Work with images in Python
The topic of today's conversation is what Python has learned over the years of its existence in working with images. And indeed, besides the oldies, originally from 1990 ImageMagick and GraphicsMagick, there are modern efficient libraries. For example, Pillow and more productive Pillow-SIMD. Their active developer Alexander Karpinsky ( homm ) at MoscowPython compared different libraries for working with images in Python, introduced benchmarks and spoke about unobvious features that are always enough. In this article, deciphering a report that will help you choose a library for your application, and make it work as efficiently as possible.
About the speaker: Alexander Karpinsky works in the company Uploadcare and is engaged in the service of quick image modification on the fly. Participates in the development of Pillow - a popular library for working with images in Python, develops its own fork of this library - Pillow-SIMD , which uses modern instructions of processors for the greatest performance.
Background
The image modification service in Uploadcare is a server that receives an HTTP request with an image identifier and some operations that need to be performed by the client. The server must perform the operation and respond as quickly as possible. The client most often is the browser.
The entire service can be described as a wrapper around a graphic library. The quality of the whole project depends on the quality, performance and usability of the graphic library. It is easy to guess that Pillow is used as a graphic library in Uploadcare.
Libraries
Let's briefly consider what kind of graphics libraries exist in Python in order to better understand what will be discussed further.
Pillow
Pillow - fork PIL (Python Imaging Library). This is a very old project released in 1995 for Python 1.2. You can imagine how old he is! At some point, the Python Imaging Library was abandoned, its development stopped. Fork Pillow was made in order to install and build the Python Imaging Library on modern systems. Gradually, the number of changes that people needed in the Python Imaging Library grew, and Pillow 2.0 was released, which added support for Python 3. This can be considered the beginning of a separate Pillow project life.
Pillow is a native module for Python, half of the code is written in C, half in Python. Versions of Python are supported the most diverse: 2.7, 3.3+, Ppu, PpuZ.
Pillow-SIMD
This is my fork Pillow, which comes out from May 2016. SIMD means Single Instruction, Multiple Data is an approach in which the processor can perform more actions per clock using modern instructions.
Pillow-SIMD is not a fork in the classic sense when a project begins to live its own life. This is a replacement for Pillow, that is, you install one library instead of another, you do not change a line in your source code, and you get great performance.
Pillow-SIMD can be built with SSE4 instructions (default). This is a set of instructions that exists in almost all modern x86 processors. Also Pillow-SIMD can be assembled with the AVX2 instruction set. This set of instructions is, starting with the architecture Haswell, that is, from about 2013.
Opencv
Another library for working with images in Python that you've probably heard about is OpenCV (Open Computer Vision). Works since 2000. Binding in Python included. This means that the binding is always up to date, there is no dissynchrony between the library itself and the binding.
Unfortunately, this library is not yet supported in PyPy, because OpenCV is based on numpy, and numpy only recently started working under PyPy, and PyPy still does not support OpenCV.
VIPS
Another library worth paying attention to is VIPS. The main idea of VIPS is that in order to work with an image, you do not need to load the entire image into memory. The library can load some small pieces, process them and save. Thus, to process gigapixel images, you do not need to waste gigabytes of memory.
This is a rather old library from 1993, but it is ahead of its time. For a long time, there was little to hear about it, but lately, for VIPS, bindings for different languages began to appear, including Go, Node.js, Ruby.
I wanted to try this library for a long time, to feel it, but I could not do it for a very stupid reason. I could not figure out how to install VIPS, because binding was going very hard. But now (in 2017) there is a pyvips binding from the author of the VIPS himself, with whom there are no problems anymore. Now installing and using VIPS is very simple. Supported: Python 2.7, 3.3+, Ppu, PpuZ.
ImageMagick & GraphicsMagick
If we talk about working with graphics, then not to mention the old men - ImageMagick and GraphicsMagick libraries . The latter was originally a fork of ImageMagick with greater performance, but now their performance seems to be equal. There are no other fundamental differences, as far as I know, between them. Therefore, you can use any, more precisely, the one that you prefer to use.
These are the oldest libraries I have mentioned today (1990). During all this time, there have been several bindings for Python, and almost all of them have safely died by now. Of those that can be used, left:
Performance
When we talk about working with images, the first thing that interests us (at least to me) is productivity, because otherwise we could write something in Python with our hands.
Performance is not such a simple thing. You can't just say that one library is faster than another. Each library has a set of functions, and each function operates at a different speed.
Accordingly, it is correct to say only that the performance of one function is higher or lower in a particular library. Either you have an application that needs a certain set of functionality, and you make a benchmark for this functionality, and say that for your application such a library runs faster (slower).
It is important to check the result.
When you make benchmarks, it is very important to look at the result that is obtained. Even if at first glance you wrote the same code, it does not mean that it is the same.
Recently, in an article comparing the performance of Pillow and OpenCV, I came across this code:
It seems to be both there and there, BoxBlur, and there, and there argument 3, but in fact the result is different. Because in Pillow (3) this is the radius of the blur, and in OpenCV, ksize = (3, 3) is the size of the core, that is, roughly speaking, the diameter. In this case, the correct value for OpenCV would be 3 * 2 + 1, that is, (7, 7).
What is the problem?
Why is performance at all a problem when working with graphics? Because the complexity of any operations depends on several parameters, and most often the complexity grows linearly with each of them. And if there are three of these factors, for example, and the complexity is linearly dependent on each, then the complexity is in a cube.
Example: Gaussian Blur in OpenCV.

Left - radius 3, right - 30. As you can see, the difference in speed is more than 10 times.
When I was faced with the task of adding a Gaussian blur to my application, I was not satisfied that 900 ms can be hypothetically spent on performing a single operation. Such operations in the application of thousands per minute, and spend so much time on one - it is inappropriate. Therefore, I studied the question and implemented a Pilot blur according to Gauss, which works for a constant time relative to the radius. That is, only the size of the image affects the performance of Gaussian blur.
But the main thing here is not that something works faster or slower.
Probably the most frequent operation that we do with images after opening them is resize.
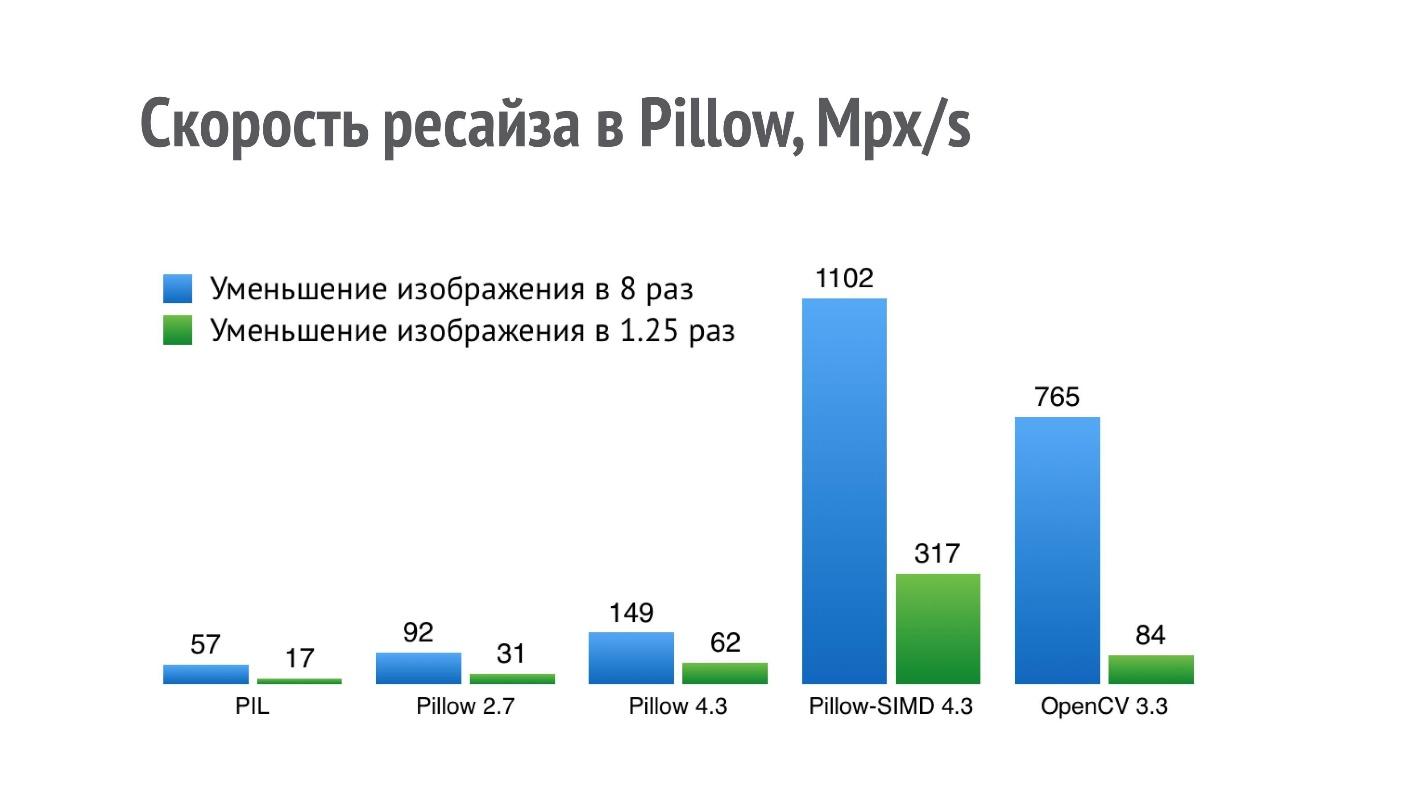
The graph shows the performance (more - better) of different libraries for the operation of reducing the image in 8 and 1.25 times.
For PIL, a result of 17 Mpx / s means that a photo from an iPhone (12 Mpx) can be reduced 1.25 times in a little less than a second. Such performance is not enough for a serious application that performs a lot of these operations.
I began to optimize the performance of the resize, and in Pillow 2.7 I managed to achieve a two-fold increase in performance, and in Pillow 4.3, a three-fold increase (Pillow 5.3 is currently relevant, but the resize performance is the same).
But the resize operation is such a thing that fits very well on SIMD. It comes up to single instruction, multiple data, and therefore in the current version of Pillow-SIMD I was able to increase the resize speed by 19 times compared to the original Python Imaging Library using the same resources.
This is significantly higher resize performance in OpenCV. But the comparison is not entirely correct, because OpenCV uses a slightly lower quality method of resizing with a box filter, and in Pillow-SIMD, resizing is implemented using convolutions.
This is an incomplete list of those operations that are accelerated in Pillow-SIMD compared to conventional Pillow.
I have already said that it is impossible to say that some library is faster than the other, but you can make up a set of operations that are interesting for you. I chose a set of operations that are interesting in my application, made a benchmark and got such results.

It turned out that Pillow-SIMD on this set works 2 times faster than Pillow. At the very end is Wand (remember, this is ImageMagick).
But I was interested in something else - why are so low results in OpenCV and VIPS, because these are libraries that are also designed with a view to performance? It turned out that in the case of OpenCV, that binary assembly of OpenCV, which is installed using pip, is compiled with a slow JPEG codec (the author of the assembly was notified, for 2018 this problem has already been solved). It is compiled with libjpeg, while on most systems, at least debian-based, libjpeg-turbo is used, which works several times faster. If you compile OpenCV from source itself, then the performance will be greater.
In the case of VIPS, the situation is different. I contacted the author of the VIPS, showed him this benchmark, we had a long and fruitful correspondence with him. After that, the author of VIPS found several places in the VIPS itself, where the performance was not on the optimal route, and corrected them.
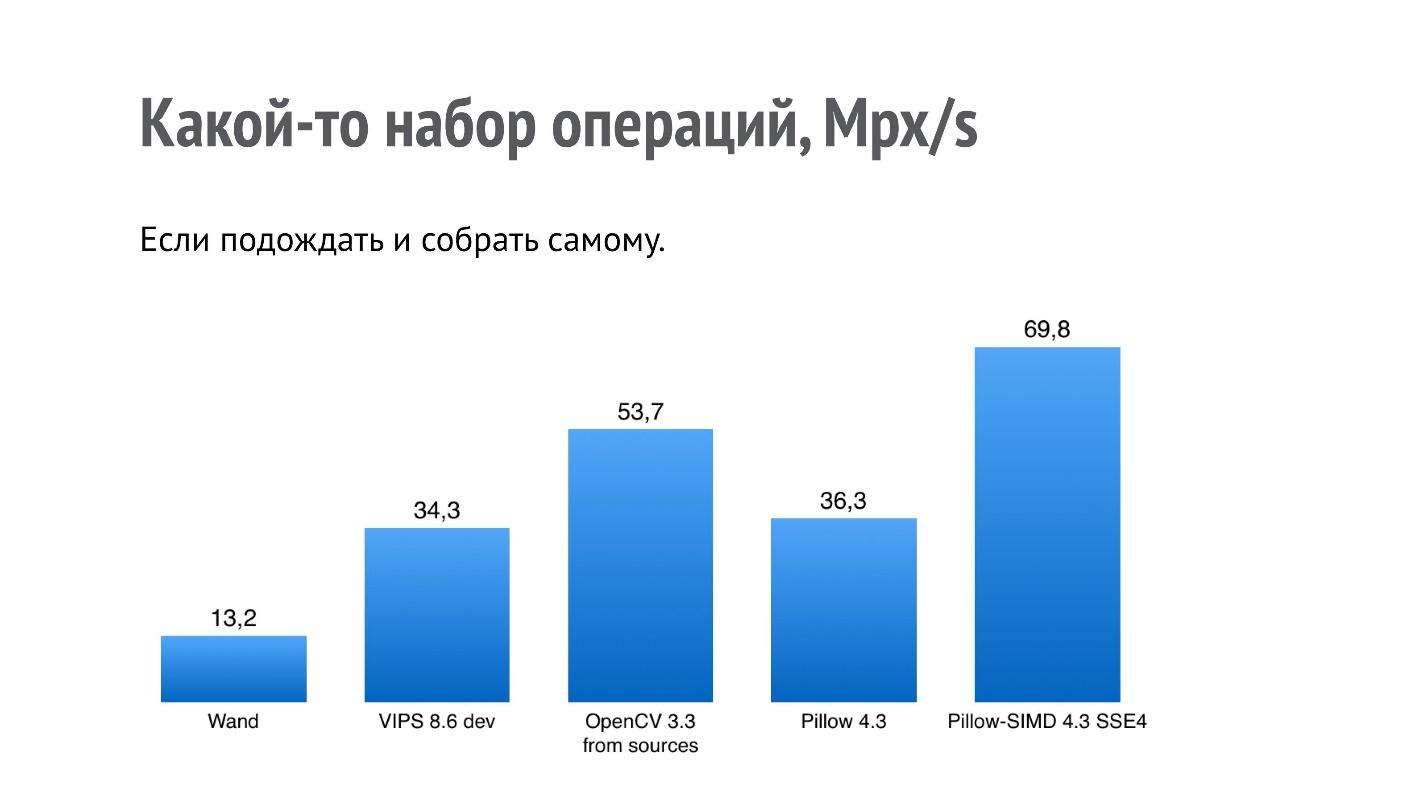
That's what will happen with performance if you compile OpenCV from the sources of the current version, and VIPS comes from the master, which is already there.
Set of benchmarks
All the benchmarks that I talked about can be found on the results page . This is a separate mini-project, where I write benchmarks that I myself need to develop Pillow-SIMD, launch them and post the results.
On GitHub there is a project with frameworks for testing, where everyone can offer their own benchmarks or correct existing ones.
Parallel work
So far I have been talking about performance in its pure form, that is, on one processor core. But we all have long been available systems with a large number of cores, and I would like to dispose of them. Here I must say that in fact Pillow is the only library in question that does not use task parallelization. I will now try to explain why this is happening. All other libraries in one form or another use it.
Performance metrics
In terms of performance, we are interested in 2 parameters:
Based on these two metrics we consider different ways of parallel work.
Ways of parallel work
1. At the application level , when you at the application level decide that operations are processed in different threads. At the same time, the actual execution time of one operation does not change, because, as before, one core deals with one sequence of operations. The system capacity increases in proportion to the number of cores, that is, very well.
2. At the level of graphic operations - that is what is in most graphic libraries. When a graphics library receives an operation, it internally creates the required number of threads, breaks one operation into several smaller ones, and performs them. At the same time, the actual execution time is reduced - one operation is performed faster. But bandwidth is growing far from linear.on the number of cores. There are operations that do not parallel, and a vivid example is the decoding of PNG files - it can not be parallelized. In addition, there are overhead costs for creating threads, splitting tasks that also do not allow throughput to grow linearly.
3. At the level of processor commands and data . We prepare data in a special way and use special commands in order for the processor to work with them faster. This is the SIMD approach, which, in fact, is used in Pillow-SIMD. Real runtime decreases, throughput grows - this is a win-win option .
How to combine parallel work
If we want to combine some kind of parallel work, then SIMD is well combined with parallelization inside the operation, and SIMD is well combined with parallelization inside the application.

But parallelization within the application and within the operation with each other are not combined. If you try to do this, you will get disadvantages from both approaches. The actual execution time of the operation will be the same as it was on one core, and the system capacity will grow, but not linearly relative to the number of cores.
Multithreading
If we are already talking about threads, we all write in Python and we know that it contains GIL, which does not allow two threads to run at the same time. Python is strictly a single-threaded language.
Of course, this is not true, because GIL actually does not allow two threads to run in Python, and if the code is written in another language and does not use internal Python structures during its work, then this code can release GIL and thus free the interpreter for other tasks.
Many libraries for working with graphics release GIL during their work, including Pillow, OpenCV, pyvips, Wand. Only one does not release - pgmagick. That is, you can safely create threads for performing some operations, and this will work in parallel with the rest of the code.
But the question arises:how many threads to create?
If we create an infinite number of threads for each task that we have, they will simply occupy all the memory and the entire processor - we will not get any effective work. I formulated a special rule.
It is best to use processes, because even within a single interpreter there are bottlenecks and overheads.
For example, in our application we use N + 1 Instance Tornado, balancing between them by ngnix. If Tornado is mentioned, then let's talk about asynchronous operation.
Asynchronous operation
The time that the graphics library actually does is useful work — image processing — can and should be used for I / O, if you have them in the application. Asynchronous frameworks are very much in topic here.
But there is a problem - when we call some kind of processing, it is called synchronously. Even if the library releases GIL at this point, the Event Loop is still blocked.
Fortunately, this problem is very easy to solve by creating a ThreadPoolExecutor with one thread, which starts image processing. This call is already happening asynchronously.
In fact, a queue with one worker is created here that performs exactly graphic operations, and the Event Loop is not blocked and quietly runs in parallel in another thread.
Input Output
Another topic that I would like to touch upon in a conversation about graphic operations is input / output. The fact is that we rarely create some images using a graphic library. Most often we open images that came to us from users in the form of encoded files (JPEG, PNG, BMP, TIFF, etc.).
Accordingly, the graphic library for building a good application should have some I / O buns from the files.
Lazy loading
The first such bun is lazy loading. If, for example, in Pillow you open an image, then at this moment there is no decoding of the picture. You are returned an object that looks as if the image has already been loaded and is working. You can view its properties and decide, based on the properties of this image, whether you are ready to work with it further, whether the user has downloaded you, for example, a gigapixel image in order to break your service.
If you decide that you are working further, then using an explicit or implicit call to load, the image is decoded. Already at this moment the necessary amount of memory is allocated.
Broken picture mode
The second bun that is needed when working with user-generated content is a mode of broken pictures. The files that we receive from users very often contain some inconsistencies with the format in which they are encoded.
These inconsistencies are for various reasons. Sometimes these are network transmission errors, sometimes they are just some kind of curved codecs that encoded an image. By default, Pillow, when it sees images that do not fit the format to the end, simply throws an exception.
But the user is not to blame for the fact that his picture is broken, he still wants to get the result. Fortunately, Pillow has a mode of broken pictures. We change one setting, and Pillow tries to ignore to the maximum all the decoding errors that are in the image. Accordingly, the user sees at least something.

Even a cropped picture is still better than nothing - just a page with an error.
Summary table
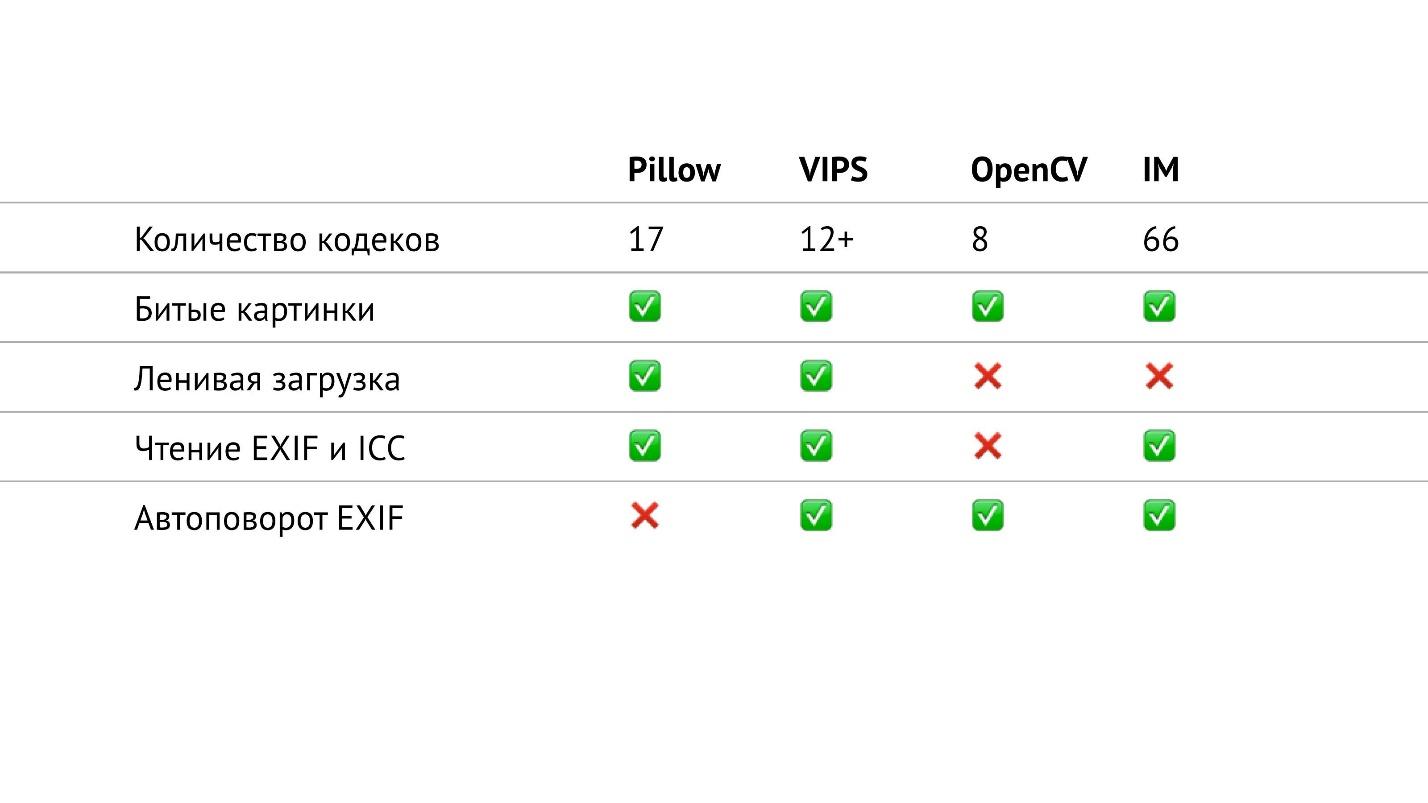
In the table above, I collected everything related to input / output in the libraries that I am talking about. In particular, I counted the number of codecs of various formats that are in libraries. It turned out that in OpenCV they are the least of all, in ImageMagick - the most. It seems that in ImageMagick you can open generally any image that you meet. VIPS has 12 native codecs, but VIPS can use ImageMagick as an intermediate. I did not check how it works, hopefully seamless.
In Pillow 17 codecs. It is now the only library in which there is no EXIF auto rotate. But now it is a small problem, because you can read the EXIF yourself and rotate the image in accordance with it. This is a question of a small snippet, which is easily googled and takes up a maximum of 20 lines.
OpenCV Features
If you look at this table closely, you can see that in OpenCV, in fact, not everything is so good with input / output. It has the least amount of codecs, there is no lazy loading and you cannot read the EXIF and color profile.
But that's not all. In fact, OpenCV has more features. When we just open some image, the call is
Fortunately, OpenCV has a flag:
If you specify the IMREAD_UNCHANGED flag, OpenCV leaves the alpha channel of the PNG files, but stops rotating the JPEG files in accordance with EXIF. That is, the same flag affects two completely different properties. As can be seen from the table, OpenCV does not have the ability to read EXIF, and it turns out that in the case of this flag it is impossible to rotate JPEG at all.
What to do if you do not know in advance what format you have the image, and you need both the PNG alpha channel and the JPEG auto-rotation? Do nothing - OpenCV doesn't work that way.
The reason why OpenCV has such problems lies in the name of this library. It has a lot of functionality for computer vision and image analysis. In fact, OpenCV is designed to work with verified sources. This, for example, is a surveillance camera, which once every second throws off images, and does this for 5 years in the same format and the same resolution. There is no need for variability in the I / O issue.
People who need OpenCV functionality do not really need the functionality of working with custom content.
But what to do if in your application you still need the functionality of working with user content, and at the same time, you need all the power of OpenCV in processing and statistics?

The solution is to combine libraries. The fact is that OpenCV is built on the basis of numpy, and Pillow has all the means to export images from Pillow to the numpy array. That is, we export the numpy array, and OpenCV can continue to work with this image, as with its own. This is done very easily:
Further, when we do magic with the help of OpenCV (processing), we call another Pillow method and back import the image into the Pillow format from OpenCV. Accordingly, you can use I / O again.
Thus, it turns out that we use input / output from Pillow, and processing from OpenCV, that is, we take the best of both worlds.
I hope this helps you to build a loaded application for working with graphics.
About the speaker: Alexander Karpinsky works in the company Uploadcare and is engaged in the service of quick image modification on the fly. Participates in the development of Pillow - a popular library for working with images in Python, develops its own fork of this library - Pillow-SIMD , which uses modern instructions of processors for the greatest performance.
Background
The image modification service in Uploadcare is a server that receives an HTTP request with an image identifier and some operations that need to be performed by the client. The server must perform the operation and respond as quickly as possible. The client most often is the browser.
The entire service can be described as a wrapper around a graphic library. The quality of the whole project depends on the quality, performance and usability of the graphic library. It is easy to guess that Pillow is used as a graphic library in Uploadcare.
Libraries
Let's briefly consider what kind of graphics libraries exist in Python in order to better understand what will be discussed further.
Pillow
Pillow - fork PIL (Python Imaging Library). This is a very old project released in 1995 for Python 1.2. You can imagine how old he is! At some point, the Python Imaging Library was abandoned, its development stopped. Fork Pillow was made in order to install and build the Python Imaging Library on modern systems. Gradually, the number of changes that people needed in the Python Imaging Library grew, and Pillow 2.0 was released, which added support for Python 3. This can be considered the beginning of a separate Pillow project life.
Pillow is a native module for Python, half of the code is written in C, half in Python. Versions of Python are supported the most diverse: 2.7, 3.3+, Ppu, PpuZ.
Pillow-SIMD
This is my fork Pillow, which comes out from May 2016. SIMD means Single Instruction, Multiple Data is an approach in which the processor can perform more actions per clock using modern instructions.
Pillow-SIMD is not a fork in the classic sense when a project begins to live its own life. This is a replacement for Pillow, that is, you install one library instead of another, you do not change a line in your source code, and you get great performance.
Pillow-SIMD can be built with SSE4 instructions (default). This is a set of instructions that exists in almost all modern x86 processors. Also Pillow-SIMD can be assembled with the AVX2 instruction set. This set of instructions is, starting with the architecture Haswell, that is, from about 2013.
Opencv
Another library for working with images in Python that you've probably heard about is OpenCV (Open Computer Vision). Works since 2000. Binding in Python included. This means that the binding is always up to date, there is no dissynchrony between the library itself and the binding.
Unfortunately, this library is not yet supported in PyPy, because OpenCV is based on numpy, and numpy only recently started working under PyPy, and PyPy still does not support OpenCV.
VIPS
Another library worth paying attention to is VIPS. The main idea of VIPS is that in order to work with an image, you do not need to load the entire image into memory. The library can load some small pieces, process them and save. Thus, to process gigapixel images, you do not need to waste gigabytes of memory.
This is a rather old library from 1993, but it is ahead of its time. For a long time, there was little to hear about it, but lately, for VIPS, bindings for different languages began to appear, including Go, Node.js, Ruby.
I wanted to try this library for a long time, to feel it, but I could not do it for a very stupid reason. I could not figure out how to install VIPS, because binding was going very hard. But now (in 2017) there is a pyvips binding from the author of the VIPS himself, with whom there are no problems anymore. Now installing and using VIPS is very simple. Supported: Python 2.7, 3.3+, Ppu, PpuZ.
ImageMagick & GraphicsMagick
If we talk about working with graphics, then not to mention the old men - ImageMagick and GraphicsMagick libraries . The latter was originally a fork of ImageMagick with greater performance, but now their performance seems to be equal. There are no other fundamental differences, as far as I know, between them. Therefore, you can use any, more precisely, the one that you prefer to use.
These are the oldest libraries I have mentioned today (1990). During all this time, there have been several bindings for Python, and almost all of them have safely died by now. Of those that can be used, left:
- Binding Wand, which is built on ctypes, but is also not updated.
- Binding pgmagick uses Boost.Python, so it compiles for a very long time and does not work in PyPy. But, nevertheless, you can use it, I would say that it is preferable to the Wand.
Performance
When we talk about working with images, the first thing that interests us (at least to me) is productivity, because otherwise we could write something in Python with our hands.
Performance is not such a simple thing. You can't just say that one library is faster than another. Each library has a set of functions, and each function operates at a different speed.
Accordingly, it is correct to say only that the performance of one function is higher or lower in a particular library. Either you have an application that needs a certain set of functionality, and you make a benchmark for this functionality, and say that for your application such a library runs faster (slower).
It is important to check the result.
When you make benchmarks, it is very important to look at the result that is obtained. Even if at first glance you wrote the same code, it does not mean that it is the same.
Recently, in an article comparing the performance of Pillow and OpenCV, I came across this code:
from PIL import Image, ImageFilter.BoxBlur
im.filter(ImageFilter.BoxBlur(3))
...
import cv2
cv2.blur(im, ksize=(3, 3))
...
It seems to be both there and there, BoxBlur, and there, and there argument 3, but in fact the result is different. Because in Pillow (3) this is the radius of the blur, and in OpenCV, ksize = (3, 3) is the size of the core, that is, roughly speaking, the diameter. In this case, the correct value for OpenCV would be 3 * 2 + 1, that is, (7, 7).
What is the problem?
Why is performance at all a problem when working with graphics? Because the complexity of any operations depends on several parameters, and most often the complexity grows linearly with each of them. And if there are three of these factors, for example, and the complexity is linearly dependent on each, then the complexity is in a cube.
Example: Gaussian Blur in OpenCV.
Left - radius 3, right - 30. As you can see, the difference in speed is more than 10 times.
When I was faced with the task of adding a Gaussian blur to my application, I was not satisfied that 900 ms can be hypothetically spent on performing a single operation. Such operations in the application of thousands per minute, and spend so much time on one - it is inappropriate. Therefore, I studied the question and implemented a Pilot blur according to Gauss, which works for a constant time relative to the radius. That is, only the size of the image affects the performance of Gaussian blur.
But the main thing here is not that something works faster or slower.
I want to convey that when you build a system, it is important to understand the parameters on which the output complexity depends. Then you can limit these parameters or in other ways deal with this complexity.
Probably the most frequent operation that we do with images after opening them is resize.
The graph shows the performance (more - better) of different libraries for the operation of reducing the image in 8 and 1.25 times.
For PIL, a result of 17 Mpx / s means that a photo from an iPhone (12 Mpx) can be reduced 1.25 times in a little less than a second. Such performance is not enough for a serious application that performs a lot of these operations.
I began to optimize the performance of the resize, and in Pillow 2.7 I managed to achieve a two-fold increase in performance, and in Pillow 4.3, a three-fold increase (Pillow 5.3 is currently relevant, but the resize performance is the same).
But the resize operation is such a thing that fits very well on SIMD. It comes up to single instruction, multiple data, and therefore in the current version of Pillow-SIMD I was able to increase the resize speed by 19 times compared to the original Python Imaging Library using the same resources.
This is significantly higher resize performance in OpenCV. But the comparison is not entirely correct, because OpenCV uses a slightly lower quality method of resizing with a box filter, and in Pillow-SIMD, resizing is implemented using convolutions.
This is an incomplete list of those operations that are accelerated in Pillow-SIMD compared to conventional Pillow.
- Resize: 4 to 7 times.
- Blur: 2.8 times.
- Use of a 3 × 3 or 5 × 5 core: 11 times.
- Multiplication and division by alpha channel: 4 and 10 times.
- Alpha composition: 5 times.
I have already said that it is impossible to say that some library is faster than the other, but you can make up a set of operations that are interesting for you. I chose a set of operations that are interesting in my application, made a benchmark and got such results.
It turned out that Pillow-SIMD on this set works 2 times faster than Pillow. At the very end is Wand (remember, this is ImageMagick).
But I was interested in something else - why are so low results in OpenCV and VIPS, because these are libraries that are also designed with a view to performance? It turned out that in the case of OpenCV, that binary assembly of OpenCV, which is installed using pip, is compiled with a slow JPEG codec (the author of the assembly was notified, for 2018 this problem has already been solved). It is compiled with libjpeg, while on most systems, at least debian-based, libjpeg-turbo is used, which works several times faster. If you compile OpenCV from source itself, then the performance will be greater.
In the case of VIPS, the situation is different. I contacted the author of the VIPS, showed him this benchmark, we had a long and fruitful correspondence with him. After that, the author of VIPS found several places in the VIPS itself, where the performance was not on the optimal route, and corrected them.
That's what will happen with performance if you compile OpenCV from the sources of the current version, and VIPS comes from the master, which is already there.
Even if you have found some kind of benchmark, it’s not a fact that everything will work with such speed on your machine.
Set of benchmarks
All the benchmarks that I talked about can be found on the results page . This is a separate mini-project, where I write benchmarks that I myself need to develop Pillow-SIMD, launch them and post the results.
On GitHub there is a project with frameworks for testing, where everyone can offer their own benchmarks or correct existing ones.
Parallel work
So far I have been talking about performance in its pure form, that is, on one processor core. But we all have long been available systems with a large number of cores, and I would like to dispose of them. Here I must say that in fact Pillow is the only library in question that does not use task parallelization. I will now try to explain why this is happening. All other libraries in one form or another use it.
Performance metrics
In terms of performance, we are interested in 2 parameters:
- Real time to complete a single operation. There is an operation (or a sequence of operations), and you wonder what the actual time (wall clock) this sequence will perform. This parameter is important on the desktop, where there is a user who gave the command and is waiting for the result.
- The bandwidth of the entire system (workflow). When you have a set of operations that goes on constantly, or many independent operations, and the speed of processing these operations on your hardware is important to you. This metric is more important on the server, where there are many customers, and you need to serve them all. The service time of a single client, of course, is important, but slightly less than the total bandwidth.
Based on these two metrics we consider different ways of parallel work.
Ways of parallel work
1. At the application level , when you at the application level decide that operations are processed in different threads. At the same time, the actual execution time of one operation does not change, because, as before, one core deals with one sequence of operations. The system capacity increases in proportion to the number of cores, that is, very well.
2. At the level of graphic operations - that is what is in most graphic libraries. When a graphics library receives an operation, it internally creates the required number of threads, breaks one operation into several smaller ones, and performs them. At the same time, the actual execution time is reduced - one operation is performed faster. But bandwidth is growing far from linear.on the number of cores. There are operations that do not parallel, and a vivid example is the decoding of PNG files - it can not be parallelized. In addition, there are overhead costs for creating threads, splitting tasks that also do not allow throughput to grow linearly.
3. At the level of processor commands and data . We prepare data in a special way and use special commands in order for the processor to work with them faster. This is the SIMD approach, which, in fact, is used in Pillow-SIMD. Real runtime decreases, throughput grows - this is a win-win option .
How to combine parallel work
If we want to combine some kind of parallel work, then SIMD is well combined with parallelization inside the operation, and SIMD is well combined with parallelization inside the application.
But parallelization within the application and within the operation with each other are not combined. If you try to do this, you will get disadvantages from both approaches. The actual execution time of the operation will be the same as it was on one core, and the system capacity will grow, but not linearly relative to the number of cores.
Multithreading
If we are already talking about threads, we all write in Python and we know that it contains GIL, which does not allow two threads to run at the same time. Python is strictly a single-threaded language.
Of course, this is not true, because GIL actually does not allow two threads to run in Python, and if the code is written in another language and does not use internal Python structures during its work, then this code can release GIL and thus free the interpreter for other tasks.
Many libraries for working with graphics release GIL during their work, including Pillow, OpenCV, pyvips, Wand. Only one does not release - pgmagick. That is, you can safely create threads for performing some operations, and this will work in parallel with the rest of the code.
But the question arises:how many threads to create?
If we create an infinite number of threads for each task that we have, they will simply occupy all the memory and the entire processor - we will not get any effective work. I formulated a special rule.
Rule N + 1
For productive work, you need to create no more than N + 1 workers, where N is the number of cores or processor threads on the machine, and the worker is the process or thread that is being processed.
It is best to use processes, because even within a single interpreter there are bottlenecks and overheads.
For example, in our application we use N + 1 Instance Tornado, balancing between them by ngnix. If Tornado is mentioned, then let's talk about asynchronous operation.
Asynchronous operation
The time that the graphics library actually does is useful work — image processing — can and should be used for I / O, if you have them in the application. Asynchronous frameworks are very much in topic here.
But there is a problem - when we call some kind of processing, it is called synchronously. Even if the library releases GIL at this point, the Event Loop is still blocked.
@gen.coroutinedefget(self, *args, **kwargs):
im = process_image(...)
...
Fortunately, this problem is very easy to solve by creating a ThreadPoolExecutor with one thread, which starts image processing. This call is already happening asynchronously.
@run_on_executor(executor=ThreadPoolExecutor(1))defprocess_image(self,
...
@gen.coroutine
def get(self, *args, **kwargs):
im = yield process_image(...)
...
In fact, a queue with one worker is created here that performs exactly graphic operations, and the Event Loop is not blocked and quietly runs in parallel in another thread.
Input Output
Another topic that I would like to touch upon in a conversation about graphic operations is input / output. The fact is that we rarely create some images using a graphic library. Most often we open images that came to us from users in the form of encoded files (JPEG, PNG, BMP, TIFF, etc.).
Accordingly, the graphic library for building a good application should have some I / O buns from the files.
Lazy loading
The first such bun is lazy loading. If, for example, in Pillow you open an image, then at this moment there is no decoding of the picture. You are returned an object that looks as if the image has already been loaded and is working. You can view its properties and decide, based on the properties of this image, whether you are ready to work with it further, whether the user has downloaded you, for example, a gigapixel image in order to break your service.
>>> from PIL import Image
>>> %time im = Image.open()
Wall time: 1.2 ms
>>> im.mode, im.size
('RGB', (2152, 1345))
If you decide that you are working further, then using an explicit or implicit call to load, the image is decoded. Already at this moment the necessary amount of memory is allocated.
>>> from PIL import Image
>>> %time im = Image.open()
Wall time: 1.2 ms
>>> im.mode, im.size
('RGB', (2152, 1345))
>>> %time im.load()
Wall time: 73.6 ms
Broken picture mode
The second bun that is needed when working with user-generated content is a mode of broken pictures. The files that we receive from users very often contain some inconsistencies with the format in which they are encoded.
These inconsistencies are for various reasons. Sometimes these are network transmission errors, sometimes they are just some kind of curved codecs that encoded an image. By default, Pillow, when it sees images that do not fit the format to the end, simply throws an exception.
from PIL import Image
Image.open('trucated.jpg').save('trucated.out.jpg')
IOError: image file is truncated (143 bytes not processed)
But the user is not to blame for the fact that his picture is broken, he still wants to get the result. Fortunately, Pillow has a mode of broken pictures. We change one setting, and Pillow tries to ignore to the maximum all the decoding errors that are in the image. Accordingly, the user sees at least something.
from PIL import Image, ImageFile
ImageFile.LOAD_TRUNCATED_IMAGES = True
Image.open('trucated.jpg').save('trucated.out.jpg')
Even a cropped picture is still better than nothing - just a page with an error.
Summary table
In the table above, I collected everything related to input / output in the libraries that I am talking about. In particular, I counted the number of codecs of various formats that are in libraries. It turned out that in OpenCV they are the least of all, in ImageMagick - the most. It seems that in ImageMagick you can open generally any image that you meet. VIPS has 12 native codecs, but VIPS can use ImageMagick as an intermediate. I did not check how it works, hopefully seamless.
In Pillow 17 codecs. It is now the only library in which there is no EXIF auto rotate. But now it is a small problem, because you can read the EXIF yourself and rotate the image in accordance with it. This is a question of a small snippet, which is easily googled and takes up a maximum of 20 lines.
OpenCV Features
If you look at this table closely, you can see that in OpenCV, in fact, not everything is so good with input / output. It has the least amount of codecs, there is no lazy loading and you cannot read the EXIF and color profile.
But that's not all. In fact, OpenCV has more features. When we just open some image, the call is
cv2.imread(filename)rotated by JPEG-files in accordance with EXIF (see table), but it ignores the alpha channel of PNG files - rather strange behavior! Fortunately, OpenCV has a flag:
cv2.imread(filename, flags=cv2.IMREAD_UNCHANGED).If you specify the IMREAD_UNCHANGED flag, OpenCV leaves the alpha channel of the PNG files, but stops rotating the JPEG files in accordance with EXIF. That is, the same flag affects two completely different properties. As can be seen from the table, OpenCV does not have the ability to read EXIF, and it turns out that in the case of this flag it is impossible to rotate JPEG at all.
What to do if you do not know in advance what format you have the image, and you need both the PNG alpha channel and the JPEG auto-rotation? Do nothing - OpenCV doesn't work that way.
The reason why OpenCV has such problems lies in the name of this library. It has a lot of functionality for computer vision and image analysis. In fact, OpenCV is designed to work with verified sources. This, for example, is a surveillance camera, which once every second throws off images, and does this for 5 years in the same format and the same resolution. There is no need for variability in the I / O issue.
People who need OpenCV functionality do not really need the functionality of working with custom content.
But what to do if in your application you still need the functionality of working with user content, and at the same time, you need all the power of OpenCV in processing and statistics?
The solution is to combine libraries. The fact is that OpenCV is built on the basis of numpy, and Pillow has all the means to export images from Pillow to the numpy array. That is, we export the numpy array, and OpenCV can continue to work with this image, as with its own. This is done very easily:
import numpy
from PIL import Image
...
pillow_image = Image.open(filename)
cv_image = numpy.array(pillow_image)
Further, when we do magic with the help of OpenCV (processing), we call another Pillow method and back import the image into the Pillow format from OpenCV. Accordingly, you can use I / O again.
import numpy
from PIL import Image
...
pillow_image = Image.fromarray(cv_image, "RGB")
pillow_image.save(filename)
Thus, it turns out that we use input / output from Pillow, and processing from OpenCV, that is, we take the best of both worlds.
I hope this helps you to build a loaded application for working with graphics.
Learn some other secrets of development in Python, learn from the invaluable and sometimes unexpected experience, and most importantly, you can discuss your tasks very soon in Moscow Python Conf ++ . For example, pay attention to such names and topics in the schedule.
- Donald Whyte with the story of how using popular libraries, tricks and deceit to do mathematics 10 times faster, and the code - understandable and supported.
- Andrei Popov about the collection of a huge amount of data and their analysis for the presence of threats.
- Efrem Matosyan in his report “Make Python fast again” will tell how to increase the performance of the daemon that processes messages from the bus.
A complete list of what is to be discussed for October 22 and 23 here , have time to join.