NetApp Backup Paradigm
In this post, I would like to consider an approach to backing up data to NetApp FAS series storage systems . Backup architecture

And I'll start from afar - with snapshots. Snapshot technology was first invented (and patented) in 1993 by NetApp, and the word Snapshot ™ is its trademark. Snapshot technology logically flowed from the WAFL file structure . Why WAFL is not a file system, see here. The fact is that WAFL always writes new data “to a new place” and simply moves the pointer to the contents of the new data to a new place, and the old data is not deleted, these data blocks that have no pointers are considered released for new records. Thanks to this recording feature, “always in a new place”, the snapshot mechanism was easily integrated into WAFL, which is why such snapshots are called Redirect on Write (RoW). More on WAFL .
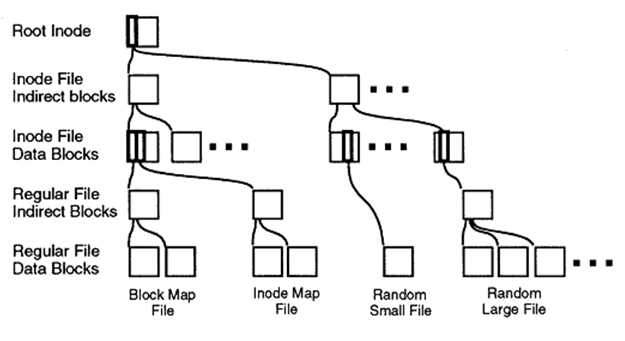
Internal unit WAFL
Due to the fact that snapshots are copies of inodes (links) to data blocks, not the data itself, and the system never writes to the old place, snapshots on NetApp systems do not affect WAFL performance at all .

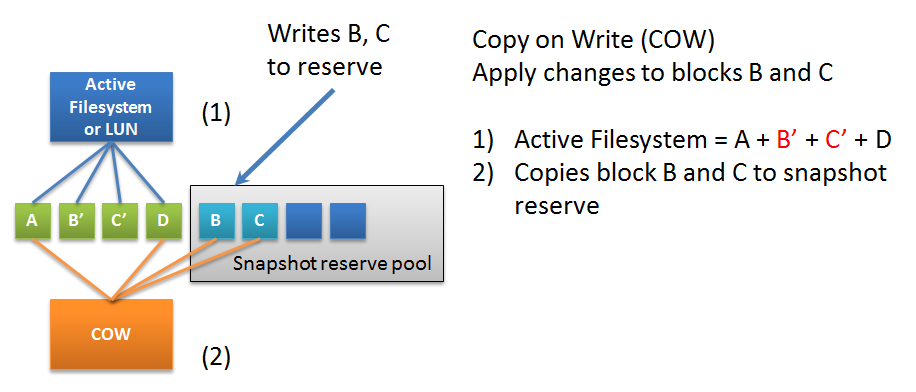
After a while, the functionality of “local snapshots” turned out to be in demand by other equipment manufacturers, so the COW snapshot technology was invented. The difference between this technology lies mainly in the fact that all other file systems and block devices, as a rule, did not have a built-in mechanism for writing “to a new place”, i.e. old data blocks at the time of their rewriting are actually overwritten: the original data is erased, and new data is written in their place. And to prevent damage to the snapshot after such a dubbing, a dedicated area is provided for the safe storage of snapshots. So in case of overwriting data blocks in the file system that are related to snapshots, such a block is first copied to the space reserved for snapshots, and new data is written in their place. The more such snapshots, the more additional parasitic operations, the greater the load on the file system or block device,SHD .
In this connection, the majority of storage and software manufacturers as a rule have recommendations to have no more than 1-5 snapshots. And on highly loaded applications, it is generally recommended not to have snapshots or delete the only one necessary for backup, as soon as it ceases to be needed.
There are two approaches to backing up: pure software and Hardware Assistant. The difference between the two is at what level the snapshot will be executed: at the host level (software) or at the storage level (HW Assistant).
“Software” snapshots are performed “at the host level” and at the time of copying data from the snapshot, the host may experience a load on the disk subsystem, CPU, and network interfaces. Such snapshots are usually tried to be performed during off-peak hours. Software snapshots can also use the COW strategy , which is often implemented at the file system level or some file structure available for management from the host OS . An example of this is ext3cow ,BTRFS , VxFS , LVM , snapshots of VMware , etc.
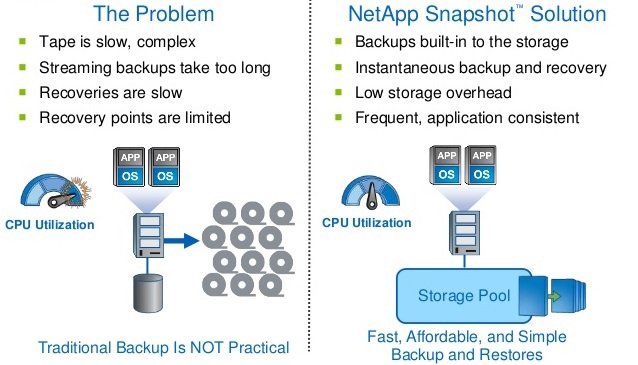
Snapshots in storage systems are often the basic functions for backup. And despite the drawback of COW , in use with Hardware Assistant snapshots at the storage level , you can somehow live with it, loading only the storage system and not the entire host at the time of the backup, and then immediately delete the snapshot so that it does not load the storage .
So here. Everything is relative.
Since NetApp has no performance problems due to snapshots, snapshots became the basis for the backup paradigm for the series of storageFAS . Since FAS systems can store up to 255 snapshots per volume, we can recover much faster if our data is located locally. After all, it is very convenient and quick to recover if the data for recovery is located locally, and recovery is not copying data, but just rewriting the pointers to the “old place”. It is worth noting that with other manufacturers, the theoretically possible number of snapshots can reach thousands , but after reading the documentation for operation, you can make sure that using COW snapshots on highly loaded systems is not recommended .
So what is the difference between NetApp approaches and other manufacturers that also use snapshots as the basis for backup? NetApp seriously uses local snapshots as part of its backup and recovery strategy, as well as for replication, while other manufacturers cannot afford it due to overhead in the form of performance degradation. This introduces significant changes to the backup architecture.
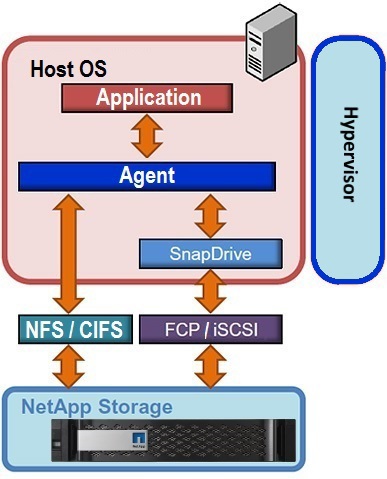
Snapshots taken "on their own" provide Crash Consistent recovery, i.e. Having rolled back to such a once-shot snapshot, the effect will be as if you clicked the Reset button on the server with your application and booted. In order to provide Application Consistent Backup, the interaction of the storage system with the application is necessary so that it properly prepares the data before the snapshot. The interaction between the storage system and the application can be achieved using agents installed on the same host where the application itself lives.
There are a number of backup software that can interact with a wide range of applications (SAP, Oracle DB, ESXi, Hyper-V, MS SQL, Exchange, Sharepoint) that support HW Snapshoots on NetApp FAS systems :
To ensure physical fault tolerance, there are many mechanisms that reduce the likelihood of a local backup failure - RIAD , duplication of components, duplication of paths, etc. Why not use the hardware fault tolerance that is already present? In other words, snapshots are backups that protect against logical data errors, from accidental deletion, damage to information by a virus, etc. Snapshots do not protect against physical failure of the storage system itself .
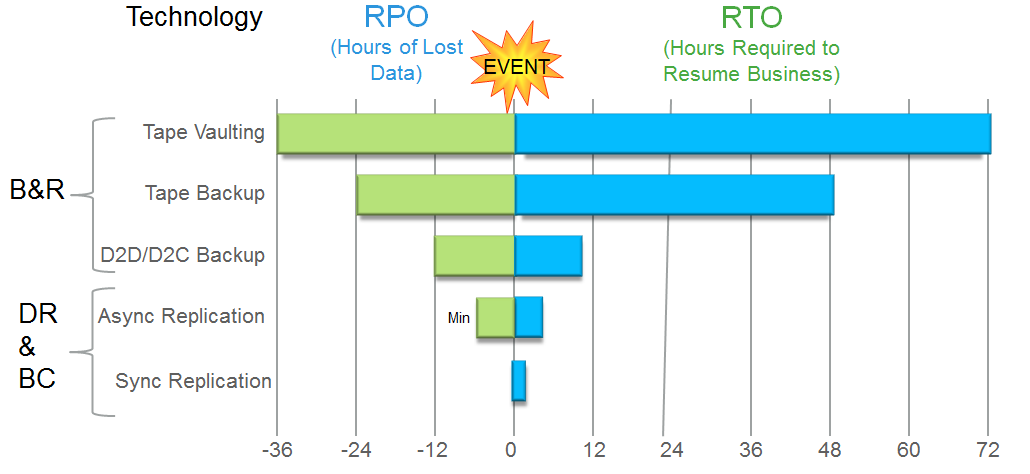
To protect against physical destruction (fire, flood, earthquake, confiscation) the data still needs to be backed up to a spare site. The standard backup approach is that the full amount of data will be transferred to a remote site. A little later they came up with the idea of compressing this data. It should be noted that the mechanism of compression (and extraction) of data requires a significant expenditure of CPU resources . Then transfer only increments, a little later they came up with reverse incremental backups (so as not to waste time collecting increments in a full backup at the time of recovery), and for reliability, periodically transfer the complete data set.
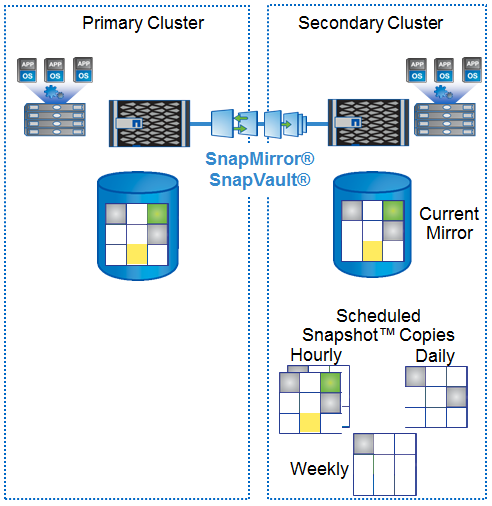
And here, too, snapshots come to the rescue. They can be compared with reverse incremental backups that do not require a long time to create them. So NetApp systems transfer the full set of data for the first time, and then, always, only a snapshot (increment) to the remote system, increasing the speed of backup and recovery. Along the way, it is possible to enable compression of the transmitted data.
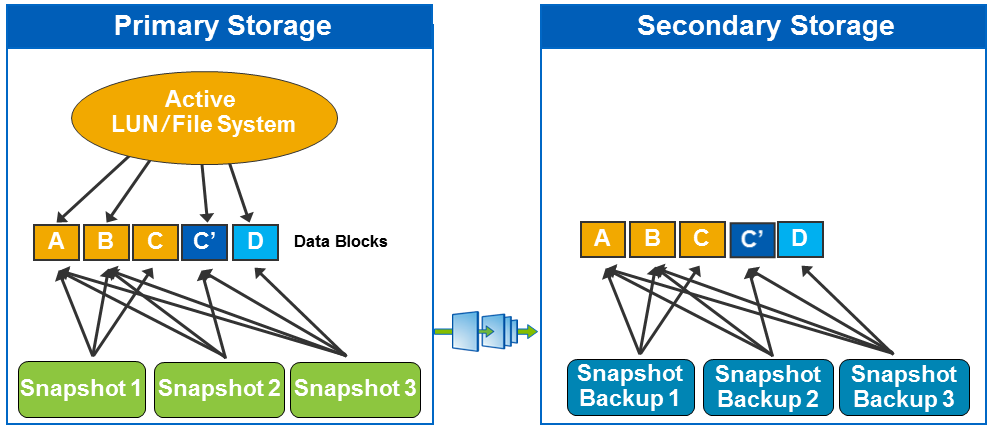
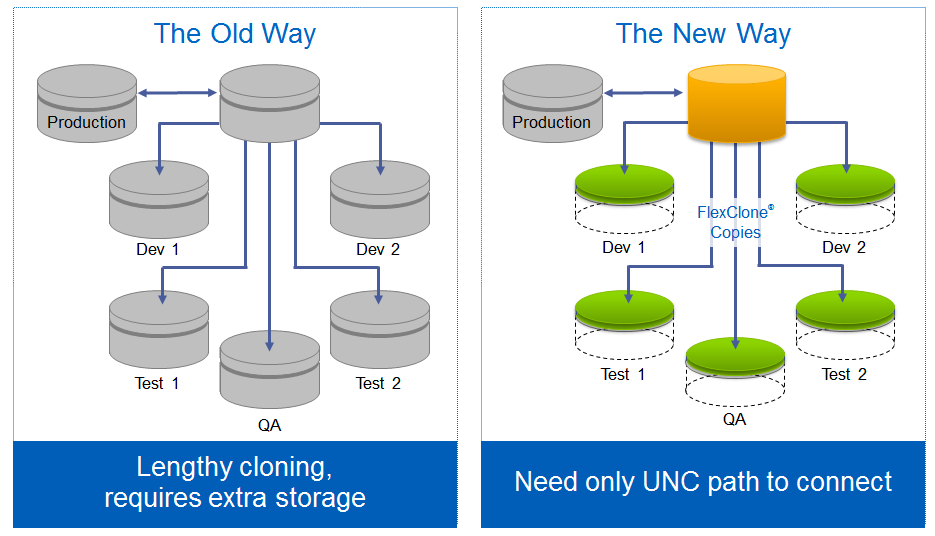
Using the same data for several tasks, such as testing backups using cloning (and others), has begun to gain popularity and is called Copy Data Management (CDM). On a "non-productive" site from a clone, it is also convenient to perform cathodization, backup verification, as well as testing and development based on thin clones of reserved data.
Thus, the backup paradigm in NetApp FAS storage consists of sets of approaches to:
The above allows you to have no performance problems, more quickly and consistently remove (reduce the backup window) and replicate data (and as a result be able to take backups more often) without interruption in service even during working hours. Recovery from a remote site is much faster, using snapshots transmitting only the "difference" between the data, and not a full copy. And local snapshots in the event of logical data corruption can reduce the recovery window to a couple of seconds.
Please send messages about errors in the text to the LAN .
Comments and additions on the contrary please comment
Wafl
And I'll start from afar - with snapshots. Snapshot technology was first invented (and patented) in 1993 by NetApp, and the word Snapshot ™ is its trademark. Snapshot technology logically flowed from the WAFL file structure . Why WAFL is not a file system, see here. The fact is that WAFL always writes new data “to a new place” and simply moves the pointer to the contents of the new data to a new place, and the old data is not deleted, these data blocks that have no pointers are considered released for new records. Thanks to this recording feature, “always in a new place”, the snapshot mechanism was easily integrated into WAFL, which is why such snapshots are called Redirect on Write (RoW). More on WAFL .
Internal unit WAFL
Snapshots
Due to the fact that snapshots are copies of inodes (links) to data blocks, not the data itself, and the system never writes to the old place, snapshots on NetApp systems do not affect WAFL performance at all .
Cow
After a while, the functionality of “local snapshots” turned out to be in demand by other equipment manufacturers, so the COW snapshot technology was invented. The difference between this technology lies mainly in the fact that all other file systems and block devices, as a rule, did not have a built-in mechanism for writing “to a new place”, i.e. old data blocks at the time of their rewriting are actually overwritten: the original data is erased, and new data is written in their place. And to prevent damage to the snapshot after such a dubbing, a dedicated area is provided for the safe storage of snapshots. So in case of overwriting data blocks in the file system that are related to snapshots, such a block is first copied to the space reserved for snapshots, and new data is written in their place. The more such snapshots, the more additional parasitic operations, the greater the load on the file system or block device,SHD .
In this connection, the majority of storage and software manufacturers as a rule have recommendations to have no more than 1-5 snapshots. And on highly loaded applications, it is generally recommended not to have snapshots or delete the only one necessary for backup, as soon as it ceases to be needed.
Backup Approaches
There are two approaches to backing up: pure software and Hardware Assistant. The difference between the two is at what level the snapshot will be executed: at the host level (software) or at the storage level (HW Assistant).
“Software” snapshots are performed “at the host level” and at the time of copying data from the snapshot, the host may experience a load on the disk subsystem, CPU, and network interfaces. Such snapshots are usually tried to be performed during off-peak hours. Software snapshots can also use the COW strategy , which is often implemented at the file system level or some file structure available for management from the host OS . An example of this is ext3cow ,BTRFS , VxFS , LVM , snapshots of VMware , etc.
Snapshots in storage systems are often the basic functions for backup. And despite the drawback of COW , in use with Hardware Assistant snapshots at the storage level , you can somehow live with it, loading only the storage system and not the entire host at the time of the backup, and then immediately delete the snapshot so that it does not load the storage .
So here. Everything is relative.
Since NetApp has no performance problems due to snapshots, snapshots became the basis for the backup paradigm for the series of storageFAS . Since FAS systems can store up to 255 snapshots per volume, we can recover much faster if our data is located locally. After all, it is very convenient and quick to recover if the data for recovery is located locally, and recovery is not copying data, but just rewriting the pointers to the “old place”. It is worth noting that with other manufacturers, the theoretically possible number of snapshots can reach thousands , but after reading the documentation for operation, you can make sure that using COW snapshots on highly loaded systems is not recommended .
Difference in approaches
So what is the difference between NetApp approaches and other manufacturers that also use snapshots as the basis for backup? NetApp seriously uses local snapshots as part of its backup and recovery strategy, as well as for replication, while other manufacturers cannot afford it due to overhead in the form of performance degradation. This introduces significant changes to the backup architecture.
Application & Crash Consistent Backups
Snapshots taken "on their own" provide Crash Consistent recovery, i.e. Having rolled back to such a once-shot snapshot, the effect will be as if you clicked the Reset button on the server with your application and booted. In order to provide Application Consistent Backup, the interaction of the storage system with the application is necessary so that it properly prepares the data before the snapshot. The interaction between the storage system and the application can be achieved using agents installed on the same host where the application itself lives.
There are a number of backup software that can interact with a wide range of applications (SAP, Oracle DB, ESXi, Hyper-V, MS SQL, Exchange, Sharepoint) that support HW Snapshoots on NetApp FAS systems :
- Veeam Backup & Replication
- CommVault Simpana
- NetApp SnapManager / SnapCenter. Read about SnapManager for Oracle for SAN in the corresponding article.
- NetApp SnapProtect .
- NetApp SnapCreator (free framework)
- Symantec NetBackup
- Symantec BackupExec
- Syncsort
- Acronis
Disaster protection
To ensure physical fault tolerance, there are many mechanisms that reduce the likelihood of a local backup failure - RIAD , duplication of components, duplication of paths, etc. Why not use the hardware fault tolerance that is already present? In other words, snapshots are backups that protect against logical data errors, from accidental deletion, damage to information by a virus, etc. Snapshots do not protect against physical failure of the storage system itself .
Thin replication
To protect against physical destruction (fire, flood, earthquake, confiscation) the data still needs to be backed up to a spare site. The standard backup approach is that the full amount of data will be transferred to a remote site. A little later they came up with the idea of compressing this data. It should be noted that the mechanism of compression (and extraction) of data requires a significant expenditure of CPU resources . Then transfer only increments, a little later they came up with reverse incremental backups (so as not to waste time collecting increments in a full backup at the time of recovery), and for reliability, periodically transfer the complete data set.
And here, too, snapshots come to the rescue. They can be compared with reverse incremental backups that do not require a long time to create them. So NetApp systems transfer the full set of data for the first time, and then, always, only a snapshot (increment) to the remote system, increasing the speed of backup and recovery. Along the way, it is possible to enable compression of the transmitted data.
Copy data management
Using the same data for several tasks, such as testing backups using cloning (and others), has begun to gain popularity and is called Copy Data Management (CDM). On a "non-productive" site from a clone, it is also convenient to perform cathodization, backup verification, as well as testing and development based on thin clones of reserved data.
Backup paradigm
Thus, the backup paradigm in NetApp FAS storage consists of sets of approaches to:
- Removing consistent snapshots of long-term stored, both locally on the same storage system and remotely
- Thin replication for archiving / backup and recovery
- Thin Cloning for Testing
The above allows you to have no performance problems, more quickly and consistently remove (reduce the backup window) and replicate data (and as a result be able to take backups more often) without interruption in service even during working hours. Recovery from a remote site is much faster, using snapshots transmitting only the "difference" between the data, and not a full copy. And local snapshots in the event of logical data corruption can reduce the recovery window to a couple of seconds.
Please send messages about errors in the text to the LAN .
Comments and additions on the contrary please comment