Using Consul to scale stateful services
September 22 held our first non-standard mitap for developers of high-load systems. It was very cool, a lot of positive feedback on the reports and therefore decided not only to put them, but also to decipher for Habr. Today we publish the speech of Ivan Bubnov, DevOps from the company BIT.GAMES. He spoke about the implementation of the Consul discovery service in an already working high-load project to enable fast scaling and failover of stateful services. And also about the organization of a flexible namespace for backend applications and pitfalls. Now a word to Ivan.
I administer the production infrastructure in the studio BIT.GAMES and tell the story of the introduction of the consul from Hashicorp to our project “Guild of Heroes” - a fantasy RPG with asynchronous pvp for mobile devices. We are released on Google Play, App Store, Samsung, Amazon. DAU about 100,000, online from 10 to 13 thousand. We make the game on Unity, so we write the client in C # and use our own scripting language BHL for game logic. We write server part on Golang (passed to it from PHP). Next is the schematic architecture of our project.

In fact, there are much more services, here are just the basics of game logic.
So, what we have. From stateless services it is:
From Stateful services, the main ones here are:
In the design process, we (like everyone) hoped that the project would be successful and provided for a sharding mechanism. It consists of two entities of the MAINDB databases and shards themselves.

MAINDB is a kind of table of contents - it stores information about the specific shard where the player's progress data is stored. Thus, the complete chain of information retrieval looks like this: the client turns to the frontend, who in turn redistributes it according to the weighting factor to one of the backends, the backend goes to MAINDB, localizes the player's shard, and then samples the data of the shard itself.
But when we designed, we were not a big project, so we decided to make shards shards only nominally. They were all on the same physical server, and most likely it is database partitioning within a single server.
For backup, we used classic master slave replication. It was not a very good solution (I will say why a bit later), but the main disadvantage of that architecture was that all our backends knew about other backend services only by IP addresses. And in the case of another ridiculous accident in a data center like “ I'm sorry, our engineer touched the cable on your server while servicing the other one and we figured it out for a long time, why didn’t your server get in touch“We needed a lot of gestures. First, it is a reassembly and desalivac backend'ov with IP backup server for the place of the one that failed. Secondly, after the incident, it is necessary to restore from the backup'a from the reserve our master, because he was in an inconsistent state and bring it into a consistent state by the means of the same replication. After that, we rebuilt the backends again and perezaliv again. All this, of course, caused downtime.
The moment came when our technical director (for which he thanks a lot) said: “Guys, stop suffering, we need to change something, let's look for ways out.” First of all, we wanted to achieve a simple, understandable, and most importantly - an easily managed process of scaling and migration from place to place of our databases if necessary. In addition, we wanted to achieve high availability by automating failover.
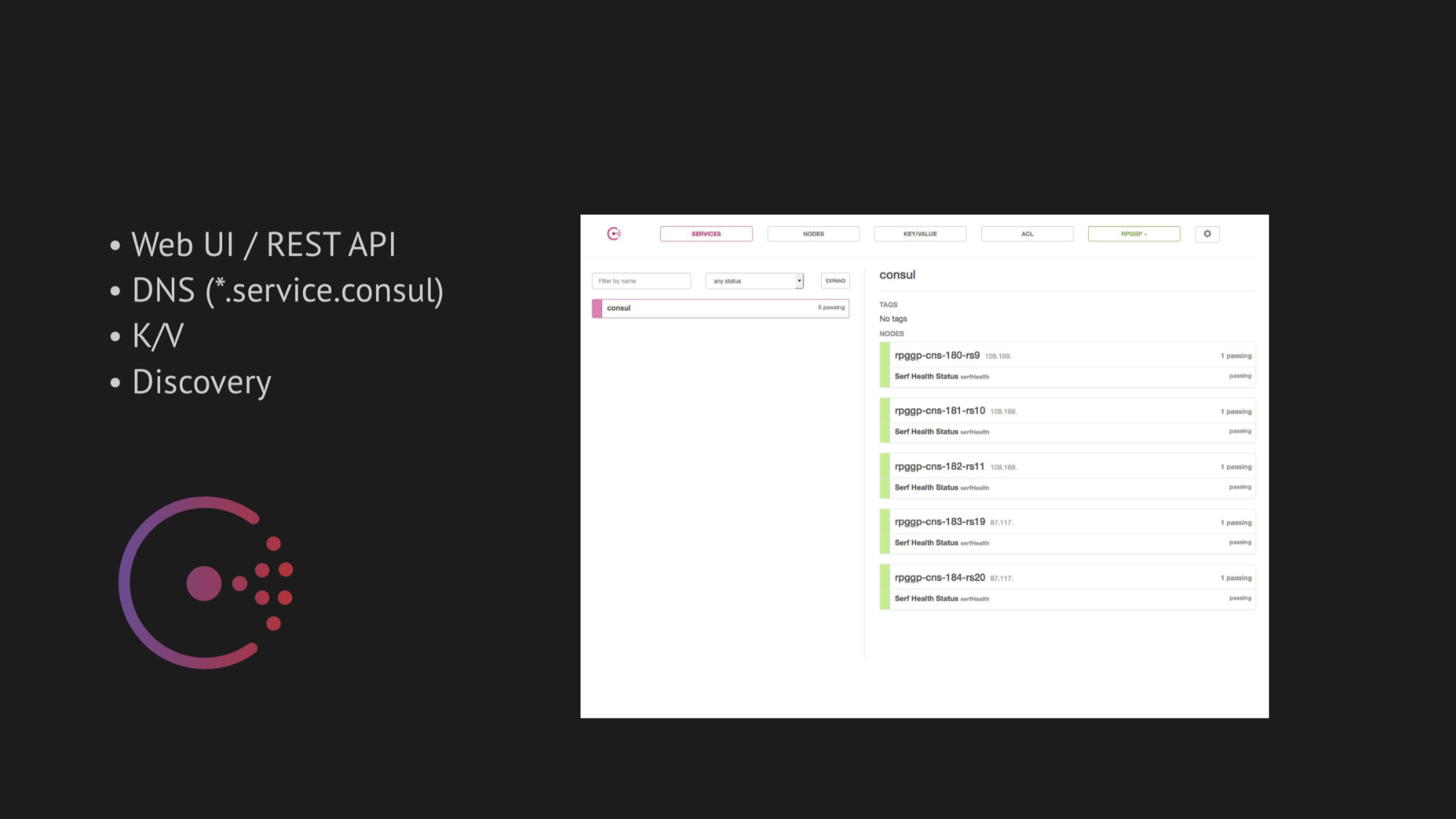
The central axis of our research was Consul from Hashicorp. First, we were advised to do it, and secondly, we were very attracted by its simplicity, friendliness and excellent technology stack in one box: discovery service with healthchecks, key-value storage and the most important thing we wanted to use is DNS, which would rezolvil us addresses from the domain service.consul.
Consul also provides excellent Web UI and REST APIs to manage all of this.
As for high availability, we chose two utilities for auto-failover:

In the case of MHA for MySQL, we poured agents onto nodes with databases, and they monitored their state. There was a certain timeout for the master Fail, after which a stop slave was made to maintain consistency and our backup master from the appeared master in a non-consistent state did not take the data. And we added a web hook to these agents, who registered there a new IP backup master in Consul itself, after which it got into the DNS issue.
With Redis-sentinel everything is even easier. Since he himself does the lion’s share of the work, all that remained for us to do was to take into account in healthcheck that the Redis-sentinel should take place exclusively at the master node.
At first everything worked fine, like a clock. We didn’t have any problems on the test bench. But it was worth moving to the natural data transfer environment of the loaded data center, remembering some OOM-killʻahs (this is out of memory, in which the process is killed by the system core) and restoring the service or more sophisticated things that affect the availability of the service. as we immediately received a serious risk of false positives or the lack of a guaranteed response at all (if, in an attempt to escape from false positives, we twist some checks).

First of all, everything depends on the difficulty of writing correct healthchecks. It seems that the task is rather trivial - check that the service is running on your server and pingani port. But, as further practice has shown, writing a healthcheck when implementing Consul is an extremely complex and time-distributed process. Because so many factors that affect the availability of your service in the data center, it is impossible to foresee - they are detected only after a certain time.
In addition, the data center is not a static structure into which you have filled in and it works as intended. But we, unfortunately (or fortunately), learned about this only later, but for now we were inspired and full of confidence that we would implement everything in production.

As for scaling, I will say briefly: we tried to find a finished bike, but they are all designed for specific architectures. And, as in the case of Jetpants, we could not meet the conditions that he imposed on the architecture of a persistent storage of information.
Therefore, we thought about our own script binding and postponed this question. We decided to act consistently and start with the implementation of Consul.

Consul is a decentralized, distributed cluster that operates based on the gossip protocol and the Raft consensus algorithm.
We have an independent equorum of five servers (five to avoid a split-brain situation). For each node, we pour the Consul agent in agent mode and spill all healthchecks (that is, there was no such thing that we fill some healthchecks with a specific server and others with certain servers). Healthcheck'i were written so that they pass only where there is a service.
We also used another utility to avoid having to learn from your backend to rezolvit addresses from a specific domain on a non-standard port. We used Dnsmasq - it provides the ability to completely transparently resolve to the cluster nodes those addresses that we need (which, in the real world, do not exist, so to say, but only exist within the cluster). We prepared an automatic script for uploading to Ansible, filled it all into production, flipped the namespace, made sure that everything was complete. And, fingers crossed, perezalili our backend'y, which are no longer addressed by ip-addresses, but by these names from the server.consul domain.
It all started the first time, our joy knew no bounds. But it was too early to rejoice, because within an hour we noticed that on all the nodes where our backends are located, the load average rate increased from 0.7 to 1.0, which is quite a bold figure.
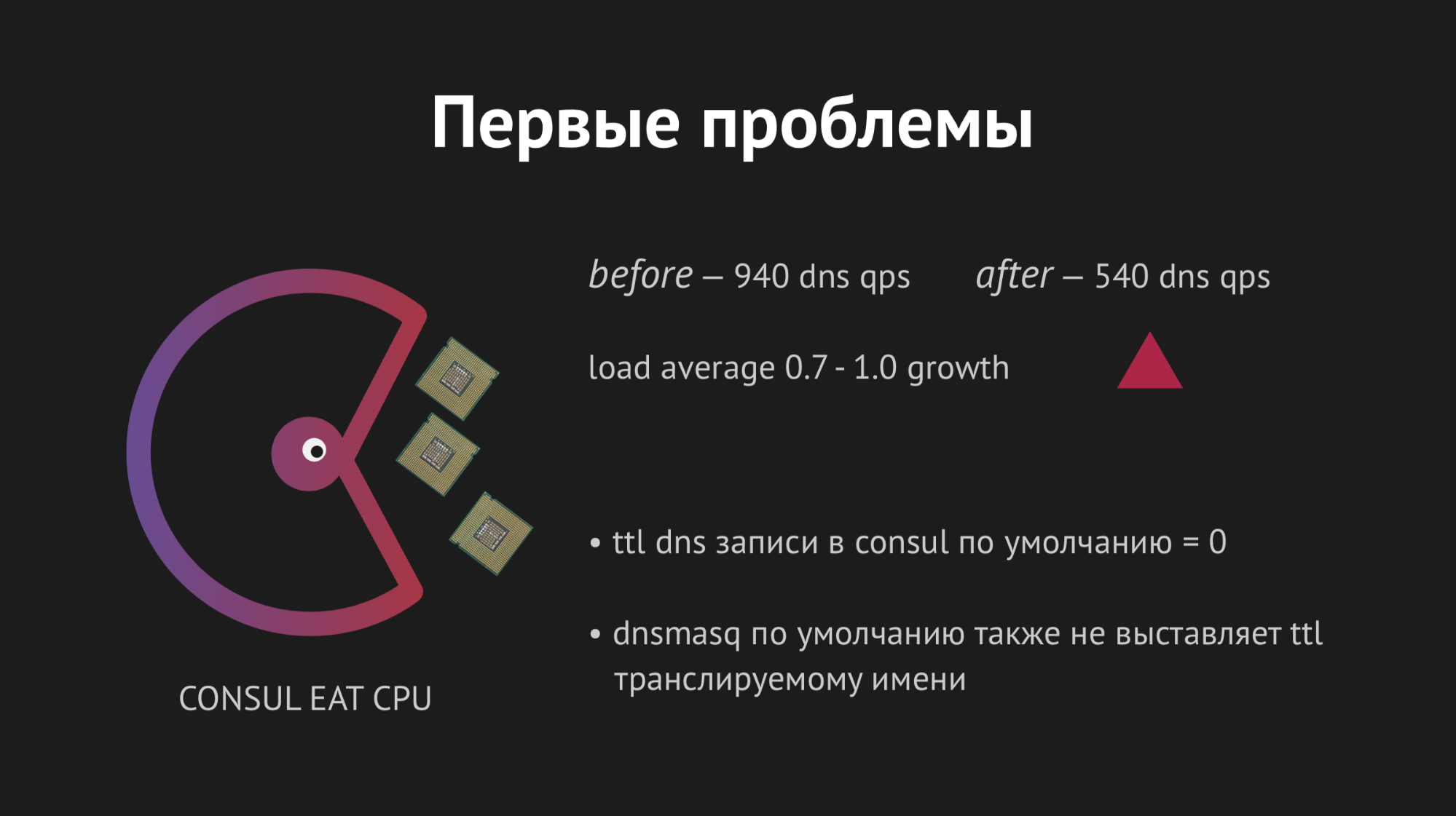
I climbed to the server to watch what was happening and it became obvious that the CPU was eating Consul. Here we started to understand, began to shaman with strace (a utility for unix-systems that allows you to track which syscall the process performs), reset the Dnsmasq statistics to understand what is going on at this node and it turned out that we missed a very important point. Planning the integration, we missed the caching of DNS records and it turned out that our backend was tugging at Dnsmasq for each of its body movements, and that in turn addressed the Consul and it all spilled into unhealthy 940 DNS requests per second.
The solution seemed obvious - just twist ttl and everything will be fine. But it was impossible to be fanatical here, because we wanted to introduce this structure in order to get a dynamic, easily manageable and fast-changing namespace (so we could not, for example, put 20 minutes). We unscrewed the ttl to the limit for our optimal values, managed to reduce the rate of requests per second to 540, but this had no effect on the CPU consumption.
Then we decided to get out in a cunning way, using the custom hosts-file.
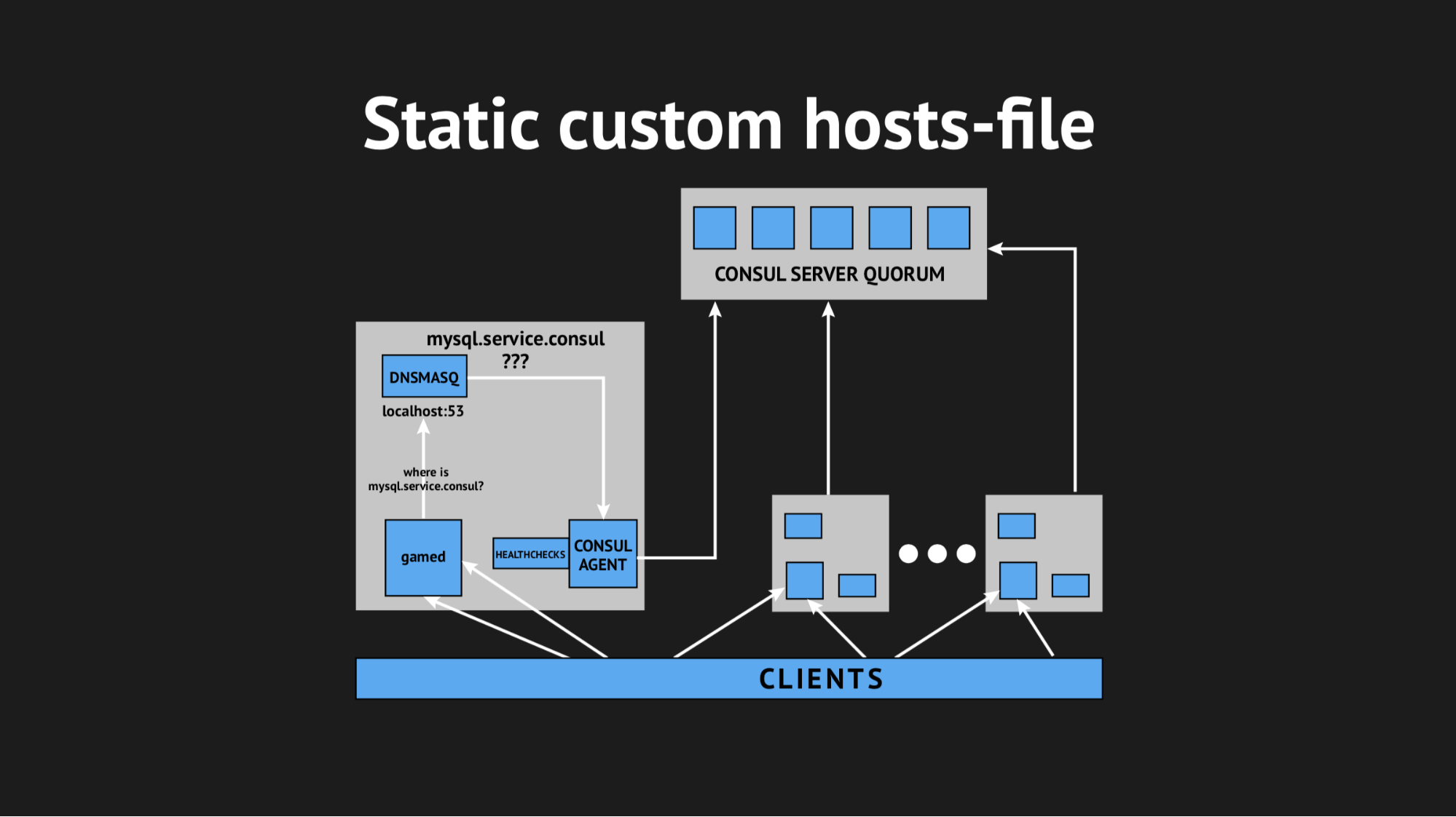
It’s good that we had everything for this: a beautiful Consul template system that generates a file of any kind based on the cluster status and template script, any config file — whatever you want. In addition, Dnsmasq has a configuration parameter addn-hosts, which allows you to use non-system hosts file as the same additional hosts file.
What we did, again prepared the script in Ansible, poured it into production and it began to look something like this:
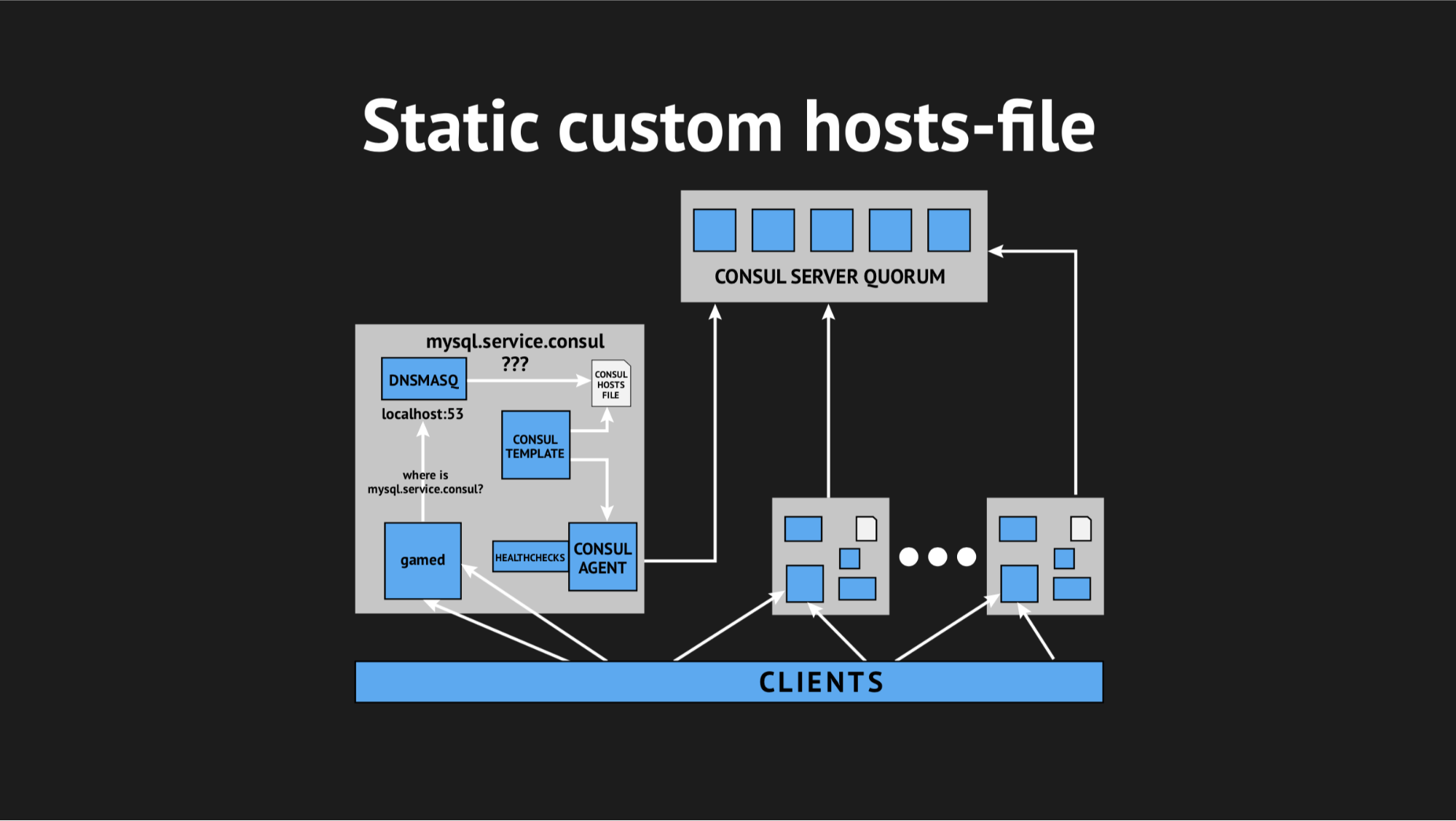
There was an additional element and a static file on the disk, which is rather quickly regenerated. Now the chain looked quite simple: gamed refers to Dnsmasq, and that in turn (instead of pulling the Consul-agent, who will ask the servers where we have this or that node) just watched the file. This solved the problem with the consumption of CPU Consul.
Now everything began to look like we planned - absolutely transparent for our production, practically without consuming resources.
We were pretty much tortured that day and went home in great fear. They were not afraid in vain, because at night I was awakened by an alert from monitoring and informed that we had a rather large-scale (albeit short-lived) surge of errors.
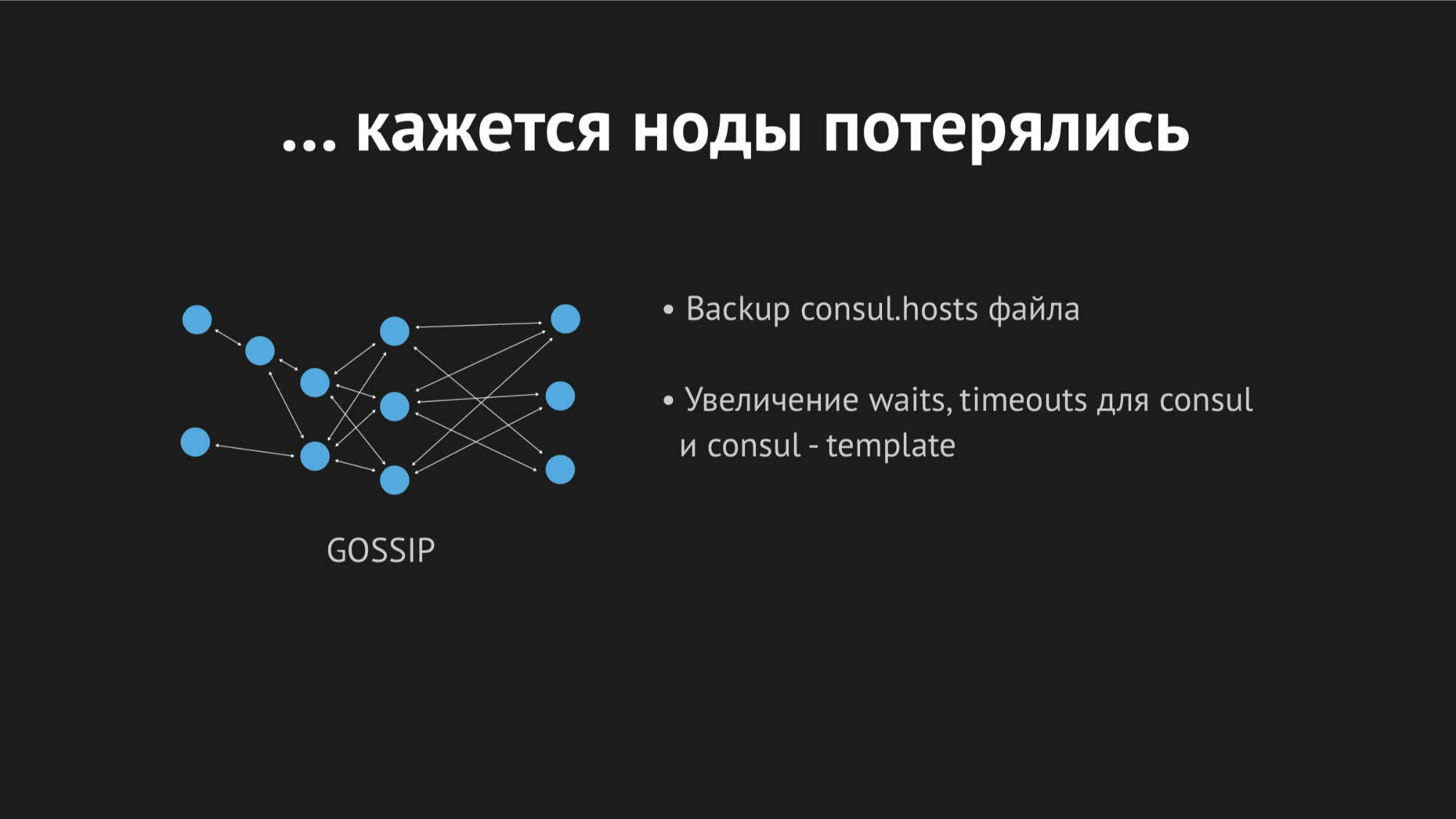
Understanding logs in the morning, I saw that all the errors of the same kind are unknown host. It was not clear why Dnsmasq could not kill one service or another from a file — the feeling that it does not exist at all. To try to understand what is happening, I added a custom metric for file re-migration — now I knew for sure when it would be regenerated. In addition, in the Consul template itself there is an excellent backup option, i.e. You can see the previous state of the regenerated file.
During the day, the incident repeated several times and it became clear that at some point in time (although it was sporadic, unsystematic), the hosts file without specific services was re-generated. It turned out that in a specific data center (I will not do anti-advertising) rather unstable networks - because of the network flopping, we completely unpredictably stopped going through healthcheck, or even nodes fell out of the cluster. It looked like this:
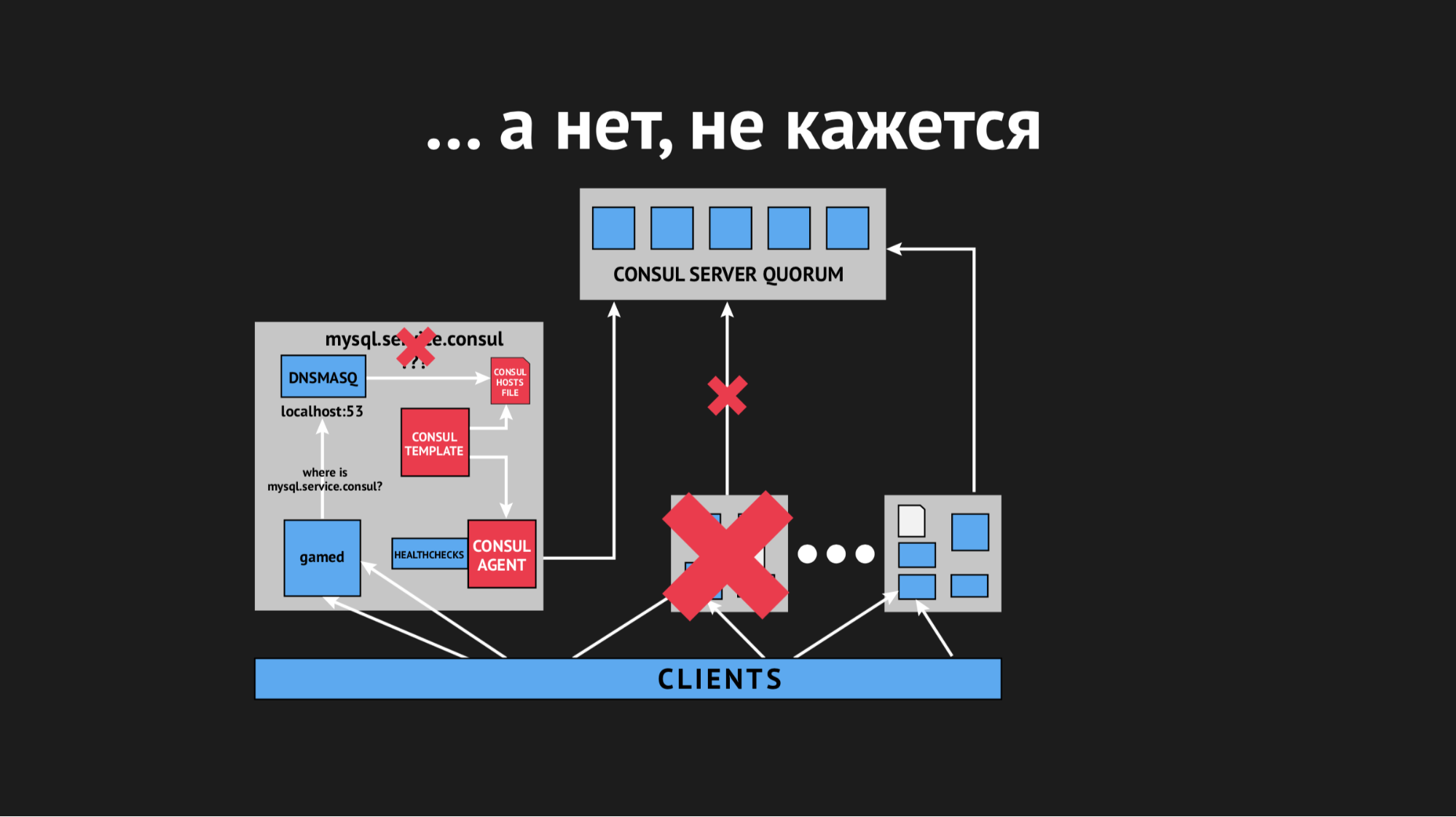
The node fell out of the cluster, the Consul agent was immediately notified about this, and the Consul template immediately regenerated the hosts file without the required service. It was generally unacceptable, because the problem is ridiculous: if the service is unavailable for a few seconds, the mood is timeouts and retracts (they did not connect once, and the second time it happened). We, however, have provoked a situation in the sales department when the service simply disappears from view and there was no possibility to connect to it.
We started to think what to do with this and turn the timeout parameter into Consul, after which it is identified after how long the node falls out. We managed to solve this problem with a rather small indicator, the nodes stopped falling out, but with healthcheck this did not help.
We started thinking about selecting different parameters for healthchecks, trying to somehow understand when and how this happens. But due to the fact that everything happened sporadically and unpredictably, we could not do it.
Then we went to the Consul template and decided to make a timeout for it, after which it reacts to a change in the cluster state. Again, it was impossible to be fanatical here, because we could come to a situation where the result would be no better than the classical DNS, when we were striving for a completely different one.
And here our technical director once again came to the rescue and said: “Guys, let's try to abandon all this interactivity, we are all in production and there is no time for research, we need to solve this issue. Let's use simple and understandable things. ” So we came to the concept of using the key-value repository as a source for generating the hosts file.
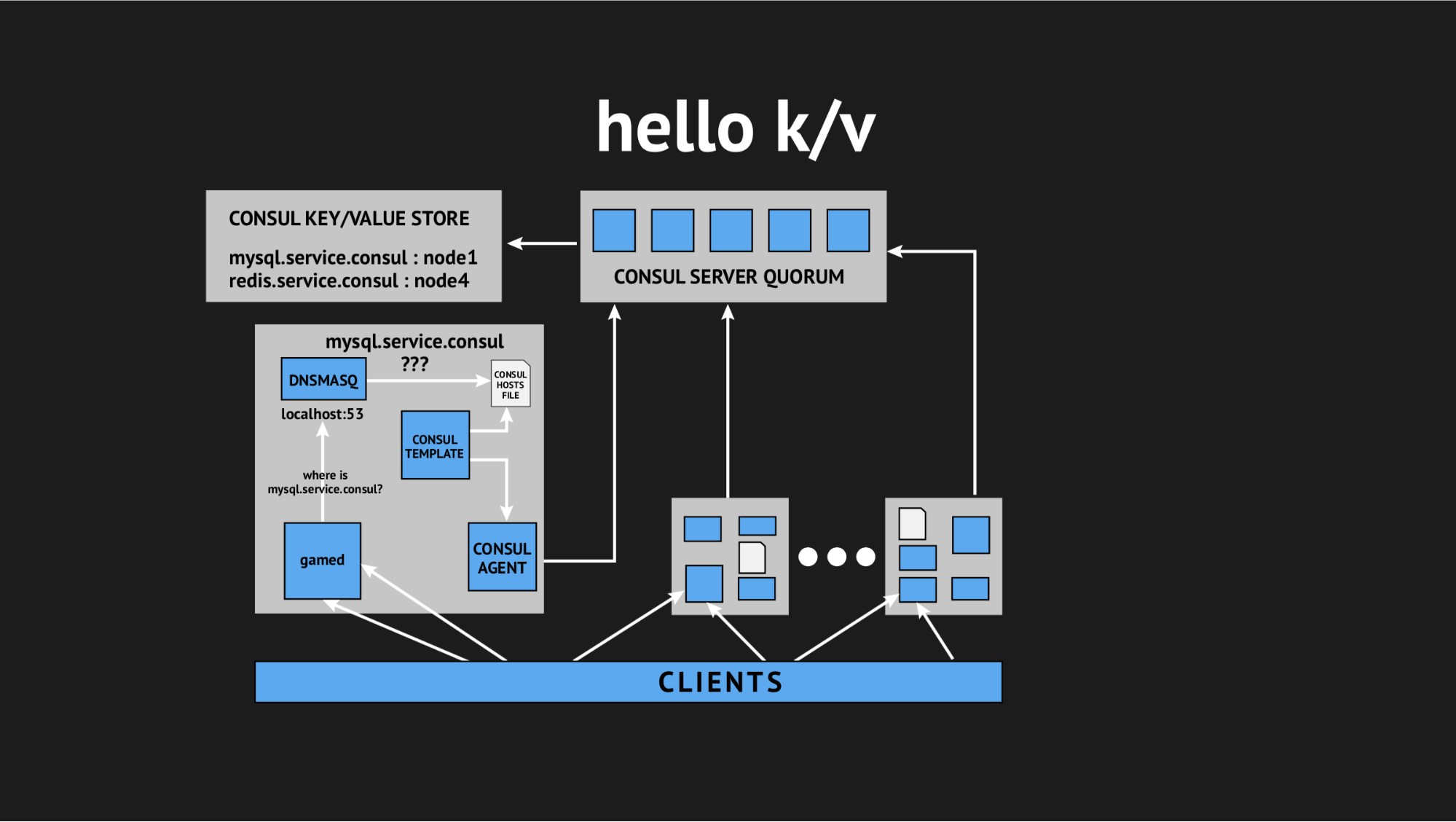
What it looks like: we abandon all dynamic healthchecks, rewrite our template script to generate a file based on the data stored in the key-value storage. In the key-value store, we describe our entire infrastructure as a key name (this is the name of the service we need) and key values (this is the name of the node in the cluster). Those. if the node is present in the cluster, then we very easily get its IP address and write it to the hosts file.
We all tested, poured into production, and it became a silver bullet in a particular situation. Again, we were pretty much tortured for the whole day, and we went home, but returned already rested, inspired, because these problems did not recur any more and did not recur for a year. From which I personally conclude that this was the right decision (specifically for us).
So. We finally achieved what we wanted and organized a dynamic namespace for our backend. Then we went towards high availability.

But the fact is that pretty frightened by the integration of Consul and because of the problems we faced, we thought and decided that implementing auto-failover is not such a good solution, because we again risk false positives or failures. This process is opaque and uncontrollable.
Therefore, we chose a simpler (or more complicated) way: we decided to leave failover on the conscience of the duty administrator, but gave him another additional tool. We replaced the master slave replication with the master replication in Read only mode. This removes a huge amount of headaches in the failover process — when you drop out of the wizard, all you have to do is change the value in the k / v storage using the Web UI or the command in the API and remove Read only to backup wizard.
After the incident has been settled, the wizard comes into contact and automatically comes to a consistent state without any unnecessary actions at all. We stopped at this option and use it as before - for us it is as convenient as possible, and most importantly as simple as possible, understandable and controllable.
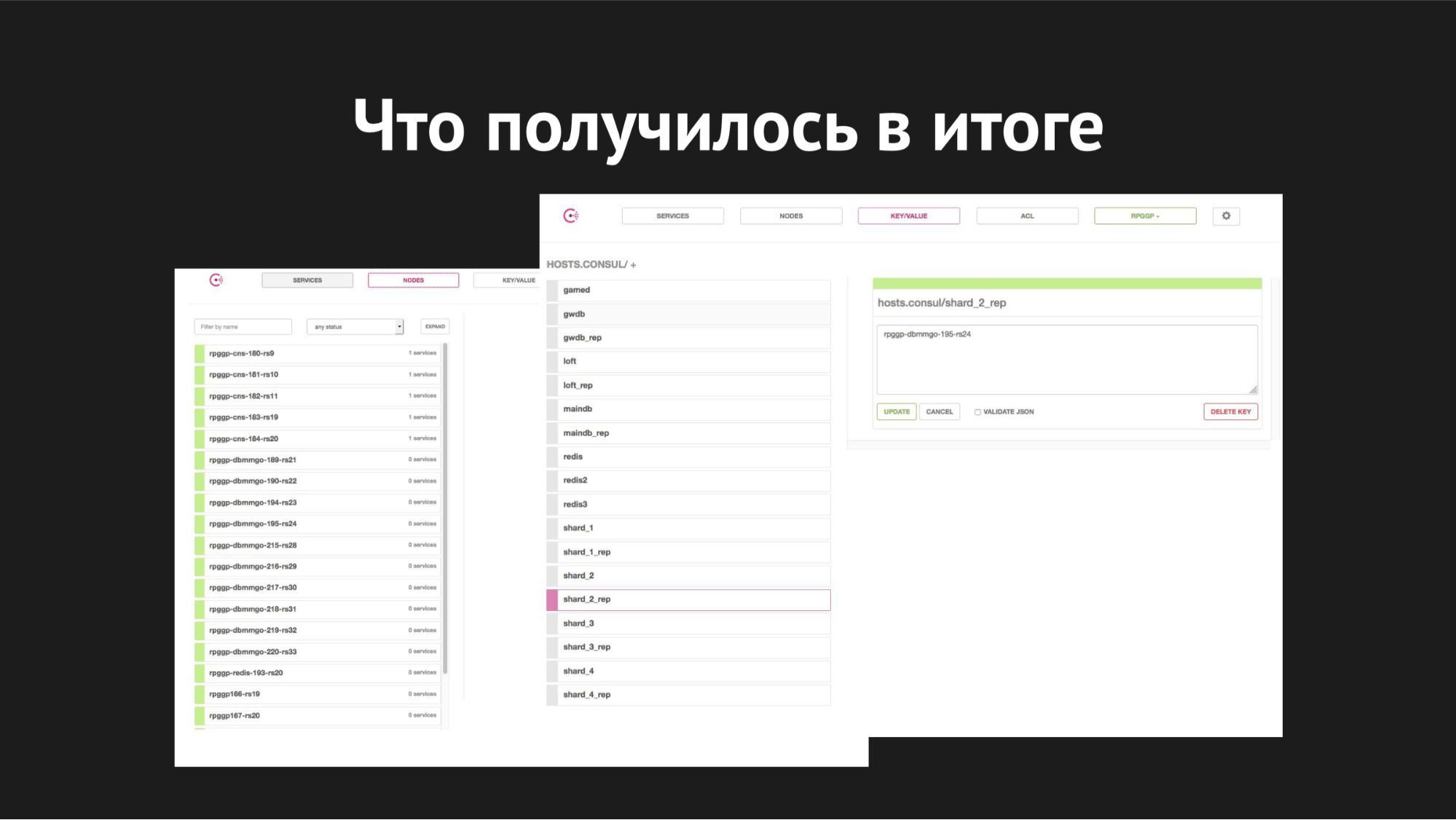
The Consul web interface
On the right, k / v storage is shown and our services are visible, which we use in the gamed operation; value is the name of the node.
As for scaling, we started to implement it when shards became crowded on one server, the bases grew, became slow, the number of players increased, we swapped and we were faced with the task of dissolving all shards on our own separate servers.

What it looked like: using the XtraBackup utility, we restored our backup on a new pair of servers, after which the new master was hung up as a slave to the old one. It came in a consistent state, we changed the key value in the k / v-storage from the name of the node of the old master to the name of the node of the new master. Then (when we thought that everything went correctly and all gamed with its selects, updates, inserts went to the new master), all that was needed was to kill replication and make the coveted drop database production, as we all like to do with unnecessary databases.

In this way, we got sharpened shards. The whole process of moving took from 40 minutes to an hour and did not cause any downtime, was completely transparent for our backends and was itself completely transparent for the players (except that as soon as they moved, it became easier and more pleasant for them to play).

As for the failover processes, here the switching time is from 20 to 40 seconds plus the response time of the system administrator on duty. That's about it now it looks like with us.
So that I would like to say in conclusion - unfortunately, our hopes for absolute, comprehensive automation broke about the harsh reality of the data transmission environment in the loaded data center and random factors that we could not foresee.
Secondly, it once again taught us that a simple and proven bird in the hands of your sysadmin is better than a newfangled, self-reactive, self-scaling crane somewhere behind the clouds, that you don’t even understand if it’s falling apart, or really began to scale.
The introduction of any infrastructure, automation in your production should not cause an extra headache for the staff that serves it; it should not significantly increase the cost of maintaining the production of infrastructure - the solution should be simple, clear, transparent for your customers, convenient and controllable.
How do you write k / v with servers - a script or do you just patch it?
We have K / v-storage on our Consul-servers and either remove something from there or replenish it with the help of http-requests RESTful API or Web UI.
I wanted to convey with this report that now, for some reason, the ideology of automating everything in the world with fierce fanaticism very often pursues without understanding that this sometimes complicates life and does not simplify.
Why do you balance between shards through databases, why not the same Redis?
This is a historically established decision and I forgot to say that now the concept has changed a little bit.
First, we have taken out the configs and now we do not need to re-fill the backend. Secondly, we have entered the parameter into the backends themselves, which is the main sharding link - that is, they distribute the players. Those. if we have a new player entity, he makes an entry in MAINDB and then saves the data on the shard he chose. And now he chooses it by weights. And it is very quickly and easily controlled and at the moment there is no need to take and use some other technology, because it all works quickly now.
But if we run into some kind of problem, then perhaps it will be better to use a fast inmemory key-value repository or something else.
What is your base?
We use MySQL fork - Percona server.
And you did not try to combine it into a cluster and due to this balance? If you had Maria, which is the same MHA for MySQL, he has Galera.
We had in service with Galera. There was another data center for the project “Guild of Heroes” for Asia and there we used Galera and it often gives a very unpleasant failure, it needs to be lifted up by hand from time to time. Having such experience of using this technology specifically, we still do not really want to use it.
Again, it should be understood that the introduction of any technology is not just because you want to do better, but because you have a need for it, you need to get out of some existing situation, or you have already predicted that the situation will happen soon and You choose a specific technology to implement.
I administer the production infrastructure in the studio BIT.GAMES and tell the story of the introduction of the consul from Hashicorp to our project “Guild of Heroes” - a fantasy RPG with asynchronous pvp for mobile devices. We are released on Google Play, App Store, Samsung, Amazon. DAU about 100,000, online from 10 to 13 thousand. We make the game on Unity, so we write the client in C # and use our own scripting language BHL for game logic. We write server part on Golang (passed to it from PHP). Next is the schematic architecture of our project.
In fact, there are much more services, here are just the basics of game logic.
So, what we have. From stateless services it is:
- nginx, which we use in the role of Frontend and Load Balancers, and according to the weighting factors, we distribute clients to our backends;
- gamed - backend'y, compiled applications from Go. This is the central axis of our architecture, they do the lion's share of the work and are associated with all the other backend services.
From Stateful services, the main ones here are:
- Redis, which we use to cache “hot” information (we also use it to organize in-game chat and store notifications for our players);
- Percona Server for Mysql is a repository of persistent information (probably the biggest and most unwieldy in any architecture). We use MySQL fork and here we will talk about it today in more detail.
In the design process, we (like everyone) hoped that the project would be successful and provided for a sharding mechanism. It consists of two entities of the MAINDB databases and shards themselves.
MAINDB is a kind of table of contents - it stores information about the specific shard where the player's progress data is stored. Thus, the complete chain of information retrieval looks like this: the client turns to the frontend, who in turn redistributes it according to the weighting factor to one of the backends, the backend goes to MAINDB, localizes the player's shard, and then samples the data of the shard itself.
But when we designed, we were not a big project, so we decided to make shards shards only nominally. They were all on the same physical server, and most likely it is database partitioning within a single server.
For backup, we used classic master slave replication. It was not a very good solution (I will say why a bit later), but the main disadvantage of that architecture was that all our backends knew about other backend services only by IP addresses. And in the case of another ridiculous accident in a data center like “ I'm sorry, our engineer touched the cable on your server while servicing the other one and we figured it out for a long time, why didn’t your server get in touch“We needed a lot of gestures. First, it is a reassembly and desalivac backend'ov with IP backup server for the place of the one that failed. Secondly, after the incident, it is necessary to restore from the backup'a from the reserve our master, because he was in an inconsistent state and bring it into a consistent state by the means of the same replication. After that, we rebuilt the backends again and perezaliv again. All this, of course, caused downtime.
The moment came when our technical director (for which he thanks a lot) said: “Guys, stop suffering, we need to change something, let's look for ways out.” First of all, we wanted to achieve a simple, understandable, and most importantly - an easily managed process of scaling and migration from place to place of our databases if necessary. In addition, we wanted to achieve high availability by automating failover.
The central axis of our research was Consul from Hashicorp. First, we were advised to do it, and secondly, we were very attracted by its simplicity, friendliness and excellent technology stack in one box: discovery service with healthchecks, key-value storage and the most important thing we wanted to use is DNS, which would rezolvil us addresses from the domain service.consul.
Consul also provides excellent Web UI and REST APIs to manage all of this.
As for high availability, we chose two utilities for auto-failover:
- MHA for MySQL
- Redis-sentinel
In the case of MHA for MySQL, we poured agents onto nodes with databases, and they monitored their state. There was a certain timeout for the master Fail, after which a stop slave was made to maintain consistency and our backup master from the appeared master in a non-consistent state did not take the data. And we added a web hook to these agents, who registered there a new IP backup master in Consul itself, after which it got into the DNS issue.
With Redis-sentinel everything is even easier. Since he himself does the lion’s share of the work, all that remained for us to do was to take into account in healthcheck that the Redis-sentinel should take place exclusively at the master node.
At first everything worked fine, like a clock. We didn’t have any problems on the test bench. But it was worth moving to the natural data transfer environment of the loaded data center, remembering some OOM-killʻahs (this is out of memory, in which the process is killed by the system core) and restoring the service or more sophisticated things that affect the availability of the service. as we immediately received a serious risk of false positives or the lack of a guaranteed response at all (if, in an attempt to escape from false positives, we twist some checks).
First of all, everything depends on the difficulty of writing correct healthchecks. It seems that the task is rather trivial - check that the service is running on your server and pingani port. But, as further practice has shown, writing a healthcheck when implementing Consul is an extremely complex and time-distributed process. Because so many factors that affect the availability of your service in the data center, it is impossible to foresee - they are detected only after a certain time.
In addition, the data center is not a static structure into which you have filled in and it works as intended. But we, unfortunately (or fortunately), learned about this only later, but for now we were inspired and full of confidence that we would implement everything in production.
As for scaling, I will say briefly: we tried to find a finished bike, but they are all designed for specific architectures. And, as in the case of Jetpants, we could not meet the conditions that he imposed on the architecture of a persistent storage of information.
Therefore, we thought about our own script binding and postponed this question. We decided to act consistently and start with the implementation of Consul.
Consul is a decentralized, distributed cluster that operates based on the gossip protocol and the Raft consensus algorithm.
We have an independent equorum of five servers (five to avoid a split-brain situation). For each node, we pour the Consul agent in agent mode and spill all healthchecks (that is, there was no such thing that we fill some healthchecks with a specific server and others with certain servers). Healthcheck'i were written so that they pass only where there is a service.
We also used another utility to avoid having to learn from your backend to rezolvit addresses from a specific domain on a non-standard port. We used Dnsmasq - it provides the ability to completely transparently resolve to the cluster nodes those addresses that we need (which, in the real world, do not exist, so to say, but only exist within the cluster). We prepared an automatic script for uploading to Ansible, filled it all into production, flipped the namespace, made sure that everything was complete. And, fingers crossed, perezalili our backend'y, which are no longer addressed by ip-addresses, but by these names from the server.consul domain.
It all started the first time, our joy knew no bounds. But it was too early to rejoice, because within an hour we noticed that on all the nodes where our backends are located, the load average rate increased from 0.7 to 1.0, which is quite a bold figure.
I climbed to the server to watch what was happening and it became obvious that the CPU was eating Consul. Here we started to understand, began to shaman with strace (a utility for unix-systems that allows you to track which syscall the process performs), reset the Dnsmasq statistics to understand what is going on at this node and it turned out that we missed a very important point. Planning the integration, we missed the caching of DNS records and it turned out that our backend was tugging at Dnsmasq for each of its body movements, and that in turn addressed the Consul and it all spilled into unhealthy 940 DNS requests per second.
The solution seemed obvious - just twist ttl and everything will be fine. But it was impossible to be fanatical here, because we wanted to introduce this structure in order to get a dynamic, easily manageable and fast-changing namespace (so we could not, for example, put 20 minutes). We unscrewed the ttl to the limit for our optimal values, managed to reduce the rate of requests per second to 540, but this had no effect on the CPU consumption.
Then we decided to get out in a cunning way, using the custom hosts-file.
It’s good that we had everything for this: a beautiful Consul template system that generates a file of any kind based on the cluster status and template script, any config file — whatever you want. In addition, Dnsmasq has a configuration parameter addn-hosts, which allows you to use non-system hosts file as the same additional hosts file.
What we did, again prepared the script in Ansible, poured it into production and it began to look something like this:
There was an additional element and a static file on the disk, which is rather quickly regenerated. Now the chain looked quite simple: gamed refers to Dnsmasq, and that in turn (instead of pulling the Consul-agent, who will ask the servers where we have this or that node) just watched the file. This solved the problem with the consumption of CPU Consul.
Now everything began to look like we planned - absolutely transparent for our production, practically without consuming resources.
We were pretty much tortured that day and went home in great fear. They were not afraid in vain, because at night I was awakened by an alert from monitoring and informed that we had a rather large-scale (albeit short-lived) surge of errors.
Understanding logs in the morning, I saw that all the errors of the same kind are unknown host. It was not clear why Dnsmasq could not kill one service or another from a file — the feeling that it does not exist at all. To try to understand what is happening, I added a custom metric for file re-migration — now I knew for sure when it would be regenerated. In addition, in the Consul template itself there is an excellent backup option, i.e. You can see the previous state of the regenerated file.
During the day, the incident repeated several times and it became clear that at some point in time (although it was sporadic, unsystematic), the hosts file without specific services was re-generated. It turned out that in a specific data center (I will not do anti-advertising) rather unstable networks - because of the network flopping, we completely unpredictably stopped going through healthcheck, or even nodes fell out of the cluster. It looked like this:
The node fell out of the cluster, the Consul agent was immediately notified about this, and the Consul template immediately regenerated the hosts file without the required service. It was generally unacceptable, because the problem is ridiculous: if the service is unavailable for a few seconds, the mood is timeouts and retracts (they did not connect once, and the second time it happened). We, however, have provoked a situation in the sales department when the service simply disappears from view and there was no possibility to connect to it.
We started to think what to do with this and turn the timeout parameter into Consul, after which it is identified after how long the node falls out. We managed to solve this problem with a rather small indicator, the nodes stopped falling out, but with healthcheck this did not help.
We started thinking about selecting different parameters for healthchecks, trying to somehow understand when and how this happens. But due to the fact that everything happened sporadically and unpredictably, we could not do it.
Then we went to the Consul template and decided to make a timeout for it, after which it reacts to a change in the cluster state. Again, it was impossible to be fanatical here, because we could come to a situation where the result would be no better than the classical DNS, when we were striving for a completely different one.
And here our technical director once again came to the rescue and said: “Guys, let's try to abandon all this interactivity, we are all in production and there is no time for research, we need to solve this issue. Let's use simple and understandable things. ” So we came to the concept of using the key-value repository as a source for generating the hosts file.
What it looks like: we abandon all dynamic healthchecks, rewrite our template script to generate a file based on the data stored in the key-value storage. In the key-value store, we describe our entire infrastructure as a key name (this is the name of the service we need) and key values (this is the name of the node in the cluster). Those. if the node is present in the cluster, then we very easily get its IP address and write it to the hosts file.
We all tested, poured into production, and it became a silver bullet in a particular situation. Again, we were pretty much tortured for the whole day, and we went home, but returned already rested, inspired, because these problems did not recur any more and did not recur for a year. From which I personally conclude that this was the right decision (specifically for us).
So. We finally achieved what we wanted and organized a dynamic namespace for our backend. Then we went towards high availability.
But the fact is that pretty frightened by the integration of Consul and because of the problems we faced, we thought and decided that implementing auto-failover is not such a good solution, because we again risk false positives or failures. This process is opaque and uncontrollable.
Therefore, we chose a simpler (or more complicated) way: we decided to leave failover on the conscience of the duty administrator, but gave him another additional tool. We replaced the master slave replication with the master replication in Read only mode. This removes a huge amount of headaches in the failover process — when you drop out of the wizard, all you have to do is change the value in the k / v storage using the Web UI or the command in the API and remove Read only to backup wizard.
After the incident has been settled, the wizard comes into contact and automatically comes to a consistent state without any unnecessary actions at all. We stopped at this option and use it as before - for us it is as convenient as possible, and most importantly as simple as possible, understandable and controllable.
The Consul web interface
On the right, k / v storage is shown and our services are visible, which we use in the gamed operation; value is the name of the node.
As for scaling, we started to implement it when shards became crowded on one server, the bases grew, became slow, the number of players increased, we swapped and we were faced with the task of dissolving all shards on our own separate servers.
What it looked like: using the XtraBackup utility, we restored our backup on a new pair of servers, after which the new master was hung up as a slave to the old one. It came in a consistent state, we changed the key value in the k / v-storage from the name of the node of the old master to the name of the node of the new master. Then (when we thought that everything went correctly and all gamed with its selects, updates, inserts went to the new master), all that was needed was to kill replication and make the coveted drop database production, as we all like to do with unnecessary databases.
In this way, we got sharpened shards. The whole process of moving took from 40 minutes to an hour and did not cause any downtime, was completely transparent for our backends and was itself completely transparent for the players (except that as soon as they moved, it became easier and more pleasant for them to play).
As for the failover processes, here the switching time is from 20 to 40 seconds plus the response time of the system administrator on duty. That's about it now it looks like with us.
So that I would like to say in conclusion - unfortunately, our hopes for absolute, comprehensive automation broke about the harsh reality of the data transmission environment in the loaded data center and random factors that we could not foresee.
Secondly, it once again taught us that a simple and proven bird in the hands of your sysadmin is better than a newfangled, self-reactive, self-scaling crane somewhere behind the clouds, that you don’t even understand if it’s falling apart, or really began to scale.
The introduction of any infrastructure, automation in your production should not cause an extra headache for the staff that serves it; it should not significantly increase the cost of maintaining the production of infrastructure - the solution should be simple, clear, transparent for your customers, convenient and controllable.
Questions from the audience
How do you write k / v with servers - a script or do you just patch it?
We have K / v-storage on our Consul-servers and either remove something from there or replenish it with the help of http-requests RESTful API or Web UI.
I wanted to convey with this report that now, for some reason, the ideology of automating everything in the world with fierce fanaticism very often pursues without understanding that this sometimes complicates life and does not simplify.
Why do you balance between shards through databases, why not the same Redis?
This is a historically established decision and I forgot to say that now the concept has changed a little bit.
First, we have taken out the configs and now we do not need to re-fill the backend. Secondly, we have entered the parameter into the backends themselves, which is the main sharding link - that is, they distribute the players. Those. if we have a new player entity, he makes an entry in MAINDB and then saves the data on the shard he chose. And now he chooses it by weights. And it is very quickly and easily controlled and at the moment there is no need to take and use some other technology, because it all works quickly now.
But if we run into some kind of problem, then perhaps it will be better to use a fast inmemory key-value repository or something else.
What is your base?
We use MySQL fork - Percona server.
And you did not try to combine it into a cluster and due to this balance? If you had Maria, which is the same MHA for MySQL, he has Galera.
We had in service with Galera. There was another data center for the project “Guild of Heroes” for Asia and there we used Galera and it often gives a very unpleasant failure, it needs to be lifted up by hand from time to time. Having such experience of using this technology specifically, we still do not really want to use it.
Again, it should be understood that the introduction of any technology is not just because you want to do better, but because you have a need for it, you need to get out of some existing situation, or you have already predicted that the situation will happen soon and You choose a specific technology to implement.
More reports from Pixonic DevGAMM Talks
- CICD: Seamless Deploy on Distributed Cluster Systems without Downtime (Egor Panov, Pixonic System Administrator);
- Practice using the model of actors in the back-end platform of the Quake Champions game (Roman Rogozin, backend developer of Saber Interactive);
- The architecture of the meta-server mobile online shooter Tacticool (Pavel Platto, Lead Software Engineer in PanzerDog);
- How ECS, C # Job System and SRP change the approach to architecture (Valentin Simonov, Field Engineer in Unity);
- KISS principle in development (Konstantin Gladyshev, Lead Game Programmer at 1C Game Studios);
- General game logic on the client and server (Anton Grigoriev, Deputy Technical Officer in Pixonic).
- Cucumber in the cloud: using BDD scripts for load testing a product (Anton Kosyakin, Technical Product Manager in ALICE Platform).