system, the farther apart the cluster nodes can be from each other, thereby ensuring greater disaster tolerance.
If the topic of constructing a geographically dispersed cluster of mainframes will arouse interest among hawkeepers, then in the next article we will describe in detail the tests of high availability of the system and the results obtained. If you are interested in other questions regarding mainframes, or just want to argue, then welcome to comment. It will also be useful if someone shares their experience in building fault-tolerant solutions.