To a global heap without traffic jams. Exploring Memory Managers
Somehow, analyzing a defect in a developed product, I came across an architectural feature of the memory manager that we used. The defect led to an increase in the creation time of some objects. A feature of the architecture was the use of the Singleton pattern when working with the memory manager (hereinafter X allocator). Schematically, it looks like this:
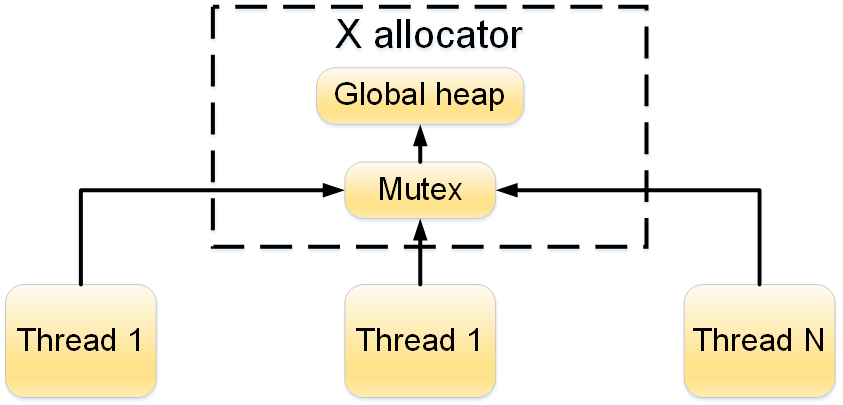
Figure 1 - Block diagram of the X allocator
The diagram shows that access to the global heap is protected by the mutex. Such an architecture, with the intensive creation of objects of the same type from several threads, can lead to threads queuing up on this mutex. But one of the main features of the product is the ability to scale it by increasing the number of processing threads (threads performing the same actions). Therefore, this approach could potentially become a bottleneck.
Realizing the magnitude of the threat, I decided to enlighten and climbed onto the Internet to look for information about multi-threaded pooled allocators. While searching, I came across several projects:
• Hoard (http://www.hoard.org/), distributed under the GPL v.2.0 license;
• TBB Memory Allocator from Intel (dropped, because the library is paid);
• Thread-Caching Malloc from gperftools by Google (https://code.google.com/p/gperftools/).
Also in the search process I found a very interesting article that describes various approaches when working with dynamic memory - www.realcoding.net/article/view/2747 .
Having several solutions in hand, I decided to experiment: compare the performance of various memory managers and spy on a solution for optimizing X allocator.
When I analyzed the implementation of Hoard and TCMalloc, I realized that the memory managers implemented in them use stream caching (an alternative to this approach is the use of lock-free lists). When deleting an object, caching allows you to return memory not to the global heap, but to cache this stream. So when you re-create the same object, the thread does not have to crawl under the mutex in a heap. Schematically, this approach can be represented as follows (Figure 2):

Figure 2 - Block diagram of the operation of X allocator using thread
caching Having implemented caching in the X allocator (hereinafter pooled X allocator) on the knee, I started to compare the performance.
A study of the behavior of memory managers was carried out with intensive CPU consumption. The test consisted of creating X objects on N threads, while testing the hypothesis that the test execution time is inversely proportional to the number of threads. An example for an ideal world: the creation of 1000 objects on 1 thread will be 2 times longer than the creation of 1000 objects on 2 threads (500 objects per stream).
The tests performed can be divided into the following categories:
1. OS type:
a. Windows
b. Linux
2. Size of objects:
a. 128b;
b. 1Kb;
c. 1Mb.
3. Memory manager:
a. system memory manager;
b. TCMalloc (Google);
c. Hoard;
d. pooled X allocator (replaced X allocator singleton with an array of X allocators, when allocating and freeing memory, the number of X allocator is calculated by the tid of the stream).
e. X allocator;
4. The number of threads: from 1 to 8;
5. Each experiment I conducted 5 times, after which I calculated the arithmetic mean value.
Below I give only one graph (Figure 3) and the experimental results for it (Table 1), since for all cases the results were similar. The results are shown for Linux objects with a size of 1 Kb.

Figure 3 - Results of a study of the performance of memory managers
On the graph, the abscissa axis is the number of threads, the ordinate axis is the relative test execution time (for 100%, the test execution time on one thread is taken using the system memory manager).
Table 1 - Results of a study of the performance of memory managers

Based on the results obtained, the following conclusions can be drawn:
1. The X allocator that we use showed good performance on only 1 thread, with an increase in the number of threads, performance drops (due to competition on the mutex);
2. other memory managers coped with the task of parallelization; indeed, with an increase in the number of threads, the task began to be executed faster;
3. TCMalloc has shown better performance.
Of course, I realized that the experiment was artificial and in real conditions the performance growth would not be as significant (some tests showed a performance increase of 80 times). When I replaced X allocator in my project with TCMalloc and experimented with real data, the performance increase was 10%, and this is a pretty good increase.
Performance is great, of course, but the X allocator provides the ability to analyze memory consumption and look for leaks. And what about the rest of the memory managers? I will try to disclose this comparison in detail in the next article.
Figure 1 - Block diagram of the X allocator
The diagram shows that access to the global heap is protected by the mutex. Such an architecture, with the intensive creation of objects of the same type from several threads, can lead to threads queuing up on this mutex. But one of the main features of the product is the ability to scale it by increasing the number of processing threads (threads performing the same actions). Therefore, this approach could potentially become a bottleneck.
Realizing the magnitude of the threat, I decided to enlighten and climbed onto the Internet to look for information about multi-threaded pooled allocators. While searching, I came across several projects:
• Hoard (http://www.hoard.org/), distributed under the GPL v.2.0 license;
• TBB Memory Allocator from Intel (dropped, because the library is paid);
• Thread-Caching Malloc from gperftools by Google (https://code.google.com/p/gperftools/).
Also in the search process I found a very interesting article that describes various approaches when working with dynamic memory - www.realcoding.net/article/view/2747 .
Having several solutions in hand, I decided to experiment: compare the performance of various memory managers and spy on a solution for optimizing X allocator.
When I analyzed the implementation of Hoard and TCMalloc, I realized that the memory managers implemented in them use stream caching (an alternative to this approach is the use of lock-free lists). When deleting an object, caching allows you to return memory not to the global heap, but to cache this stream. So when you re-create the same object, the thread does not have to crawl under the mutex in a heap. Schematically, this approach can be represented as follows (Figure 2):
Figure 2 - Block diagram of the operation of X allocator using thread
caching Having implemented caching in the X allocator (hereinafter pooled X allocator) on the knee, I started to compare the performance.
A study of the behavior of memory managers was carried out with intensive CPU consumption. The test consisted of creating X objects on N threads, while testing the hypothesis that the test execution time is inversely proportional to the number of threads. An example for an ideal world: the creation of 1000 objects on 1 thread will be 2 times longer than the creation of 1000 objects on 2 threads (500 objects per stream).
The tests performed can be divided into the following categories:
1. OS type:
a. Windows
b. Linux
2. Size of objects:
a. 128b;
b. 1Kb;
c. 1Mb.
3. Memory manager:
a. system memory manager;
b. TCMalloc (Google);
c. Hoard;
d. pooled X allocator (replaced X allocator singleton with an array of X allocators, when allocating and freeing memory, the number of X allocator is calculated by the tid of the stream).
e. X allocator;
4. The number of threads: from 1 to 8;
5. Each experiment I conducted 5 times, after which I calculated the arithmetic mean value.
Below I give only one graph (Figure 3) and the experimental results for it (Table 1), since for all cases the results were similar. The results are shown for Linux objects with a size of 1 Kb.
Figure 3 - Results of a study of the performance of memory managers
On the graph, the abscissa axis is the number of threads, the ordinate axis is the relative test execution time (for 100%, the test execution time on one thread is taken using the system memory manager).
Table 1 - Results of a study of the performance of memory managers
Based on the results obtained, the following conclusions can be drawn:
1. The X allocator that we use showed good performance on only 1 thread, with an increase in the number of threads, performance drops (due to competition on the mutex);
2. other memory managers coped with the task of parallelization; indeed, with an increase in the number of threads, the task began to be executed faster;
3. TCMalloc has shown better performance.
Of course, I realized that the experiment was artificial and in real conditions the performance growth would not be as significant (some tests showed a performance increase of 80 times). When I replaced X allocator in my project with TCMalloc and experimented with real data, the performance increase was 10%, and this is a pretty good increase.
Performance is great, of course, but the X allocator provides the ability to analyze memory consumption and look for leaks. And what about the rest of the memory managers? I will try to disclose this comparison in detail in the next article.