The Taming of the Shrew (in fact, no) FineReader
- Tutorial
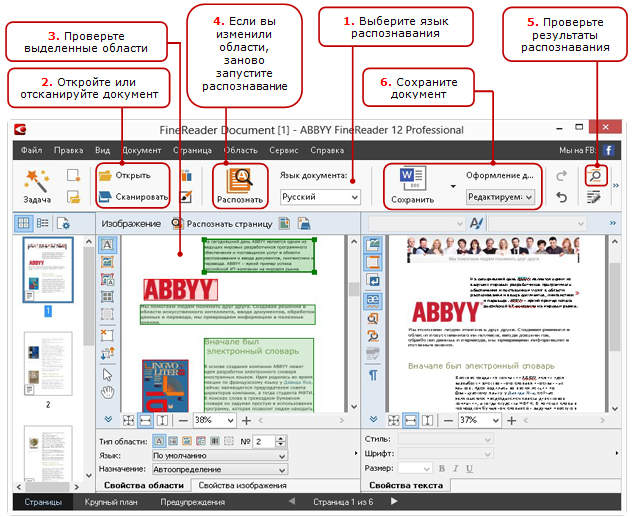
After a short story about how ABBYY FineReader (aka “theoretical part”) works, it's time to move on to applying the knowledge gained. And yes, there are no seals under the cat: everything is very serious.
How can a user participate in document processing?
In order not to reinvent the wheel, I will start with a simple and understandable diagram from the Help (see the figure on the right).
Now, knowing the list of all operations, let's look at examples - what might go wrong and how to deal with it.
Only good images are well recognized.
And what to do when there are images, but not very good ones? Improve everything in FineReader that is possible, and if it is impossible to improve, try to get the image again, eliminating the problem. Since the topic is very extensive, with due interest there will be a separate post on how to make friends with automatic and manual image processing tools directly in FineReader. In the meantime, I will limit myself to the observation that the image will be processed better if it:
- (after scanning) has no pronounced geometric distortions - skew or noticeable bending of the pages of a thick book at the spine of a two-page spread,
- (after photographing, in addition to the previous one) it also has no non-linear geometric distortions (“pillow”, “trapezoid”), it has uniform focusing (and preferably brightness) over the entire area, has no noise from insufficient lighting, does not have pronounced illumination from flash (especially on glossy paper).
Document / Project Setup Step
It is possible and necessary to immediately indicate the language of the text, the parameters of image preprocessing, some parameters of analysis and recognition. Here is a screenshot of one of the tabs in the settings dialog.
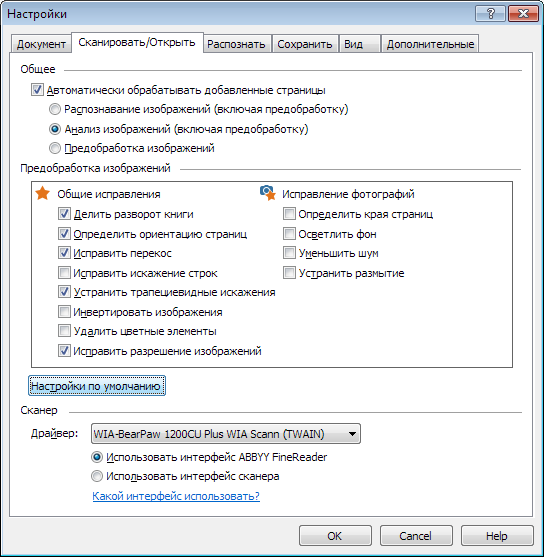
These and other settings are described in detail in the Help.
Analysis stage
The program automatically identifies areas of various types in terms of recognition. At this stage, we can both independently mark the areas and correct (if necessary) those that we found the Analysis module.
In order not to write too much about tools for working with regions, I will refer to the Help section , and here I will explain what for what, “what is good, what is bad” (with respect to areas) and how to fix a bad result.
Assigning areas of different types
There are several types of areas available in the FineReader user interface, for them there are different options for a hidden property panel (at the bottom of the “Image” window) and a context menu (right-click):
- “Recognition zone” (gray frame by default) - this name is used in the user interface, in my opinion it would be more correct to call “area for automatic analysis”. The purpose of such an area is to indicate where on the page in general you need to look for something useful. Therefore, as a result of subsequent analysis or analysis + recognition, within each “recognition zone” zero or more areas of other types can be found . Recognition zones are especially useful in block templates (more about them in the Help).Examples of correctly drawn recognition zonesРеальный пример из проекта оцифровки Толстого — часть страниц имеет нумерацию строк (пронумерованы строки с номерами, кратными 10), не нужную в результате и затрудняющую вычитку/правку текста, если автоматический анализ включил эти номера в текстовую область колонки. Если страницы были почти одинаково выровнены на сканере или качественно обрезаны после сканирования, то перед анализом к нужной группе страниц можно применить шаблон блоков, где область (или области) распознавания просто не содержит не нужных нам частей страницы:
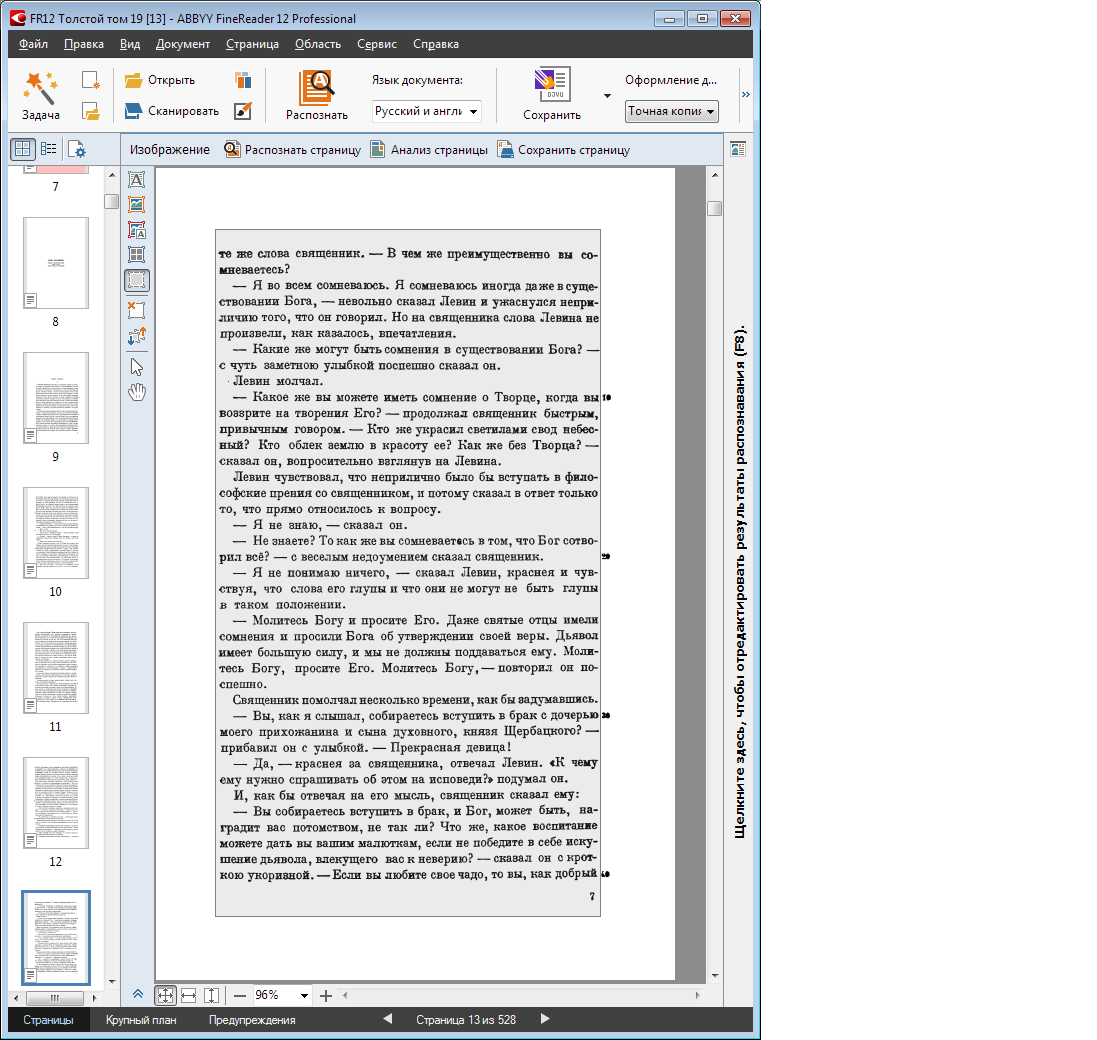
Помните, что в отличие от текстовой области область распознавания может превратиться в области разных типов, что бывало нужно и в этом проекте. - Text area - contains the text of one or more lines, each of which contains logically connected text, so it is a very bad idea to select two columns in one block. May have a non-rectangular shape. It happens that you need to set or correct after incorrect auto-analysis the direction of the text, “inversion” (simplified: dark text on a light background is “plain text”, and light text on a dark background is “inverse” text, the default is “Auto” and almost never requires correction).
These parameters are set per block, so selecting text of different directions or different inversions in one block is another bad idea.About the direction of the main text of the pageВ европейских языках в нормальной ориентации текста строки читаются сверху вниз (в блоке с повёрнутым текстом – от логического верха в сторону логического низа), но в случае иероглифических языков всё гораздо веселее – даже на одной странице одни области могут содержать текст в горизонтальной ориентации, а другие – в колоночной, причём иероглифы имеют одинаковую ориентацию во всех этих областях (если тема дальневосточных и ближневосточных языков интересна – просите отдельный пост про тамошние навороты). 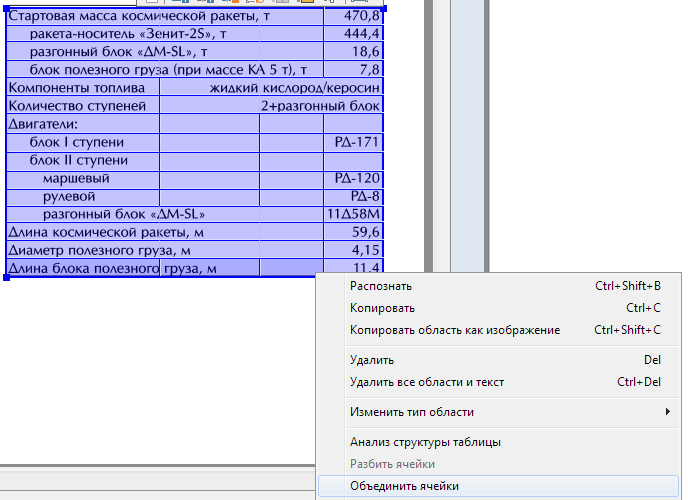 Tablespace - contains a table with both visible row and column separators, and invisible (partially or everywhere). A table can only have a rectangular shape, each of the cells is also a rectangle, but using the combination of cell groups or row groups, you can transfer very complex text configurations.
Tablespace - contains a table with both visible row and column separators, and invisible (partially or everywhere). A table can only have a rectangular shape, each of the cells is also a rectangle, but using the combination of cell groups or row groups, you can transfer very complex text configurations.
Each cell can have recognizable text (possibly blank) or a picture. If you want to recognize text in a cell, you can set special recognition parameters for it, but if not, you should specify “picture in full cell”. By the way, you can immediately select a rectangular group of table cells and change the desired property for all at once.
Tables are a complex object for automatic analysis, especially with partially or everywhere invisible delimiters. It is extremely important that manually correcting the layout and layout of the table before the first or repeated recognition is always easier than correcting the incorrect structure of the text after recognition - in FineReader or even after saving, in the target application. So in the "Workshop" section, I will give a lot of real life examples of error correction for automatic table layout.- The picture area - may have a non-rectangular shape. It has two varieties - regular (crowds out the column text) and background (doesn't crowd out the column text), they have slight differences when drawing (for example, stretching the background image does not delete the text areas covered by it).
- Barcode Area — Contains a barcode of an autodetectable or explicitly specified type. Like a picture, it can have a non-rectangular shape, although this is rarely necessary.
Important considerations
- Recognition and synthesis are visible only to those fragments of the text that are highlighted in the text areas or text cells of the tables. If a piece of text is not selected in blocks, it will not be recognized.
- Similarly with pictures - if part of the picture is outside the area or one whole picture is divided into several areas - most likely, there will be problems as a result of processing.
- Recognition languages in FineReader are not set for a tick - they affect a lot of mechanisms, starting with analysis: for example, hieroglyphic (Chinese, Japanese, Korean) or Arabic text have many features that are not always taken into account, but only when choosing the appropriate languages recognition.
Features of the interaction of nearby or intersecting areas
The following rules are important both for the correct handling of areas in the program shell and for understanding what happens to them in the recognition and saving results.
- The intersection of text and table blocks with each other , if there are characters or their parts that appear in more than one block is almost always an error , such analysis results need to be corrected, especially since this is usually done with several mouse movements.
The intersection of picture areas with each other is almost always a mistake, although less critical for processing text. Such cases are also desirable to correct. - The picture area against the background of a larger text area is a legitimate and often demanded combination. The main application is the processing of so-called inline images when a fragment (pictogram, formula or part of it, etc.) occurs within a line (which is poorly recognized or not recognized at all in the text model used in FineReader).

 Examples of proper use of images in a tableОбратите внимание, что с помощью галочки в панели свойств области (внизу) ячейки из левой колонки таблицы сделаны картинками.
Examples of proper use of images in a tableОбратите внимание, что с помощью галочки в панели свойств области (внизу) ячейки из левой колонки таблицы сделаны картинками.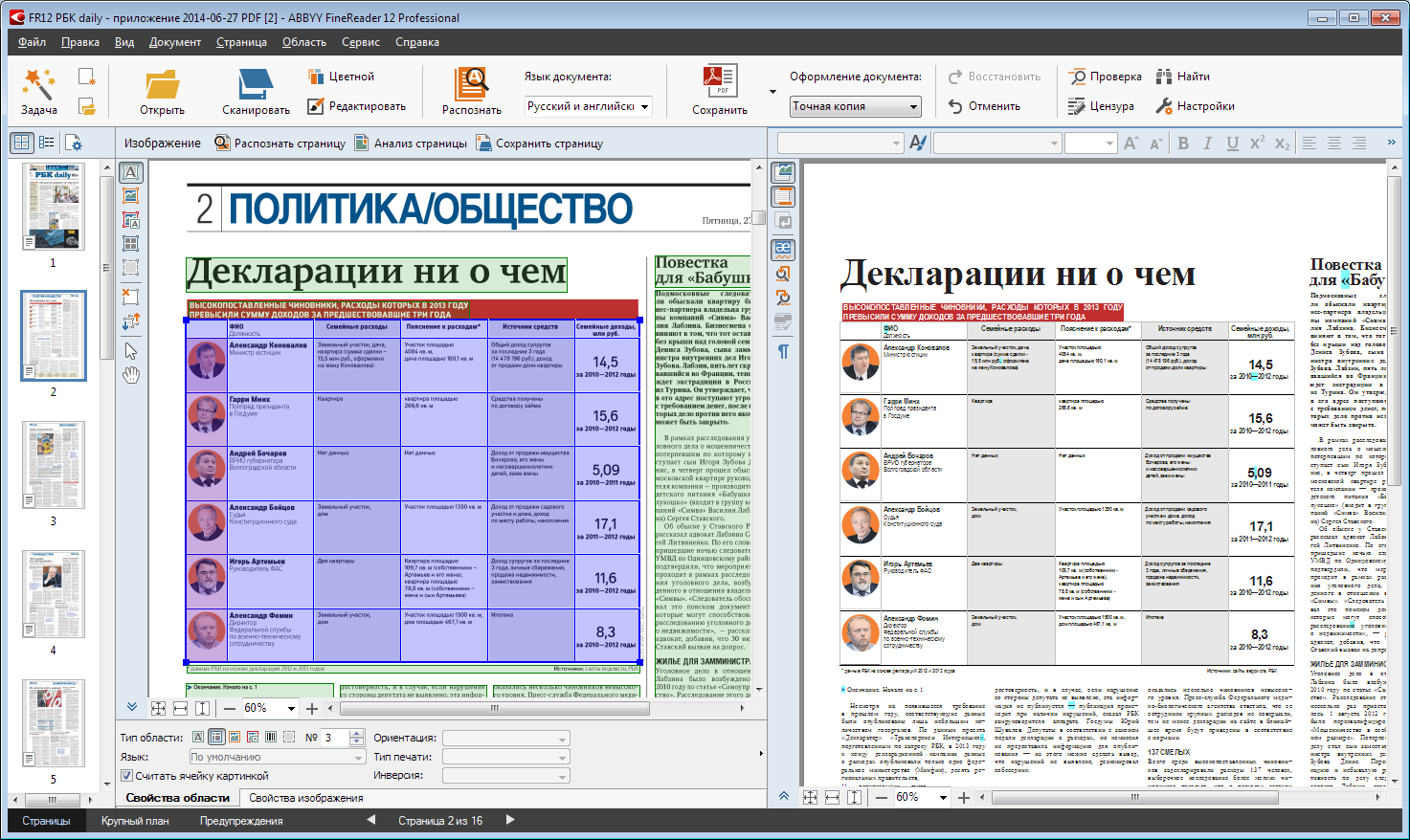
The text area against the background of the "picture" area is also an important tool: against the background of the usual picture areas, there may be signatures to them, on the "background" picture areas can be located the main ("column") text of the document, as well as the table.Examples of the correct use of text areas on the background of pictures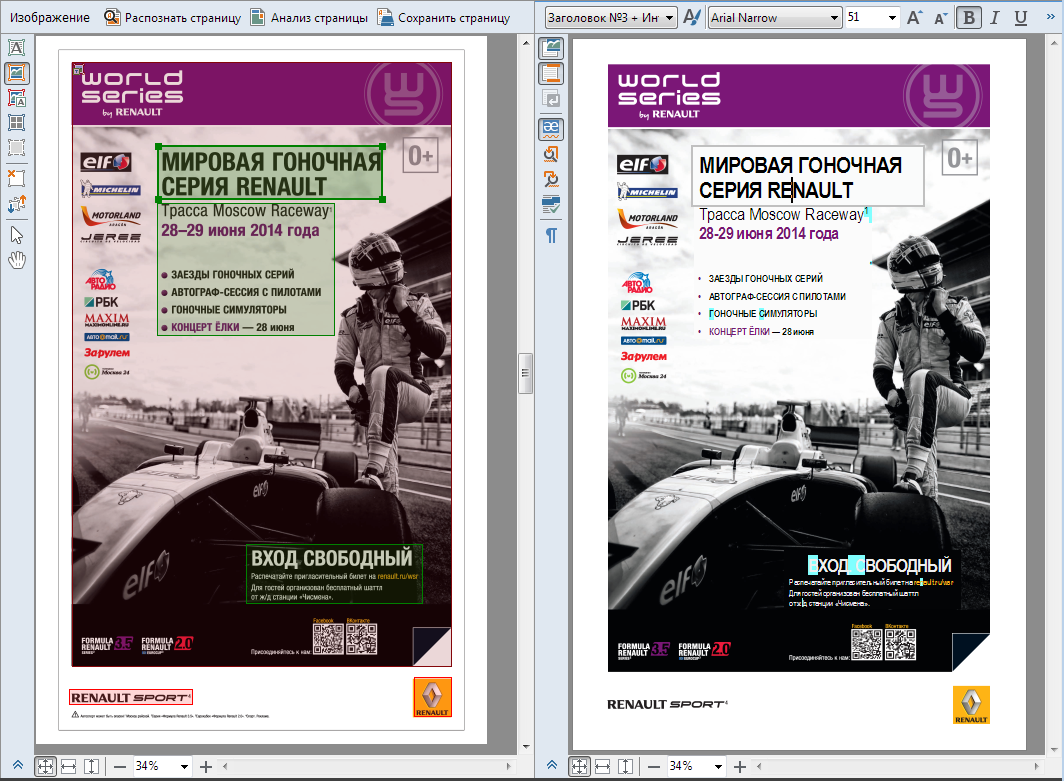
Little tricks to make working with blocks easier
The described conventions are reflected in the behavior of the block editor. For example, if you draw a new one or stretch an existing block so that it completely or almost completely overlaps other blocks, these other blocks are automatically deleted.Logic / inconsistent allocation of areas
Here is the time to think - for what purposes and what format the document you want to receive as a result of processing. Here are some considerations that affect the number and nature of block layout corrections in complex cases:Option 1: we only need the text (perhaps we do not understand this, but this is the case)
If you need to save a document in PDF with images of pages of the original document and added “invisible” recognized text (for searching and copying it), then the main thing is to ensure a reasonable selection of text in text and table blocks. By "rationality" is meant the following:- there are no “garbage” areas where elements of pictures or page design elements are recognized (as garbage) as text or tables.
- areas logically highlight lines, preventing characters from entering more than one area and unjustifiably splitting lines into more than one area.
- that, from the point of view of man, is the tables in the original, should be highlighted in the table areas. This affects both the quality of recognition (for example, the base lines of lines in different cells may not be aligned vertically), and the convenience of finding and copying text fragments in the output document.
If individual images should not be copied from the output PDF-document, then such areas can be excluded from the document at all (do not create new ones and do not leave the ones found automatically, at least remove the illogically found images, and if not laziness - that's all).
I hope to expand the topic of “rationality” of images in a article about the preservation of documents more widely and deeper - if this is of interest to readers of this material.Option 2: you need everything at once
If a document that includes more than one text content (in one or two columns) is supposed to be saved immediately as an e-book in FB2 / e-pub formats or in any intermediate editable format (Word or HTML) for further editing and production of the e-book, then The meaningful selection of tables and pictures becomes especially important.
Among other things, you need to decide what to do with the groups of adjacent pictures, and what to do with the captions to the pictures, both standing side by side and overlapping with the pictures. We will analyze this topic in more detail in the "Workshop", using real examples.Something like the conclusion of this part
So, we now imagine how to deal with incorrectly allocated blocks, which in really difficult cases from the point of view of our technologies really complicate life.
Of course, FineReader is great, so the user does not know at least something in it. Therefore, we will return to this topic in a separate "Workshop". If readers show interest, of course :)