CodeRainbow: interactive study and documenting code

Often, programmers have to deal with someone else's unfamiliar code. This may be the study of interesting projects with open source, and the need for work - in the case of joining a new project, when analyzing a large amount of legacy code, etc. I think every one of you has come across this.
In the course of such work, I always felt the need for some kind of tool, specially sharpened to facilitate the process of fast immersion in large volumes of unfamiliar code. Over time, all the new interesting ideas in different areas, and they all required the study of large amounts of someone else's code. Decentralized networks, cryptocurrencies, compilers, operating systems are all large projects that require the study of significant amounts of code. At some point I decided: you just need to take and make this special tool. In this article I present to your attention what happened as a result.
What generally can help in learning the code? Of course, it’s good when there is detailed documentation on the code - as a rule, it isn’t; good coding style and comments are also good, but this is usually not enough. There are also various code documentation generators, such as doxygen. Analyzing the structure of the code and special documenting comments, they generate documentation in the form of hypertext in html format. The main drawback of such documentation is its non-interactivity; In the process of studying the code, a programmer may have some kind of new understanding, and in order to reflect it in the documentation, you need to write new documenting comments and regenerate all the documentation anew.
In addition, such documentation has no direct connection with the code in the development environment, i.e. Clicking on the hyperlink will not open the file with this code in the IDE. There is a good analogy for such tools, rooted in ancient times: the first disassemblers were command line tools that generated code without user input. Then came the first interactive disassembler (“IDA pro”), which implied the user's active participation in the disassembly process - assigning names of variables and functions, defining structures, writing code comments, etc.
Analyzing large amounts of foreign code in a high-level language is in some ways very similar to disassembling. Thus, I started to get an idea of what exactly I want. Most IDEs have classic File View and Class View panels that display the structure of files and namespaces / classes inside them. But this structure is usually rigidly connected with the syntax of the language and does not allow the user to make a meaning. Thus, the first thing I wanted to have was the interactive possibility of building arbitrary trees that contain meaningfully named links to the code — to the same classes and functions, or to arbitrary places. And the second is the desire to somehow mark the code directly in the editor. Marks can carry a very different meaning: from simple “learned”, “understand”, “rewrite”, before the code belongs to different semantic groups. You can mark the comment, but I wanted something more visible. For example, changing the background color of a code fragment. So the color separators on the KDPV is a fairly accurate analogy from the real world.
Having conducted the first experiments, I quickly realized that it should be a plug-in to the modern development environment, and not my own editor. Working from two editors at the same time is stupid and inconvenient; the prospect of repeating all the possibilities of the development environment did not inspire joy, and why do what has already been done? Therefore, the plugin. Qt Creator was chosen as the first IDE simply because the most popular code navigation operations (Go to definition, Find references, etc.) are performed as quickly as possible. The next medium will be Visual Studio, and then - if the concept itself is successful - an implementation for other IDEs.
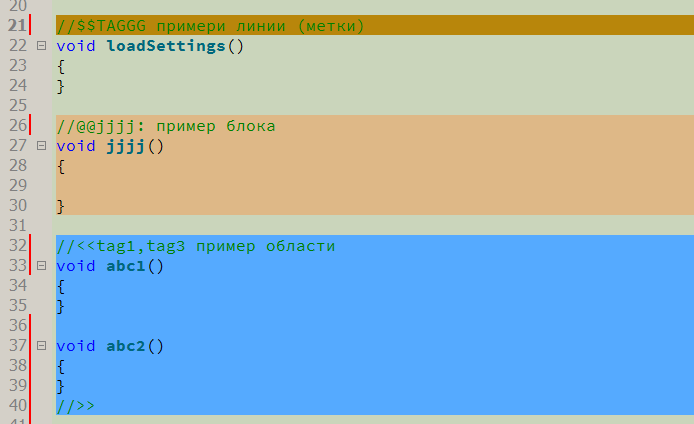
Now, how it all works. Introduced the concept of "marker comments". This is a common comment of a programming language (at the moment it is a single-line comment "//" used in many languages - C, C ++, C #, Java, ...), followed by a sequence of special characters, followed by an identifier and / or tags, which can be placed ordinary human comment. I entered three types of marker comments.
- Comment to highlight an arbitrary area. The only type requiring a “closing” marker comment. It starts with "// <<" and ends with "// >>".
- Comment to denote an arbitrary line in the code. Denoted by "// $$"
- Comment to highlight a syntactically correct block of code. It starts with "// @@" and includes the block of code below, surrounded by curly brackets "{" and "}", which are used for blocks of code in most C-like programming languages. A full-fledged bracket analysis is implemented - nested curly brackets are allowed, and the parser correctly skips curly brackets in lines and comments.
Further, immediately after the special characters are one or more identifiers separated by commas. Identifiers are "tags" and can mean what the programmer wants - signs of "learned", "rewrite", "figure out", authorship of the code, the relation of code to some semantic groups, etc. You can also specify one unique identifier - it is placed first and separated from the rest by a colon. If you wish, you can explicitly specify the background color of the code snippet — a grid is placed at the end of the tag list, after which the color is indicated in RGB format (although this method is not the best — the other, more “correct” method will be discussed later). And at the very end you can put a space, then you can write a regular human-readable comment. I tried to choose the syntax so that it was as simple as possible for quick input,
Although manual input of marker comments is possible, it is supposed to use special toolbar buttons for this. The cursor is set to the desired position of the code and the button is pressed (or one of the last options is selected from the menu).
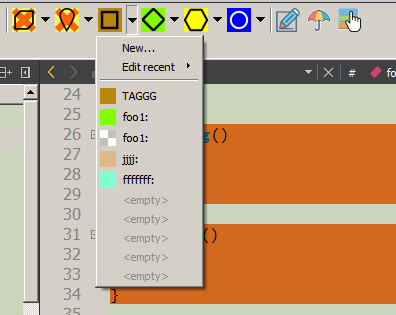
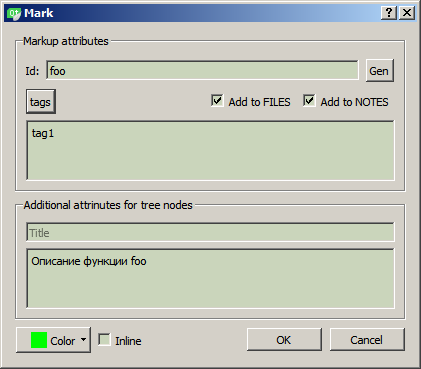
If necessary, an input dialog will open, where you can enter tags and identifiers of marker comments, a detailed description, as well as select a background color. This data will be entered not only in the code, but also in the “CRContentTree” tree displayed on the side in the tree panel (where FileView, ClassView, etc.). It should be noted that the background color can be “transparent” - in this case, the background color of the enclosing block (if any) is used or the backlight is not used at all.
At the moment, the tree consists of three main parts (top-level nodes): FILES, TAGS and NOTES (perhaps this is not the final solution, because the concept is not completely obvious, nor is the convenience of such a structure).
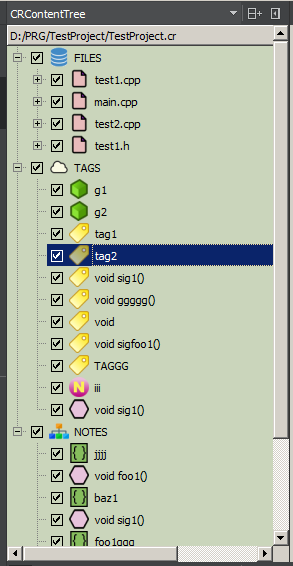
FILES is the file structure of the project, which is extracted from the project file or from the source distribution on the disk. File nodes are created during the initial generation of the tree. Double clicking on the file node normally opens the file in the IDE editor. You can specify the addition of a marker comment in FILES - then the child will appear in the corresponding file. This is where unique identifiers of marker comments are added. The system checks the uniqueness of the identifier within the file node of the tree and allows you to generate a unique name automatically.
TAGS is a global tag cloud for a project; tags are not tied to the source file and can appear in any project file as many times as necessary.
NOTES is a place to store nodes, grouped in an arbitrary way and not tied to the file structure. Each node contains both a file path and an identifier. The main purpose is to create custom logical groups. For example, "all functions that need to be rewritten" or "all functions related to cryptography", or "a sequence of network exchange functions with the server" (since the nodes in the tree are ordered, then simply placing the nodes behind each other can display any sequences).
Each tree node has a context menu. The node can be deleted (although it does not delete the marker comments from the code - as long as I am not sure that this is necessary), I can edit it. You can add nodes that are not related to marker comments: for example, you can add a link (Link). Double clicking on such a node will open the linked resource in the associated program, for example, a hyperlink in the browser.
Each node can be disabled by unchecking the corresponding check box in the checkbox of the node. This will cause the highlighting of this node and all the child nodes in the code to be removed. Thus, removing for example the checkboxes from the three root nodes (FILES, TAGS and NOTES), you can turn off the highlighting of all marker comments, except for those whose color is clearly indicated in the code (through the grid).
Double clicking on a node opens the corresponding file in the IDE and positions the cursor on the corresponding code position. For tags that may occur many times, instead of opening a file, a list of all entries is formed, which is loaded into the CR Output panel, and by double-clicking on the corresponding line of this list you can open the file and the position in the code.
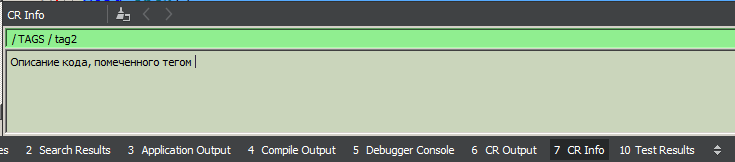
Each node has a field for a detailed description (multi-line text of arbitrary length). This description is loaded into the “CR Info” area with a simple selection of a node in the tree (with a single click of the mouse), and also by placing the cursor anywhere in the highlighted area in the code and clicking the “Lookup” button on the toolbar. Editing is always available, modified text is saved automatically (by loss of focus). I am thinking about making support for the Markdown format in this area, but so far my hands have not reached this point.
It is not always desirable (or not always convenient) to insert any comments into the code. Therefore, the second possibility is “signatures”, i.e. use as markers of the code itself. A signature is considered to be some sequence of tokens (excluding spaces and line breaks - that is, “foo (1,2,3)” and “foo (1, 2, 3)” are the same thing). There are three types of signatures:
- block - a block is highlighted, starting with a signature and including a code sequence enclosed in braces.
- single line - the entire line with the signature is highlighted
- character - only the signature sequence is highlighted. Such signatures are conveniently used to single out individual names - variables, functions, classes.
Working with signature blocks is the same as with marker blocks. Similarly, nodes are created in the tree.
If for marker nodes the identifier and tags were created separately, then for signature sites it is suggested to indicate how exactly we want to treat the signature as an identifier (linked to a file) or as a global tag. For example, it is logical to use the tag mode for “names” - then the corresponding name will be highlighted in the code for the entire project.
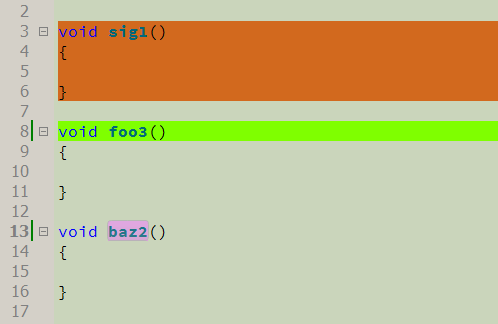
Another interesting feature is building code coverage. A special function scans the code and determines the places that are not marked at all, and generates a list of such places in the CR Output. It does not take into account empty lines and comments, i.e. The scan takes into account only significant code. Double-click on the line of the list, you can go to this place in the code, and having studied it, mark it in one way or another.
A little about the format of the storage base. Actually, only marker comments are stored in the source code; the contents of the tree are stored in a special xml-file with the extension ".cr". There is no explicit linking of the base file to the projects, although when opening a project, an attempt is made to open a cr-file with the same name if no cr-file was previously loaded.
To summarize. In general, I realized almost everything I wanted. The concept is new and unusual, and therefore it takes some time and feedback from users to understand what needs to be developed and what can be abandoned. In an attempt to realize as many possibilities as possible, something turned out to be slightly over-complicated, which is inevitable. The interface itself is probably not yet established and will change. But in general, it seems, turned out well.
What are the plans? This is a demo version, largely raw and not intended for commercial use. I have a dream - to make my commercial product, which brings even a small but steady income, sufficient to take up other interesting projects. In addition, some things are not adapted for commercial use. I imagine how to adapt a similar system for a multi-user mode, given the fact that the code can be ruled by several people simultaneously working through a version control system. It is also possible to look towards the generation of familiar documentation (html), perhaps - tools for deeper integration with the code (syntactic analysis instead of lexical / bracketing, automatic generation of class lists and methods and their conversion into tree nodes). Of course, it requires the correction of bugs (which still exist) and the improvement of features. And of course I am waiting for your comments with ideas and suggestions :)
That's all for now (although there are still some minor features that I didn’t mention in the article - for example, I found it necessary to add tabs, because without them it's completely sad - although there are several plug-ins for tabs; also some basic Qt commands are displayed on the toolbar Creator, unrelated to the plugin, etc.).
Download Link: https://www.dropbox.com/s/9iiw5x7elwy3tpe/CodeRainbow4.zip?dl=0
System Requirements: Windows, Qt Creator> = 4.5.1 compiled MSVC2015 32bit (this is the standard assembly distributed to download.qt .io)
installation: unzip the archive and copy the plugin to the c: /Qt/Qt5.10.1/Tools/QtCreator/lib/qtcreator/plugins folder (this is an example for standard Qt placement, if you have Qt installed differently or another version - the path will be different) and (re) run Qt Creator.