Hadoop: what, where and why

We dispel fears, eliminate illiteracy and destroy myths about the iron-born elephant. Under the cat, an overview of the Hadoop ecosystem, development trends and a bit of personal opinion.
Suppliers: Apache, Cloudera, Hortonworks, MapR
Hadoop is the top-level project of the Apache Software Foundation, so Apache Hadoop is considered the main distribution and central repository for all the developments. However, this same distribution is the main reason for the majority of burned nerve cells when familiar with this tool: by default, installing an elephant on a cluster requires preliminary configuration of the machines, manual installation of packages, editing of many configuration files and a bunch of other body movements. However, the documentation is often incomplete or simply outdated. Therefore, in practice, distributions from one of three companies are most often used:
Cloudera. A key product - CDH (Cloudera Distribution including Apache Hadoop) - a bunch of the most popular tools from the Hadoop infrastructure running Cloudera Manager. The manager assumes responsibility for the deployment of the cluster, the installation of all components and their further monitoring. In addition to CDH, the company also develops its other products, for example, Impala (more on this below). A distinctive feature of Cloudera is also the desire to be the first to provide new features on the market, even at the expense of stability. Well and yes, the creator of Hadoop - Doug Cutting - works at Cloudera.
Hortonworks. Like Cloudera, they provide a single solution in the form of HDP (Hortonworks Data Platform). Their distinguishing feature is that instead of developing their own products, they invest more in the development of Apache products. For example, instead of Cloudera Manager they use Apache Ambari, instead of Impala, they further develop Apache Hive. My personal experience with this distribution comes down to a couple of tests on a virtual machine, but it feels like HDP looks more stable than CDH.
Mapr. Unlike the two previous companies, for which, apparently, consulting and affiliate programs are the main source of revenue, MapR is directly involved in the sale of its developments. From the pros: a lot of optimizations, an affiliate program with Amazon. Of the minuses: the free version (M3) has truncated functionality. In addition, MapR is the main ideologist and chief developer of Apache Drill.
Foundation: HDFS
When we talk about Hadoop, we primarily mean its file system - HDFS (Hadoop Distributed File System). The easiest way to think about HDFS is to imagine a regular file system, only more. A typical file system, by and large, consists of a file descriptor table and a data area. In HDFS, instead of a table, a special server is used - a name server (NameNode), and data is scattered across data servers (DataNode).
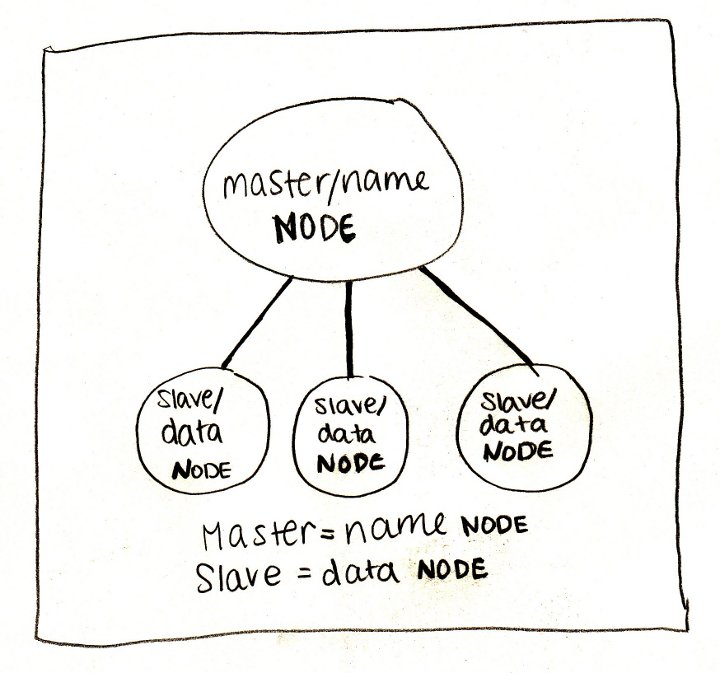
Otherwise, there are not so many differences: the data is divided into blocks (usually 64 MB or 128 MB), for each file the name server stores its path, a list of blocks and their replicas. HDFS has a classic unix tree structure of directories, users with a triple of rights, and even a similar set of console commands:
# просмотреть корневую директорию: локально и на HDFS
ls /
hadoop fs -ls /
# оценить размер директории
du -sh mydata
hadoop fs -du -s -h mydata
# вывести на экран содержимое всех файлов в директории
cat mydata/*
hadoop fs -cat mydata/*
Why is HDFS so cool? Firstly, because it is reliable: somehow, when IT equipment was rearranged, the IT department accidentally destroyed 50% of our servers, while only 3% of the data was irretrievably lost. And secondly, and even more importantly, the name server reveals the location of data blocks on machines for everyone . Why is this important, see the next section.
Engines: MapReduce, Spark, Tez
With the correct architecture of the application, information about the machines on which the data blocks are located allows you to run computational processes on them (which we will gently call “workers”) and perform most of the calculations locally , i.e. without data transmission over the network. It is this idea that underlies the MapReduce paradigm and its concrete implementation in Hadoop.
The classic Hadoop cluster configuration consists of one name server, one MapReduce wizard (the so-called JobTracker) and a set of working machines, each of which simultaneously runs a data server (DataNode) and a worker (TaskTracker). Each MapReduce work consists of two phases:
- map - runs in parallel and (if possible) locally on each data block. Instead of delivering terabytes of data to the program, a small, user-defined program is copied to the server with the data and does everything with it that does not require shuffling and moving data (shuffle).
- reduce - supplements map with aggregation operations
In fact, between these phases there is also a combine phase , which does the same as reduce , but above the local data blocks. For example, suppose we have 5 terabytes of mail server logs that we need to parse and extract error messages. Lines are independent of each other, so their analysis can be shifted to the map task . Next, with combine, you can filter the lines with the error message at the single server level, and then with reducedo the same at the level of all data. Everything that could be parallelized, we parallelized, and, in addition, we minimized data transfer between servers. And even if some task crashes for some reason, Hadoop will automatically restart it, picking up intermediate results from the disk. Cool!
The problem is that most real-world tasks are much more complicated than a single MapReduce job. In most cases, we want to do parallel operations, then sequential, then parallel again, then combine several data sources and again do parallel and sequential operations. The standard MapReduce is designed so that all results — both final and intermediate — are written to disk. As a result, the time of reading and writing to disk, multiplied by the number of times it is done in solving the problem, is often several times (yes, there are several, up to 100 times!) Exceeds the time of the calculations themselves.
And here comes Spark. Designed by the guys at Berkeley University, Spark uses the idea of data locality, but it puts most of the calculations into memory instead of a disk. The key concept in Spark is RDD (resilient distributed dataset) - a pointer to a lazy distributed data collection. Most operations on RDD do not lead to any calculations, but only creates the next wrapper, promising to perform operations only when they are needed. However, this is easier to show than to tell. The following is a Python script (Spark out of the box supports interfaces for Scala, Java and Python) for solving the log problem:
sc = ... # создаём контекст (SparkContext)
rdd = sc.textFile("/path/to/server_logs") # создаём указатель на данные
rdd.map(parse_line) \ # разбираем строки и переводим их в удобный формат
.filter(contains_error) \ # фильтруем записи без ошибок
.saveAsTextFile("/path/to/result") # сохраняем результаты на дискIn this example, real calculations begin only on the last line: Spark sees that the results need to be materialized, and for this begins to apply operations to the data. At the same time, there are no intermediate stages - each line is lifted into memory, disassembled, checked for a sign of error in the message, and if there is such a sign, it is immediately written to disk.
Such a model turned out to be so effective and convenient that projects from the Hadoop ecosystem began to transfer their calculations to Spark one by one, and now more people are working on the engine itself than on the obsolete MapReduce.
But not Spark's one. Hortonworks decided to focus on an alternative engine - Tez. Tez presents the task as a directed acyclic graph (DAG) of handler components. The scheduler starts the calculation of the graph and, if necessary, dynamically reconfigures it, optimizing for the data. This is a very natural model for performing complex data queries, such as SQL-like scripts in Hive, where Tez brought acceleration up to 100 times. However, besides Hive, this engine is still not widely used, so it’s quite difficult to say how suitable it is for simpler and more common tasks.
SQL: Hive, Impala, Shark, Spark SQL, Drill
Despite the fact that Hadoop is a complete platform for developing any application, it is most often used in the context of data storage and specifically SQL solutions. Actually, this is not surprising: large amounts of data almost always mean analytics, and analytics is much easier to do on tabular data. In addition, for SQL databases it is much easier to find both tools and people than for NoSQL solutions. There are several SQL-oriented tools in the Hadoop infrastructure:
Hive- The very first and still one of the most popular DBMSs on this platform. As a query language, it uses HiveQL, a stripped-down dialect of SQL, which, nevertheless, allows you to perform rather complex queries on data stored in HDFS. Here we need to draw a clear line between the versions of Hive <= 0.12 and the current version 0.13: as I said, in the latest version Hive switched from the classic MapReduce to the new Tez engine, accelerating it many times and making it suitable for interactive analytics. Those. now you don’t have to wait 2 minutes to calculate the number of records in one small partition or 40 minutes to group the data by day for a week (goodbye long breaks!). In addition, both Hortonworks and Cloudera provide ODBC drivers, allowing you to connect tools like Tableau to Hive.
Impala is a Cloudera product and a major competitor to Hive. Unlike the latter, Impala never used the classic MapReduce, but initially executed queries on its own engine (written, incidentally, on non-standard for Hadoop C ++). In addition, recently Impala has been actively using caching of frequently used data blocks and column storage formats, which has a very good effect on the performance of analytical queries. Just like for Hive, Cloudera offers its offspring a very effective ODBC driver.
Shark. When Spark entered the Hadoop ecosystem with its revolutionary ideas, the natural desire was to get an SQL engine based on it. This resulted in a project called Shark, created by enthusiasts. However, in Spark 1.0, the Spark team released the first version of their own SQL engine - Spark SQL; from now on, Shark is considered stopped.
Spark sq- A new branch of SQL development based on Spark. Honestly, comparing it with previous tools is not entirely correct: Spark SQL does not have a separate console and its own metadata repository, the SQL parser is still rather weak, and the partitions, apparently, are not supported at all. Apparently, at the moment, his main goal is to be able to read data from complex formats (such as Parquet, see below) and express logic in the form of data models, not program code. And honestly, this is not so little! Very often, the processing pipeline consists of alternating SQL queries and program code; Spark SQL allows you to seamlessly relate these stages without resorting to black magic.
Hive on Spark - there is such a thing, but, apparently, it will work no earlier than version 0.14.
Drill. To complete the picture, mention should be made of Apache Drill. This project is still located in the ASF incubator and is not widespread, but apparently, the main emphasis in it will be placed on semi-structured and embedded data. In Hive and Impala, you can also work with JSON strings, however, the query performance is significantly reduced (often up to 10-20 times). It is hard to say what the creation of another DBMS based on Hadoop will lead to, but let's wait and see.
Personal experience
Если нет каких-то особых требований, то серьёзно воспринимать можно только два продукта из этого списка — Hive и Impala. Оба достаточно быстры (в последних версиях), богаты функционалом и активно развиваются. Hive, однако, требует гораздо больше внимания и ухода: чтобы корректно запустить скрипт, часто нужно установить десяток переменных окружения, JDBC интерфейс в виде HiveServer2 работает откровенно плохо, а бросаемые ошибки мало связаны с настоящей причиной проблемы. Impala также неидеальна, но в целом гораздо приятней и предсказуемей.
NoSQL: HBase
Despite the popularity of SQL analytics solutions based on Hadoop, sometimes you still have to deal with other problems for which NoSQL databases are better suited. In addition, both Hive and Impala work better with large packets of data, and reading and writing individual lines almost always means more overhead (remember the data block size is 64 MB).
And here HBase comes to the rescue. HBase is a distributed versioned non-relational DBMS that effectively supports random read and write. Here you can tell that the tables in HBase are three-dimensional (a string key, time stamp and qualified column name), that the keys are stored sorted in lexicographic order, and much more, but the main thing is that HBase allows you to work with individual records in real time . And this is an important addition to the Hadoop infrastructure. Imagine, for example, that you need to store information about users: their profiles and a log of all actions. The action log is a classic example of analytical data: actions, i.e. in fact, events are recorded once and are never changed again. Actions are analyzed in batches and at some intervals, for example, once a day. But profiles are a completely different matter. Profiles need to be constantly updated, and in real time. Therefore, for the event log, we use Hive / Impala, and for profiles - HBase.
With all this, HBase provides reliable storage due to its base on HDFS. Stop, but haven't we just said that random access operations are not efficient on this file system due to the large data block size? That's right, and this is HBase’s big trick. In fact, new records are first added to the sorted structure in memory, and only when this structure reaches a certain size are flushed to disk. Consistency is maintained at the expense of write-ahead-log (WAL), which is written directly to disk, but, of course, does not require support for sorted keys. Read more about this on the Cloudera blog .
Oh yes, you can query HBase tables directly from Hive and Impala.
Data Import: Kafka

Typically, importing data into Hadoop goes through several stages of evolution. Initially, the team decides that regular text files will be enough. Everyone knows how to write and read CSV files, there should be no problems! Then from somewhere unprintable and non-standard characters appear (what a bastard inserted them!), The problem of escaping strings, etc., and you have to switch to binary formats or at least a surplus JSON. Then two dozen clients (external or internal) appear, and it is not convenient for everyone to send files to HDFS. At this point, RabbitMQ appears. But he does not last long, because everyone suddenly remembers that the rabbit is trying to keep everything in his memory, and there is a lot of data, and it is not always possible to quickly collect them.
And then someone stumbles upon Apache Kafka- A distributed messaging system with high bandwidth. Unlike the HDFS interface, Kafka provides a simple and familiar messaging interface. Unlike RabbitMQ, it immediately writes messages to disk and stores there a configured period of time (for example, two weeks) during which you can come and collect data. Kafka is easy to scale and theoretically can express any amount of data.
All this beautiful picture collapses when you start using the system in practice. The first thing to remember when dealing with Kafka is that everyone lies. Especially the documentation. Especially official. If the authors write “we have X supported,” this often means “we would like to have X supported” or “in future versions we plan to support X”. If it says “the server guarantees Y”, then most likely it means “the server guarantees Y, but only for client Z”. There were cases when one was written in the documentation, another in the commentary on the function, and the third in the code itself.
Kafka changes the main interfaces even in minor versions and for a long time can not make the transition from 0.8.x to 0.9. The source code itself, both structurally and at the level of style, is clearly written under the influence of the famous writer, who gave the name to this monster.
And, despite all these problems, Kafka remains the only project at the architecture level that solves the issue of importing a large amount of data. Therefore, if you still decide to contact this system, remember a few things:
- Kafka doesn’t lie about reliability - if messages reach the server, they will remain there for the specified time; if there is no data, then check your code;
- consumer groups do not work: regardless of configuration, all messages from the partition will be sent to all connected consumers;
- the server does not store offsets for users; the server in general, in fact, cannot identify connected consumers.
A simple recipe that we gradually came to is to start one consumer per partition line (topic, in Kafka terminology) and manually control the shifts.
Stream Processing: Spark Streaming
If you read up to this paragraph, then you are probably interested. And if you're interested, then you probably heard about lambda architecture , but just in case, I will repeat it. Lambda architecture involves duplication of the pipeline of calculations for batch and streaming data processing. Batch processing starts periodically over the past period (for example, yesterday) and uses the most complete and accurate data. Stream processing, in contrast, produces real-time calculations, but does not guarantee accuracy. This can be useful, for example, if you launched a promotion and want to track its effectiveness hourly. A delay of a day is unacceptable here, but the loss of a couple of percent of events is not critical. Spark Streaming
is responsible for streaming data in the Hadoop ecosystem.. Streaming from the box can take data from Kafka, ZeroMQ, socket, Twitter, etc. ... The developer is provided with a convenient interface in the form of DStream - in fact, a collection of small RDDs collected from a stream for a fixed period of time (for example, in 30 seconds or 5 minutes ) All the buns of ordinary RDD are preserved.
Machine learning

The picture above perfectly expresses the state of many companies: everyone knows that big data is good, but few people really understand what to do with it. And you need to do two things with them first of all - translates into knowledge (read how: use when making decisions) and improve the algorithms. The analytics tools already help with the first, and the second comes down to machine learning. Hadoop has two major projects for this:
Mahout- The first large library to implement many popular algorithms using MapReduce. It includes algorithms for clustering, collaborative filtering, random trees, as well as several primitives for factorizing matrices. At the beginning of this year, the organizers decided to transfer everything to the Apache Spark computing kernel, which supports iterative algorithms much better (try to drive 30 iterations of gradient descent through the disk with the standard MapReduce!).
MLlib. Unlike Mahout, which is trying to port its algorithms to the new kernel, MLlib is initially a Spark subproject. It includes: basic statistics, linear and logistic regression, SVM, k-means, SVD and PCA, as well as optimization primitives such as SGD and L-BFGS. The Scala interface uses Breeze for linear algebra, the Python interface is NumPy. The project is actively developing and with each release significantly adds to the functionality.
Data Formats: Parquet, ORC, Thrift, Avro
If you decide to use Hadoop to the fullest, it will not hurt to familiarize yourself with the main formats of data storage and transmission.
Parquet is a columnar format optimized for storing complex structures and efficient compression. It was originally developed on Twitter, and now it is one of the main formats in the Hadoop infrastructure (in particular, it is actively supported by Spark and Impala).
ORC is the new optimized storage format for Hive. Here we again see the confrontation between Cloudera c Impala and Parquet and Hortonworks with Hive and ORC. The most interesting thing to read is a comparison of the performance of solutions: on the Cloudera blog, Impala always wins, with a significant margin, and on the Hortonworks blog, as you might guess, Hive wins, with no less margin.
Thrift- An effective, but not very convenient binary data transfer format. Working with this format involves defining a data scheme and generating the appropriate client code in the desired language, which is not always possible. Recently, they began to refuse it, but many services still use it.
Avro - basically positioned as a replacement for Thrift: it does not require code generation, can transfer a scheme along with data, or even work with dynamically typed objects.
Other: ZooKeeper, Hue, Flume, Sqoop, Oozie, Azkaban
And finally, briefly about other useful and useless projects.
ZooKeeper is the primary coordination tool for all elements of the Hadoop infrastructure. It is most often used as a configuration service, although its capabilities are much wider. Simple, convenient, reliable.
Hue is a web-based interface to Hadoop services, part of Cloudera Manager. It works poorly, with errors and mood. Suitable for display to non-technical specialists, but for serious work it is better to use console analogs.
Flume is a service for organizing data flows. For example, you can configure it to receive messages from syslog, aggregate and automatically drop it into a directory on HDFS. Unfortunately, it requires a lot of manual configuration of threads and constant expansion of their own Java classes.
Sqoop is a utility for quickly copying data between Hadoop and RDBMS. Quick in theory. In practice, Sqoop 1 turned out to be essentially single-threaded and slow, and Sqoop 2 simply did not work at the time of the last test.
Oozie is a task flow scheduler. Originally designed to combine individual MapReduce jobs into a single pipeline and run them on a schedule. In addition, it can perform Hive, Java and console actions, but in the context of Spark, Impala, etc., this list looks rather useless. Very fragile, confusing and almost impossible to debug.
Azkaban- A completely suitable replacement for Oozie. It is part of LinkedIn's Hadoop infrastructure. It supports several types of actions, the main of which is a console command (and what else is needed), scheduled launch, application logs, notifications of dropped work, etc. Of the minuses, there is some dampness and an interface that is not always clear (try to guess that you don’t need to work create through the UI, and upload as a zip archive with text files).
That's all. Thanks to everybody, you're free.