Virtual Infrastructure Configuration: VDI Cluster Optimization
Well, how is the optimization. Creative efforts to level the heeling and wobbling infrastructure, which they tried hard to keep with the “do not touch anything, everything can break” method . A dangerous phrase that quickly turns into the life philosophy of an IT specialist who has stopped in development. The source of IT “deception”.
Six months have passed since the person responsible for the virtual infrastructure quit and left me all the household and operational documentation in the form of a list of service records. During this time, a number of works were carried out to strengthen the foundation, increase the reliability and even the comfort of the structure. I want to share the key points.
So, given:
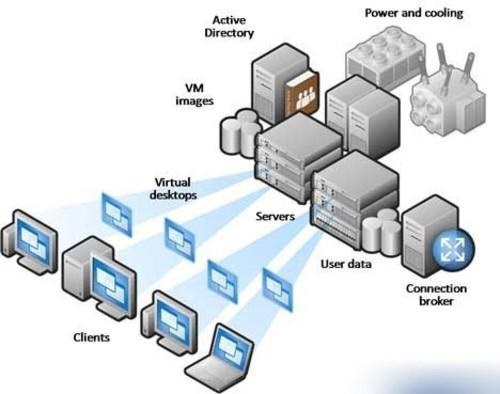
VMware Enterprise Plus Virtualization Infrastructure. Includes Productivity, Test Zone, and VDI. The latter is based on the product fujitsu Pano Logic, which has not been updated for 2 years and, apparently, is not supported.
The main upgradeable cluster is VDI, as the most voluminous critical service and the most dense in terms of resource utilization. It is implemented on the basis of complete clones, because pano manager does not understand the associated clones by himself, and View does not want to buy View.
As a storage system, a set of EMC arrays is used - several CX4-240 and a pair of VNX. And there is also such sophistication as the IBM SVC. It is used for storage consolidation and virtualization (that is, luns are mounted with storage on SVC, pooled there, and new LUNs are already created on these pools that are given to servers). All storages are connected via FC SAN.
Since there was no documentation, I had to learn how to live and work. At the same time, some seemingly harmless changes, sometimes led to unexpectedly unpleasant consequences, revealing strange settings and crutches.
Fast navigation:
1. Storage subsystem
2. Network
3. Computing resources
I started this area even before my colleague left, since SAN was my main area of responsibility.
The first thing that surprised me was the use of a large number of small (1TB) datastores. Why - no one could explain. An attempt to consolidate into larger datastores immediately revealed the problem - too many scsi-locks, as a result of high latency and boot-storms, as a phenomenon. The strange thing was that the storage system behaved as if it did not support VAAI. But the properties of the datastores explicitly state "Hardware Acceleration: Supported."
Understanding came when they introduced a new host into the cluster. A colleague recalled that before the operation “you need to enter a command - to disable some thing that leads to problems when working with SVC”. The "parameter" was the VMFS3.HardwareAcceleratedLocking parameterset to 0. In other words, the most important VAAI function, Atomic Test and Set (ATS), was turned off, which allows not changing the entire datastore, but specific sectors to block when the metadata of the datastore (on / off, migration and stretching of thin VM disks) drives.
However, this setting had some problems with SVC. At least with the version of firmware that we had. An attempt to update firmware led to the death of two (out of three updated) nodes, support for this equipment ended, so we decided to transfer datastores directly to EMC arrays. In general, it remained incomprehensible to me - why it was necessary to pull such a curved layer of storage virtualization over a clearly more advanced layer of EMC storage pools.
Recommendations: In terms of performance, a smaller number of large LUNs is more profitable than a large number of small LUNs - here is an overhead for servicing each LUN and query parallelization and performance degradation of different cache levels. (EMC recommendation to reduce SP load: Reduce the number of LUNs by consolidating LUNs where possible. If a RAID group has multiple LUNs being used for the same host and application, then this can lead to linked contention, large seek distances and poor use of cache. Replacing these with fewer, larger LUNs will also reduce the amount of statistics which need to be monitored, therefore further reducing SP Utilization .)
When using storage virtualization systems, make sure that they are “more intelligent” than the lower level, or at least do not kill the storage functionality. In our case, SVC was clearly “dumber” than EMC arrays, refused to see LUNs over 2 TB and made features such as auto-tearing senseless (and I suspect Flash Cache).
And of course, you should make sure that the storage equipment supports VAAI, and, moreover, that this functionality is not blocked at the level of virtualization infrastructure.
The second point is a strange spread of different categories of data across arrays. The databases, interspersed with file servers and VDI in a chaotic manner, were scattered across all the storages on the principle of "where was the place." Not to mention the fact that some of the datastores were connected directly to EMC arrays, and some through SVC.
After long migrations and redistributions, we were able to distribute the data in the most optimal way - put the most resource-consuming (productive servers and VDI) into VNXs, and give the clarions for backups and less demanding services. In SVC there were only directly forwarded to LUN servers, I removed all datastores from it. The number of zones on the switches decreased from ~ 120 to ~ 75, taking into account the fact that earlier there were zones like “many targets - many initiators”, and now there are no more than one initiator in a zone. Just because the data of a certain type, with which certain servers worked, are now on the same storage system, and not on three different ones.
What is the profit- extra zones created unnecessary load in the SAN network; using a heterogeneous load (IO-intensive, such as a database and sequential recording, such as backups / file servers) on a single array harms performance. Using more than one initiator in one zone is bad practice.
# esxcli storage nmp device list on hosts showed that
a) For the most part, the Round Robin policy is used to select the paths to the datastores,
b) For some datastores (the first six) on the first two hosts, the path change takes place through 3 IOPS
Path Selection Policy Policy Device Config : {policy = iops, iops = 3,
on the rest - the default value
Path Selection Policy Device Config: {policy = rr, iops = 1000,
c) On the last five hosts of the cluster, for some of the datastores, Fixed was used (all communication with storage is via one way, as long as it is available).
The choice of Path Selection Policy is determined by the model and vendor of storage. In most cases, round robin is used for the active-active configuration, due to some, but load balancing. By default, the change of path occurs after 1000 iops. However, in some cases this can lead to delays. There is kb from VMware , where it is recommended to change this value to 1. There are tests showing that the performance of the storage subsystem in this case is really higher.
Recommendations : configure multipathing according to vendor recommendations for your configurations. And make sure that they are the same on all hosts. Well, Host Profiles in VMware help with this.
In order to configure load balancing, all VDI cluster blade basket switches were stacked, EtherChannel was organized, and load balancing in the Teaming and Failover section was configured as Route Based on IP Hash. The fact is that IP Hash works only on top of EtherChannel and only IP Hash is compatible with EtherChannel. However, when the cluster grew to a second blade basket whose switches did not support EtherChannel, a problem arose. The problem manifested itself in the form of hard MAC flapping on the switches of the second basket (according to networkers) and the rejection of received packets on the first (from 10 to 100 per second, according to the monitoring system).
An important recommendation - do not change the network settings in bulk for the entire cluster. After checking on one host and making sure everything is in order, we disabled EtherChannel on everyone else. And they lost access to all but the first. Fifteen agonizing minutes, while departing from the shock and returning the configuration back, no one but the lucky ones located on the first server could work. Subsequently, the settings for one host were changed, first displaying it in Maintenance Mode. At the same time, I counted the total idle man-hours, multiplying 15 by 1300 (the number of VDIs) and dividing by 60. Thanks to the management for understanding ... But this was not the first shock associated with virtual desktops.
By the way, I don’t know why, but until I recreated dvSwitch, the host generated an error with every reboot: LACP Error: <something about the fact that the current configuration supports IP Hash only>. Although EtherChannel has been disabled. The new dvSwitch did not show such an error. Transferring hosts and virtual machines to the new distributed switch burned a pack of nerve cells, but nothing happened.
Along the way, I reconfigured the use of uplinks. Before starting work, all portgroups were configured the same way:

I did this:

As a way to organize balancing, use Route based on physical NIC load (the next interface in the list is selected if the current one is more than 70% loaded).
conclusions- Setting up network balancing and fault tolerance - a creative process. But subsequent monitoring showed that with this configuration a) packet loss of the first blade basket disappeared, b) load balancing by uplinks became more even, c) rarely, but there were previously cases that the host suddenly became unavailable. Over the past few months, this has never happened. d) Mass vMotion (server output in Maintenance Mode, for example) does not affect VM traffic.
The advantages of using IP Hash, compared with LB, I do not see.
It immediately seemed to me that 1.5 GB of RAM for virtual desktops on Windows 7 is a mockery of users. And most likely a negative impact on the disk subsystem due to swapping inside the OS. But there was no excess memory. The risk of failover and swap loss at the virtual machine level was a more negative factor. The idea came from the news about disabling the Transparent Pages Sharing tool from the default settings in future versions of vSphere. More precisely, from the discussion about her on Facebook .
Summary: The
feature is disabled because there is a hypothetical security risk ( can be abused to gain unauthorized access to data * under certain highly controlled conditions * ).
In most implementations, the technology is really almost useless since the advent of ASLR and support for large pages of memory. Since it is less likely to find two identical pages with a size of 2 MB than 4 KB. And for server-side virtualization, a 2 MB page is much more critical in terms of performance than saving memory.
However, why not test it on a VDI cluster?
I made the following changes to the Advanced Settings of the host:
Mem.AllocGuestLargePage = 0 instead of 1 - turning off large pages of memory
Mem.ShareScanGhz = 6 instead of 4 - increasing the scanning frequency
Mem.ShareScanTime = 30 instead of 60 - increasing the scanning speed
To compensate for the increased processor load, I turned off vNuma chips as useless in the case of VMs with less than 8 vCPUs. These settings (along with the Path Selecting Policy settings) I distributed to all hosts using Host Profiles. The result can be seen in the screenshot below.

Explanation of the parameters:
If two VMs share 100 MB of memory, then the Shared parameter will be 200 MB, and Shared Common - 100 MB.
As can be seen from the monitoring results for the month, Shared Common grew four times, and Shared - six. The total memory savings amounted to almost 700 GB, that is, 600 GB more compared to the state on October 26. This is almost a quarter of all cluster resources. True, the average processor load increased from 50-60% to 70-90%.
On November 5, there is a slight decline, as Mem.ShareScanTime and Mem.ShareScanGhz had to be returned to default values in order to reduce processor load. Now it keeps at 60-80%. Nevertheless, the savings still remained significant and there was an opportunity for all machines that had 1.5 GB of memory to increase its volume to 2.
The impact of these changes in terms of the responsiveness of the disk subsystem can be estimated from the picture below. Read Latency is shown for several datastores. Unfortunately, experiments with the SCCM service windows occurred during the same period, which gave night peaks with fantastic values of up to 80 seconds and made the average values absolutely non-indicative. For this reason, I did not give the chart itself - night peaks killed all the visibility of the daily load. But you can evaluate the change by the minimum values of the response time (first columns).

At first, it was generally unusual to see the average Latency readings in the “green” zone - 10-20 ms. It was usual that almost never dropped below 30.
Conclusion: Not all publicized technologies are as useful as they are talked about. But not all features on which they put an end to, and which competitors, in this case VMware, bury at their performances are so pointless. However, one must know them and understand when to use. And for this you need to study the settings, parameters and properties of the product, including undocumented ones. And then the management of IT infrastructure will not be shamanism. And it will be a competent and creative use of knowledge, which is the basis of professionalism.
Thanks for attention.
Six months have passed since the person responsible for the virtual infrastructure quit and left me all the household and operational documentation in the form of a list of service records. During this time, a number of works were carried out to strengthen the foundation, increase the reliability and even the comfort of the structure. I want to share the key points.
So, given:
VMware Enterprise Plus Virtualization Infrastructure. Includes Productivity, Test Zone, and VDI. The latter is based on the product fujitsu Pano Logic, which has not been updated for 2 years and, apparently, is not supported.
The main upgradeable cluster is VDI, as the most voluminous critical service and the most dense in terms of resource utilization. It is implemented on the basis of complete clones, because pano manager does not understand the associated clones by himself, and View does not want to buy View.
As a storage system, a set of EMC arrays is used - several CX4-240 and a pair of VNX. And there is also such sophistication as the IBM SVC. It is used for storage consolidation and virtualization (that is, luns are mounted with storage on SVC, pooled there, and new LUNs are already created on these pools that are given to servers). All storages are connected via FC SAN.
Since there was no documentation, I had to learn how to live and work. At the same time, some seemingly harmless changes, sometimes led to unexpectedly unpleasant consequences, revealing strange settings and crutches.
Fast navigation:
1. Storage subsystem
2. Network
3. Computing resources
1. Storage Subsystem
I started this area even before my colleague left, since SAN was my main area of responsibility.
1.1 VAAI
The first thing that surprised me was the use of a large number of small (1TB) datastores. Why - no one could explain. An attempt to consolidate into larger datastores immediately revealed the problem - too many scsi-locks, as a result of high latency and boot-storms, as a phenomenon. The strange thing was that the storage system behaved as if it did not support VAAI. But the properties of the datastores explicitly state "Hardware Acceleration: Supported."
Understanding came when they introduced a new host into the cluster. A colleague recalled that before the operation “you need to enter a command - to disable some thing that leads to problems when working with SVC”. The "parameter" was the VMFS3.HardwareAcceleratedLocking parameterset to 0. In other words, the most important VAAI function, Atomic Test and Set (ATS), was turned off, which allows not changing the entire datastore, but specific sectors to block when the metadata of the datastore (on / off, migration and stretching of thin VM disks) drives.
However, this setting had some problems with SVC. At least with the version of firmware that we had. An attempt to update firmware led to the death of two (out of three updated) nodes, support for this equipment ended, so we decided to transfer datastores directly to EMC arrays. In general, it remained incomprehensible to me - why it was necessary to pull such a curved layer of storage virtualization over a clearly more advanced layer of EMC storage pools.
Recommendations: In terms of performance, a smaller number of large LUNs is more profitable than a large number of small LUNs - here is an overhead for servicing each LUN and query parallelization and performance degradation of different cache levels. (EMC recommendation to reduce SP load: Reduce the number of LUNs by consolidating LUNs where possible. If a RAID group has multiple LUNs being used for the same host and application, then this can lead to linked contention, large seek distances and poor use of cache. Replacing these with fewer, larger LUNs will also reduce the amount of statistics which need to be monitored, therefore further reducing SP Utilization .)
When using storage virtualization systems, make sure that they are “more intelligent” than the lower level, or at least do not kill the storage functionality. In our case, SVC was clearly “dumber” than EMC arrays, refused to see LUNs over 2 TB and made features such as auto-tearing senseless (and I suspect Flash Cache).
And of course, you should make sure that the storage equipment supports VAAI, and, moreover, that this functionality is not blocked at the level of virtualization infrastructure.
1.2 Zoning and Array Distribution
The second point is a strange spread of different categories of data across arrays. The databases, interspersed with file servers and VDI in a chaotic manner, were scattered across all the storages on the principle of "where was the place." Not to mention the fact that some of the datastores were connected directly to EMC arrays, and some through SVC.
After long migrations and redistributions, we were able to distribute the data in the most optimal way - put the most resource-consuming (productive servers and VDI) into VNXs, and give the clarions for backups and less demanding services. In SVC there were only directly forwarded to LUN servers, I removed all datastores from it. The number of zones on the switches decreased from ~ 120 to ~ 75, taking into account the fact that earlier there were zones like “many targets - many initiators”, and now there are no more than one initiator in a zone. Just because the data of a certain type, with which certain servers worked, are now on the same storage system, and not on three different ones.
What is the profit- extra zones created unnecessary load in the SAN network; using a heterogeneous load (IO-intensive, such as a database and sequential recording, such as backups / file servers) on a single array harms performance. Using more than one initiator in one zone is bad practice.
1.3 Path Selection Settings
# esxcli storage nmp device list on hosts showed that
a) For the most part, the Round Robin policy is used to select the paths to the datastores,
b) For some datastores (the first six) on the first two hosts, the path change takes place through 3 IOPS
Path Selection Policy Policy Device Config : {policy = iops, iops = 3,
on the rest - the default value
Path Selection Policy Device Config: {policy = rr, iops = 1000,
c) On the last five hosts of the cluster, for some of the datastores, Fixed was used (all communication with storage is via one way, as long as it is available).
The choice of Path Selection Policy is determined by the model and vendor of storage. In most cases, round robin is used for the active-active configuration, due to some, but load balancing. By default, the change of path occurs after 1000 iops. However, in some cases this can lead to delays. There is kb from VMware , where it is recommended to change this value to 1. There are tests showing that the performance of the storage subsystem in this case is really higher.
Recommendations : configure multipathing according to vendor recommendations for your configurations. And make sure that they are the same on all hosts. Well, Host Profiles in VMware help with this.
2. Network
In order to configure load balancing, all VDI cluster blade basket switches were stacked, EtherChannel was organized, and load balancing in the Teaming and Failover section was configured as Route Based on IP Hash. The fact is that IP Hash works only on top of EtherChannel and only IP Hash is compatible with EtherChannel. However, when the cluster grew to a second blade basket whose switches did not support EtherChannel, a problem arose. The problem manifested itself in the form of hard MAC flapping on the switches of the second basket (according to networkers) and the rejection of received packets on the first (from 10 to 100 per second, according to the monitoring system).
An important recommendation - do not change the network settings in bulk for the entire cluster. After checking on one host and making sure everything is in order, we disabled EtherChannel on everyone else. And they lost access to all but the first. Fifteen agonizing minutes, while departing from the shock and returning the configuration back, no one but the lucky ones located on the first server could work. Subsequently, the settings for one host were changed, first displaying it in Maintenance Mode. At the same time, I counted the total idle man-hours, multiplying 15 by 1300 (the number of VDIs) and dividing by 60. Thanks to the management for understanding ... But this was not the first shock associated with virtual desktops.
By the way, I don’t know why, but until I recreated dvSwitch, the host generated an error with every reboot: LACP Error: <something about the fact that the current configuration supports IP Hash only>. Although EtherChannel has been disabled. The new dvSwitch did not show such an error. Transferring hosts and virtual machines to the new distributed switch burned a pack of nerve cells, but nothing happened.
Along the way, I reconfigured the use of uplinks. Before starting work, all portgroups were configured the same way:
I did this:
As a way to organize balancing, use Route based on physical NIC load (the next interface in the list is selected if the current one is more than 70% loaded).
conclusions- Setting up network balancing and fault tolerance - a creative process. But subsequent monitoring showed that with this configuration a) packet loss of the first blade basket disappeared, b) load balancing by uplinks became more even, c) rarely, but there were previously cases that the host suddenly became unavailable. Over the past few months, this has never happened. d) Mass vMotion (server output in Maintenance Mode, for example) does not affect VM traffic.
The advantages of using IP Hash, compared with LB, I do not see.
3. Computing resources
It immediately seemed to me that 1.5 GB of RAM for virtual desktops on Windows 7 is a mockery of users. And most likely a negative impact on the disk subsystem due to swapping inside the OS. But there was no excess memory. The risk of failover and swap loss at the virtual machine level was a more negative factor. The idea came from the news about disabling the Transparent Pages Sharing tool from the default settings in future versions of vSphere. More precisely, from the discussion about her on Facebook .
Summary: The
feature is disabled because there is a hypothetical security risk ( can be abused to gain unauthorized access to data * under certain highly controlled conditions * ).
In most implementations, the technology is really almost useless since the advent of ASLR and support for large pages of memory. Since it is less likely to find two identical pages with a size of 2 MB than 4 KB. And for server-side virtualization, a 2 MB page is much more critical in terms of performance than saving memory.
However, why not test it on a VDI cluster?
I made the following changes to the Advanced Settings of the host:
Mem.AllocGuestLargePage = 0 instead of 1 - turning off large pages of memory
Mem.ShareScanGhz = 6 instead of 4 - increasing the scanning frequency
Mem.ShareScanTime = 30 instead of 60 - increasing the scanning speed
To compensate for the increased processor load, I turned off vNuma chips as useless in the case of VMs with less than 8 vCPUs. These settings (along with the Path Selecting Policy settings) I distributed to all hosts using Host Profiles. The result can be seen in the screenshot below.
Explanation of the parameters:
If two VMs share 100 MB of memory, then the Shared parameter will be 200 MB, and Shared Common - 100 MB.
As can be seen from the monitoring results for the month, Shared Common grew four times, and Shared - six. The total memory savings amounted to almost 700 GB, that is, 600 GB more compared to the state on October 26. This is almost a quarter of all cluster resources. True, the average processor load increased from 50-60% to 70-90%.
On November 5, there is a slight decline, as Mem.ShareScanTime and Mem.ShareScanGhz had to be returned to default values in order to reduce processor load. Now it keeps at 60-80%. Nevertheless, the savings still remained significant and there was an opportunity for all machines that had 1.5 GB of memory to increase its volume to 2.
The impact of these changes in terms of the responsiveness of the disk subsystem can be estimated from the picture below. Read Latency is shown for several datastores. Unfortunately, experiments with the SCCM service windows occurred during the same period, which gave night peaks with fantastic values of up to 80 seconds and made the average values absolutely non-indicative. For this reason, I did not give the chart itself - night peaks killed all the visibility of the daily load. But you can evaluate the change by the minimum values of the response time (first columns).
At first, it was generally unusual to see the average Latency readings in the “green” zone - 10-20 ms. It was usual that almost never dropped below 30.
Conclusion: Not all publicized technologies are as useful as they are talked about. But not all features on which they put an end to, and which competitors, in this case VMware, bury at their performances are so pointless. However, one must know them and understand when to use. And for this you need to study the settings, parameters and properties of the product, including undocumented ones. And then the management of IT infrastructure will not be shamanism. And it will be a competent and creative use of knowledge, which is the basis of professionalism.
Thanks for attention.