14 questions about indexes in SQL Server that you were shy to ask
- Transfer
- Tutorial
Indexes are the first thing that you need to understand well in SQL Server , but in a strange way, basic questions are not asked too often in forums and there are not many answers.
Rob Sheldon answers these embarrassing questions in the professional community about indexes in SQL Server : we’re just shy to ask some of them, and first think twice before asking others.
From translator
This post is a compilation of two articles by Rob Sheldon:
If you write queries in T-SQL , but do not understand where the data comes from, then you should read this translation.
If you want to know more, then at the end of the translation I give three books from which to move on.
- SQL Server Index Basics November 25, 2008 (note provides an understanding of the basic terms)
- 14 SQL Server Indexing Questions You Were Too Shy To Ask dated March 25, 2014 (in fact, everything was started for her sake)
If you write queries in T-SQL , but do not understand where the data comes from, then you should read this translation.
If you want to know more, then at the end of the translation I give three books from which to move on.
Used terminology in Russian translation
| index | index |
| heap | a bunch |
| table | table |
| view | representation |
| B-tree | balanced tree |
| clustered index | clustered index |
| nonclustered index | nonclustered index |
| composite index | composite index |
| covering index | covering index |
| primary key constraint | primary key restriction |
| unique constraint | uniqueness constraint |
| query | inquiry |
| query engine | query subsystem |
| database | database |
| database engine | data storage subsystem |
| fill factor | index fill factor |
| surrogate primary key | surrogate primary key |
| query optimizer | query optimizer |
| index selectivity | index selectivity |
| filtered index | filtered index |
| execution plan | implementation plan |
Skip reading the basics and go directly to 14 questions
Index Basics in SQL Server
One of the most important ways to achieve high SQL Server performance is to use indexes. An index speeds up the query process by providing quick access to rows of data in a table, similar to how a pointer in a book helps you quickly find the information you need. In this article, I will give a brief overview of indexes in SQL Server and explain how they are organized in a database and how they help speed up database queries.
Index structure
Indexes are created for table columns and views. Indexes provide a way to quickly find data based on the values in these columns. For example, if you create an index by the primary key, and then look for the data row using the primary key values, then SQL Server will first find the index value, and then use the index to quickly find the entire data row. Without an index, a full scan (scan) of all rows in the table will be performed, which can have a significant impact on performance.
You can create an index on most columns of a table or view. The exception is mainly columns with data types for storing large objects ( LOB ), such as image , textor varchar (max) . You can also create indexes on columns intended for storing data in XML format , but these indexes are arranged slightly different than standard ones and their consideration is beyond the scope of this article. Also, columnstore indexes are not considered in the article . Instead, I focus on those indexes that are most commonly used in SQL Server databases .
An index consists of a set of pages, index nodes, which are organized in a tree structure - a balanced tree . This structure is hierarchical in nature and begins with a root node at the top of the hierarchy and leaf nodes, leaves, at the bottom, as shown in the figure:
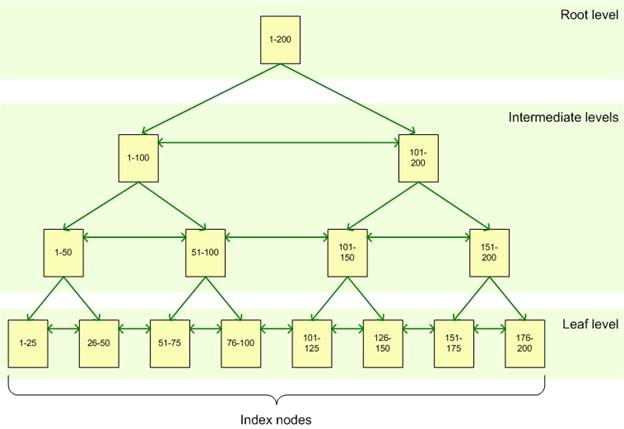
When you create a query for an indexed column, the query subsystem starts to go above the root node and gradually moves down through the intermediate nodes, with each layer of the intermediate level containing more detailed information about the data. The query subsystem continues to move through the nodes of the index until it reaches the bottom level with the leaves of the index. For example, if you are looking for the value 123 in an indexed column, then the query subsystem will first determine the page at the root level at the first intermediate level. In this case, the first page indicates a value from 1 to 100, and the second from 101 to 200, so the query subsystem will turn to the second page of this intermediate level. Next, it will be found that you should refer to the third page of the next intermediate level. From here, the query subsystem will read at the lower level the value of the index itself. The leaves of the index can contain both the data of the table itself, or just a pointer to the rows with the data in the table, depending on the type of index: a clustered index or a non-clustered one.
Clustered index
A clustered index stores real rows of data in index leaves. Returning to the previous example, this means that the data string associated with the key value of 123 will be stored in the index itself. An important characteristic of a clustered index is that all values are sorted in a specific order, either increasing or decreasing. Thus, a table or view can have only one clustered index. In addition, it should be noted that the data in the table is stored in sorted form only if a clustered index is created for this table.
A table that does not have a clustered index is called a heap.
Nonclustered Index
Unlike a clustered index, non-clustered index leaves contain only those columns ( key), by which this index is defined, and also contains a pointer to rows with real data in the table. This means that the subquery system needs an additional operation to discover and retrieve the required data. The content of the data pointer depends on how the data is stored: a clustered table or a heap. If the pointer refers to a clustered table, then it leads to a clustered index, using which you can find real data. If the pointer refers to the heap, then it leads to a specific identifier for the data row. Non-clustered indexes cannot be sorted, unlike clustered ones, however you can create more than one non-clustered index on a table or view, up to 999. This does not mean that you must create as many indexes as possible. Indices can both improve, and degrade system performance. In addition to being able to create multiple non-clustered indexes, you can also include additional columns (included column ) in its index: not only the value of the indexed columns themselves, but also the values of these non-indexed additional columns will be stored on the index leaves. This approach will allow you to get around some of the restrictions placed on the index. For example, you can include a non-indexable column or bypass the index length limit (900 bytes in most cases).
Types of Indexes
In addition to being either clustered or non-clustered, it is possible to further configure it as a composite index, a unique index, or a covering index.
Composite index
Such an index may contain more than one column. You can include up to 16 columns in the index, but their total length is limited to 900 bytes. Both clustered and nonclustered indexes can be composite.
Unique index
Such an index ensures the uniqueness of each value in the indexed column. If the index is composite, then the uniqueness extends to all columns of the index, but not to each individual column. For example, if you create a unique index on the NAME and SURNAME columns , the full name must be unique, but duplicates in the first or last name are possible separately.
A unique index is automatically created when you define column restrictions: primary key or restriction on the uniqueness of values:
- Primary key
When you define a primary key restriction on one or more columns, then SQL Server automatically creates a unique clustered index if the clustered index has not been created before (in this case, a unique non-clustered index is created on the primary key) - Uniqueness of values
When you define a restriction on the uniqueness of values, then SQL Server automatically creates a unique non-clustered index. You can specify that a unique clustered index be created if a clustered index has not yet been created on the table
Covering Index
Such an index allows a particular query to immediately get all the necessary data from the index leaves without additional calls to the records of the table itself.
Index Design
How useful indexes can be, so carefully they need to be designed. Since indexes can occupy significant disk space, you will not want to create indexes more than necessary. In addition, indexes are automatically updated when the data row itself is updated, which can lead to additional overhead and lower performance. When designing indexes, several considerations should be taken into account regarding the database and its queries.
Database
As noted earlier, indexes can improve system performance because they provide a query subsystem in a quick way to find data. However, you should also consider how often you intend to insert, update or delete data. When you modify data, the indices must also be changed to reflect the corresponding actions on the data, which can significantly reduce system performance. Consider the following guidelines when planning your indexing strategy:
- For tables that are frequently updated, use as few indexes as possible.
- If the table contains a large amount of data, but their changes are insignificant, then use as many indexes as necessary to improve the performance of your queries. However, think carefully before using indexes on small tables, as perhaps using index search may take longer than just scanning all the rows.
- For clustered indexes, try to use as short fields as possible. The best way would be to use a clustered index on columns with unique values and not allowing NULL. This is why the primary key is often used as a clustered index.
- The uniqueness of the values in the column affects the performance of the index. In general, the more duplicates you have in a column, the worse the index works. On the other hand, the more unique values, the higher the efficiency of the index. Whenever possible use a unique index.
- For a composite index, take into account the order of the columns in the index. The columns used in the WHERE clauses (for example, WHERE FirstName = 'Charlie' ) must be the first in the index. Subsequent columns should be listed taking into account the uniqueness of their values (columns with the highest number of unique values come first).
- You can also specify an index on calculated columns if they meet certain requirements. For example, the expression that is used to obtain the column value must be deterministic (always return the same result for a given set of input parameters).
Database Queries
Another consideration to consider when designing indexes is which queries are executed against the database. As stated earlier, you must consider how often the data changes. Additionally, the following principles should be used:
- Try to insert or modify as many rows as possible in one query, rather than doing so in several single queries.
- Create a non-clustered index on columns that are often used in your queries as search terms in WHERE and joins in JOIN .
- Consider indexing the columns used in row lookups for exact match values.
And now, actually:
14 questions about indexes in SQL Server that you were shy to ask
Why can't a table have two clustered indexes?
If a clustered table provides many benefits, then why use a bunch?
How to change the default index fill factor value?
Is it possible to create a clustered index on a column containing duplicates?
How is a table stored if a clustered index has not been created?
What is the relationship between restrictions on the uniqueness of a value and a primary key with table indices?
Why are clustered and nonclustered indexes called a balanced tree in SQL Server?
How can an index generally improve query performance if you have to navigate through all these index nodes?
If the indexes are so wonderful, then why not just create them on each column?
Is it mandatory to create a clustered index on a column with a primary key?
But what if you index the view, will it still be the view?
Why use a covering index instead of a composite index?
Does the number of duplicates in the key column matter?
Is it possible to create a non-clustered index only for a specific subset of key column data?
Why can't a table have two clustered indexes?
Want a short answer? A clustered index is the table. When you create a clustered index on a table, the data storage subsystem sorts all rows in the table in ascending or descending order, according to the definition of the index. A clustered index is not a separate entity like other indexes, but a mechanism for sorting data in a table and facilitating quick access to rows with data.
Imagine that you have a table containing the history of sales operations. The Sales table includes information such as the order identifier, item position in the order, item number, item quantity, order number and date, etc. You create a clustered index on the OrderID and LineID columns , sorted in ascending order, as shown in the followingT-SQL code:
CREATE UNIQUE CLUSTERED INDEX ix_oriderid_lineid
ON dbo.Sales(OrderID, LineID); When you run this script, all rows in the table will be physically sorted first by the OrderID column, and then by the LineID, but the data itself will remain in a single logical block, in the table. For this reason, you cannot create two clustered indexes. There can only be one table with the same data, and this table can only be sorted once in a specific order.
If a clustered table provides many benefits, then why use a bunch?
You're right. Clustered tables are great and most of your queries will be better executed for tables that have a clustered index. But in some cases, you might want to leave the tables in their natural pristine state, i.e. in the form of a heap, and create only non-clustered indexes to maintain the health of your queries.
A heap, as you recall, stores data in random order. Typically, the data storage subsystem adds data to the table in the order in which they are inserted, but the subsystem also likes to move rows for more efficient storage. As a result, you have no chance to predict in what order the data will be stored.
If the query subsystem needs to find data without the benefits of a non-clustered index, then it will do a full table scan to find the rows it needs. On very small tables, this is usually not a problem, but as soon as the heap grows in size, performance drops rapidly. Of course, a non-clustered index can help by using a pointer to the file, page, and line where the necessary data is stored - usually this is a much better alternative to scanning the table. But even in this case, it is difficult to compare with the benefits of a clustered index when considering query performance.
However, heaps can help improve performance in certain situations. Consider a table with a large number of inserts, but rare updates or data deletion. For example, a table storing a log is mainly used to insert values until it is archived. On the heap, you will not see pagination and data fragmentation, as is the case with a clustered index, because the rows are simply added to the end of the heap. Too much page separation can have a significant impact on performance, and in a bad way. In general, a bunch allows you to insert data relatively painlessly and you will not have to deal with the overhead of storage and maintenance, as is the case with a clustered index.
But the lack of updating and deleting data should not be considered as the only reason. The way data is fetched is also an important factor. For example, you should not use the heap if you frequently perform queries on data ranges or the requested data often needs to be sorted or grouped.
All this means that you should consider using the heap only when working with extra-small tables or all your interaction with the table is limited to inserting data and your queries are extremely simple (and you use non-clustered indexes anyway). Otherwise, stick to a well-designed clustered index, such as defined on a simple incremental key field, as a widely used column with IDENTITY .
How to change the default index fill factor value?
Changing the default index fill factor is one thing. Understanding how the default ratio works is another. But first, a couple of steps back. The fill factor of the index determines the amount of space on the page to store the index at the lower level (leaf level) before you start filling out a new page. For example, if the coefficient is set to 90, then with growth, the index will take 90% on the page, and then go to the next page.
By default, the index fill factor value in SQL Serverequals 0, which is equivalent to 100. As a result, all new indexes automatically inherit this setting, unless you specifically specify a value different from the standard value for the system or change the default behavior. You can use SQL Server Management Studio to adjust the default value or run the sp_configure system stored procedure . For example, the following set of T-SQL commands sets the coefficient value to 90 (you must first switch to the advanced settings mode):
EXEC sp_configure 'show advanced options', 1;
GO
RECONFIGURE;
GO
EXEC sp_configure 'fill factor', 90;
GO
RECONFIGURE;
GO After changing the index fill factor, you must restart the SQL Server service . Now you can check the set value by running sp_configure without the second argument specified:
EXEC sp_configure 'fill factor'
GO This command should return a value equal to 90. As a result, all newly created indexes will use this value. You can verify this by creating an index and querying the fill factor:
USE AdventureWorks2012; -- ваша база данных
GO
CREATE NONCLUSTERED INDEX ix_people_lastname
ON Person.Person(LastName);
GO
SELECT fill_factor FROM sys.indexes
WHERE object_id = object_id('Person.Person')
AND name='ix_people_lastname'; In this example, we created a non-clustered index in the Person table in the AdventureWorks2012 database . After creating the index, we can get the fill factor from the sys.indexes system tables. The query should return 90.
However, imagine that we deleted the index and re-created it, but now we specified a specific fill factor:
CREATE NONCLUSTERED INDEX ix_people_lastname
ON Person.Person(LastName)
WITH (fillfactor=80);
GO
SELECT fill_factor FROM sys.indexes
WHERE object_id = object_id('Person.Person')
AND name='ix_people_lastname'; This time we added the WITH statement and the fillfactor option for our CREATE INDEX index creation operation and set the value to 80. The SELECT statement now returns the corresponding value.
So far, everything has been pretty straightforward. Where you can really get burned in this whole process is when you create an index using the default coefficient value, implying that you know this value. For example, someone is poorly tinkering with the server settings and is so tricky that it sets the index fill factor to 20. Meanwhile, you continue to create indexes, assuming a default value of 0. Unfortunately, you don’t have a way to find out the coefficient until you create an index, and then check the value, as we did in our examples. Otherwise, you have to wait until the query performance drops so much that you start to suspect something.
Another issue you should keep in mind is rebuilding indexes. As with creating an index, you can specify the value of the index fill factor when you rebuild it. However, unlike the index creation command, the rebuild does not use the server default settings, although it may seem so. Even more, if you do not specifically specify the index fill factor, then SQL Server will use the coefficient value with which the index existed before it was rebuilt. For example, the following ALTER INDEX operation rebuilds the index we just created:
ALTER INDEX ix_people_lastname
ON Person.Person REBUILD;
GO
SELECT fill_factor FROM sys.indexes
WHERE object_id = object_id('Person.Person')
AND name='ix_people_lastname'; When we check the fill factor, we get a value of 80, because that is what we specified when we last created the index. The default value is not taken into account.
As you can see, changing the index fill factor is not that difficult. It is much more difficult to know the current value and understand when it is applied. If you always specify the coefficient when creating and rebuilding indexes, then you always know the specific result. Unless you have to take care that someone else does not mess up the server settings again, causing the rebuild of all indexes with a ridiculously low index fill factor.
Is it possible to create a clustered index on a column containing duplicates?
Yes and no. Yes, you can create a clustered index on a key column containing duplicate values. No, the value of the key column will not be able to remain in a state of non-uniqueness. Let me explain. If you create a non-unique clustered index on a column, the data storage subsystem adds an uniquifier to the duplicate value to ensure uniqueness and, accordingly, provide the ability to identify each row in a clustered table.
For example, you might decide to create a clustered index on the LastName column in a table with customer dataholding the last name. The column contains values such as Franklin, Hancock, Washington, and Smith. Then you insert the values Adams, Hancock, Smith and Smith again. But the value of the key column must be unique, so the data storage subsystem will change the value of duplicates so that they look something like this: Adams, Franklin, Hancock, Hancock1234, Washington, Smith, Smith4567 and Smith5678.
At first glance, this approach seems normal, but an integer value increases the key size, which can become a problem with a large number of duplicates, and these values will become the basis of a non-clustered index or a foreign key reference. For these reasons, you should always try to create unique clustered indexes whenever possible. If this is not possible, then at least try to use columns with a very high content of unique values.
How is a table stored if a clustered index has not been created?
SQL Serversupports two types of tables: clustered tables that have a clustered index and heap tables, or just heaps. Unlike clustered tables, heap data is not sorted in any way. In fact, this is a heap (heap) of data. If you add a row to such a table, the data storage subsystem will simply add it to the end of the page. When the page is filled with data, they will be added to the new page. In most cases, you will want to create a clustered index on the table in order to get the benefits of the ability to sort and speed up queries (try to imagine finding a phone number in the address book that is not sorted by any principle). However, if you decide not to create a clustered index, then you can still create a non-clustered index on the heap. In this case, each row in the index will have a pointer to a row in the heap. The pointer includes a file identifier, page number and line number with data.
Какая взаимосвязь между ограничениями на уникальность значения и первичным ключом с индексами таблицы?
The primary key and uniqueness constraint ensure that the values in the column are unique. You can create only one primary key for a table and it cannot contain NULL values . You can create a table with several restrictions on the uniqueness of a value, and each of them can have a single record with NULL .
When you create a primary key, the data storage subsystem also creates a unique clustered index, in case an already clustered index has not been created. However, you can override the default behavior and then a non-clustered index will be created. If a clustered index exists when you create the primary key, a unique nonclustered index will be created.
When you create a unique constraint, the data storage subsystem creates a unique non-clustered index. But you can specify the creation of a unique clustered index, if it was not created earlier.
In general, a restriction on the uniqueness of a value and a unique index are one and the same.
Why are clustered and nonclustered indexes called a balanced tree in SQL Server?
Base indexes in SQL Server, whether clustered or non-clustered, are distributed across page sets — index nodes. These pages are organized in a specific hierarchy with a tree structure called a balanced tree. At the upper level, there is a root node, at the lower one, leaf leaf nodes, with intermediate nodes between the upper and lower levels, as shown in the figure:
The root node provides the main entry point for queries trying to get data through the index. Starting from this node, the query subsystem initiates a hierarchical transition down to a suitable end node containing data.
For example, suppose that a request has been received to select rows containing a key value of 82. The query subsystem starts working from the root node, which refers to a suitable intermediate node, in our case 1-100. From the intermediate node 1-100, a transition occurs to the node 51-100, and from there to the final node 76-100. If it is a clustered index, then the node sheet contains the data of the row associated with the key equal to 82. If it is a non-clustered index, then the index sheet contains a pointer to the clustered table or a specific row in the heap.
How can an index generally improve query performance if you have to navigate through all these index nodes?
First, indexes do not always improve performance. Too many incorrectly created indexes turn the system into a swamp and slow down query performance. It is more correct to say that if indexes were carefully applied, then they can provide a significant increase in productivity.
Think of the huge SQL Server performance tuning book (paper, not electronic). Imagine that you want to find information about configuring a Resource Governor. You can slide your finger page by page through the entire book or open the content and find out the exact page number with the information you are looking for (provided that the book is correctly indexed and the contents are correct). Of course, this will save you considerable time, despite the fact that you first need to turn to a completely different structure (index) to get the information you need from the primary structure (book).
Like a book pointer, a pointer in SQL ServerAllows you to perform precise queries on the data you need, instead of completely scanning all the data in the table. For small tables, a full scan is usually not a problem, but large tables occupy many pages of data, which can result in a significant query time if there is no index that allows the query subsystem to immediately obtain the correct data location. Imagine that you got lost at a multi-level road junction in front of a large metropolis without a map and you understand the idea.
If the indexes are so wonderful, then why not just create them on each column?
No good deed should go unpunished. At least that is exactly the case with indices. Of course, indexes show themselves perfectly when you execute queries to select data with the SELECT statement , but as soon as the INSERT , UPDATE, and DELETE statements are frequently called , the landscape changes very quickly.
When you initiate a data query with the SELECT statement , the query subsystem finds the index, moves along its tree structure and finds the data you are looking for . What could be easier? But everything changes if you initiate a change statement such as UPDATE. Yes, for the first part of the operator, the query subsystem can again use the index to detect a modifiable string - this is good news. And if there is a simple change in the data in a row that does not affect the change in the key columns, then the change process will be completely painless. But what if the change leads to the separation of the pages containing the data, or the value of the key column changes, leading to its transfer to another index node - this will lead to the fact that the index may need a reorganization that affects all related indexes and operations, as a result there will be widespread drop in productivity.
Similar processes occur when a DELETE statement is called.. An index can help find the location of the data being deleted, but deleting the data itself can cause the pages to rearrange. Regarding the INSERT operator , the main enemy of all indexes: you start adding a lot of data, which leads to a change in the indexes and their reorganization and everyone suffers.
So consider the types of queries to your database when considering what type of indexes and in what quantity it is worth creating. More doesn't mean better. Before adding a new index to the table, calculate the cost of not only basic queries, but also the amount of occupied disk space, the cost of maintaining health and indexes, which can lead to a domino effect for other operations. Your index design strategy is one of the most important implementation aspects and should include many considerations: from the size of the index, the number of unique values, to the type of queries supported by the index.
Is it mandatory to create a clustered index on a column with a primary key?
You can create a clustered index on any column that meets the necessary conditions. It’s true that the clustered index and the primary key constraint are created for each other and their marriage is made in heaven, so learn the fact that when you create the primary key, the clustered index will be automatically created if it was not created earlier. However, you can decide that a clustered index will work better elsewhere, and often your decision will be justified.
The main goal of a clustered index is to sort all rows to your table based on the key column specified when defining the index. This provides quick search and easy access to table data.
A table primary key can be a good choice because it uniquely identifies each row in the table without the need to add additional data. In some cases, a surrogate primary key will be the best choice, having not only a sign of uniqueness, but also a small size, and whose values increase sequentially, which makes non-clustered indexes based on this value more efficient. The query optimizer also likes this combination of a clustered index and a primary key, because joining tables is faster than joining in a different way that does not use the primary key and the clustered index associated with it. As I said, this is a marriage made in heaven.
In the end, however, it is worth noting that when creating a clustered index, several aspects need to be taken into account: how many non-clustered indexes will be based on it, how often the value of the key column of the index will change, and no matter how large. When the value in the columns of the clustered index changes or the index does not provide proper performance, then all other indexes on the table can be affected. The clustered index should be based on the most stable column, the values of which increase in a certain order, but do not change in a random way. The index must support queries to the most frequently used table data, so queries get all the benefits of the data being sorted and available on the root nodes, index leaves. If the primary key matches this scenario, then use it. If not, select a different set of columns.
But what if you index the view, will it still be the view?
A view is a virtual table that forms data from one or more tables. Essentially, this is a named query that retrieves data from the underlying tables when you invoke a query on that view. You can improve query performance by creating a clustered index and non-clustered indexes on this view, similar to how you create indexes on a table, but the main caveat is that a clustered index is created initially, and then you can create a non-clustered index.
When an indexed view (materialized view) is created, then the definition of the view itself remains a separate entity. This, after all, is just a hard-coded SELECT statementstored in the database. But the index is a completely different story. When you create a clustered or non-clustered index at a predalation, the data is physically saved to disk, similar to a regular index. In addition, when the data in the underlying tables changes, the view index automatically changes (this means that you might want to avoid indexing the views of those tables in which frequent changes occur). In any case, the view remains the view - a look at the tables, but it was done at the moment, with the indices corresponding to it.
Before you can create an index on a view, it must meet several restrictions. For example, a view can only refer to base tables, but not other views, and these tables must be in the same database. There are actually many other limitations, so be sure to check the SQL Server documentation for all the dirty details.
Why use a covering index instead of a composite index?
First, let's make sure that we understand the difference between the two. A composite index is simply a regular index that includes more than one column. Several key columns can be used to ensure the uniqueness of each row in the table; it is also possible that the primary key consists of several columns ensuring its uniqueness, or you are trying to optimize the execution of frequently called queries on several columns. In general, however, the more key columns an index contains, the less efficient this index works, which means composite indexes should be used wisely.
As was said, a query can be of great benefit if all the necessary data is immediately located on the leaves of the index, like the index itself. This is not a problem for a clustered index, as all the data is already there (which is why it is so important to think carefully when you create a clustered index). But a non-clustered leaf index contains only key columns. For access to all other data, the query optimizer needs additional steps, which can cause significant additional overhead for the execution of your queries.
This is where the covering index rushes to the rescue. When you define a non-clustered index, you can specify additional columns to your key columns. For example, suppose your application often requests data from OrderID andOrderDate in the Sales table :
SELECT OrderID, OrderDate
FROM Sales
WHERE OrderID = 12345;You can create a composite non-clustered index on both columns, but the OrderDate column will only add overhead for maintaining the index, but it will not be able to serve as a particularly useful key column. A better solution would be to create a covering index with the OrderID key column and the OrderDate column optionally included :
CREATE NONCLUSTERED INDEX ix_orderid
ON dbo.Sales(OrderID)
INCLUDE (OrderDate);At the same time, you avoid the disadvantages that arise when indexing redundant columns, while at the same time preserving the advantages of storing data on leaves when executing queries. The included column is not part of the key, but the data is stored on the final node, the index sheet. This can improve query execution performance at no additional cost. In addition, the columns included in the covering index are subject to fewer restrictions than the key columns of the index.
Does the number of duplicates in the key column matter?
When you create an index, you must try to reduce the number of duplicates in your key columns. Or more precisely: try to keep the repetition rate as low as possible.
If you are working with a composite index, then duplication applies to all key columns in general. A single column may contain many duplicate values, but the repetition among all columns in the index should be minimal. For example, you create a composite non-clustered index on the FirstName and LastName columns , you can have many values equal to John and many Doe, but you want to have as few John Doe values as possible, or only one John Doe value is better.
The uniqueness factor of key column values is called index selectivity. The more unique values, the higher the selectivity: a unique index has the highest possible selectivity. The query subsystem is very fond of columns with a high selectivity value, especially if these columns are involved in the WHERE clause of your most frequently executed queries. The higher the selectivity of the index, the faster the query subsystem can reduce the size of the resulting data set. The flip side, of course, is that columns with relatively few unique values will rarely be good candidates for indexing.
Is it possible to create a non-clustered index only for a specific subset of key column data?
By default, a non-clustered index contains one row for each row in the table. Of course, you can say the same thing about a clustered index, taking into account that such an index is the table. But for the non-clustered index, the one-to-one relationship is an important concept because, starting with SQL Server 2008, you have the option of creating a filtered index that limits the rows included in it. A filtered index can improve query performance because it is smaller in size and contains filtered, more accurate statistics than the whole table - this leads to the creation of improved execution plans. The filtered index also requires less storage space and lower maintenance costs. The index is updated only when the data suitable for the filter changes.
In addition, a filtered index is easy to create. In the CREATE INDEX statement, you just need to specify a filter condition in WHERE . For example, you can filter out all rows containing NULL from the index, as shown in the code:
CREATE NONCLUSTERED INDEX ix_trackingnumber
ON Sales.SalesOrderDetail(CarrierTrackingNumber)
WHERE CarrierTrackingNumber IS NOT NULL;We can, in fact, filter out any data that is not important in critical queries. But be careful, as SQL Server imposes several restrictions on filtered indexes, such as the inability to create a filtered index on a view, so read the documentation carefully.
It may also happen that you can achieve similar results by creating an indexed view. However, a filtered index has several advantages, such as the ability to reduce maintenance costs and improve the quality of your execution plans. Filterable indexes also allow online rebuilding. Try this with an indexed view.
And again a little from the translator
Целью появления данного перевода на страницах Хабрахабра было рассказать или напомнить вам о блоге SimpleTalk от RedGate.
В нём публикуется множество занимательных и интересных записей.
Я не связан ни с продуктами фирмы RedGate, ни с их продажей.
Как и обещал, книги для тех кто хочет знать больше
Порекомендую от себя три очень хорошие книги (ссылки ведут на kindle версии в магазине Amazon):
Yes, in fact there are a lot of good and high-quality books.
Basically, you can open just a list of the most desirable SQL Server and buy any.
Many of them are not translated into Russian. And probably never will be!
The topic of a free book search has not been disclosed and is left to your personal discretion (upd: the same, now a little disclosed).
В нём публикуется множество занимательных и интересных записей.
Я не связан ни с продуктами фирмы RedGate, ни с их продажей.
Как и обещал, книги для тех кто хочет знать больше
Порекомендую от себя три очень хорошие книги (ссылки ведут на kindle версии в магазине Amazon):
 | Microsoft SQL Server 2012 T-SQL Fundamentals (Developer Reference) Author Itzik Ben-Gan Publication Date: July 15, 2012 Автор, мастер своего дела, даёт базовые знания о работе с базами данных. Если вы всё забыли или никогда не знали, то определенно стоит её прочитать |
 | SQL Server Execution Plans Author Grant Fritchey Publication Date: May 21, 2013 Автор буквально на пальцах объясняет как работают запросы к базе данных. GraDeaнапомнил, что бесплатно можно скачать pdf на сайте RedGate |
 | SQL Server Query Performance Tuning Author Grant Fritchey Publication Date: September 3, 2014 The same author, in a more global and comprehensive book, explains how to improve database and query performance. |
Yes, in fact there are a lot of good and high-quality books.
Basically, you can open just a list of the most desirable SQL Server and buy any.
Many of them are not translated into Russian. And probably never will be!
The topic of a free book search has not been disclosed and is left to your personal discretion (upd: the same, now a little disclosed).