Fast Data Recipe Based on Big Data Solution

Image source
When discussing work with big data, the issues of analytics and problems of organizing the computing process are most often addressed. My colleagues and I had the opportunity to work on tasks of a different kind - accelerating access to data and balancing the load on the storage system. Below I will talk about how we dealt with this.
We made our “recipe” from existing “ingredients”: a piece of iron and a software tool. First, I will tell you how we faced the task of speeding up access. Then we will consider a piece of iron and a software tool. In conclusion, let's talk about two problems that we had to face in the course of work.
Let's start with a description of the problem.
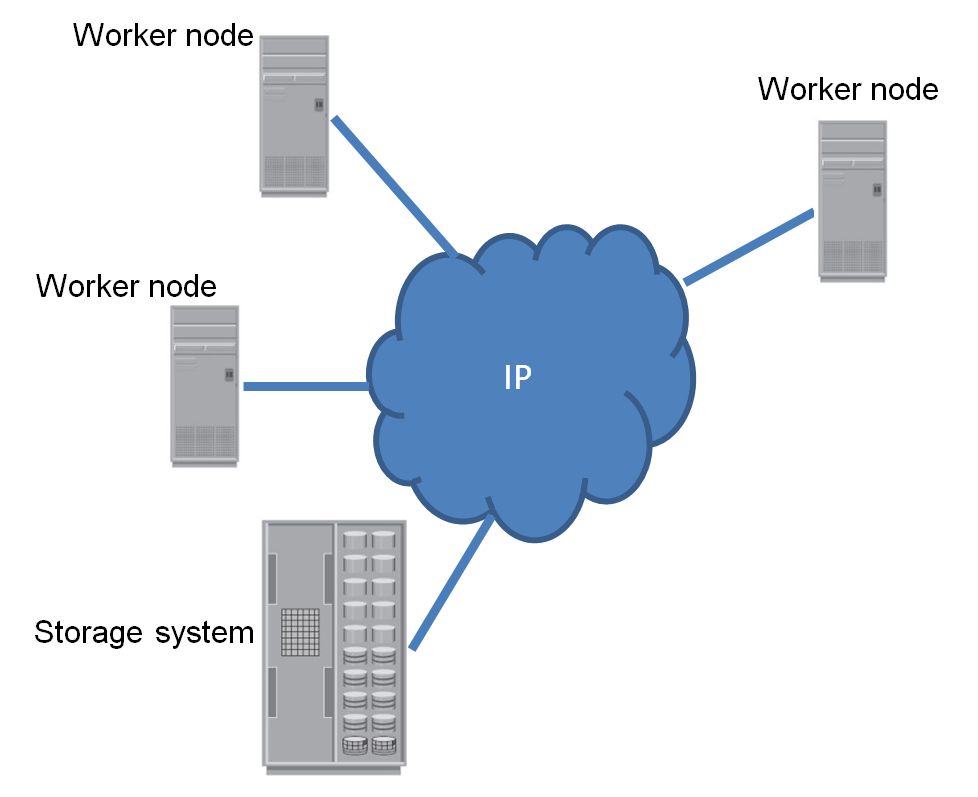
In the environment that we had to optimize, horizontally scalable network storage is used to store data . If you are not familiar with these words, don’t be afraid, I’ll explain everything now :) A
horizontally scalable storage system (in English - scale-out NAS) is a cluster system consisting of many nodes interconnected by a high-speed internal network. All nodes are available to the user individually through an external network, for example, via the Internet.
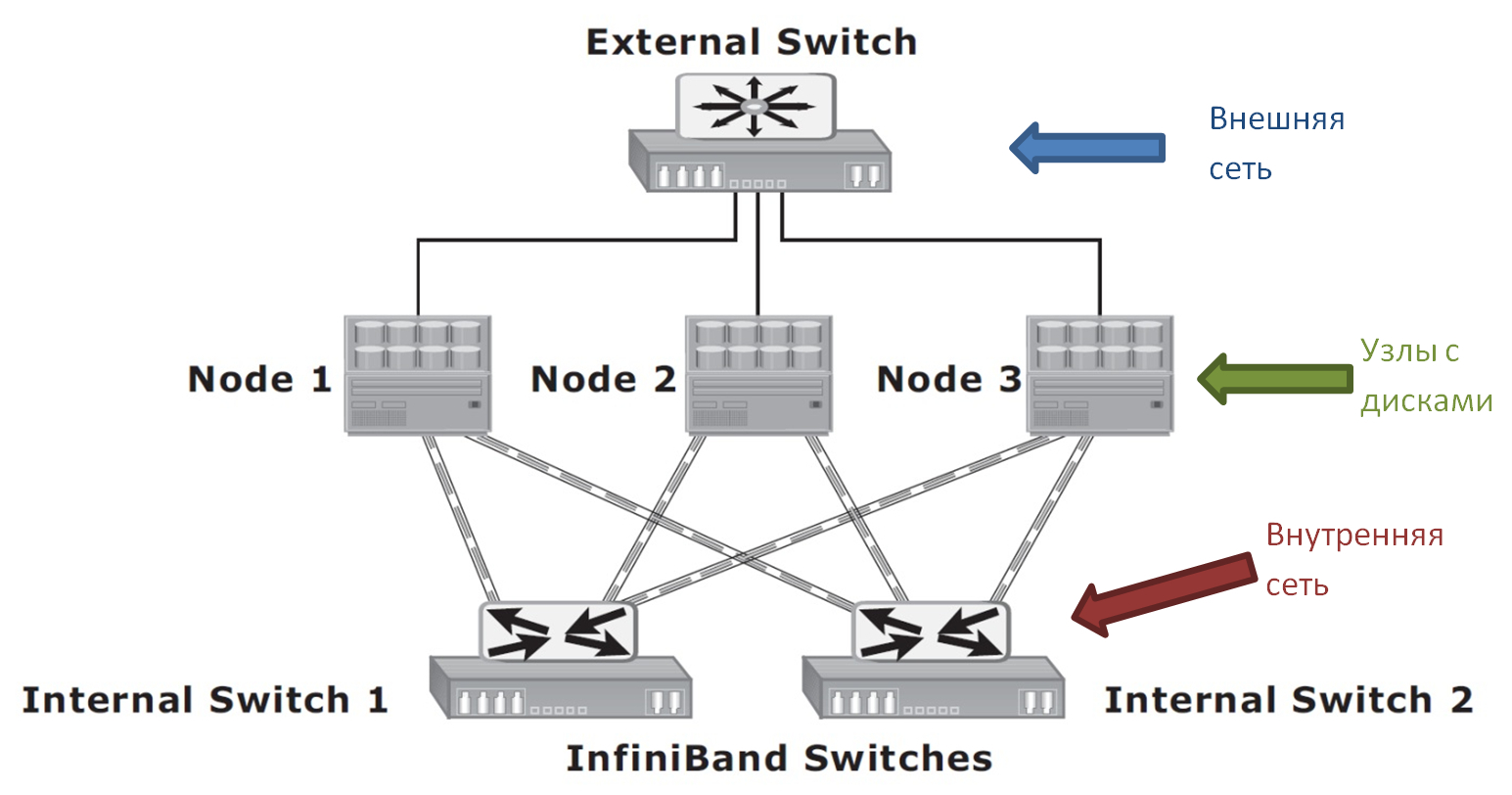
The diagram shows only three nodes. In fact, there can be many more. This is the beauty of scale-out systems. As soon as you need additional disk space or performance, you simply add new nodes to the cluster.
I said above that each of the cluster nodes is available separately. It is understood that with each node you can establish a separate network connection (or even several). However, no matter through which node the user connects to the cluster, he sees a single file system.
In the scale-out data center, the storage looks something like this (cluster nodes are stacked in stylish racks).

In our case, just the system shown in the picture was used for data storage: Isilon from EMC. It was chosen because of its almost unlimited scalability: one cluster can provide up to 30 petabytes of disk space. And from the outside all the space will be available as a single file system.
The problem that we had to solve is related to a specific model of using Isilon. In an environment that we optimize, data is accessed through a data management system. I will not go into details here, as This is a separate big topic. I will only talk about the consequences of this approach. Moreover, I will greatly simplify the overall picture in order to concentrate only on those things that are most important for the future.
A simplified picture of data access in our environment is as follows:
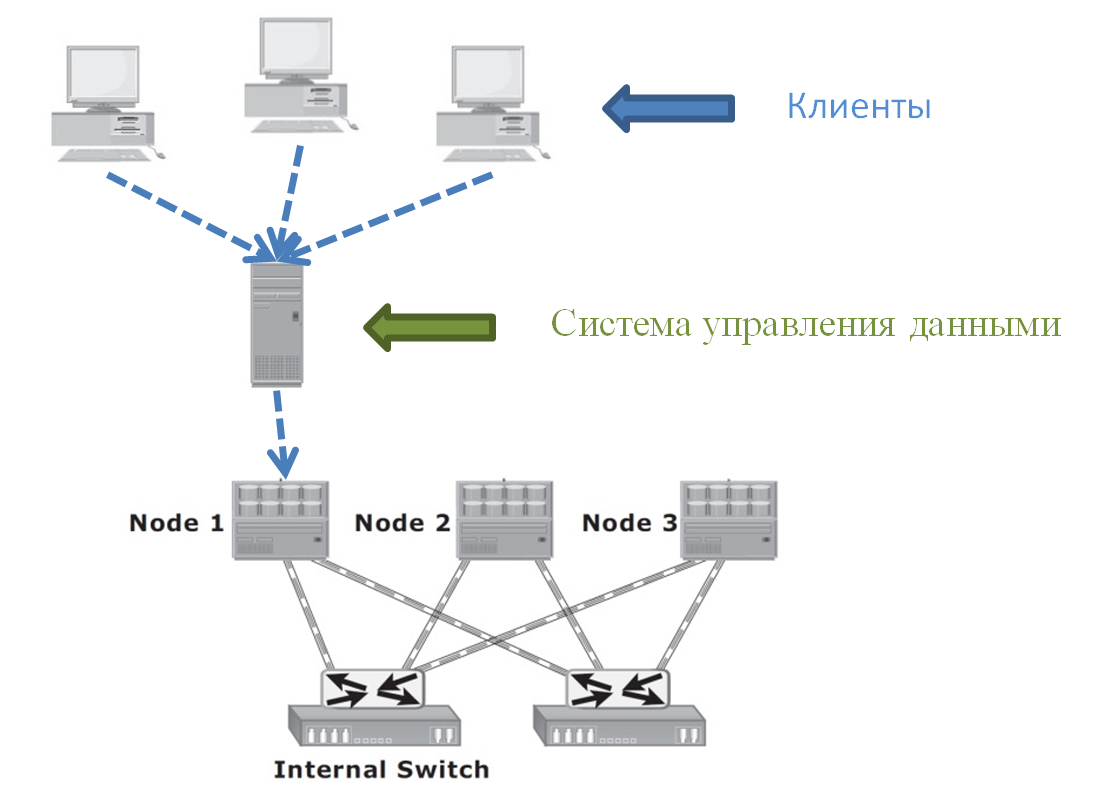
Many clients turn to a data management system that runs on a dedicated server. Customers do not write / read data from Isilon directly. This is done only through a control system that can potentially perform some kind of manipulation of data: for example, encrypt.
In the diagram, the control system server communicates with only one node of the data storage system (SHD). And this is what we really had. The stream of numerous client requests went to one single storage node. It turns out that the load on the cluster could be very unbalanced when the other nodes were not loaded with other servers or clients.
Isilon, generally speaking, provides excellent automatic load balancing capabilities. For example, if some server tries to establish a connection with Isilon, then it will be serviced by the node least loaded at the moment. Of course, in order to make such balancing possible, it is necessary to configure and use Isilon accordingly.
However, automatic load balancing on storage systems is possible only at the level of network connections. For example, if a large number of “gluttonous” compounds accumulate on some node of the cluster, the storage system will be able to “scatter” them along more free nodes. But in the case of the only loaded connection, the storage system is powerless.
Now a few words about what constitutes the only highly loaded connection that we had to unload. This is just an NFS mount. If you are not familiar with NFS, take a look under the spoiler.
Nfs
Unix has the concept of a virtual file system. This is such a generalized interface for accessing information. Through it, you can already access specific file systems. In fact, the file systems of various devices are simply integrated into the local file system and look to be part of it for the user. At the lower level, a floppy disk file system or remote file systems that can be accessed through the network can be used. One example of such a remote file system is NFS.
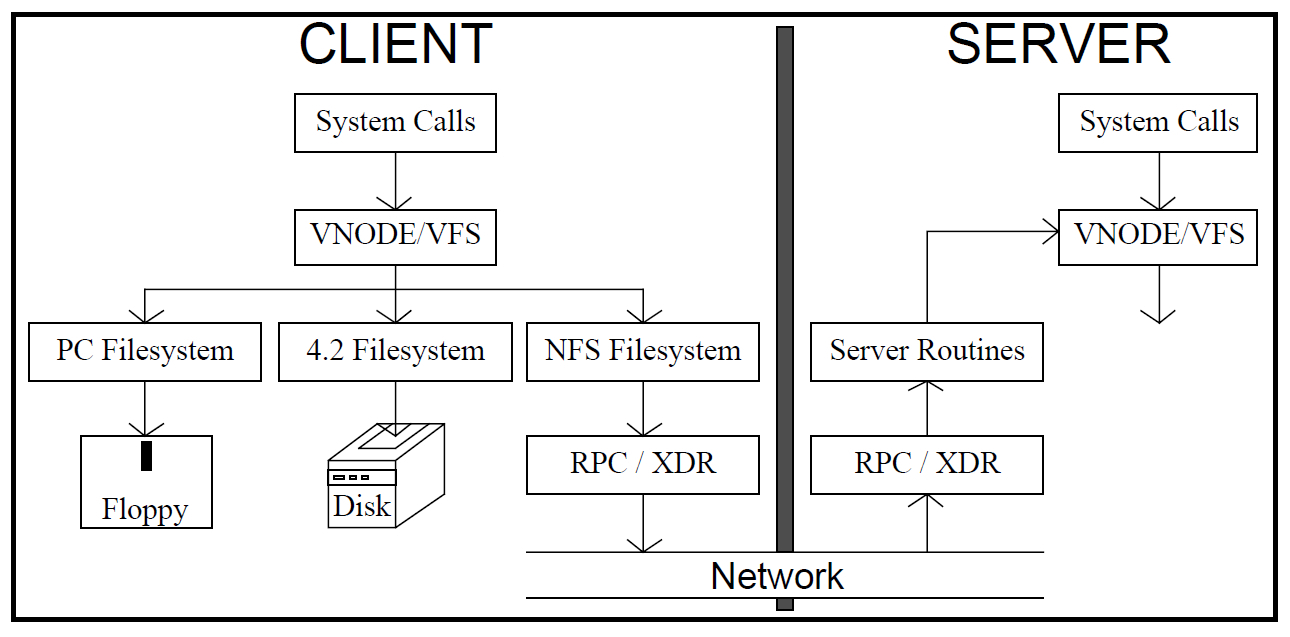
Now that the problem is clear, it's time to talk about how we solved it.
As I already said, a piece of hardware and a software solution designed to work with big data helped us. The piece of iron is the same Isilon. And we were very lucky that more than two years ago, one interesting property was added to it. Without it, dealing with load balancing would be much more difficult. The property in question is support for the HDFS protocol. The second ingredient of our recipe is based on it.
If you are not familiar with this abbreviation and the technical side of the issue, there’s a spoiler for welkams.
HDFS
HDFS is a distributed file system that is part of Hadoop, a platform for developing and running distributed programs. Hadoop is now widely used for big data analytics.
A classic Hadoop-based computing solution is a cluster of compute nodes and data nodes. Computing nodes perform distributed computing, loading / saving information from data nodes. Both types of nodes are more likely logical components of a cluster than physical ones. For example, on one physical server one computing node and several data nodes can be deployed. Although the most typical situation is when two nodes are running on the same physical machine, one of each type.
Communication of computing nodes with data nodes occurs just according to the HDFS protocol. The intermediary in this communication is the HDFS file system directory, which is represented in the cluster by another type of node - name node. If we abandon minor clauses, we can assume that there is only one directory node in the cluster.
Data nodes store data blocks. In the directory, among other things, information is stored on how the blocks related to specific files are distributed across data nodes.
The process of placing a file in HDFS from the client side looks something like this:
A classic Hadoop-based computing solution is a cluster of compute nodes and data nodes. Computing nodes perform distributed computing, loading / saving information from data nodes. Both types of nodes are more likely logical components of a cluster than physical ones. For example, on one physical server one computing node and several data nodes can be deployed. Although the most typical situation is when two nodes are running on the same physical machine, one of each type.
Communication of computing nodes with data nodes occurs just according to the HDFS protocol. The intermediary in this communication is the HDFS file system directory, which is represented in the cluster by another type of node - name node. If we abandon minor clauses, we can assume that there is only one directory node in the cluster.
Data nodes store data blocks. In the directory, among other things, information is stored on how the blocks related to specific files are distributed across data nodes.
The process of placing a file in HDFS from the client side looks something like this:
- HDFS client requests directory to create file
- if everything is ok, the directory signals that the file has been created
- when the client is ready to write the next block of this file, he again turns to the directory with a request to provide the address of the data node to which the block should be sent
- the directory returns the corresponding address
- the client sends a block to this address
- successful recording is confirmed
- when the client has sent all the blocks, it may request closing the file
Initially, the HDFS interface was not supported in Isilon so that my colleagues and I could use it to balance the load on storage. If you are interested in why HDFS is implemented in Isilon, then go to the next spoiler.
Native HDFS Support
At Isilon, the HDFS interface was supported so that storage can be used directly with Hadoop. What did this lead to? See the diagrams below. The first shows one of the typical scenarios for organizing a Hadoop cluster (not all types of nodes that exist in the cluster are shown)
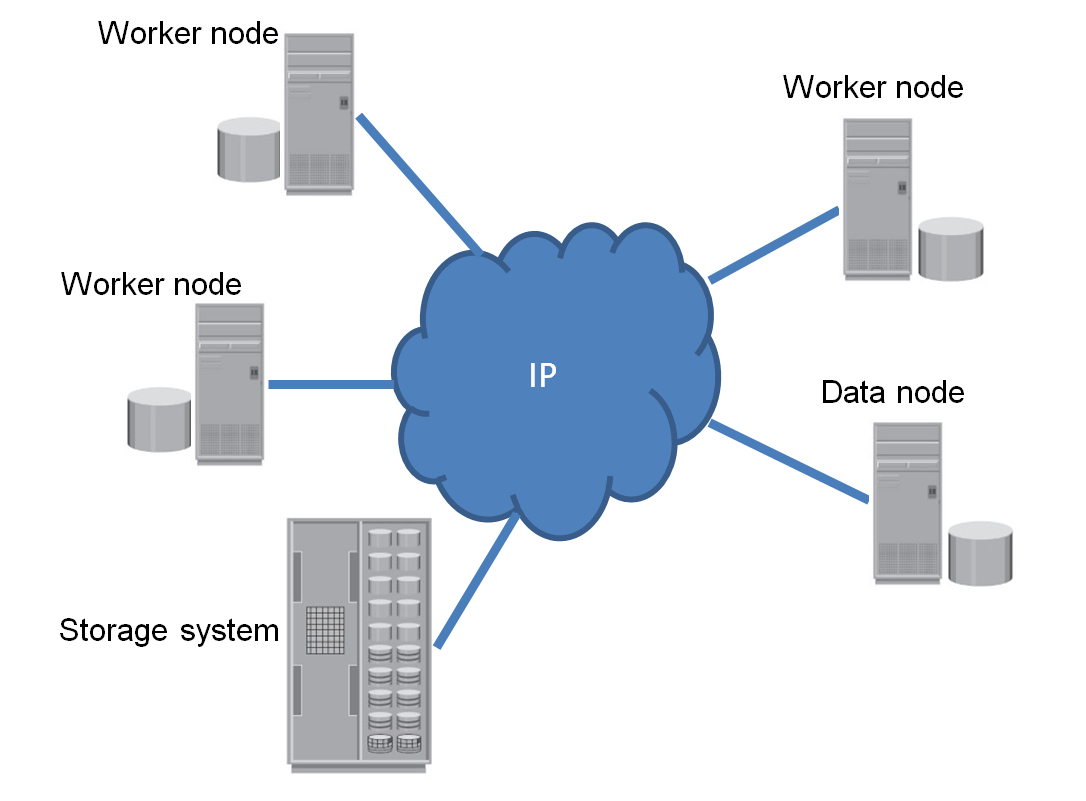
Worker node is a server that combines the functions of computing and data storage. Data node is a server that only stores data. Next to all the servers are shown "thick" disks that host data under the control of HDFS.
Why is the storage shown in the figure? It is a grocery data warehouse. It stores files that enter the product environment during everyday business operations. Typically, these files are transferred to the storage system using some widespread protocol. For example, NFS. If we want to analyze them, then we need to copy the files (do staging) into the Hadoup cluster. If it comes to many terabytes, then staging can take many hours.
The second picture shows what changes if the environment uses storage systems that support HDFS. The servers disappear large disks. Additionally, servers that were exclusively engaged in providing access to data are deleted from the cluster. All disk resources are now consolidated in one single storage system. There is no need to do staging. Analytical calculations can now be performed directly on product copies of files.
Data can still go to storage using the NFS protocol. And read on the HDFS protocol. If, for some reason, the calculations cannot be performed on product copies of files, then the data can be copied inside the same storage system. I will not list all the charms of this approach. There are many of them, and a lot has already been written about them in English-language blogs and news feeds.
Better, I’ll say a few words about how the work with the Isilon HDFS interface looks from the client side. Each of the cluster nodes can act as an HDFS data node (if not prohibited by the settings). But what is more interesting and what is not in the "real" HDFS, each node can also act as a directory (name node). It should be borne in mind that Isilon HDFS from the point of view of the "internals" has almost nothing to do with the Hadoup implementation of HDFS. The Isilon HDFS file system is duplicated only at the interface level. The entire inner kitchen is original and very efficient. For example, to protect data, they use their own economical and fast Isilon technologies, in contrast to copying along a chain of data nodes, which is implemented in the “standard” HDFS.
Worker node is a server that combines the functions of computing and data storage. Data node is a server that only stores data. Next to all the servers are shown "thick" disks that host data under the control of HDFS.
Why is the storage shown in the figure? It is a grocery data warehouse. It stores files that enter the product environment during everyday business operations. Typically, these files are transferred to the storage system using some widespread protocol. For example, NFS. If we want to analyze them, then we need to copy the files (do staging) into the Hadoup cluster. If it comes to many terabytes, then staging can take many hours.
The second picture shows what changes if the environment uses storage systems that support HDFS. The servers disappear large disks. Additionally, servers that were exclusively engaged in providing access to data are deleted from the cluster. All disk resources are now consolidated in one single storage system. There is no need to do staging. Analytical calculations can now be performed directly on product copies of files.
Data can still go to storage using the NFS protocol. And read on the HDFS protocol. If, for some reason, the calculations cannot be performed on product copies of files, then the data can be copied inside the same storage system. I will not list all the charms of this approach. There are many of them, and a lot has already been written about them in English-language blogs and news feeds.
Better, I’ll say a few words about how the work with the Isilon HDFS interface looks from the client side. Each of the cluster nodes can act as an HDFS data node (if not prohibited by the settings). But what is more interesting and what is not in the "real" HDFS, each node can also act as a directory (name node). It should be borne in mind that Isilon HDFS from the point of view of the "internals" has almost nothing to do with the Hadoup implementation of HDFS. The Isilon HDFS file system is duplicated only at the interface level. The entire inner kitchen is original and very efficient. For example, to protect data, they use their own economical and fast Isilon technologies, in contrast to copying along a chain of data nodes, which is implemented in the “standard” HDFS.
Let's see now how HDFS helped us deal with balancing the load on Isilon. Let us return to the example of recording a file in HDFS, which was examined above in the spoiler. What do we have in the case of Isilon?
To add another block to the file, the client must go to the directory in order to find out the address of the data node that this block will receive. In Isilon to anyonethe cluster node can be accessed as a directory. This is done either directly through the node address, or through a special service that deals with balancing connections. The address that will return the directory corresponds to the least loaded node at the moment. It turns out that sending blocks to HDFS, you always transfer them to the most free nodes. Those. you automatically have very fine, granular balancing: at the level of individual elementary operations, not mounts, as is the case with NFS.
Noticing this, we decided to use HDFS as a standalone interface. "Stand alone" here means that the interface is used in isolation from Hadoop. Perhaps this is the first example of this kind. At least, so far I have not heard that HDFS should be used separately from the family of Khadupov or okolokhadupovskih products.
As a result, we “fastened” HDFS to our data management system. Most of the problems that we had to solve at the same time were on the side of the management system itself. I will not talk about them here, because this is a separate big topic, tied in addition to the specifics of a particular system. But I will talk about two small problems that are associated with the use of HDFS as a standalone file system.
The first problem is that HDFS is not allocated to a separate product. It is distributed as part of Hadoop. Therefore, there is no “HDFS standard” or “HDFS specification”. In essence, HDFS exists as a reference implementation from Apache. So if you want to know the details of the implementation (for example, what is the policy for capturing and releasing leases), then you will have to do reverse engineering, either reading the source code, or looking for people who have already done this to you.
The second problem is finding a low-level library for HDFS.
After a superficial search on the network, it may seem that there are many such libraries. However, in reality there is one Apache reference Java library. Most other libraries for C ++, C, Python, and other languages are simply wrappers around the Java library.
We could not take the Java library for our C ++ project. Even with the appropriate wrapper. Firstly, to drag a data management system onto the server along with our small HDFS module was also an unacceptable luxury Java machine. Secondly, on the Internet, there are some complaints about the performance of Java libraries.
The situation was such that if we did not find a ready-made C ++ library for HDFS, we would have to write our own. And this is additional time for reverse engineering. Fortunately, we found the library.
Last year (and maybe even earlier) the first native-libraries for HDFS began to appear. At the moment, I am aware of two of them: for C and Python. Hadoofus and Snakebite . Perhaps something else has appeared. I have not repeated the search for a long time.
For our project, we took Hadoofus. For all the time of use, we found only two errors in it. The first - simple - led to the fact that the library was not built by the C ++ compiler. The second is more unpleasant: deadlock with multithreaded use. It appeared extremely rarely, which complicated the analysis of the problem. Both errors are currently fixed. Although we are still working on full testing of the lack of deadlocks.
We did not have to solve any other problems associated with the use of HDFS.
In general, it should be noted that writing an HDFS client for Isilon is easier than writing a client for "standard" HDFS. Undoubtedly, any “standard” HDFS client will work with Isilon without any problems. The converse does not have to be true. If you write an HDFS client exclusively for Isilon, then the task is simplified.
Consider an example. Let's say you need to read a data block with HDFS. To do this, the client turns to the directory and asks which data nodes this block can be taken from. In general, in response to such a request, the catalog returns the coordinates of not one node, but several, on which copies of this block are stored. If the client fails to receive a response from the first node in the list (for example, this node fell), then it will turn to the second, third, etc., until a node is found that will respond.
In the case of Isilon, you do not need to think about such scenarios. Isilon always returns the address of a single node, which will certainly serve you. This does not mean that the Isilon nodes cannot “fall”. In the end, you can disable the node at least with an ax. However, if Isilon for some reason loses a node, he simply passes its address to another - surviving - node in the cluster. So the fault tolerance scenario is already largely embedded in the hardware, and you do not need to fully implement it in software.
On this, the story about our “recipe” can be considered complete. It remains only to add a few words about the results.
The amortized gain in productivity, compared to working through NFS, is about 25% in our environment. This figure was obtained by comparing "ourselves": in both cases, the performance was measured on the same equipment and the same software. The only thing that differed was the module for accessing the file system.
If we consider only read operations, then a 25% gain is also observed when downloading each individual file. In the case of data recording, we can only talk about amortized gain. Writing every single file is slower than through NFS. There are two reasons for this:
- HDFS does not support multithreaded file recording
- our data management system has features that, due to the above-mentioned restriction of HDFS, do not allow the quick recording of a single file
If the file recording was organized in the data management system more optimally, a 25% gain in recording could be expected for a separate transfer.
I note that slowing down the upload of each specific file did not upset us much, because throughput at peak loads is most significant for us. In addition, in environments similar to ours, reading data is a much more frequent operation than writing.
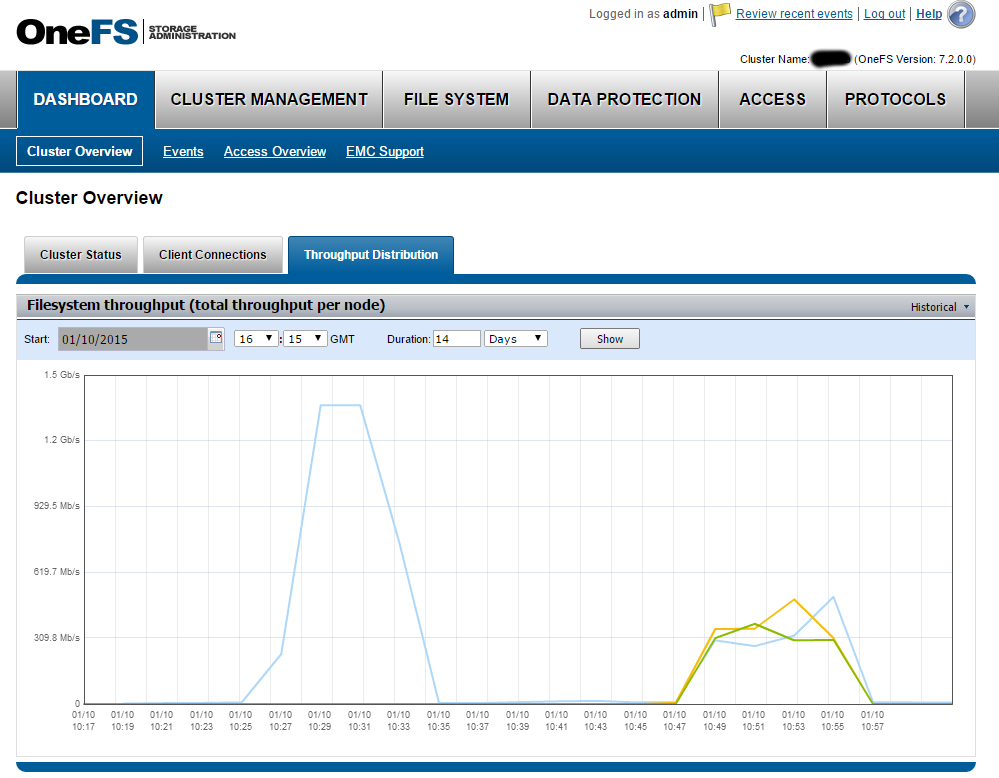
In conclusion, I will give an illustration that gives an idea of how the load of Isilon changes when using HDFS as an interface.
The screenshot shows the cluster load when transferring a 2GB file on both sides (the file was downloaded and downloaded 14 times in a row). The blue high peak on the left is obtained when working through NFS. Reading and writing occur through a single mount, and the entire load in this case is borne by one cluster node. The multi-colored low peaks on the right correspond to work through HDFS. It can be seen that now the load is “spread” over all the nodes in the cluster (3 pieces).
That’s probably all.
Let everything always work fast and reliably for you!