Hospital mean temperature calculation
It’s worth starting with the fact that this article is completely not serious. New Year's Eve, holiday, no strength there is no need to do something serious both for writers and readers. That is why it was decided to write an article about, suddenly, statistics.
This article is indirectly related to one of the discussions in which we took part, regarding the possibility of some regularity in the manifestation of errors in certain places when copying the code. We very often refer to the article " The effect of the last line" – согласно наблюдениям, в однотипных, полученных методом копирования и вставки строчках кода ошибка наиболее часто встречается в последней из них. Обсуждение касалось того, нельзя ли каким-то образом вывести некую закономерность появления ошибки в других местах однотипных блоков? К сожалению, примеры построены так, что собрать какую бы то ни было статистику касательно проявления таких ошибок достаточно сложно. Однако это подало идею провести небольшое статистическое исследование на нашей базе примеров.
Скажем сразу, что статья эта будет носить шуточный характер, так как серьёзных закономерностей мы найти не смогли. Многие помнят, что "Существуют три вида лжи: ложь, наглая ложь и статистика", поэтому зачастую с недоверием относятся к любым статистическим исследованиям. И поделом, ведь статистика, ориентированная на «толпу», зачастую используется для поиска закономерностей там, где их нет. Один из наиболее ярких примеров – "Эффект Марса". Но у нас всё не так. Мы изначально говорим, что это статистическое исследование не претендует на то, чтобы быть серьёзным. Любые статистические зависимости, которые здесь будут описаны, либо довольно очевидны сами по себе, либо имеют характер "ложной корреляции", либо не превышают статистическую погрешность из-за небольшого размера выборки.
Ну что ж, приступим? Пока что Google собирает статистики, чего не по душе людям, мы соберём статистики, чего не по душе анализатору.
Assumption 1. Some words are more common than others.
Come on? Are you kidding me?
Anyone who is familiar with any programming language can say that some words or symbols are more often found in the text of the program than others. Even in Brainfuck programming, the '+' character is more common than the '.' Character. The only "programming language" in which someone once really wrote and where one can argue with this fact - programming is not even in assembler, but directly in machine code. Connoisseurs in addition to this will probably call counterexamples from esoteric languages like Malbolgeetc. What about C ++? And so it is clear that the int keyword will appear on average more often in the source code than float, public - than protected and class - than struct or especially union. But still. What are the most common words in sections of C ++ code containing an error? Counting was carried out by elementary calculation of the number of words for all examples; that is, if the word if occurred twice in one example, then it was counted twice. Words in the comments did not count. So, a list of the most frequently occurring words (the number before the colon indicates the number of times how many words the word occurs in all examples):
- 1323: if
- 798: int
- 699: void
- 686: i
- 658: const
- 620: return
- 465: char
- 374: static
- 317: else
- 292: sizeof
- 258: bool
- 257: NULL
- 239: s
- 223: for
- 194: unsigned
- 187: n
- 150: struct
- 146: define
- 137: x
- 133: std
- 121: c
- 121: new
- 115: typedef
- 113: j
- 107: d
- 105: a
- 102: buf
- 102: case
“Conclusion”: 'if' generates errors.
The following words give hope; rather, their number compared to if and even case:
- 15: goto
- 13: static_cast
- 6: reinterpret_cast
It seems that not everything is so bad with the structure of Open Source applications.
But the word auto was not noticed almost anywhere (less than five inclusions), as well as constexpr, and unique_ptr, and so on. This, on the one hand, is logical, since the base of examples began to gather examples a long time ago, when they did not even think about implementing the C ++ 11 standard. On the other hand, there is another subtext in this: language extensions are introduced primarily to simplify it and reduce the likelihood of new errors. We remind you that only examples with errors found by the PVS-Studio analyzer get into our database.
Similar statistics were collected on numbers.
- 1304: 0
- 653: 1
- 211: 2
- 120: 4
- 108: 3
- 70: 8
- 43: 5
- 39: 16
- 36: 64
- 29: 6
- 28: 256
It is curious that the number 4 in the examples of erroneous code is more common than the number 3, and this is not connected with 64-bit diagnostics - in the examples they are, if any, in a very small amount (no more than one or two copies of the code). The vast majority of examples (at least 99%) were collected on general-purpose diagnostics.
Most likely, the appearance of a four above three, albeit with a small margin, is due to the fact that four is a “round” number, and three is “non-circular” if you know what I mean. For the same reason, the numbers 8, 16, 64 and 256 seem to go into a significant margin. Here is such a strange distribution.
And then - on wit and knowledge. Where do you think these numbers come from, 4996 and 2047?
- 6: 4996
- 5: 2047
The answer is at the end of the next section.
Assumption 2. The most common letter in the code is the letter 'e'
According to statistics , in literary English, the letter 'e' is found most often. The ten most common letters in the English language are e, t, a, o, i, n, s, h, r, d. And what is the probability of meeting one or another character in the source code in C ++? Let's put on such an experiment. The approach to the experiment this time is even more brutal and heartless than to the previous one. We just go through all, all examples and just count the number of all characters. Case insensitive, i.e. 'K' = 'k'. So the results are:
- 82100:
- 28603: e
- 24938: t
- 19256: i
- 18088: r
- 17606: s
- 16700: a
- 16466:.
- 16343: n
- 14923: o
- 12438: c
- 11527: l
The most common character is a space. In literary English, the space character is slightly ahead of the letter e, but in our case this is far from the case. Space is very widely used for aligning code, which provides it with a leading position with a huge margin, at least in our examples, because for the convenience of formatting, we replace tabs with spaces. As for the rest of the characters - the characters i (the leader in the market of names for counters since 19XX) came very far ahead, r (according to our assumptions - there are several commonly used names, such as run, rand, vector, read, write and especially - error) and s (std :: string s).However, due to a sufficiently large statistical sample, we can argue that the letters e and t are exactly the most frequent in the source code of the program, as well as in texts in English.
About the point. Of course, in real programs, the point is not found as often as can be judged from the list above. The fact is that in our examples, four dots very often omit redundant code that is not required to understand the error. Therefore, in fact, the point is hardly included in the set of the most common characters in C ++.
What did anyone say about entropy coding ?
And if you look from a different angle. What symbol was most rare in the examples?
- 90:?
- 70: ~
- 24: ^
- 9: @
- 1: $
Another very strange result that struck us. Look at the number of these characters. It practically coincides (and in some places even coincides to the last sign!). Mystery, and only. How could this happen?
- 8167: (
- 8157 :)
- 3064: {
- 2897:}
- 1457: [
- 1457:]
Oh yes, the promised answer to the question from the previous section. 2047 = 2048 - 1, and the number 4996 was typed due to lines in the style
#pragma warning (disable:4996)Assumption 3. There is a relationship between the occurrences of certain words
This is somewhat reminiscent of correlation analysis. The task was set like this: is there a correlation between the appearance of some two words in the examples?
Why only "reminds". We decided to calculate a relative value, more similar to a linear correlation coefficient, but not one, since it changes from 0 to 1 for convenience and is measured for each pair of words (a, b) as follows: if the word a occurs in Na examples, the word b - in Nb examples, and at the same time they met in Nab examples, then the coefficient Rab = Nab / Na, and Rba = Nab / Nb. Since it is known that 0 <= Nab <= Na, Nb; Na, Nb> 0, we can obviously deduce that 0 <= Rab, Rba <= 1.
How it works. Suppose that the word void was found in 500 examples, the word int was in 2000, and the words void and int were both 100. Then the coefficient Rvoid, int = 100/500 = 20%, and the coefficient Rint, void = 100/2000 = 5 % Yes, the coefficient turned out to be asymmetric (Rab in the general case is not equal to Rba), but this can hardly be considered an obstacle.
Probably, we can talk about at least some kind of statistical dependence when R> = 50%. Why exactly 50%? Yes, simply because I wanted to. In fact, threshold values are chosen rather roughly, there are usually no recommendations. The value of 95%, in theory, should indicate a strong dependence. In theory.

So, using the correlation analysis, it was possible to find out the following amazing, unorthodox facts:
- In examples where the else keyword is used, the vast majority of cases (95.00%) also use the if! (I wonder where the remaining 5% went?)
- In examples where the public keyword is used, in the vast majority of cases (95.12%), the class keyword is also used!
- In examples where the typename keyword is used, in the vast majority of cases (90.91%) the template keyword is also used!
And so on and so forth. Here are a few "obvious" blocks below.
- 100.00% (18 of 18): argc -> argv
- 100.00% (18 of 18): argc -> int
- 94.44% (17 of 18): argc -> char
- 90.00% (18 of 20): argv -> argc
- 90.00% (18 of 20): argv -> char
- 90.00% (18 of 20): argv -> int
- 75.00% (12 of 16): main -> argv
- 60.00% (12 of 20): argv -> main
At least this example shows that the program at least works, even if it makes senseless operations to identify all the dependencies between main, argc and argv.
- 100.00% (11 of 11): disable -> pragma
- 100.00% (11 of 11): disable -> default
- 100.00% (11 of 11): disable -> warning
- 91.67% (11 of 12): warning -> pragma
- 91.67% (11 of 12): warning -> default
- 91.67% (11 of 12): warning -> disable
- 78.57% (11 of 14): pragma -> warning
- 78.57% (11 of 14): pragma -> disable
- 78.57% (11 of 14): pragma -> default
- 57.89% (11 of 19): default -> warning
- 57.89% (11 of 19): default -> disable
- 57.89% (11 of 19): default -> pragma
The madness of directives to the compiler. The analysis revealed all the dependencies between the words disable, pragma, warning and default. Apparently, all these examples were pulled from the V665 diagnostic database - especially pay attention to the fact that there are only eleven examples. By the way, these dependencies may seem completely unclear for those unfamiliar with the C ++ language, but for the programmer they may seem obvious.
And we continue.
- 100.00% (24 of 24): WPARAM -> LPARAM
- 92.31% (24 of 26): LPARAM -> WPARAM
- 91.30% (21 of 23): wParam -> WPARAM
- 91.30% (21 of 23): lParam -> LPARAM
- 91.30% (21 of 23): wParam -> LPARAM
- 87.50% (21 of 24): WPARAM -> wParam
- 86.96% (20 of 23): wParam -> lParam
- 86.96% (20 of 23): lParam -> wParam
- 86.96% (20 of 23): lParam -> WPARAM
- 83.33% (20 of 24): WPARAM -> lParam
- 80.77% (21 of 26): LPARAM -> wParam
- 80.77% (21 of 26): LPARAM -> lParam
This, I think, does not need comments at all. A fairly strong relationship between the types of WPARAM, LPARAM, as well as their standard names lParam and wParam. These words, by the way, stretch from 16-bit versions of Windows, and it seems that even from Windows 3.11, which clearly shows us how much work Microsoft does for compatibility purposes year after year.
There were, however, more interesting results.
- 100.00% (12 of 12): continue -> if
- 100.00% (13 of 13): goto -> if
- 68.25% (43 of 63): break -> if
The first two examples say that, most likely, the examples do not have a single unconditional continue and goto. The third, in principle, does not show anything, since break can be used not only in the loop, but also in the switch statement, which itself replaces the "garland" of if statements. Or not? Does the presence of the if statement in the example indicate that break / continue / goto are conditional? Did someone say something about V612 diagnostics ? In my defense, I can say, however, that in the examples there is not a single unconditional continue and goto, but continue and goto in general! But with break, the situation is much more sad.
- 85.00% (17 of 20): vector -> std
Still, the authors of real code try to avoid the “using namespace std;” construct in the header files, which certainly has favorable consequences for readers, although sometimes it’s not very convenient for programmers (how can I type five extra characters!).
- 94.87% (74 of 78): memset -> 0
- 82.05% (64 of 78): memset -> sizeof
Most often, memory is filled with zeros, at least in our examples. Yes, most likely, these statistics were greatly influenced by the diagnostics of V597 . And also V575 , V512 and so on. By the way, memory is filled with zeros more often than sizeof is used, which is at least strange and justified only if an array of bytes of a known size is filled. Well, or if an error was made, for example, V512 , when sizeof is simply forgotten in the third argument to memset.
- 76.80% (139 out of 181): for -> 0
In the vast majority of cases, for loops start from zero. No, this is not a phrase as opposed to the Pascal language or there, for example, Mathematica. Of course, that many cycles keep their score from scratch. It is precisely because of this that, probably, the foreach loop was introduced in C ++ 11 , which quite fairly “deals with” not only classes with overridden begin (), end (), etc., but also ordinary arrays ( but not with pointers to arrays). In addition, making a mistake in the foreach loop is much harder than in the for loop.
So it goes. By the way, this analysis took one hour and seven minutes in our release build on our eight-core machine.
Assumption 4. There are dangerous function names that are often mistaken.
Actually, the title of the paragraph should speak for itself. There is a suspicion that in some functions they make mistakes more often. This suspicion was almost immediately smashed into harsh reality - functions are called very differently, and in several projects the same function can be called ReadData (), readData (), read_data (), ReAdDaTa (), and so on. . Therefore, the first idea was to write an additional subroutine that breaks function names into separate words, such as read and data in the first three cases, and the fourth tries to burn out with fire.
After breaking all the names of the functions in which the errors were detected into words, such a distribution was obtained.
- 159: get
- 69: set
- 46: init
- 44: create
- 44: to
- 38: on
- 37: read
- 35: file
- 34: is
- 30: string
- 29: data
- 29: operator
- 26: proc
- 25: add
- 25: parse
- 25: write
- 24: draw
- 24: from
- 23: info
- 22: process
- 22: update
- 20: find
- 20: load
Apparently, in functions with the word 'get' in the name, errors are made more often than in functions with 'set'. Well, or, perhaps, our analyzer finds more errors in get functions than in set functions. Maybe get functions are programmed more often than set functions.
An analysis similar to the analysis in the previous paragraph was carried out on a set of words in functions. This time, the results are still not very large and can be given here in full. Function names are not very specific and any dependencies can be traced. Although I managed to isolate something.
- 77.78% (14 of 18): dlg -> proc
- 70.59% (12 of 17): name -> get
- 53.85% (14 of 26): proc -> dlg
- 43.48% (10 of 23): info -> get
The level of validity of this result is somewhat comparable with this correlation:
Assumption 5. Some diagnostics work more often than others.
Again, the assumption is in a fairly obvious style. When developing the analyzer, no one set themselves the task of making sure that various diagnostics were issued with approximately the same frequency. Yes, and even if such a task was posed, some errors can be noticed almost immediately (such as V614 ) and are intended mainly to accelerate development by automatically displaying a message during incremental analysis. And some, on the contrary, may go unnoticed until the end of the product life cycle (such as V597 ). The database contains the errors found based on the analysis of Open Source (for the most part) projects, and these are mainly stable versions. Is it necessary to say that in such cases the errors of the second class are more often found than of the first?
The calculation method is quite simple. Let’s take an example. The database contains the following entry:
NetXMS
V668 There is no sense in .... calltip.cpp 260
PRectangle CallTip::CallTipStart(....)
{
....
val = new char[strlen(defn) + 1];
if (!val)
return PRectangle();
....
}
Identical errors can be found in some other places:
V668 There is no sense in .... cellbuffer.cpp 153
V668 There is no sense in .... document.cpp 1377
V668 There is no sense in .... document.cpp 1399
And 23 additional diagnostic messages.The first line is the short name of the project. It will be needed a little later. The second record contains information about the error — the number of the triggered diagnostics, the description of the diagnostics, the name of the .cpp file in which the error was detected, and the line number. Next comes the code that we are not interested in. Next is a record about the additional places where the diagnostics were found, also with a diagnostic message, the name of the module and the line in which the error was found. This information may well not be. The last line is also optional and contains only the number of errors omitted for brevity. As a result of this example, we get the information that the project NetXMS diagnostics V668 found 1 + 3 + 23 = 27 errors. You can handle the following.
So, the numbers of the most common diagnostics:
- 1037: 668
- 1016: 595
- 311: 610
- 249: 547
- 231: 501
- 171: 576
- 143: 519
- 141: 636
- 140: 597
- 120: 512
- 89: 645
- 83: 611
- 81: 557
- 78: 624
- 67: 523
Two diagnostics related to working with memory are clearly in the lead. It is not surprising, because in C / C ++ languages it is just “dangerous” memory management. V595 diagnostics looks for cases where it is possible to dereference an object by a null pointer, and V668 diagnostics warns that it is pointless to check the pointer issued by the new operator for the fact that it will be null, because new throws an exception when memory allocation is not possible. Yes, 9X.XX% of programmers make mistakes when working with memory in C / C ++.

And then the idea came up to check in which projects the most errors were found and even which ones. Well, said - done.
- 640: Miranda NG :
- - V595 : 165 (25.8%)
- - V645 : 84 (13.1%)
- - V668 : 83 (13%)
- 388: ReactOS :
- - V595 : 213 (54.9%)
- - V547 : 32 (8.25%)
- 280: V8 :
- - V668 : 237 (84.6%)
- 258: Geant4 :
- - V624 : 71 (27.5%)
- - V668 : 70 (27.1%)
- - V595 : 31 (12%)
- 216: icu :
- - V668 : 212 (98.1%)
Assumption 6. The density of errors at the beginning of the file is higher than at its end
The latter assumption was also not particularly graceful. The idea is this: is there any line or group of lines (for example, from 67 to 75) where programmers make mistakes most often? Obviously enough, programmers would rarely make mistakes in the first ten lines (well, in those where #pragma once or #include “file.h” is often written), it was also pretty obvious that programmers rarely make mistakes in lines 30,000 to 30100. If only because such large files in real projects are usually simply not there.
Actually, the calculation method was quite simple. Each diagnostic error message contains the line number of the error file. Yes, but not all errors show the line number: from the example above, you can get only four line numbers out of a possible twenty-seven, since the remaining twenty-three are not described. But even with the help of such a tool, you can get quite a lot of errors from the database. That's just the total size of the .cpp file for subsequent normalization is not saved anywhere, so there will be no reduction to relative percentages. In other words, based on the examples, one cannot just take and test the hypothesis that 80% of errors occur in the last 20% of the file .
This time, instead of textual information, we provide a full-fledged histogram.
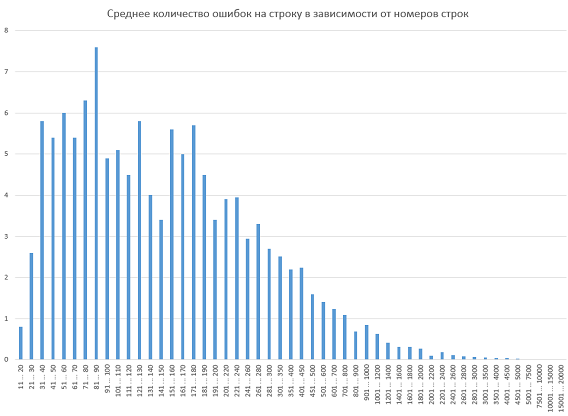
Figure 1 - A histogram of the distribution of the error density depending on the line number of the code.
The calculation was carried out as follows (using the example of the first column): we calculated how many errors occurred in lines 11 through 20 and divided this number by the number of lines between the twentieth and eleventh inclusive (then there is 10). As a result, a little less than one mistake was made on all projects on lines 11 to 20. This indicator is displayed in a histogram. I remind you that we did not normalize - it was more important not the exact values, which all the same are unlikely to reflect the dynamics due to the small sample size, but at least the type of graph.
Despite the fact that sharp deviations from the norm are noticeable in the histogram (and this norm somewhat resembles the lognormal distribution), we decided not to delve into the proof that from line 81 to line 90 the error code is most often committed. Still, drawing a graph is one task, and mathematically rigorously proving something based on it is another, and much more complicated. As for the same schedule, it was decided to confine ourselves to a vague phrase. “Unfortunately, all the deviations do not seem to be larger than the statistical error.” That's all.
Conclusion
This article clearly showed how you can, doing absolute nonsense, write scientifically texts and get paid for it.
But seriously - the extraction of statistical information on the basis of errors has two serious problems. The first problem is what will we look for? Confirming the “effect of the last line” is quite possible manually (and even necessary, since automation of the search for similar blocks is a thankless task), and everything else simply stumbles upon a lack of ideas. The second problem is whether the sample size is sufficient? Perhaps, for a frequency analysis of symbols, the selection is quite sufficient, but for the rest of the statistics this can not be said. The same can be said about statistical significance. Moreover, after collecting a database with a large number of experiments, it is not enough just to repeat the same thing. In order to rigorously confirm a certain statistical hypothesis, it is necessary to carry out many complicated mathematical calculations related, for example,Pearson's consent criterion . Of course, if the dependence is supposed to be somewhere at the level of the astrologer's predictions, such tests are essentially meaningless.
This article was originally intended to search for directions where exactly to dig in statistics on the basis of errors. If a sharp deviation from the norm occurred somewhere, one could think about it and conduct more detailed experiments. However, this was not seen anywhere, alas.