How to write a fast database scripting and deployment system
Part One, Historical
Now historians are trying to present
that in fifteen hundred some year
something was there.
Yes there was nothing!
V.S. Chernomyrdin
So, it all started back in 2006, when I got into the it-company, which was engaged in the development of solutions in the field of telecommunications. Our team developed a C # application that received some data from the MS Sql Server database, processed it, and folded it back. At first, there were about 10 tables and a couple of stored procedures in our database. Over time, the number of tables and other objects began to grow. We began to think about how to manage these facilities. We stored the scripts in the version control system.
Initially, we used DB Project from Visual Studio, but over time it became obvious that this environment takes a very long time to deploy, because compares the target database and source scripts. In addition, in the database we needed a part of the objects from the large subsystem with which we integrated and which we did not want to store in our repository. As a result, we wrote a simple application that took an xml file with a list of objects that we want to deploy. This file was edited manually by each developer, and its “textual nature” made it possible to resolve conflicts during commits. In the future, we abandoned the xml file in favor of a strict order of storage of scripts and the order of their roll. (tables rolled up before presentations, etc.)
Everything was fine until a new problem appeared. Our technical support could edit the code in the release branch, as well as sometimes make changes directly on the client, which led to problems when installing the next release. We decided to implement a subsystem that would detect “illegal” changes on the client. Our application scripted the database, sent scripts to our server, deployed them to the correct structure, and then our deployment system was connected, which received two databases at the output - from the repository and from the client. Next, the same Visual Studio was launched, which compared the databases.
The scripting was done using the SMO (Server Management Objects) library .
It was easy to work with, but there was one big problem - speed. She could script about 6 objects per second. The database on the client consisted of about 10,000 objects and the scripting process took half an hour.
A few months ago, my colleague and I decided to implement the fastest system of scripting and database deployment, taking into account all the advantages and disadvantages of what we have already done. That's what we got.
Part Two, Technical
Modern technology has so
facilitated the work of women
that men have a
lot of free time.
Vladislav Gzheshchik
Scripting
For the scripting system, we have identified the following requirements:
• Support for all versions of Ms Sql Server, starting from 2008;
• Scripts must be formed in parallel (the scripting of any database should last seconds, not minutes);
• The structure of the script storage must be defined in the settings;
• Ability to select the types of objects that need to be scripted (for example, to receive scripts of only stored procedures);
• Storage of scripts in the file system, archive, cloud service.
First of all, we tried to run scripting through SMO in parallel, but we got about 60 objects per second, which was no good. It was decided to use meta information from the Ms Sql Server system objects from which it was possible to form a script. We began to think, and how to form a script using some abstract data. And here El-expressions from Java came to our aid. After a short coding, we got our own template engine.
Example template for generating a primary key script:
${templ::if_cont_coll(${PKFields},${ALTER TABLE [${Schema}].[${TableName}] ADD ${templ::if_cont_field_val(${PKName},${ CONSTRAINT [${PKName}] },${})}${ConstraintType} ${PKType}
(
${templ::for(${PKFields}, ${[${FieldName}] ${Order}},${,
})}
)WITH (${PKProperties})${templ::if_cont_field_val(${PKFileGroup},${ ON [${PKFileGroup}]},${})}${templ::if_cont_coll(${PartitionPKFields},${(${templ::for(${PartitionPKFields},${[${PartitionFieldName}]},${,})})})}})}
This template in its logical structure resembles a description from MSDN .
When loading meta information about a database object, we form a set of fields and collections. For a specific primary key, we get fields such as Schema, TableName, etc. We load the fields on which the key is built into the PKFields collection.
The template engine allows you to implement any functions. For example, you can organize a conditional IF ... ELSE statement, a FOR statement, etc. (in the example, all functions begin with the keyword templ: :).
Now we have templates for each type of object, it is time to solve the problem of slow scripting.
We created a special TypeMapper file that contains information about a specific type of scripting. Excerpt from this file:
This structure allows you to define different rules, depending on the version of Ms Sql Server, specify the mask of the path along which the script will be saved (the same template engine), determine the type names responsible for loading meta information and forming the script template.
As a result, we get a list of types that we are going to script and build the following processing pipeline:
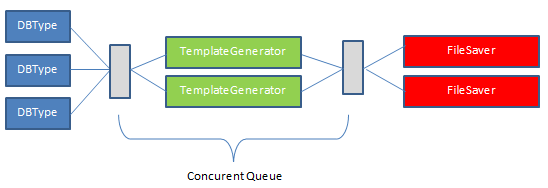
As a result, we create N queries in Ms Sql Server and use them to create descriptor objects that describe a specific object and pass it to TemplateGenerator through a competitive queue. The template generator works in parallel by the number of logical cores and passes the finished script with its name to FileSaver through another competitive queue. FileSaver saves files in parallel, depending on the bandwidth of the disk subsystem.
As a result, the database containing 15,000 objects is scripted in 50 seconds on a regular desktop computer with a local Ms Sql Server instance, while SMO can do this in 50 minutes!
Also during scripting we form a special dependency graph, which will be discussed in more detail in the next part.
Deployment
In the first part of the article, I told that at the beginning we deployed scripts from a flat list, which was formed by the developers. We decided that it was inconvenient and tried to solve this problem. When scripting, we form a special dependency graph, which contains information about which particular script should be deployed in order. Thus, we can execute scripts that are on the same level, in parallel.
You may ask, what if there is a dependency graph, and new scripts have been added to the script directory?
In this case, if the script is not found in the dependency graph, it is considered independent and is executed in the first batch. If it "crashes", then such a script is placed in the queue of the "second chance". After deploying all the scripts, the redeployment from the second chance queue occurs. This is repeated until the new line of the "second chance" is empty.
Part Three, Practical
Theoretically,
anything can happen . But in practice,
everything that is objectionable often happens.
Yuri Tatarkin
So what we managed to get. We learned how to quickly get scripts of any database objects. Run scripts, given their dependencies. What have we made of these opportunities.
Spindle Scripting Too l is a desktop application that allows you to get database scripts in a few clicks by selecting the types of objects for scripting. You can change the script file name generation patterns. Scripts can be saved on disk, in archive, in the cloud service. Along with this, a dependency graph and a project file are generated, which allows you to perform a deployment by simply selecting the desired project file.
Spindle SSMS Addin- Add-on for Sql Server Management Studio. This add-on allows you to create database scripts by selecting a database in the Object Explorer window. And also unique functionality - right in the script editor window, having selected the database object, press the right mouse button and select the command for receiving the script in the context menu. The script will form in a few milliseconds and open in a new editor window. This function, unlike the built-in feature, works great with remote servers.
Well, for the sweet - we realized that we can compare 2 databases with each other in a matter of seconds.
Spindle Comparer is an ultrafast database comparator. Just select any 2 databases and click the Compare button.