How we put together a 12-story technology stack and weren’t crazy
Appodeal is a company of about 100 people who work in Moscow, San Francisco, Barnaul, Lutsk, Kirov, Barcelona, and since June 2018, also in Minsk.
We are engaged in the monetization of mobile applications through advertising to users. We started with advertising mediation, but the technology stack is constantly growing, so other products from the Ad Tech industry were added to the mediation.

For those who are not yet familiar with Ad Tech - this is the area of work of technology companies that work in the field of advertising. When you tell someone that you are working in the field of mobile advertising, people often react skeptically - apparently, annoying ads “Azino Three Axes” come to mind. In fact, this is only the tip of the iceberg, and all this “wild” advertising has nothing to do with this advertising business. And the mobile segment, which we are engaged in, has long outgrown the segment of advertising on the web:

Of course, many resources are spent on creating applications — and the creators / owners want the time and effort spent to pay off. Owners of mobile applications that spread their application in the App store / Google Play are called publishers or publishers. Publishers use different monetization models, from in-app purchases to monetizing through advertising. But of all these methods, only the latter allows the user not to pay for the use of the application - and this gives the greatest audience reach.
Yes, if there are too many advertisements, it will annoy everyone and negatively affect the user’s retention. Which, of course, no one needs. Therefore, advertising is always trying to integrate wisely in order to earn maximum money on its application and at the same time not to take a penny from users.
As soon as the publisher decides to monetize with the help of advertising, he comes to the company that can make this task as easy as possible for him. How does this happen with Appodeal? After registering on the site, we integrate its application with our service. This is done through the client SDK, which connects the application with the server part and communicates with the server part via the API.
If we reduce the details to a minimum, the goal of interaction is reduced to two stages:
a. Determine what kind of advertising you need to show right now;
b. Send information about which ad was shown and which was not, and display it in the statistics.
Currently, Appodeal serves several thousand active applications that provide approximately 400-450 million ad impressions per day, received in response to about 1 billion queries to advertising networks (which are advertising providers). For all this to work, our servers serve a total of about 125 thousand requests per second, i.e. approximately 10.8 billion requests per day.

We use various technologies to provide speed, reliability and at the same time development and support flexibility. At the moment we are writing code in the following languages:

Appodeal competes in its segment with very large players, so it is necessary to adapt to market changes quickly. Often it feels like a car wheel change at a speed of 100 km / h. Ruby on Rails allowed us to sustain the race and gain a foothold in the market enough to be the leader in its segment. The main advantages of Rails in our opinion:

From the obvious minuses:

We have a lot of data. Highly. These are billions / tens / hundreds of billions of records. Since the data is completely different, we store them in different ways. You should never be limited in architecture to any one solution that is supposedly universal. Practice shows that, firstly, in Highload there are practically no universal solutions. Versatility means average (or significantly lower than average) data on access / read speed / storage size as payment for this very versatility. Secondly, you need to try something new all the time, experiment and search for non-trivial solutions for the tasks set. Total:

Such a set may seem overloaded, but firstly, Appodeal is a large conglomerate of several development teams and several projects within one. And secondly, these are the harsh realities of ad tech - it’s far from us alone that we use a multi-storey stack inside one company.
Since the data streams are large, in order to process them, the data must be added to the queue. As a queue, we use Kafka. This is a great reliable solution, written in Scala, which has never failed us.
The only requirement for the user in this case is that he has time to rake the ever-increasing queue faster than it grows. Simple and obvious rule. Therefore, for these purposes, we mainly use GoLang. However, this does not negate the fact that the RAM on this server should be abundant.
To keep track of all this economy, you have to monitor and delegate literally everything. For this we use:

You need to understand that properly constructed monitoring is your eyes and ears. Blind work impossible. You need to see what is happening on your servers at a particular point in time, so the stability and reliability of your product will depend largely on how well you build a system for collecting and displaying metrics.
By the way, speaking of reliability, we keep several staging servers for pre-rolling out and checking releases, which we consistently keep under load, duplicating some of the real traffic there. Every week we synchronize the databases between production and styling. This gives us a kind of “mirror” that allows us to test those things that cannot be tested locally, as well as to identify problems at the level of load testing.
It turns out that way. As Ilon Musk wrote in his book: “The best minds of my generation are engaged in how to get people to click on advertisements,” Jeff Hammerbacher, formerly an Facebook engineer, told me. - The horror ... ". A short list of what Appodeal does:

In this case, the so-called bidders are traded with each other online at the auction for the right to show their ads on the selected device. Very interesting moment worthy of a separate article. Many exchanges, such as Google AdExchange, set a rigid framework for the server's response time (for example, 50ms), which raises the question of performance. In the case of disobedience - a fine of thousands of dollars. This is exactly what makes the kernel written on Scala in conjunction with Druid.
Every hunter wants to know where the pheasant is sitting, and our clients (like us) want to know who was shown the ads, when and why. Therefore, the whole bunch of data that we have, we have to put in a queue (Kafka), gradually process and add to the OLAP database (ClickHouse). Many people think that PostgreSQL can handle this task as well as any other hipster solution, but it’s not. PostgreSQL is good, but the classic solution to building indexes for data access speed stops working when the number of fields for filtering and sorting exceeds 10, and the amount of stored data approaches 1 billion records. You simply do not have enough memory to store all of these indexes, or there are problems with updating these indexes. In any case, to achieve the same performance as a column-oriented solution,
In this article I tried to at least briefly tell what we are doing, how we store and process data. Tell us in the comments which stack you use, ask questions and request new articles - we will be happy to share our experience.
We are engaged in the monetization of mobile applications through advertising to users. We started with advertising mediation, but the technology stack is constantly growing, so other products from the Ad Tech industry were added to the mediation.
For those who are not yet familiar with Ad Tech - this is the area of work of technology companies that work in the field of advertising. When you tell someone that you are working in the field of mobile advertising, people often react skeptically - apparently, annoying ads “Azino Three Axes” come to mind. In fact, this is only the tip of the iceberg, and all this “wild” advertising has nothing to do with this advertising business. And the mobile segment, which we are engaged in, has long outgrown the segment of advertising on the web:
Why do I need to integrate advertising in applications?
Of course, many resources are spent on creating applications — and the creators / owners want the time and effort spent to pay off. Owners of mobile applications that spread their application in the App store / Google Play are called publishers or publishers. Publishers use different monetization models, from in-app purchases to monetizing through advertising. But of all these methods, only the latter allows the user not to pay for the use of the application - and this gives the greatest audience reach.
Yes, if there are too many advertisements, it will annoy everyone and negatively affect the user’s retention. Which, of course, no one needs. Therefore, advertising is always trying to integrate wisely in order to earn maximum money on its application and at the same time not to take a penny from users.
How it works?
As soon as the publisher decides to monetize with the help of advertising, he comes to the company that can make this task as easy as possible for him. How does this happen with Appodeal? After registering on the site, we integrate its application with our service. This is done through the client SDK, which connects the application with the server part and communicates with the server part via the API.
If we reduce the details to a minimum, the goal of interaction is reduced to two stages:
a. Determine what kind of advertising you need to show right now;
b. Send information about which ad was shown and which was not, and display it in the statistics.
Currently, Appodeal serves several thousand active applications that provide approximately 400-450 million ad impressions per day, received in response to about 1 billion queries to advertising networks (which are advertising providers). For all this to work, our servers serve a total of about 125 thousand requests per second, i.e. approximately 10.8 billion requests per day.
What is all this built on?
We use various technologies to provide speed, reliability and at the same time development and support flexibility. At the moment we are writing code in the following languages:
- / Ruby / Ruby on Rails + React.JS (front-end) /: Still a big part of the API and the whole web part that users and our employees see
- / GoLang /: Processing large amounts of data according to statistics and not only
- / Scala /: Realtime processing of requests for working with traffic trading exchanges via RTB protocol (read more about it at the end of the article)
- / Elixir / Phoenix /: Rather, the experimental part. Construction of some micro-services for processing part of the statistics and API.
Why initially Ruby and Ruby on Rails?
Appodeal competes in its segment with very large players, so it is necessary to adapt to market changes quickly. Often it feels like a car wheel change at a speed of 100 km / h. Ruby on Rails allowed us to sustain the race and gain a foothold in the market enough to be the leader in its segment. The main advantages of Rails in our opinion:
- A large number of skilled developers
- Great community. A huge number of ready-made solutions and libraries
- The speed of the introduction of new features and change / delete old
From the obvious minuses:
- Overall performance leaves much to be desired. It also affects the lack of JIT (at the moment), the inability to parallelize the code (if you do not take into account the JRuby). To some extent, this remains tolerable, because the database and cache, as a rule, become the bottleneck. What we see in the picture from NewRelic:
- The rail monolith is not sawn too well on microservices - a high degree of coherence of business logic and data access logic (ActiveRecord) affects.
How is the data stored?
We have a lot of data. Highly. These are billions / tens / hundreds of billions of records. Since the data is completely different, we store them in different ways. You should never be limited in architecture to any one solution that is supposedly universal. Practice shows that, firstly, in Highload there are practically no universal solutions. Versatility means average (or significantly lower than average) data on access / read speed / storage size as payment for this very versatility. Secondly, you need to try something new all the time, experiment and search for non-trivial solutions for the tasks set. Total:
- / PostgreSQL /: We love Postgre. We consider it the best at the moment OLTP storage solution. Data about users, applications, advertising campaigns and so on is stored there. We use Primary-Replica replication. Backups are done only during the Christmas holidays, because this is for wimps (just kidding).
- / VerticaDB /: Column-oriented database. We use to store billions of records in statistics. In short, for some time Vertik was considered the best OLAP solution for analytics storage. The main disadvantage is the huge (individual) license price.
- / ClickHouse /: Also column-oriented database. Gradually move to it with VerticaDB. We consider the best OLAP solution at the moment. Not worth a penny. It works very quickly and reliably. The main disadvantage is that data cannot be deleted and updated (we will tell about this in a separate article if anyone is interested).
Nichosi! How can this not delete and change data ?!
- / Aerospike /: The fastest NoSQL key-value storage in our opinion. There are a number of disadvantages, but in general we are satisfied. For Aerospike, there is even a comparison table on their website for performance with other solutions: [When to use Aerospike NoSQL database vs. Redis] (https://www.aerospike.com/when-to-use-aerospike-vs-redis/)
- / Redis /: About “Radishes”, I think, it makes no sense to tell separately. Paradoxically, its main advantage is ease of use and single streaming, which allows to avoid race conditions, for example, when working with banal counters.
- / Druid /: We use for large data arrays in working with RTB exchanges. In fact, for the most part, it plays on the same field with ClickHouse, but historically it turned out that we have not yet been able to switch to any one instrument.
Such a set may seem overloaded, but firstly, Appodeal is a large conglomerate of several development teams and several projects within one. And secondly, these are the harsh realities of ad tech - it’s far from us alone that we use a multi-storey stack inside one company.
How do you follow this?
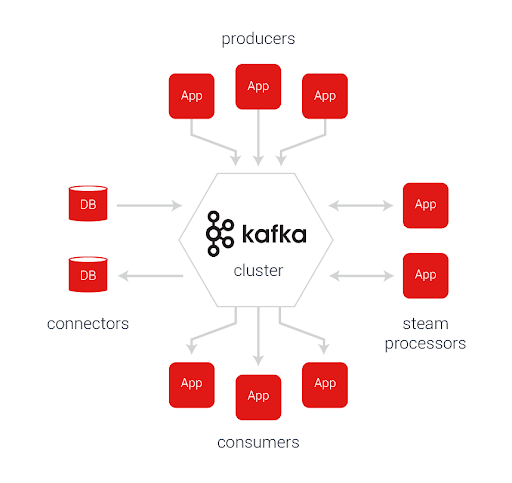
Since the data streams are large, in order to process them, the data must be added to the queue. As a queue, we use Kafka. This is a great reliable solution, written in Scala, which has never failed us.
The only requirement for the user in this case is that he has time to rake the ever-increasing queue faster than it grows. Simple and obvious rule. Therefore, for these purposes, we mainly use GoLang. However, this does not negate the fact that the RAM on this server should be abundant.
To keep track of all this economy, you have to monitor and delegate literally everything. For this we use:
- / NewRelic /: A time-tested solution that integrates perfectly with Ruby on Rails and micro services on GoLang. The only disadvantage of NewRelic is its price. Therefore, NewRelic is not everywhere with us. For the most part, we try to replace it with hand-collected metrics - we add them to Grafana.
- / Statsd + Grafana /: Good stuff for collecting your metrics. With the only drawback that you have to customize everything yourself and “repeat” the NewRelic functionality out of the box.
- / ElasticSearch + Fluentd + Kibana /: In the logs we add everything. From slow PostgreSQL queries to some Rails system messages. Actually, such a solution as Kibana based on ElasticSearch allows you to conveniently collect all the logs in one place and then search for the necessary messages.
- / Airbrake /: The process of collecting errors along with stacktrace messages is mandatory in all of this. At the moment we are moving out of one of the free solutions with Airbrake. For the reason, again, prices.
You need to understand that properly constructed monitoring is your eyes and ears. Blind work impossible. You need to see what is happening on your servers at a particular point in time, so the stability and reliability of your product will depend largely on how well you build a system for collecting and displaying metrics.
By the way, speaking of reliability, we keep several staging servers for pre-rolling out and checking releases, which we consistently keep under load, duplicating some of the real traffic there. Every week we synchronize the databases between production and styling. This gives us a kind of “mirror” that allows us to test those things that cannot be tested locally, as well as to identify problems at the level of load testing.
Is it all so difficult?
It turns out that way. As Ilon Musk wrote in his book: “The best minds of my generation are engaged in how to get people to click on advertisements,” Jeff Hammerbacher, formerly an Facebook engineer, told me. - The horror ... ". A short list of what Appodeal does:
- We are integrated with two dozen ad networks and agencies. In the automatic mode, we register applications in these networks, and also set up various parameters so that these networks work with maximum performance. Not every network has corresponding APIs, somewhere you have to do it with “robots”.
- Each network pays users revenue for impressions, which must be obtained, broken down according to different parameters and processed. This is done in non-stop mode. Somewhere, again, by robots.
- In order to provide the user with maximum revenue, we “force” the grids to compete with each other, building up the so-called “waterfall” of promotional offers. The waterfall is based on various indicators, for example, eCPM (average price per 1000 impressions), which we predict in various ways. The higher the promotional offer in a waterfall, the higher we predict the price for it. A waterfall is offered on the device as often as required. As you might have guessed, an advertisement that nobody pushes, and which will only annoy everyone, is of no interest to anyone. The only exception is the so-called. “Branded” banner ads from Coca-Cola, Pepsi and other corporate giants who used to talk about themselves always and everywhere.
- Some of this interaction is based on the so-called RTB protocol (Real-Time Bidding):
In this case, the so-called bidders are traded with each other online at the auction for the right to show their ads on the selected device. Very interesting moment worthy of a separate article. Many exchanges, such as Google AdExchange, set a rigid framework for the server's response time (for example, 50ms), which raises the question of performance. In the case of disobedience - a fine of thousands of dollars. This is exactly what makes the kernel written on Scala in conjunction with Druid.
Every hunter wants to know where the pheasant is sitting, and our clients (like us) want to know who was shown the ads, when and why. Therefore, the whole bunch of data that we have, we have to put in a queue (Kafka), gradually process and add to the OLAP database (ClickHouse). Many people think that PostgreSQL can handle this task as well as any other hipster solution, but it’s not. PostgreSQL is good, but the classic solution to building indexes for data access speed stops working when the number of fields for filtering and sorting exceeds 10, and the amount of stored data approaches 1 billion records. You simply do not have enough memory to store all of these indexes, or there are problems with updating these indexes. In any case, to achieve the same performance as a column-oriented solution,
Conclusion
In this article I tried to at least briefly tell what we are doing, how we store and process data. Tell us in the comments which stack you use, ask questions and request new articles - we will be happy to share our experience.