Dictionary implementation in Python 2.7
This article will talk about how a dictionary is implemented in Python. I will try to answer the question why the elements of the dictionary are not ordered, to describe how the dictionaries store, add and delete their elements. I hope that this article will be useful not only to people learning Python, but also to everyone who is interested in the internal structure and organization of data structures.
The question on Stack Overflow prompted me to write this article .
This article discusses the implementation of CPython version 2.7. All examples were prepared in a 32-bit version of Python on a 64-bit OS, for another version the values will differ.
A dictionary in Python is an associative array, that is, it stores data in the form of pairs (key, value). A dictionary is a mutable data type. This means that you can add elements to it, modify them and delete them from the dictionary. It also provides the operation of finding and returning an item by key.
Initializing and adding items:
Receive item:
Delete item:
Dictionary keys can only be values of hashable types, that is, types that can have a hash (for this they must have a __hash __ () method). Therefore, values of types such as a list, a set, and the dictionary itself (dict) cannot be dictionary keys:
A dictionary in Python is implemented as a hash table. As you know, the implementation of the hash table must take into account the possibility of collisions - situations where different keys have the same hash value. There should be a way to insert and extract elements taking into account collisions. There are several ways to resolve collisions, such as the chaining method and the open addressing method. Python uses the open addressing method. The developers preferred the open addressing method to the chaining method because it can significantly save memory by storing pointers that are used in chain hash tables.
In this implementation, each entry (PyDictEntry) in the dictionary hash table consists of three elements - a hash, a key, and a value.
The structure of PyDictObject is as follows:
When creating a new dictionary object, its size is 8. This value is determined by the PyDict_MINSIZE constant. To store the hash table, the variables ma_smalltable and ma_table were introduced in PyDictObject. The ma_smalltable variable with pre-allocated memory of size PyDict_MINSIZE (i.e. 8) allows small dictionaries (up to 8 PyDictEntry objects) to be stored without additional memory allocation. The experiments conducted by the developers showed that this size is quite enough for most dictionaries: small instance dictionaries and usually small dictionaries created to pass named arguments (kwargs). The ma_table variable corresponds to ma_smalltable for small tables (that is, for tables of 8 cells). For larger tables, ma_table is allocated separately. The ma_table variable cannot be NULL.
If someone suddenly wants to change the value of PyDict_MINSIZE, this can be done in the sources, and then rebuild Python. The value is recommended to be equal to the power of two, but not less than four.
1) Unused (me_key == me_value == NULL)
This state means that the cell does not contain and has never contained a pair (key, value).
After inserting the key, the “unused” cell goes into the “active” state.
This state is the only case when me_key = NULL and is the initial state for all cells in the table.
2) Active (me_key! = NULL and me_key! = Dummy and me_value! = NULL)
Means that the cell contains an active pair (key, value).
After removing the key, the cell from the active state goes into the empty state (that is, me_key = dummy, and
dummy = PyString_FromString ("")).
This is the only state when me_value! = NULL.
3) Empty (me_key == dummy and me_value == NULL)
This state indicates that the cell previously contained the active pair (key, value), but it was deleted , and the new active pair has not yet been written to the cell.
Just like in the “unused” state, after inserting the key, the cell from the “empty” state goes into the “active” state. The
“empty” cell cannot return to the “unused" state, that is, return me_key = NULL, since in this case the sequence of samples in the event of a collision will not be possible find out if the cell "active."
ma_fill - the number of non-zero keys (me_key! = NULL), that is, the sum of the "active" and "empty" cells.
ma_used - the number of non-zero and non-empty keys (me_key! = NULL, me_key! = dummy), that is, the number of "active" cells.
ma_mask - mask equal to PyDict_MINSIZE - 1.
ma_lookup - search function. By default, lookdict_string is used when creating a new dictionary. This is done because the developers decided that most dictionaries contain only string keys.
The effectiveness of the hash table depends on the availability of “good” hash functions. A “good” hash function must be computed quickly and with a minimum of collisions. But, unfortunately, the most frequently used and important hash functions (for string and integer types) return fairly regular values, which leads to collisions. Take an example:
Для целых чисел хэшами являются их значения, поэтому подряд идущие числа будут иметь подряд идущие хэши, а для строк подряд идущие строки имеют практически подряд идущие хэши. Это не обязательно плохо, напротив, в таблице размером 2**i взятие i младших бит хэша как начального индекса таблицы выполняется очень быстро, и для словарей, проиндексированных последовательностью целых чисел, коллизий не будет вообще:
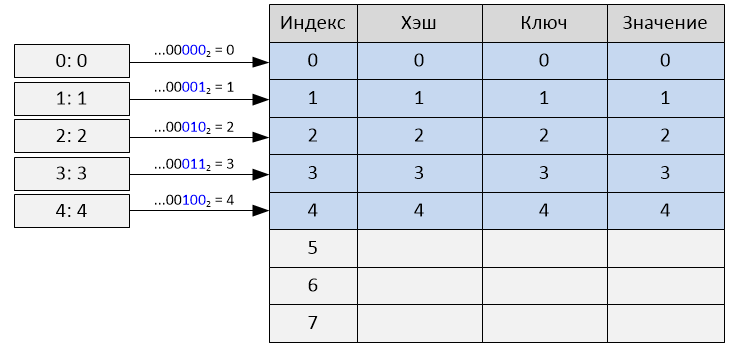
То же самое будет почти полностью соблюдаться, если ключи словаря – это «подряд идущие» строки (как в примере выше). В общих случаях это дает более чем случайное поведение, что и требуется.
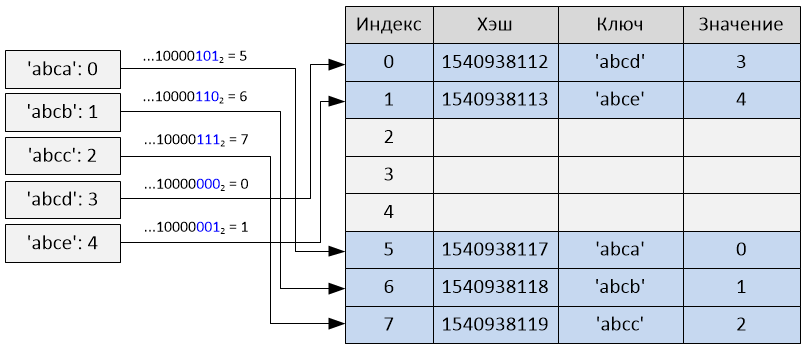
Taking only the i least significant bits of the hash as an index is also vulnerable to collisions: for example, take the list [i << 16 for i in range (20000)] as a set of keys. Since integers are their own hashes and this fits into a dictionary of size 2 ** 15 (since 20,000 <32768), the last 15 bits from each hash will all be 0.
It turns out that all the keys will have the same index. That is, for all keys (except the first) collisions will occur.
Examples of specially selected “bad” cases should not affect ordinary cases, so just leave the last i bits. Everything else is left to the conflict resolution method.
The procedure for selecting a suitable cell to insert an item into the hash table is called probing, and the candidate cell in question is called probing.
Typically, the cell is located on the first try (and this is indeed so, because the hash table fill factor is kept below 2/3), which allows you to save time on probing and makes calculating the initial index very fast. But let's look at what happens if a conflict occurs.
The first part of the collision resolution method is to calculate the indices of the table for probing using the formula:
For any initial j within [0 .. (2 ** i - 1)], invoking this formula 2 ** i times will return each number within [0 .. (2 ** i - 1)] exactly once. For instance:
You will say that this is no better than using linear sampling with a constant step, because in this case the cells in the hash table are also scanned in a certain order, but this is not the only difference. In general cases, when the hash of the key values goes in a row, this method is better than linear probing. From the example above, it can be seen that for a table of size 8 (2 ** 3), the order of the indices will be as follows:
If there is a collision for a sample with an index of 5, then the next index of the sample will be 2, not 6, as in the case of linear testing with a step of +1, therefore, for a key added in the future, the sample index of which will be 6, no collision will occur . Linear probing in this case (with sequential key values) would be a bad option, since there would be many collisions. The likelihood that the hash of the key value will go in the order of 5 * j + 1 is much less.
The second part of the method for resolving collisions is to use not only the lower i bits of the hash, but also the remaining bits, too. This is implemented using the perturb variable as follows:
After that, the sequence of probes will depend on each bit of the hash. Pseudo-random variation is very effective because it quickly increases the differences in bits. Since the perturb variable is unsigned, if testing is performed often enough, the perturb variable eventually becomes and remains equal to zero. At this moment (which is very rarely achieved), the result j again becomes 5 * j + 1. Further, the search occurs in exactly the same way as in the first part of the method, and a free cell will ultimately be found, since, as was said earlier, each a number in the range [0 .. (2 ** i - 1)] will be returned exactly once, and we are sure that there is always at least one “unused" cell.
Choosing a “good” value for PERTURB_SHIFT is a matter of balance. If you make it small, then the high bits of the hash will affect the sequence of probes through iterations. If you make it large, then in really “bad” cases, the high bits of the hash will only affect the early iterations. As a result of experiments conducted by one of the Python developers, Tim Peters, the value PERTURB_SHIFT was chosen equal to 5, since this value turned out to be "the best". That is, it showed the minimum total number of collisions for both normal and specially selected “bad” cases, although values 4 and 6 were not significantly worse.
Historical note: One of the Python developers, Reimer Berends, proposed the idea of using a polynomial-based table index calculation approach, which was then improved by Christian Tismer. This approach also showed excellent results for collisions, but required more operations, as well as an additional variable to store the table polynomial in the PyDictObject structure. In the experiments of Tim Peters, the current method used in Python turned out to be faster, showing equally good results on the occurrence of collisions, but it required less code and used less memory.
When you create a dictionary, the PyDict_New function is called. The following operations are performed sequentially in this function: memory is allocated for a new PyDictObject dictionary object. The ma_smalltable variable is cleared. The variables ma_used and ma_fill are set to 0, ma_table becomes equal to ma_smalltable. The value of ma_mask is equal to PyDict_MINSIZE - 1. The function for searching ma_lookup is set to lookdict_string. The created dictionary object is returned.
When adding an element to the dictionary or changing the value of an element in the dictionary, the PyDict_SetItem function is called. In this function, the hash value is taken and the insertdict function is called, as well as the dictresize function, if the table is filled 2/3 of the current size.
In turn, the call to lookdict_string (or lookdict if the dictionary does not have a string key) is called in the insertdict function, in which a free cell is searched in the hash table for insertion. The same function is used to find the key during extraction.
The initial index of the sample in this function is calculated as a hash of the key divided modulo the size of the table (thus, the lower bits of the hash are captured). I.e:
In Python, this is implemented using the logical AND operation and a mask. The mask is equal to the following value: mask = PyDict_MINSIZE - 1.
This produces the least significant bits of the hash:
2 ** i = PyDict_MINSIZE, hence i = 3, that is, the three least significant bits are enough.
hash (123) = 123 = 1111011 2
mask = PyDict_MINSIZE - 1 = 8 - 1 = 7 = 111 2
index = hash (123) & mask = 1111011 2 & 111 2 = 011 2 = 3
After the index is calculated, the cell is checked by the index, and if it is "unused", a record is added to it (hash, key, value). But if this cell is busy due to the fact that another record has the same hash (i.e., a collision has occurred), the hash and key of the inserted record and the record in the cell are compared. If the hash and the key for the entries match, then it is considered that the entry already exists in the dictionary, and its updating is performed.
This explains the tricky moment associated with adding equal in value, but different in type of keys (for example, float, int and complex):
That is, the type that was first added to the dictionary will be the key type, despite the update. This is because the hash implementation for float values returns the hash from int if the fractional part is 0.0. An example hash calculation for float, rewritten in Python:
And the hash from complex returns the hash from float. In this case, the hash of only the real part is returned, since the imaginary part is zero:
Example:
Due to the fact that both hashes and values are equal for all three types, a simple update of the value of the found record is performed.
Note on adding elements: Python prohibits adding elements to the dictionary during iteration, so an error will occur when trying to add a new element:
Let's return to the procedure of adding an element to the dictionary. After successfully adding or updating a record in the hash table, the next candidate record for insertion is compared. If the hash or key of the records do not match, probing begins. Searches for the “unused" cell to insert. This Python implementation uses random (and if the perturb variable is zero - quadratic) probing. As described above, with random probing, the index of the next cell is selected in a pseudo-random manner. The record is added to the first “unused” cell found. That is, two keys a and b, for which hash (a) == hash (b), but a! = B can easily exist in one dictionary. If the cell at the initial index of the sample is “empty”, probing will occur. And if the first cell found is “zero”, then the “empty” cell will be reused. This allows you to overwrite deleted cells, while retaining unused ones.
It turns out that the indices of the elements added to the dictionary depend on the elements already in it, and the order of the keys for two dictionaries consisting of the same set of pairs (key, value) can be different and is determined by the order of adding the elements:
This explains why dictionaries in Python display stored pairs (key, value) in the order in which they are added to the dictionary when displaying content. Dictionaries output them in the order in the hash table (i.e. in index order).
Consider an example:
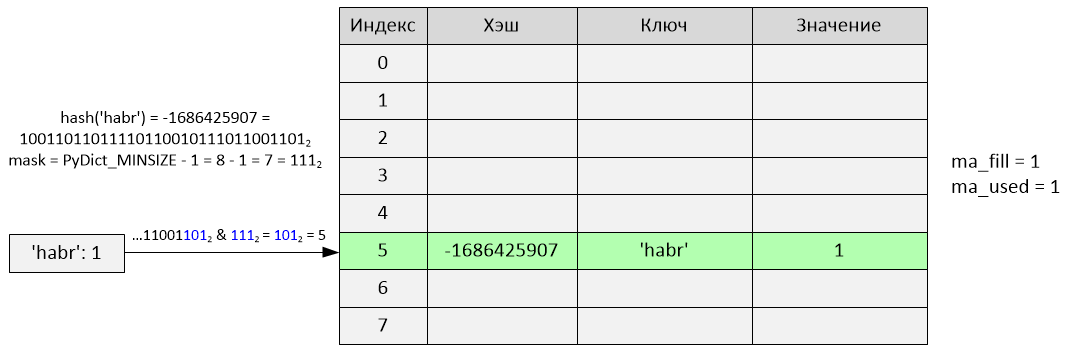
An insert was made at index 5. The variables ma_fill and ma_used became equal to 1.
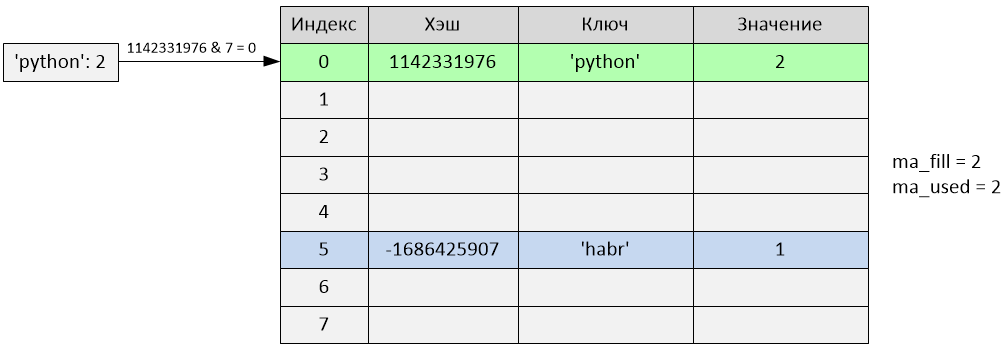
Index 0 was inserted. The variables ma_fill and ma_used became equal to 2.
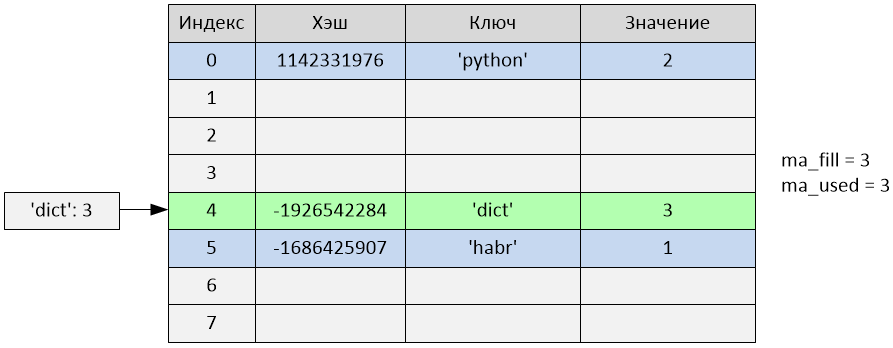
Index 4 was inserted. The variables ma_fill and ma_used became equal to 3.
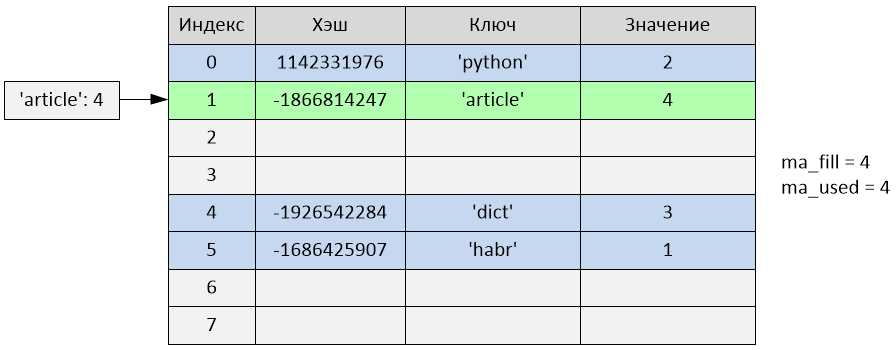
An insert was made at index 1. The variables ma_fill and ma_used became equal to 4.
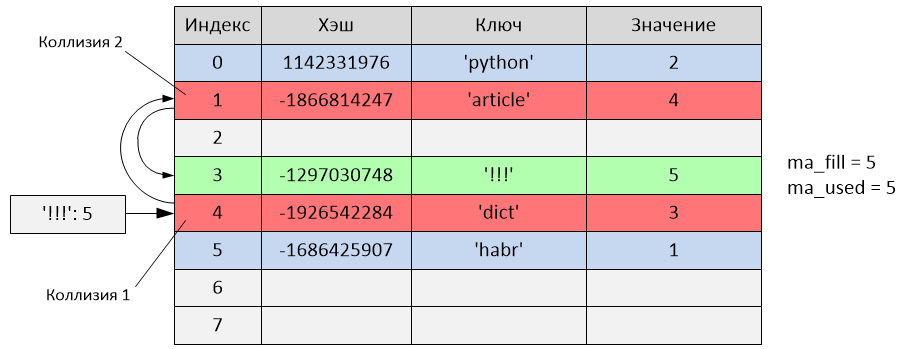
The following happened:
hash ('!!!') = -1297030748
i = -1297030748 & 7 = 4
But as you can see from the table, index 4 is already occupied by the record with the key 'dict'. That is, a collision occurred.
Testing begins: perturb = -1297030748
i = (i * 5) + 1 + perturb
i = (4 * 5) + 1 + (-1297030748) = -1297030727
index = -1297030727 & 7 = 1 The
new sample index is 1, but this index is also busy (record with the key 'article'). Another collision occurred, we continue to
test : perturb = perturb >> PERTURB_SHIFT
perturb = -1297030748 >> 5 = -40532211
i = (i * 5) + 1 + perturb
i = (-1297030727 * 5) + 1 + (-40532211) = -6525685845
index = -6525685845 & 7 = 3
The new sample index is 3, and since it is not busy, an entry is inserted with the key '!!!' into the cell with the third index. In this case, the record was added after two trials due to collisions. Variables ma_fill and ma_used became equal to 5.
We are trying to add the sixth element to the dictionary.
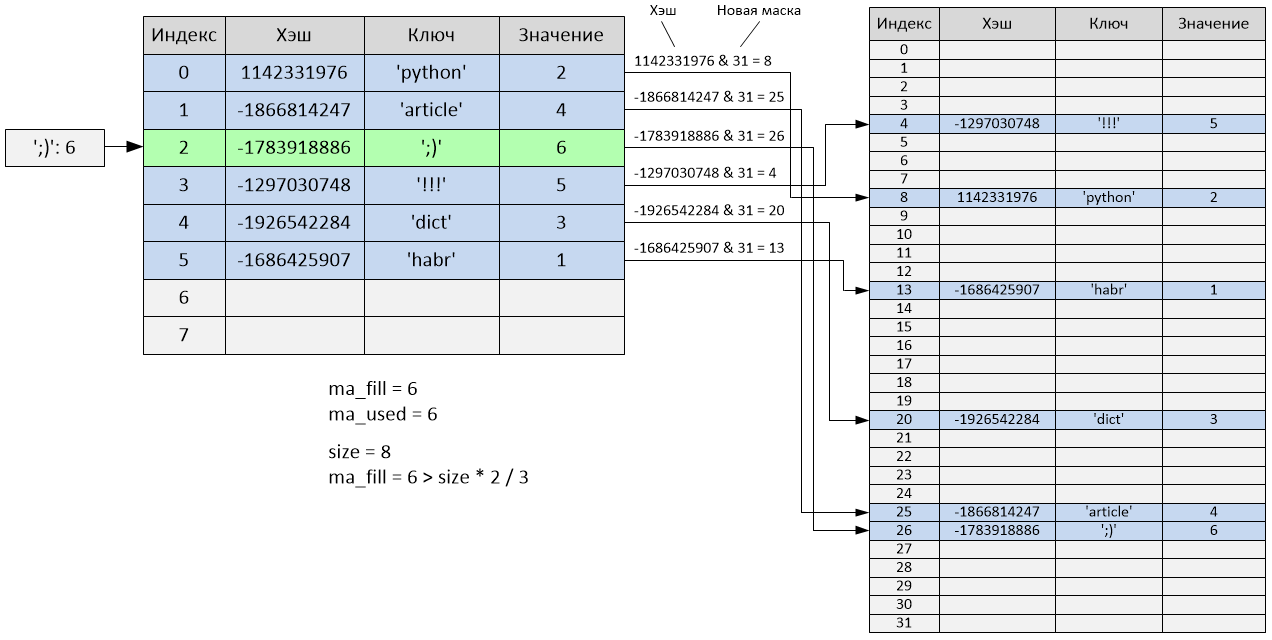
After adding the sixth element, the table will be filled in 2/3, and accordingly, its size will change. After the size has changed (in this case, it will increase 4 times), the hash table will be completely rebuilt taking into account the new size - all "active" cells will be redistributed, and "empty" and "unused" cells will be ignored.
The size of the hash table is now 32, and the variables ma_fill and ma_used are now equal to 6. As you can see, the order of the elements has completely changed:
The search for entries in the dictionary hash table is similar, starting from cell i, where i depends on the key hash. If the hash and key do not coincide with the hash and key of the found record (that is, there was a conflict and you need to find the appropriate record), testing starts, which continues until a record is found for which the hash and key match. If all the cells were viewed, but the record was not found, an error is returned.
The size of the table changes when it is filled in 2/3. That is, for the initial size of the dictionary hash table equal to 8, the change will occur after 6 elements are added.
At the same time, the hash table is rebuilt taking into account its new size, and accordingly, the indexes of all records change.
The value 2/3 of the size was chosen as optimal, so that the sampling would not take too much time, that is, the insertion of a new record was quick. Increasing this value leads to the fact that the dictionary is denser filled with entries, which in turn increases the number of collisions. Decreasing it increases the sparseness of the records to the detriment of the increase in the processor cache lines occupied by them and to the detriment of the increase in the total memory. Checking the filling of the table occurs in a very time-sensitive piece of code. Attempts to make verification more complex (for example, by changing the fill factor for different sizes of the hash table) reduced performance.
You can verify that the dictionary size is really changing by:
The example returns the size of the entire PyDictObject for the 64-bit version of the OS.
The initial size of the table is 8. Thus, when the number of filled cells is 6 (that is, more than 2/3 of the size), the size of the table will increase to 32. Then, when the number is 22, it will increase to 128. At 86, it will increase to 512 , at 342 - until 2048 and so on.
The coefficient of increasing the size of the table upon reaching the maximum fill level is 4 if the size of the table is less than 50,000 elements, and 2 for larger tables. This approach may be useful for memory-limited applications.
Increasing the size of the table improves the average sparseness, that is, the dispersion of entries in the dictionary table (reducing collisions), due to an increase in the amount of memory consumed and the speed of iterations, and also reduces the number of expensive memory allocation operations when resizing for a growing dictionary.
Usually adding an element to the dictionary can increase its size by 4 or 2 times depending on the current size of the dictionary, but it is also possible that the size of the dictionary decreases. This situation can happen if ma_fill (the number of non-zero keys, the sum of the "active" and "empty" cells) is much larger than ma_used (the number of "active" cells), that is, many keys have been deleted.
When an item is deleted from the dictionary, the PyDict_DelItem function is called.
Deletion from the dictionary occurs by key, although in reality memory is not released. In this function, the hash value of the key is calculated, and then a record is searched in the hash table using the same lookdict_string or lookdict function. If a record with such a key and hash is found, the key of this record is set to “empty” (that is, me_key = dummy), and the record value is set to NULL (me_value = NULL). After that, the ma_used variable will decrease by one, and ma_fill will remain unchanged. If the record is not found, an error is returned.
After deletion, the ma_used variable became equal to 4, and ma_fill remained equal to 5, since the cell was not deleted, but was just marked as “empty” and continues to occupy the cell in the hash table.
When you run python, you can use the -R switch to use a pseudo-random salt. In this case, the hash of values of types such as strings, buffer, bytes, and datetime objects (date, time, and datetime) will be unpredictable between calls to the interpreter. This method is proposed as protection against DoS attacks.
github.com/python/cpython/blob/2.7/Objects/dictobject.c
github.com/python/cpython/blob/2.7/Include/dictobject.h
github.com/python/cpython/blob/2.7/Objects/dictnotes. txt
www.shutupandship.com/2012/02/how-hash-collisions-are-resolved-in.html
www.laurentluce.com/posts/python-dictionary-implementation
rhodesmill.org/brandon/slides/2010-03-pycon
www.slideshare.net/MinskPythonMeetup/ss-26224561 - Dictionary in Python. Based on Objects / dictnotes.txt - SlideShare (Cyril notorca Lashkevich)
www.youtube.com/watch?v=JhixzgVpmdM - Video of the report “Dictionary in Python. Based on Objects / dictnotes.txt »
The question on Stack Overflow prompted me to write this article .
This article discusses the implementation of CPython version 2.7. All examples were prepared in a 32-bit version of Python on a 64-bit OS, for another version the values will differ.
Python dictionary
A dictionary in Python is an associative array, that is, it stores data in the form of pairs (key, value). A dictionary is a mutable data type. This means that you can add elements to it, modify them and delete them from the dictionary. It also provides the operation of finding and returning an item by key.
Initializing and adding items:
>>> d = {} # то же самое, что d = dict()
>>> d['a'] = 123
>>> d['b'] = 345
>>> d['c'] = 678
>>> d
{'a': 123, 'c': 678, 'b': 345}
Receive item:
>>> d['b']
345
Delete item:
>>> del d['c']
>>> d
{'a': 123, 'b': 345}
Dictionary keys can only be values of hashable types, that is, types that can have a hash (for this they must have a __hash __ () method). Therefore, values of types such as a list, a set, and the dictionary itself (dict) cannot be dictionary keys:
>>> d[list()] = 1
Traceback (most recent call last):
File "", line 1, in
TypeError: unhashable type: 'list'
>>> d[set()] = 2
Traceback (most recent call last):
File "", line 1, in
TypeError: unhashable type: 'set'
>>> d[dict()] = 3
Traceback (most recent call last):
File "", line 1, in
TypeError: unhashable type: 'dict'
Implementation
A dictionary in Python is implemented as a hash table. As you know, the implementation of the hash table must take into account the possibility of collisions - situations where different keys have the same hash value. There should be a way to insert and extract elements taking into account collisions. There are several ways to resolve collisions, such as the chaining method and the open addressing method. Python uses the open addressing method. The developers preferred the open addressing method to the chaining method because it can significantly save memory by storing pointers that are used in chain hash tables.
In this implementation, each entry (PyDictEntry) in the dictionary hash table consists of three elements - a hash, a key, and a value.
typedef struct {
Py_ssize_t me_hash;
PyObject *me_key;
PyObject *me_value;
} PyDictEntry;
The structure of PyDictObject is as follows:
#define PyDict_MINSIZE 8
typedef struct _dictobject PyDictObject;
struct _dictobject {
PyObject_HEAD
Py_ssize_t ma_fill;
Py_ssize_t ma_used;
Py_ssize_t ma_mask;
PyDictEntry *ma_table;
PyDictEntry *(*ma_lookup)(PyDictObject *mp, PyObject *key, long hash);
PyDictEntry ma_smalltable[PyDict_MINSIZE];
};
When creating a new dictionary object, its size is 8. This value is determined by the PyDict_MINSIZE constant. To store the hash table, the variables ma_smalltable and ma_table were introduced in PyDictObject. The ma_smalltable variable with pre-allocated memory of size PyDict_MINSIZE (i.e. 8) allows small dictionaries (up to 8 PyDictEntry objects) to be stored without additional memory allocation. The experiments conducted by the developers showed that this size is quite enough for most dictionaries: small instance dictionaries and usually small dictionaries created to pass named arguments (kwargs). The ma_table variable corresponds to ma_smalltable for small tables (that is, for tables of 8 cells). For larger tables, ma_table is allocated separately. The ma_table variable cannot be NULL.
If someone suddenly wants to change the value of PyDict_MINSIZE, this can be done in the sources, and then rebuild Python. The value is recommended to be equal to the power of two, but not less than four.
A cell in a hash table can have three states
1) Unused (me_key == me_value == NULL)
This state means that the cell does not contain and has never contained a pair (key, value).
After inserting the key, the “unused” cell goes into the “active” state.
This state is the only case when me_key = NULL and is the initial state for all cells in the table.
2) Active (me_key! = NULL and me_key! = Dummy and me_value! = NULL)
Means that the cell contains an active pair (key, value).
After removing the key, the cell from the active state goes into the empty state (that is, me_key = dummy, and
dummy = PyString_FromString ("
This is the only state when me_value! = NULL.
3) Empty (me_key == dummy and me_value == NULL)
This state indicates that the cell previously contained the active pair (key, value), but it was deleted , and the new active pair has not yet been written to the cell.
Just like in the “unused” state, after inserting the key, the cell from the “empty” state goes into the “active” state. The
“empty” cell cannot return to the “unused" state, that is, return me_key = NULL, since in this case the sequence of samples in the event of a collision will not be possible find out if the cell "active."
Member variables
ma_fill - the number of non-zero keys (me_key! = NULL), that is, the sum of the "active" and "empty" cells.
ma_used - the number of non-zero and non-empty keys (me_key! = NULL, me_key! = dummy), that is, the number of "active" cells.
ma_mask - mask equal to PyDict_MINSIZE - 1.
ma_lookup - search function. By default, lookdict_string is used when creating a new dictionary. This is done because the developers decided that most dictionaries contain only string keys.
The main subtleties
The effectiveness of the hash table depends on the availability of “good” hash functions. A “good” hash function must be computed quickly and with a minimum of collisions. But, unfortunately, the most frequently used and important hash functions (for string and integer types) return fairly regular values, which leads to collisions. Take an example:
>>> map(hash, [0, 1, 2, 3, 4])
[0, 1, 2, 3, 4]
>>> map(hash, ['abca', 'abcb', 'abcc', 'abcd', 'abce'])
[1540938117, 1540938118, 1540938119, 1540938112, 1540938113]
Для целых чисел хэшами являются их значения, поэтому подряд идущие числа будут иметь подряд идущие хэши, а для строк подряд идущие строки имеют практически подряд идущие хэши. Это не обязательно плохо, напротив, в таблице размером 2**i взятие i младших бит хэша как начального индекса таблицы выполняется очень быстро, и для словарей, проиндексированных последовательностью целых чисел, коллизий не будет вообще:
То же самое будет почти полностью соблюдаться, если ключи словаря – это «подряд идущие» строки (как в примере выше). В общих случаях это дает более чем случайное поведение, что и требуется.
Taking only the i least significant bits of the hash as an index is also vulnerable to collisions: for example, take the list [i << 16 for i in range (20000)] as a set of keys. Since integers are their own hashes and this fits into a dictionary of size 2 ** 15 (since 20,000 <32768), the last 15 bits from each hash will all be 0.
>>> map(lambda x: '{0:016b}'.format(x), [i << 16 for i in xrange(20000)])
['0000000000000000', '10000000000000000', '100000000000000000', '110000000000000000', '1000000000000000000', '1010000000000000000', '1100000000000000000', '1110000000000000000', ...]
It turns out that all the keys will have the same index. That is, for all keys (except the first) collisions will occur.
Examples of specially selected “bad” cases should not affect ordinary cases, so just leave the last i bits. Everything else is left to the conflict resolution method.
Collision Resolution Method
The procedure for selecting a suitable cell to insert an item into the hash table is called probing, and the candidate cell in question is called probing.
Typically, the cell is located on the first try (and this is indeed so, because the hash table fill factor is kept below 2/3), which allows you to save time on probing and makes calculating the initial index very fast. But let's look at what happens if a conflict occurs.
The first part of the collision resolution method is to calculate the indices of the table for probing using the formula:
j = ((5 * j) + 1) % 2**i
For any initial j within [0 .. (2 ** i - 1)], invoking this formula 2 ** i times will return each number within [0 .. (2 ** i - 1)] exactly once. For instance:
>>> j = 0
>>> i = 3
>>> for _ in xrange(0, 2**i):
... print j,
... j = ((5 * j) + 1) % 2**i
...
0 1 6 7 4 5 2 3
You will say that this is no better than using linear sampling with a constant step, because in this case the cells in the hash table are also scanned in a certain order, but this is not the only difference. In general cases, when the hash of the key values goes in a row, this method is better than linear probing. From the example above, it can be seen that for a table of size 8 (2 ** 3), the order of the indices will be as follows:
0 -> 1 -> 6 -> 7 -> 4 -> 5 -> 2 -> 3 -> 0 -> … (затем идут повторения)
If there is a collision for a sample with an index of 5, then the next index of the sample will be 2, not 6, as in the case of linear testing with a step of +1, therefore, for a key added in the future, the sample index of which will be 6, no collision will occur . Linear probing in this case (with sequential key values) would be a bad option, since there would be many collisions. The likelihood that the hash of the key value will go in the order of 5 * j + 1 is much less.
The second part of the method for resolving collisions is to use not only the lower i bits of the hash, but also the remaining bits, too. This is implemented using the perturb variable as follows:
j = (5 * j) + 1 + perturb
perturb >>= PERTURB_SHIFT
затем j % 2**i используется как следующий индекс пробы
где:
perturb = hash(key)
PERTURB_SHIFT = 5
After that, the sequence of probes will depend on each bit of the hash. Pseudo-random variation is very effective because it quickly increases the differences in bits. Since the perturb variable is unsigned, if testing is performed often enough, the perturb variable eventually becomes and remains equal to zero. At this moment (which is very rarely achieved), the result j again becomes 5 * j + 1. Further, the search occurs in exactly the same way as in the first part of the method, and a free cell will ultimately be found, since, as was said earlier, each a number in the range [0 .. (2 ** i - 1)] will be returned exactly once, and we are sure that there is always at least one “unused" cell.
Choosing a “good” value for PERTURB_SHIFT is a matter of balance. If you make it small, then the high bits of the hash will affect the sequence of probes through iterations. If you make it large, then in really “bad” cases, the high bits of the hash will only affect the early iterations. As a result of experiments conducted by one of the Python developers, Tim Peters, the value PERTURB_SHIFT was chosen equal to 5, since this value turned out to be "the best". That is, it showed the minimum total number of collisions for both normal and specially selected “bad” cases, although values 4 and 6 were not significantly worse.
Historical note: One of the Python developers, Reimer Berends, proposed the idea of using a polynomial-based table index calculation approach, which was then improved by Christian Tismer. This approach also showed excellent results for collisions, but required more operations, as well as an additional variable to store the table polynomial in the PyDictObject structure. In the experiments of Tim Peters, the current method used in Python turned out to be faster, showing equally good results on the occurrence of collisions, but it required less code and used less memory.
Vocabulary initialization
When you create a dictionary, the PyDict_New function is called. The following operations are performed sequentially in this function: memory is allocated for a new PyDictObject dictionary object. The ma_smalltable variable is cleared. The variables ma_used and ma_fill are set to 0, ma_table becomes equal to ma_smalltable. The value of ma_mask is equal to PyDict_MINSIZE - 1. The function for searching ma_lookup is set to lookdict_string. The created dictionary object is returned.
Add item
When adding an element to the dictionary or changing the value of an element in the dictionary, the PyDict_SetItem function is called. In this function, the hash value is taken and the insertdict function is called, as well as the dictresize function, if the table is filled 2/3 of the current size.
In turn, the call to lookdict_string (or lookdict if the dictionary does not have a string key) is called in the insertdict function, in which a free cell is searched in the hash table for insertion. The same function is used to find the key during extraction.
The initial index of the sample in this function is calculated as a hash of the key divided modulo the size of the table (thus, the lower bits of the hash are captured). I.e:
>>> PyDict_MINSIZE = 8
>>> key = 123
>>> hash(key) % PyDict_MINSIZE
>>> 3
In Python, this is implemented using the logical AND operation and a mask. The mask is equal to the following value: mask = PyDict_MINSIZE - 1.
>>> PyDict_MINSIZE = 8
>>> mask = PyDict_MINSIZE - 1
>>> key = 123
>>> hash(key) & mask
>>> 3
This produces the least significant bits of the hash:
2 ** i = PyDict_MINSIZE, hence i = 3, that is, the three least significant bits are enough.
hash (123) = 123 = 1111011 2
mask = PyDict_MINSIZE - 1 = 8 - 1 = 7 = 111 2
index = hash (123) & mask = 1111011 2 & 111 2 = 011 2 = 3
After the index is calculated, the cell is checked by the index, and if it is "unused", a record is added to it (hash, key, value). But if this cell is busy due to the fact that another record has the same hash (i.e., a collision has occurred), the hash and key of the inserted record and the record in the cell are compared. If the hash and the key for the entries match, then it is considered that the entry already exists in the dictionary, and its updating is performed.
This explains the tricky moment associated with adding equal in value, but different in type of keys (for example, float, int and complex):
>>> 7.0 == 7 == (7+0j)
True
>>> d = {}
>>> d[7.0]='float'
>>> d
{7.0: 'float'}
>>> d[7]='int'
>>> d
{7.0: 'int'}
>>> d[7+0j]='complex'
>>> d
{7.0: 'complex'}
>>> type(d.keys()[0])
That is, the type that was first added to the dictionary will be the key type, despite the update. This is because the hash implementation for float values returns the hash from int if the fractional part is 0.0. An example hash calculation for float, rewritten in Python:
def float_hash(float_value):
...
fractpart, intpart = math.modf(float_value)
if fractpart == 0.0:
return int_hash(int(float_value)) # использовать хэш int
...
And the hash from complex returns the hash from float. In this case, the hash of only the real part is returned, since the imaginary part is zero:
def complex_hash(complex_value):
hashreal = float_hash(complex_value.real)
if hashreal == -1:
return -1
hashimag = float_hash(complex_value.imag)
if hashimag == -1:
return -1
res = hashreal + 1000003 * hashimag
res = handle_overflow(res)
if res == -1:
res = -2
return res
Example:
>>> hash(7)
7
>>> hash(7.0)
7
>>> hash(7+0j)
7
Due to the fact that both hashes and values are equal for all three types, a simple update of the value of the found record is performed.
Note on adding elements: Python prohibits adding elements to the dictionary during iteration, so an error will occur when trying to add a new element:
>>> d = {'a': 1}
>>> for i in d:
... d['new item'] = 123
...
Traceback (most recent call last):
File "", line 1, in
RuntimeError: dictionary changed size during iteration
Let's return to the procedure of adding an element to the dictionary. After successfully adding or updating a record in the hash table, the next candidate record for insertion is compared. If the hash or key of the records do not match, probing begins. Searches for the “unused" cell to insert. This Python implementation uses random (and if the perturb variable is zero - quadratic) probing. As described above, with random probing, the index of the next cell is selected in a pseudo-random manner. The record is added to the first “unused” cell found. That is, two keys a and b, for which hash (a) == hash (b), but a! = B can easily exist in one dictionary. If the cell at the initial index of the sample is “empty”, probing will occur. And if the first cell found is “zero”, then the “empty” cell will be reused. This allows you to overwrite deleted cells, while retaining unused ones.
It turns out that the indices of the elements added to the dictionary depend on the elements already in it, and the order of the keys for two dictionaries consisting of the same set of pairs (key, value) can be different and is determined by the order of adding the elements:
>>> d1 = {'one': 1, 'two': 2, 'three': 3, 'four': 4, 'five': 5}
>>> d2 = {'three': 3, 'two': 2, 'five': 5, 'four': 4, 'one': 1}
>>> d1 == d2
True
>>> d1.keys()
['four', 'three', 'five', 'two', 'one']
>>> d2.keys()
['four', 'one', 'five', 'three', 'two']
This explains why dictionaries in Python display stored pairs (key, value) in the order in which they are added to the dictionary when displaying content. Dictionaries output them in the order in the hash table (i.e. in index order).
Consider an example:
>>> d = {}
>>> d['habr'] = 1

An insert was made at index 5. The variables ma_fill and ma_used became equal to 1.
>>> d['python'] = 2

Index 0 was inserted. The variables ma_fill and ma_used became equal to 2.
>>> d['dict'] = 3

Index 4 was inserted. The variables ma_fill and ma_used became equal to 3.
>>> d['article'] = 4

An insert was made at index 1. The variables ma_fill and ma_used became equal to 4.
>>> d['!!!'] = 5

The following happened:
hash ('!!!') = -1297030748
i = -1297030748 & 7 = 4
But as you can see from the table, index 4 is already occupied by the record with the key 'dict'. That is, a collision occurred.
Testing begins: perturb = -1297030748
i = (i * 5) + 1 + perturb
i = (4 * 5) + 1 + (-1297030748) = -1297030727
index = -1297030727 & 7 = 1 The
new sample index is 1, but this index is also busy (record with the key 'article'). Another collision occurred, we continue to
test : perturb = perturb >> PERTURB_SHIFT
perturb = -1297030748 >> 5 = -40532211
i = (i * 5) + 1 + perturb
i = (-1297030727 * 5) + 1 + (-40532211) = -6525685845
index = -6525685845 & 7 = 3
The new sample index is 3, and since it is not busy, an entry is inserted with the key '!!!' into the cell with the third index. In this case, the record was added after two trials due to collisions. Variables ma_fill and ma_used became equal to 5.
>>> d
{'python': 2, 'article': 4, '!!!': 5, 'dict': 3, 'habr': 1}
We are trying to add the sixth element to the dictionary.
>>> d[';)'] = 6

After adding the sixth element, the table will be filled in 2/3, and accordingly, its size will change. After the size has changed (in this case, it will increase 4 times), the hash table will be completely rebuilt taking into account the new size - all "active" cells will be redistributed, and "empty" and "unused" cells will be ignored.
The size of the hash table is now 32, and the variables ma_fill and ma_used are now equal to 6. As you can see, the order of the elements has completely changed:
>>> d
{'!!!': 5, 'python': 2, 'habr': 1, 'dict': 3, 'article': 4, ';)': 6}
Element search
The search for entries in the dictionary hash table is similar, starting from cell i, where i depends on the key hash. If the hash and key do not coincide with the hash and key of the found record (that is, there was a conflict and you need to find the appropriate record), testing starts, which continues until a record is found for which the hash and key match. If all the cells were viewed, but the record was not found, an error is returned.
>>> d = {'a': 123, 'b': 345, 'c': 678}
>>> d['x']
Traceback (most recent call last):
File "", line 1, in
KeyError: 'x'
Hash table fill factor
The size of the table changes when it is filled in 2/3. That is, for the initial size of the dictionary hash table equal to 8, the change will occur after 6 elements are added.
>>> 8 * 2.0 / 3
5.333333333333333
At the same time, the hash table is rebuilt taking into account its new size, and accordingly, the indexes of all records change.
The value 2/3 of the size was chosen as optimal, so that the sampling would not take too much time, that is, the insertion of a new record was quick. Increasing this value leads to the fact that the dictionary is denser filled with entries, which in turn increases the number of collisions. Decreasing it increases the sparseness of the records to the detriment of the increase in the processor cache lines occupied by them and to the detriment of the increase in the total memory. Checking the filling of the table occurs in a very time-sensitive piece of code. Attempts to make verification more complex (for example, by changing the fill factor for different sizes of the hash table) reduced performance.
You can verify that the dictionary size is really changing by:
>>> d = dict.fromkeys(range(5))
>>> d.__sizeof__()
248
>>> d = dict.fromkeys(range(6))
>>> d.__sizeof__()
1016
The example returns the size of the entire PyDictObject for the 64-bit version of the OS.
The initial size of the table is 8. Thus, when the number of filled cells is 6 (that is, more than 2/3 of the size), the size of the table will increase to 32. Then, when the number is 22, it will increase to 128. At 86, it will increase to 512 , at 342 - until 2048 and so on.
Table size increase ratio
The coefficient of increasing the size of the table upon reaching the maximum fill level is 4 if the size of the table is less than 50,000 elements, and 2 for larger tables. This approach may be useful for memory-limited applications.
Increasing the size of the table improves the average sparseness, that is, the dispersion of entries in the dictionary table (reducing collisions), due to an increase in the amount of memory consumed and the speed of iterations, and also reduces the number of expensive memory allocation operations when resizing for a growing dictionary.
Usually adding an element to the dictionary can increase its size by 4 or 2 times depending on the current size of the dictionary, but it is also possible that the size of the dictionary decreases. This situation can happen if ma_fill (the number of non-zero keys, the sum of the "active" and "empty" cells) is much larger than ma_used (the number of "active" cells), that is, many keys have been deleted.
Delete item
When an item is deleted from the dictionary, the PyDict_DelItem function is called.
Deletion from the dictionary occurs by key, although in reality memory is not released. In this function, the hash value of the key is calculated, and then a record is searched in the hash table using the same lookdict_string or lookdict function. If a record with such a key and hash is found, the key of this record is set to “empty” (that is, me_key = dummy), and the record value is set to NULL (me_value = NULL). After that, the ma_used variable will decrease by one, and ma_fill will remain unchanged. If the record is not found, an error is returned.
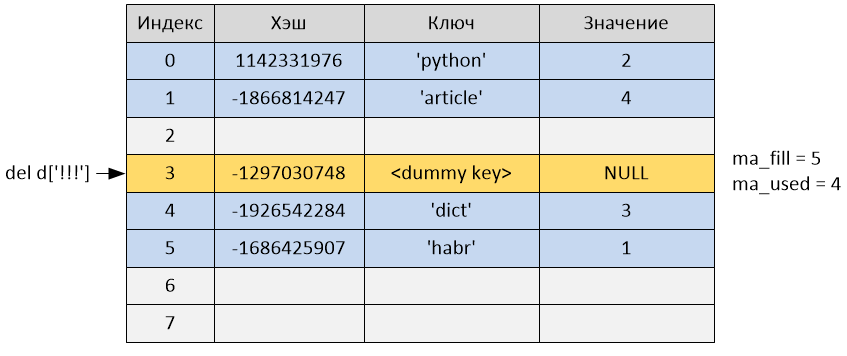
>>> del d['!!!']

After deletion, the ma_used variable became equal to 4, and ma_fill remained equal to 5, since the cell was not deleted, but was just marked as “empty” and continues to occupy the cell in the hash table.
Hash randomization
When you run python, you can use the -R switch to use a pseudo-random salt. In this case, the hash of values of types such as strings, buffer, bytes, and datetime objects (date, time, and datetime) will be unpredictable between calls to the interpreter. This method is proposed as protection against DoS attacks.
References
github.com/python/cpython/blob/2.7/Objects/dictobject.c
github.com/python/cpython/blob/2.7/Include/dictobject.h
github.com/python/cpython/blob/2.7/Objects/dictnotes. txt
www.shutupandship.com/2012/02/how-hash-collisions-are-resolved-in.html
www.laurentluce.com/posts/python-dictionary-implementation
rhodesmill.org/brandon/slides/2010-03-pycon
www.slideshare.net/MinskPythonMeetup/ss-26224561 - Dictionary in Python. Based on Objects / dictnotes.txt - SlideShare (Cyril notorca Lashkevich)
www.youtube.com/watch?v=JhixzgVpmdM - Video of the report “Dictionary in Python. Based on Objects / dictnotes.txt »