Analysis of VK friendships using Python. Continuation
In the previous article, we built a graph based on common friends of VKontakte, and today we’ll talk about how to get a list of friends, friends of friends and so on. It is assumed that you have already read the previous article , and I will not describe it all over again. Under the habrakat there are large pictures and a lot of text.
To begin with, simply downloading all user IDs is quite easy, a list of valid id can be found in the VKontakte User Directory . Our task is to get a list of friends of the user id chosen by us, their friends and recursively arbitrarily deep, depending on the specified depth.
The code published in the article will change over time, so a more recent version can be found in the same project on Github .
How we will implement:
What we will use:
What we need in the beginning - is to specify the depth ( deep ), with which we want to work. You can do this right away in settings.py :
deep equal to 1 are our friends, 2 are friends of our friends and so on. As a result, we get a dictionary whose keys are user id, and the values are their list of friends.
Do not rush to set large depths. With 14 of my original friends and a depth of 2, the number of keys in the dictionary was 2427, and with a depth of 3, I did not have the patience to wait for the script to finish working, at that time the dictionary counted 223,908 keys. For this reason, we will not visualize such a huge graph, because the vertices will be the keys, and the edges will be the values.
To achieve the result we need, the already known friends.get method will help , which will be located in the stored procedure, which has the following form:
I remind you that a stored procedure can be created in the application settings , it is written in VkScript , like execute , the documentation can be read here and here .
Now about how it works. We accept a string of 25 id separated by commas, take out one id, make a request to friends.get , and the information we need will come in the dictionary, where the keys are id and the values are the friends list of this id.
At the first start, we will send the stored procedure a list of friends of the current user, whose id is specified in the settings. The list will be divided into several parts (N / 25 is the number of requests), this is due to the limited number of calls to the VKontakte API.
All the information we receive is stored in a dictionary, for example:
Keys 1, 2, and 3 were obtained at a depth of 1. Assume that these were all friends of the specified user (0).
If the depth is greater than 1, then we will use the difference of the sets, the first of which is the values of the dictionary, and the second is its keys. Thus, we will get those id (in this case 0 and 4) that are not in the keys, we will split them again into 25 parts and send them to the stored procedure.
Then 2 new keys will appear in our dictionary:
The deep_friends () method itself looks like this:
Of course, this is faster than throwing one id at friends.get one without using a stored procedure, but it still takes a lot of time.
If friends.get was similar to users.get , namely, it could take user_ids as a parameter , i.e. id separated by commas, for which you need to return a list of friends, and not just one id, then the code would be much simpler, and the number of requests was many times less.
Returning to the beginning of the article, I can repeat again - very slowly. Stored procedures do not save, the alxpy multithreading solution (thanks to him for his contribution and participation,at least someone was interested, except me ) accelerated the program for several seconds, but wanted more.
I received wise advice from igrishaev - I need some kind of map-reducer.
The fact is that VKontakte allows 25 API requests via execute , it follows that if you make requests from different clients, then we can increase the number of valid requests. 5 wheelbarrows - this is 125 requests per second. But this is far from the case. Looking ahead, I’ll say that it’s possible and even faster, it will look something like this (on each machine):
If we receive an error message, then we make the request again, after the specified number of seconds. This technique works for a while, but then VKontakte starts sending None in all responses , so after each request we will honestly wait 1 second. For now.
Next, we need to choose new tools or write our own in order to implement our plan. As a result, we should get a horizontally scalable system, the principle of work is seen to me as follows:
And if you saw this picture, then you understand which message broker I am hinting at.
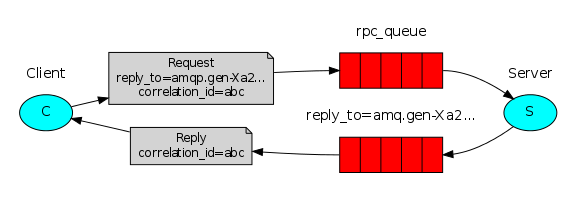
Once all the answers are accepted, we combine them into one. Further, the result can be displayed on the screen or completely saved, more on that later.
It is worth noting that the code will change, and if you just had to use the previous version of the project, then it remained unchanged. All of the code below is for the new release.
We will use RabbitMQ as a message broker, Celery , an asynchronous distributed task queue .
For those who have never encountered them, here are some useful links to materials that I advise you to read:
Do not be afraid to understand, although they say that you can specifically turn your head when you start to "think not with one computer, but with several", but this is not at all so.
If you have a Mac, like the author, then RabbitMQ is smartly installed through Homebrew :
Celery is even easier, using the third Python branch :
I have Celery installed on Linux Mint, and RabbitMQ on Mac. With Windows, as usual, the problems arehard to find, easy to lose; for some reason, for some reason, it did not want to return a response to my Mac.
Next, create a virtual host , the user and give him rights:
In the RabbitMQ configuration, you must specify the ip of the host on which it is installed:
Here are a few possible configurations, which one to choose - you decide.
If you have a router or something else, it will be useful to know that RabbitMQ uses 5672 port, well, and redirect in the settings of your device. Most likely, if you test, then you will scatter workers on different machines, and they will need to use a broker, and if you do not configure the network correctly, Celery will not reach RabbitMQ .
The very good news is that VKontakte allows you to make 3 requests per second from one id. We multiply these requests by the number of possible calls to the VK API (25), we get the maximum number of contacts processed per second (75).

If we have a lot of workers, then the time will come when we begin to move beyond the permissible limit. Therefore, the token variable (in settings.py ) will now be a tuple containing several tokens with different id. The script will, at each request to the VKontakte API, select one of them in a random way:
In this regard, you should not have any difficulties, if you have several accounts on VKontakte (you can strain friends and family), I had no problems with 4 tokens and 3 workers.
No, no one bothers you with using time.sleep () , or the example above with while, but then get ready to receive error messages (generally empty answers are possible - id: None), or wait longer.
The most interesting from the call.py file :
As you can see, in 2 functions we use groups () , which simultaneously runs several tasks, after which we “glue” the answer. Remember how deep_friends () looked at the beginning (there’s a very old example - even without multithreading)? The meaning remains the same - we use the difference of sets.
And finally, tasks.py . Someday these wonderful features will be combined into one:
When everything is configured, run RabbitMQ with the command:
Then go to the project folder and activate the worker:
Now, to get and save a list of general or “deep” friends, just command in the console:
Let me remind you that the author of the article that inspired me in the first part , 343 friends (request for mutual friends) were “processed” in 119 seconds .
My version from the previous article did the same in 9 seconds .
Now that author has a different number of friends - 308. Well, you have to make one extra request for the last eight id, spend a precious second on it, although 75 id can be processed in the same second.
With one worker, the script took 4.2 seconds , with two workers - 2.2 seconds .
If 119 is rounded to 120, and 2.2 to 2, then my option works 60 times faster.
As for the “deep friends” (friends of my friends and so on + testing on a different id to wait less) - with a depth of 2, the number of keys in the dictionary was 1,251.
The execution time of the code at the very beginning of the article is 17.9 seconds .
With one worker, the execution time of the script is 15.1 seconds , with two workers - 8.2 seconds .
Thus, deep_friends () became faster by about 2.18 times .
Yes, the result is not always so rosy, sometimes an answer to one request in VKontakte has to wait for 10 and 20 seconds (although the frequent execution time of one task is 1.2 - 1.6 seconds), most likely, this is due to the load on the service, because we are not alone in the universe.

As a result, the more workers to do, the faster the result will be processed. Do not forget about the power of your hardware, additional tokens, the network (for example, the author increased the execution time of the script when he used his iPhone as an access point) and other factors.
Yes, there are many graph-oriented databases. If in the future (and it will be so), we want to analyze the results, then all the same they will need to be stored somewhere until the analysis itself, then these results will be unloaded into memory and some actions should be performed with them. I don’t see the point of using any kind of subd if the project would be commercial and we were interested, for example, what happens to the graph of a particular user over time - then yes, a graph-oriented database is required here, but since we will be engaged in analysis in “home conditions” ", Pickle is enough for us.
Before saving dictionaries, it will be logical to delete keys from them whose values are None. These are blocked or deleted accounts. Simply put, these id will be present in the graph, because someone has a friend, but we will save on the number of keys in the dictionary:
As you can see, if we saved the result somewhere, then somewhere we must load it so as not to collect the id again.
In order not to write your bike, we will use the fairly well-known networkx , which will do all thedirty work for us . You can learn more about networkx from this article .
Before we begin to analyze the graph, draw it. networkx this would require matplotlib :
Next, we need to create the graph itself. In general, there are 2 ways.
The first will gobble up a lot of RAM and your time:
And this is not the author who survived from the mind, no. Such an example is given on the page at Rice University ( Rice University then ), under the heading of the Convert a Dictionary Graph Representation Into NetworkX Graph Representation :
You can take my word for it, the graph was being built all evening, when it already had more than 300,000 peaks, my patience snapped.If you have taken a course on Coursera in Python from this university, then you understand what I mean. And I said to everyone on the course that people are not taught that way, but oh well.
Yes, an example is given for a directed graph, but the essence remains the same - first add the keys, making them vertices, then make the vertices values, and then if they are not already in the graph, and then connect them with edges (in my version).
And the second method will do everything in seconds:
The code lies in the graph.py file . To draw a graph of mutual friends, just run this script or create an instance of the VkGraph () class somewhere , and then call its draw_graph () method .
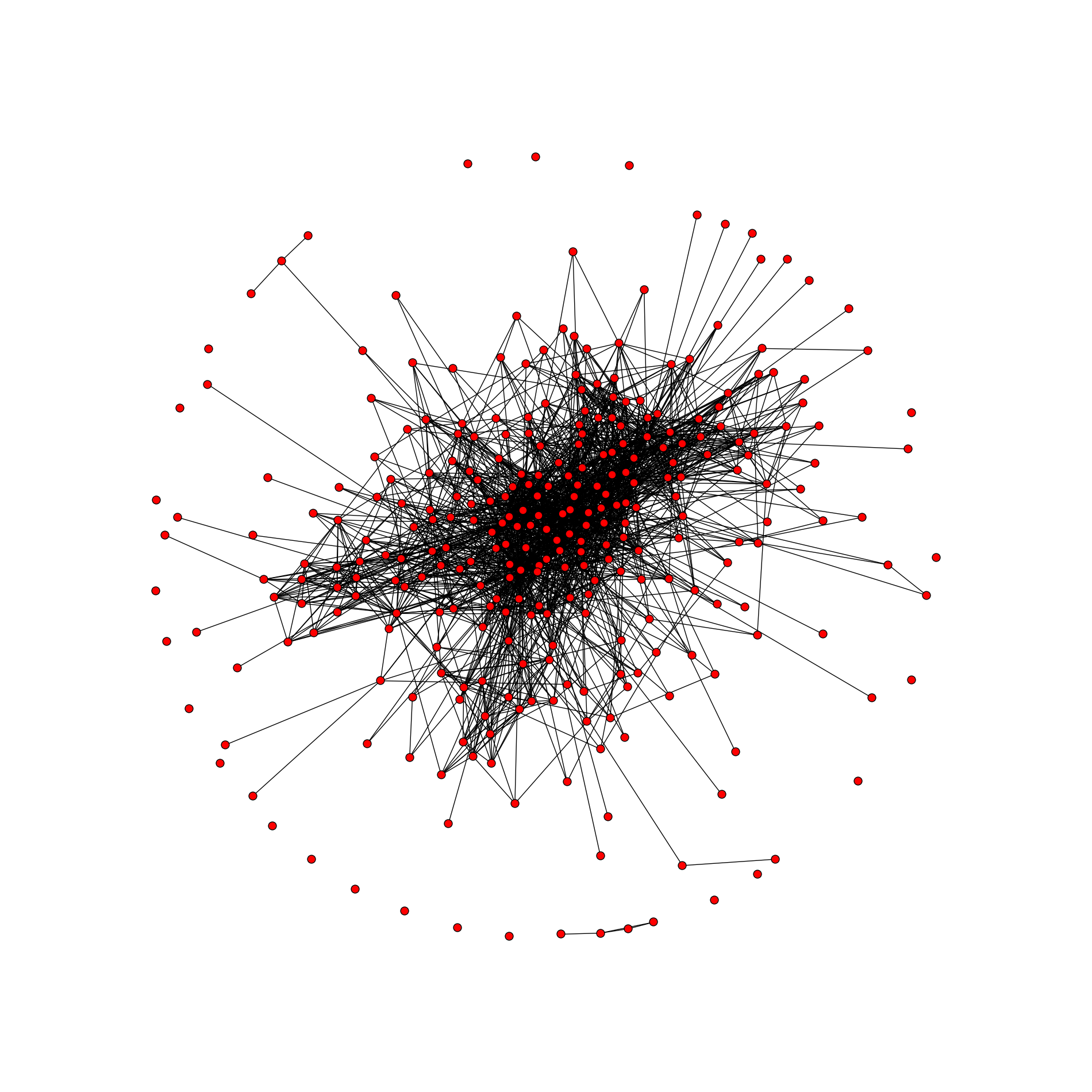
This is a graph of mutual friends, with a total of 306 peaks and 2096 ribs. Unfortunately, I’m never a designer (almost all the settings are standard), but you can always stylize the graph "for yourself". Here are a couple of links:
And the method itself looks like this:
As a result, you get a picture date graph.png in the project folder. I do not advise drawing a graph for deep friends. With 308 friends and a depth of 2, there were more than 145,000 keys in the dictionary . But there are also values - tuples with id, which are unlikely to be small.
For a long time I was looking for the most low-profile friends profile on VKontakte, although here it is more important - friends-friends. 10 initial friends (1 of them blocked and will automatically be deleted), with our standard depth (2), in the dictionary there were 1234 keys and 517 174 id (from values). About 419 friends have one id. Yes, there are general friends there, when we build the graph, we will understand this:
Will return:
With such big data, it would be nice to play around. In networkx a very large list of algorithms that can be applied to graphs. We will analyze some of them.
First, let's determine if we have a connected graph:
A connected graph is a graph in which any pair of vertices is connected by a route.
By the way, the same id with a depth of 1 has such a beautiful graph containing 1268 vertices and 1329 edges:
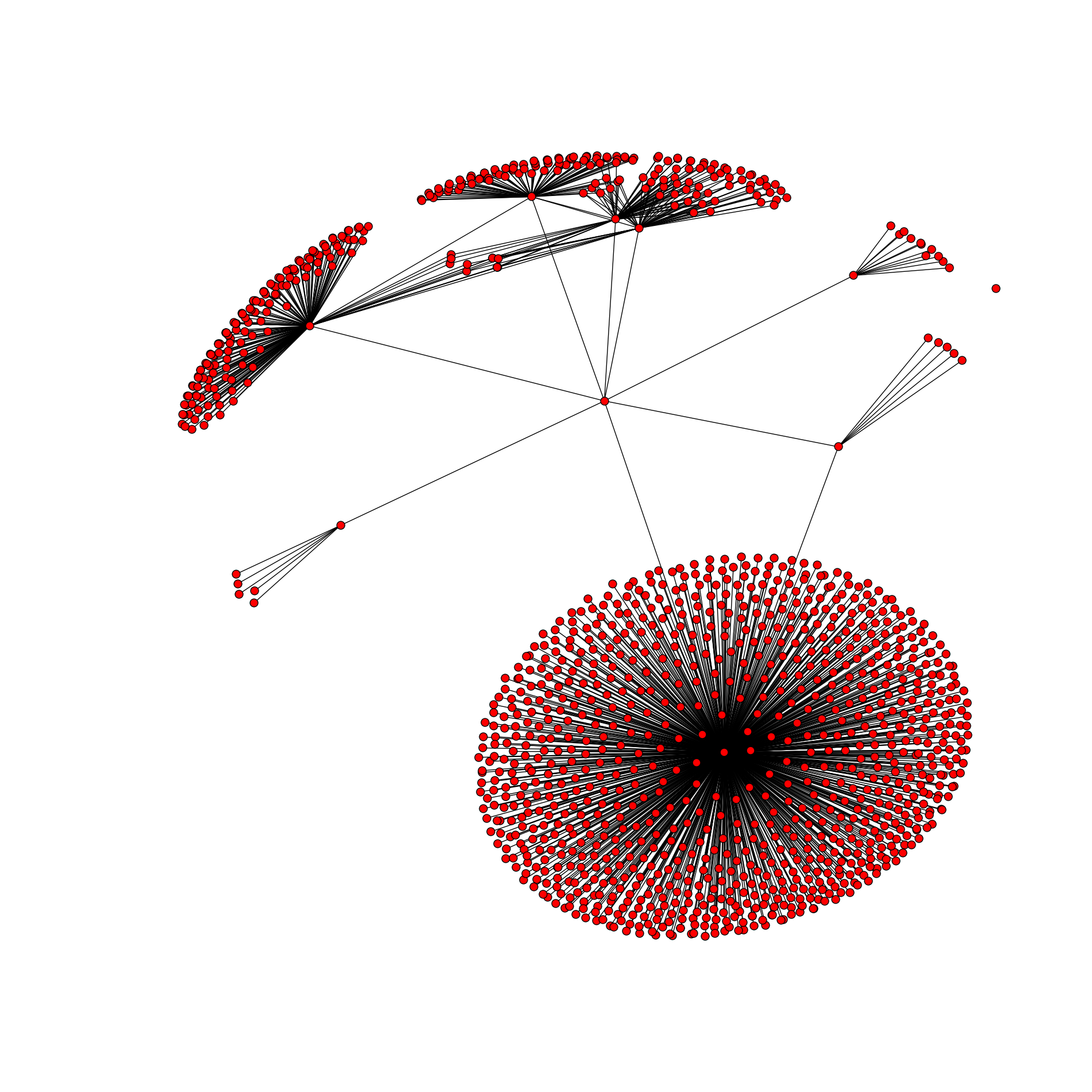
Question for connoisseurs. Since we get a graph of friends-friends, it should be connected in any way. It cannot be such that a peak appears out of nowhere that is not connected with any of the existing ones. However, we see one vertex on the right that is not connected to any one. Why? I urge you to think first, it will be more interesting to learn the truth.
We assume that you will not have such a situation, that is, most likely you will see True .
Recall that the diameter of a graph is the maximum distance between its two vertices.
The center of the graph is any vertex such that the distance from it to the most distant vertex is minimal. The center of a graph can be one vertex or several vertices. Or easier. The center of the graph is a vertex whose eccentricity (the distance from this vertex to the most distant from it) is equal to the radius.
Will return a list of vertices that are the center of the graph. Do not be surprised if the center is the id specified in settings.py .
The radius of the graph is the smallest of the eccentricities of all the vertices.
This is the very Page Rank that you thought about. Typically, the algorithm is used for web pages or other documents linked by links. The more links to a page, the more important it is. But no one forbids using this algorithm for graphs. We will borrow a more accurate and suitable definition from this article :
Quoting Wikipedia:
As you can see, there is nothing complicated, and networkx offers many more algorithms (the author counted 148) that can be applied to graphs. You just have to select the algorithm you need and call the appropriate method in the graph.py file .
We made a distributed system that allows you to collect and build a graph of mutual friends on VKontakte, which works 60 times faster (depending on the number of workers) than the proposed version from Himura , also implemented a new function - request all “deep friends”, added the ability to analyze constructed graphs.
If you do not want to install additional software and you need to build a beautiful graph of mutual friends from the previous article , then the old release is at your service. In it you will also find the old version of getting the user's friends list recursively arbitrarily deeply.
This is not the limit, work will continue to increase the speed of the program.
Still waiting for you to pull pull requests, especially if you are involved in data visualization. Thanks for attention!
To begin with, simply downloading all user IDs is quite easy, a list of valid id can be found in the VKontakte User Directory . Our task is to get a list of friends of the user id chosen by us, their friends and recursively arbitrarily deep, depending on the specified depth.
The code published in the article will change over time, so a more recent version can be found in the same project on Github .
How we will implement:
- Set the depth we need
- We send the source data or those id that need to be explored at a given depth
- We get the answer
What we will use:
- Python 3.4
- Stored procedures on VK
Set the depth we need
What we need in the beginning - is to specify the depth ( deep ), with which we want to work. You can do this right away in settings.py :
deep = 2 # такая строчка там уже есть
deep equal to 1 are our friends, 2 are friends of our friends and so on. As a result, we get a dictionary whose keys are user id, and the values are their list of friends.
Do not rush to set large depths. With 14 of my original friends and a depth of 2, the number of keys in the dictionary was 2427, and with a depth of 3, I did not have the patience to wait for the script to finish working, at that time the dictionary counted 223,908 keys. For this reason, we will not visualize such a huge graph, because the vertices will be the keys, and the edges will be the values.
Sending data
To achieve the result we need, the already known friends.get method will help , which will be located in the stored procedure, which has the following form:
var targets = Args.targets;
var all_friends = {};
var req;
var parametr = "";
var start = 0;
// из строки с целями вынимаем каждую цель
while(start<=targets.length){
if (targets.substr(start, 1) != "," && start != targets.length){
parametr = parametr + targets.substr(start, 1);
}
else {
// сразу делаем запросы, как только вытащили id
req = API.friends.get({"user_id":parametr});
if (req) {
all_friends = all_friends + [req];
}
else {
all_friends = all_friends + [0];
}
parametr = "";
}
start = start + 1;
}
return all_friends;
I remind you that a stored procedure can be created in the application settings , it is written in VkScript , like execute , the documentation can be read here and here .
Now about how it works. We accept a string of 25 id separated by commas, take out one id, make a request to friends.get , and the information we need will come in the dictionary, where the keys are id and the values are the friends list of this id.
At the first start, we will send the stored procedure a list of friends of the current user, whose id is specified in the settings. The list will be divided into several parts (N / 25 is the number of requests), this is due to the limited number of calls to the VKontakte API.
Receive response
All the information we receive is stored in a dictionary, for example:
{1:(0, 2, 3, 4), 2: (0, 1, 3, 4), 3: (0, 1, 2)}
Keys 1, 2, and 3 were obtained at a depth of 1. Assume that these were all friends of the specified user (0).
If the depth is greater than 1, then we will use the difference of the sets, the first of which is the values of the dictionary, and the second is its keys. Thus, we will get those id (in this case 0 and 4) that are not in the keys, we will split them again into 25 parts and send them to the stored procedure.
Then 2 new keys will appear in our dictionary:
{1:(0, 2, 3, 4), 2: (0, 1, 3, 4), 3: (0, 1, 2), 0: (1, 2, 3), 4:(1, 2, ….)}
The deep_friends () method itself looks like this:
def deep_friends(self, deep):
result = {}
def fill_result(friends):
for i in VkFriends.parts(friends):
r = requests.get(self.request_url('execute.deepFriends', 'targets=%s' % VkFriends.make_targets(i))).json()['response']
for x, id in enumerate(i):
result[id] = tuple(r[x]["items"]) if r[x] else None
for i in range(deep):
if result:
# те айди, которых нет в ключах + не берем id:None
fill_result(list(set([item for sublist in result.values() if sublist for item in sublist]) - set(result.keys())))
else:
fill_result(requests.get(self.request_url('friends.get', 'user_id=%s' % self.my_id)).json()['response']["items"])
return result
Of course, this is faster than throwing one id at friends.get one without using a stored procedure, but it still takes a lot of time.
If friends.get was similar to users.get , namely, it could take user_ids as a parameter , i.e. id separated by commas, for which you need to return a list of friends, and not just one id, then the code would be much simpler, and the number of requests was many times less.
Too slow
Returning to the beginning of the article, I can repeat again - very slowly. Stored procedures do not save, the alxpy multithreading solution (thanks to him for his contribution and participation,
I received wise advice from igrishaev - I need some kind of map-reducer.
The fact is that VKontakte allows 25 API requests via execute , it follows that if you make requests from different clients, then we can increase the number of valid requests. 5 wheelbarrows - this is 125 requests per second. But this is far from the case. Looking ahead, I’ll say that it’s possible and even faster, it will look something like this (on each machine):
while True:
r = requests.get(request_url('execute.getMutual','source=%s&targets=%s' % (my_id, make_targets(lst)),access_token=True)).json()
if 'response' in r:
r = r["response"]
break
else:
time.sleep(delay)
If we receive an error message, then we make the request again, after the specified number of seconds. This technique works for a while, but then VKontakte starts sending None in all responses , so after each request we will honestly wait 1 second. For now.
Next, we need to choose new tools or write our own in order to implement our plan. As a result, we should get a horizontally scalable system, the principle of work is seen to me as follows:
- The main server receives its VKontakte id and operation code from the client: either pull out all common friends, or walk recursively through the list of friends with the specified depth.
- Further, in both cases, the server makes a request to the VKontakte API - we need a list of all the user's friends.
- Since everything has been done so that we take maximum advantage of the capabilities of stored procedures, here it will be necessary to divide the list of friends into parts, 25 contacts each. In fact, 75. About this a little lower.
- We will get many parts, using a message broker we will deliver each part to a specific recipient (producer-consumer).
- Recipients will accept contacts, immediately make requests, return the result to the supplier. Yes, you thought about RPC correctly.
And if you saw this picture, then you understand which message broker I am hinting at.

Once all the answers are accepted, we combine them into one. Further, the result can be displayed on the screen or completely saved, more on that later.
It is worth noting that the code will change, and if you just had to use the previous version of the project, then it remained unchanged. All of the code below is for the new release.
We will use RabbitMQ as a message broker, Celery , an asynchronous distributed task queue .
For those who have never encountered them, here are some useful links to materials that I advise you to read:
Celery
Do not be afraid to understand, although they say that you can specifically turn your head when you start to "think not with one computer, but with several", but this is not at all so.
If you have a Mac, like the author, then RabbitMQ is smartly installed through Homebrew :
brew update
brew install rabbitmq
Celery is even easier, using the third Python branch :
pip3 install Celery
I have Celery installed on Linux Mint, and RabbitMQ on Mac. With Windows, as usual, the problems are
Next, create a virtual host , the user and give him rights:
rabbitmqctl add_vhost vk_friends
rabbitmqctl add_user user password
rabbitmqctl set_permissions -p vk_friends user ".*" ".*" ".*"
In the RabbitMQ configuration, you must specify the ip of the host on which it is installed:
vim /usr/local/etc/rabbitmq/rabbitmq-env.conf
NODE_IP_ADDRESS=192.168.1.14 // конкретно мой вариант
Here are a few possible configurations, which one to choose - you decide.

If you have a router or something else, it will be useful to know that RabbitMQ uses 5672 port, well, and redirect in the settings of your device. Most likely, if you test, then you will scatter workers on different machines, and they will need to use a broker, and if you do not configure the network correctly, Celery will not reach RabbitMQ .
The very good news is that VKontakte allows you to make 3 requests per second from one id. We multiply these requests by the number of possible calls to the VK API (25), we get the maximum number of contacts processed per second (75).

If we have a lot of workers, then the time will come when we begin to move beyond the permissible limit. Therefore, the token variable (in settings.py ) will now be a tuple containing several tokens with different id. The script will, at each request to the VKontakte API, select one of them in a random way:
def request_url(method_name, parameters, access_token=False):
"""read https://vk.com/dev/api_requests"""
req_url = 'https://api.vk.com/method/{method_name}?{parameters}&v={api_v}'.format(
method_name=method_name, api_v=api_v, parameters=parameters)
if access_token:
req_url = '{}&access_token={token}'.format(req_url, token=random.choice(token))
return req_url
In this regard, you should not have any difficulties, if you have several accounts on VKontakte (you can strain friends and family), I had no problems with 4 tokens and 3 workers.
No, no one bothers you with using time.sleep () , or the example above with while, but then get ready to receive error messages (generally empty answers are possible - id: None), or wait longer.
The most interesting from the call.py file :
def getMutual():
all_friends = friends(my_id)
c_friends = group(mutual_friends.s(i) for i in parts(list(all_friends[0].keys()), 75))().get()
result = {k: v for d in c_friends for k, v in d.items()}
return cleaner(result)
def getDeep():
result = {}
for i in range(deep):
if result:
# те айди, которых нет в ключах + не берем id:None
lst = list(set([item for sublist in result.values() if sublist for item in sublist]) - set(result.keys()))
d_friends = group(deep_friends.s(i) for i in parts(list(lst), 75))().get()
result = {k: v for d in d_friends for k, v in d.items()}
result.update(result)
else:
all_friends = friends(my_id)
d_friends = group(deep_friends.s(i) for i in parts(list(all_friends[0].keys()), 75) )().get()
result = {k: v for d in d_friends for k, v in d.items()}
result.update(result)
return cleaner(result)
As you can see, in 2 functions we use groups () , which simultaneously runs several tasks, after which we “glue” the answer. Remember how deep_friends () looked at the beginning (there’s a very old example - even without multithreading)? The meaning remains the same - we use the difference of sets.
And finally, tasks.py . Someday these wonderful features will be combined into one:
@app.task
def mutual_friends(lst):
"""
read https://vk.com/dev/friends.getMutual and read https://vk.com/dev/execute
"""
result = {}
for i in list(parts(lst, 25)):
r = requests.get(request_url('execute.getMutual', 'source=%s&targets=%s' % (my_id, make_targets(i)), access_token=True)).json()['response']
for x, vk_id in enumerate(i):
result[vk_id] = tuple(i for i in r[x]) if r[x] else None
return result
@app.task
def deep_friends(friends):
result = {}
for i in list(parts(friends, 25)):
r = requests.get(request_url('execute.deepFriends', 'targets=%s' % make_targets(i), access_token=True)).json()["response"]
for x, vk_id in enumerate(i):
result[vk_id] = tuple(r[x]["items"]) if r[x] else None
return result
When everything is configured, run RabbitMQ with the command:
rabbitmq-server
Then go to the project folder and activate the worker:
celery -A tasks worker --loglevel=info
Now, to get and save a list of general or “deep” friends, just command in the console:
python3 call.py
About measurement results
Let me remind you that the author of the article that inspired me in the first part , 343 friends (request for mutual friends) were “processed” in 119 seconds .
My version from the previous article did the same in 9 seconds .
Now that author has a different number of friends - 308. Well, you have to make one extra request for the last eight id, spend a precious second on it, although 75 id can be processed in the same second.
With one worker, the script took 4.2 seconds , with two workers - 2.2 seconds .
If 119 is rounded to 120, and 2.2 to 2, then my option works 60 times faster.
As for the “deep friends” (friends of my friends and so on + testing on a different id to wait less) - with a depth of 2, the number of keys in the dictionary was 1,251.
The execution time of the code at the very beginning of the article is 17.9 seconds .
With one worker, the execution time of the script is 15.1 seconds , with two workers - 8.2 seconds .
Thus, deep_friends () became faster by about 2.18 times .
Yes, the result is not always so rosy, sometimes an answer to one request in VKontakte has to wait for 10 and 20 seconds (although the frequent execution time of one task is 1.2 - 1.6 seconds), most likely, this is due to the load on the service, because we are not alone in the universe.

As a result, the more workers to do, the faster the result will be processed. Do not forget about the power of your hardware, additional tokens, the network (for example, the author increased the execution time of the script when he used his iPhone as an access point) and other factors.
Saving the result
Yes, there are many graph-oriented databases. If in the future (and it will be so), we want to analyze the results, then all the same they will need to be stored somewhere until the analysis itself, then these results will be unloaded into memory and some actions should be performed with them. I don’t see the point of using any kind of subd if the project would be commercial and we were interested, for example, what happens to the graph of a particular user over time - then yes, a graph-oriented database is required here, but since we will be engaged in analysis in “home conditions” ", Pickle is enough for us.
Before saving dictionaries, it will be logical to delete keys from them whose values are None. These are blocked or deleted accounts. Simply put, these id will be present in the graph, because someone has a friend, but we will save on the number of keys in the dictionary:
def cleaner(dct):
return {k:v for k, v in dct.items() if v != None}
def save_or_load(myfile, sv, smth=None):
if sv and smth:
pickle.dump(smth, open(myfile, "wb"))
else:
return pickle.load(open(myfile, "rb"))
As you can see, if we saved the result somewhere, then somewhere we must load it so as not to collect the id again.
Graph analysis
In order not to write your bike, we will use the fairly well-known networkx , which will do all the
pip3 install networkx
Before we begin to analyze the graph, draw it. networkx this would require matplotlib :
pip3 install matplotlib
Next, we need to create the graph itself. In general, there are 2 ways.
The first will gobble up a lot of RAM and your time:
def adder(self, node):
if node not in self.graph.nodes():
self.graph.add_node(node)
self.graph = nx.Graph()
for k, v in self.dct.items():
self.adder(k)
for i in v:
self.adder(i)
self.graph.add_edge(k, i)
And this is not the author who survived from the mind, no. Such an example is given on the page at Rice University ( Rice University then ), under the heading of the Convert a Dictionary Graph Representation Into NetworkX Graph Representation :
def dict2nx(aDictGraph):
""" Converts the given dictionary representation of a graph,
aDictGraph, into a networkx DiGraph (directed graph) representation.
aDictGraph is a dictionary that maps nodes to its
neighbors (successors): {node:[nodes]}
A DiGraph object is returned.
"""
g = nx.DiGraph()
for node, neighbors in aDictGraph.items():
g.add_node(node) # in case there are nodes with no edges
for neighbor in neighbors:
g.add_edge(node, neighbor)
return g
You can take my word for it, the graph was being built all evening, when it already had more than 300,000 peaks, my patience snapped.
Yes, an example is given for a directed graph, but the essence remains the same - first add the keys, making them vertices, then make the vertices values, and then if they are not already in the graph, and then connect them with edges (in my version).
And the second method will do everything in seconds:
self.graph = nx.from_dict_of_lists(self.dct)
The code lies in the graph.py file . To draw a graph of mutual friends, just run this script or create an instance of the VkGraph () class somewhere , and then call its draw_graph () method .

This is a graph of mutual friends, with a total of 306 peaks and 2096 ribs. Unfortunately, I’m never a designer (almost all the settings are standard), but you can always stylize the graph "for yourself". Here are a couple of links:
And the method itself looks like this:
def draw_graph(self):
plt.figure(figsize=(19,19), dpi=450,)
nx.draw(self.graph, node_size=100, cmap=True)
plt.savefig("%s graph.png" % datetime.now().strftime('%H:%M:%S %d-%m-%Y'))
As a result, you get a picture date graph.png in the project folder. I do not advise drawing a graph for deep friends. With 308 friends and a depth of 2, there were more than 145,000 keys in the dictionary . But there are also values - tuples with id, which are unlikely to be small.
For a long time I was looking for the most low-profile friends profile on VKontakte, although here it is more important - friends-friends. 10 initial friends (1 of them blocked and will automatically be deleted), with our standard depth (2), in the dictionary there were 1234 keys and 517 174 id (from values). About 419 friends have one id. Yes, there are general friends there, when we build the graph, we will understand this:
deep_friends = VkGraph(d_friends_dct)
print('Количество вершин:', deep_friends.graph.number_of_nodes())
print('Количество ребер:', deep_friends.graph.number_of_edges())
Will return:
Количество вершин: 370341
Количество ребер: 512949
With such big data, it would be nice to play around. In networkx a very large list of algorithms that can be applied to graphs. We will analyze some of them.
Connected graph
First, let's determine if we have a connected graph:
print('Связный граф?', nx.is_connected(deep_friends.graph))
A connected graph is a graph in which any pair of vertices is connected by a route.
By the way, the same id with a depth of 1 has such a beautiful graph containing 1268 vertices and 1329 edges:

Question for connoisseurs. Since we get a graph of friends-friends, it should be connected in any way. It cannot be such that a peak appears out of nowhere that is not connected with any of the existing ones. However, we see one vertex on the right that is not connected to any one. Why? I urge you to think first, it will be more interesting to learn the truth.
Correct answer
Let's figure it out. First we take a list of friends, and it turns out that we have id X. Because of which the graph is incoherent. Next, we make a request for the friends of this X (in depth, after all). So if X has all his friends hidden, then there will be an entry in the dictionary:
When the graph is built, we honestly add the vertex X, but it will not have any edges. Yes, purely theoretically, the vertex X should have an edge with the vertex whose id is specified in settings.py , but you read carefully - we add only what is in the dictionary. Therefore, with a depth equal to 2, we get in the dictionary id specified in the settings. And then at the vertex X there will be edges.
{X:(), ...}
When the graph is built, we honestly add the vertex X, but it will not have any edges. Yes, purely theoretically, the vertex X should have an edge with the vertex whose id is specified in settings.py , but you read carefully - we add only what is in the dictionary. Therefore, with a depth equal to 2, we get in the dictionary id specified in the settings. And then at the vertex X there will be edges.
We assume that you will not have such a situation, that is, most likely you will see True .
Diameter, center and radius
Recall that the diameter of a graph is the maximum distance between its two vertices.
print('Диамерт графа:', nx.diameter(deep_friends.graph))
The center of the graph is any vertex such that the distance from it to the most distant vertex is minimal. The center of a graph can be one vertex or several vertices. Or easier. The center of the graph is a vertex whose eccentricity (the distance from this vertex to the most distant from it) is equal to the radius.
print('Центр графа:', nx.center(deep_friends.graph))
Will return a list of vertices that are the center of the graph. Do not be surprised if the center is the id specified in settings.py .
The radius of the graph is the smallest of the eccentricities of all the vertices.
print('Радиус графа:', nx.radius(deep_friends.graph))
Authority or Page Rank
This is the very Page Rank that you thought about. Typically, the algorithm is used for web pages or other documents linked by links. The more links to a page, the more important it is. But no one forbids using this algorithm for graphs. We will borrow a more accurate and suitable definition from this article :
Authority in a social graph can be analyzed in various ways. The easiest is to sort the participants by the number of incoming edges. Whoever has more is more authoritative. This method is suitable for small graphs. In an Internet search, Google uses PageRank as one of the criteria for page credibility. It is calculated by randomly wandering around the graph, where the nodes are pages, and the edge between the nodes is if one page links to another. A random walker moves around the graph and from time to time moves to a random node and starts walking again. PageRank is equal to the share of stay on some node for the entire time of wandering. The larger it is, the more authoritative the node.
import operator
print('Page Rank:', sorted(nx.pagerank(deep_friends.graph).items(), key=operator.itemgetter(1), reverse=True))
Clustering coefficient
Quoting Wikipedia:
The clustering factor is the degree of probability that two different users associated with a particular individual are also connected.
print('Коэффициент кластеризации', nx.average_clustering(deep_friends.graph))
As you can see, there is nothing complicated, and networkx offers many more algorithms (the author counted 148) that can be applied to graphs. You just have to select the algorithm you need and call the appropriate method in the graph.py file .
Total
We made a distributed system that allows you to collect and build a graph of mutual friends on VKontakte, which works 60 times faster (depending on the number of workers) than the proposed version from Himura , also implemented a new function - request all “deep friends”, added the ability to analyze constructed graphs.
If you do not want to install additional software and you need to build a beautiful graph of mutual friends from the previous article , then the old release is at your service. In it you will also find the old version of getting the user's friends list recursively arbitrarily deeply.
This is not the limit, work will continue to increase the speed of the program.
Still waiting for you to pull pull requests, especially if you are involved in data visualization. Thanks for attention!