Asynchronous business logic today
In short:
- Proof is already implemented in C ++ , JS and PHP , suitable for Java .
- Faster than Coroutine and Promise, more features.
- Does not require the allocation of a separate software stack.
- Is friends with all the security and debugging tools.
- It works on any architecture and does not require special compiler flags.
Look back
At the dawn of a computer, there was a single control flow with I / O blocking. Then interruptions of iron were added to it. Now you can effectively use slow and unpredictable devices.
With the increasing capabilities of iron and its low availability, there is a need to perform several tasks at the same time, which provided hardware support. Thus, isolated processes with abstracted from iron interruptions in the form of signals appeared.
The next evolutionary stage was multithreading, which was implemented on the foundation of the same processes, but with shared access to memory and other resources. This approach has its limitations and significant overhead for switching to a secure OS.
For communication between processes and even different machines, a Promise / Future abstraction was proposed 40+ years ago.
User interfaces and the now ridiculous problem of 10K clients led to the heyday of Event Loop, Reactor and Proactor approaches that are more event-oriented than clear, consistent business logic.
Finally, we arrived at a modern coroutine (coroutine), which is essentially an emulation of threads on top of the abstractions described above with the corresponding technical limitations and deterministic transfer of control.
For the transfer of events, results and exceptions all returned to the same concept of Promise / Future. Some offices have decided to call a little differently - "Task".
Ultimately, everything is hidden in a beautiful package async/awaitthat requires support from the compiler or translator, depending on the technology.
Problems with current asynchronous business logic situations
Consider only coroutines and Promise, decorated async/await, because the existence of problems in older approaches confirms the process of evolution itself.
These two terms are not identical. For example, in ECMAScript there are no coroutines, but there are syntactic facilitations for use Promise, which in turn only organizes work with the hell of callbacks (callback hell). In fact, scripting engines like V8 go further and make special optimizations for pure async/awaitfunctions and calls.
The experts' statements about those not in C ++ 17 co_async/co_awaitare here on the resource , but with the pressure of the software giant, coroutines can appear in the standard exactly in their form. In the meantime, the traditional solution is recognized Boost.Context , Boost.Fiber and Boost.Coroutine2 .
In Java, there is still no async/awaitlanguage-level, but there are solutions like EA Async , which, like Boost.Context, need to be customized for each version of JVM and code byte.
Go has its coroutines, but if you look carefully at the articles and bug reports of open projects, it turns out that everything is not so smooth. Perhaps the loss of the coroutine interface as a managed entity is not the best idea.
Opinion of the author: coroutines on bare gland are dangerous
Personally, the author has very little against coroutines in dynamic languages, but he is extremely wary of any flirting with the machine code level stack.
A few theses:
- It is required to allocate a stack:
- the stack on the heap has a number of flaws: problems of timely detection of overflow, damage by neighbors and other reliability / safety problems,
- a protected stack requires at least one page of physical memory, one conditional page, and additional overhead for each
asyncfunction call : 4 + KB (minimum) + increased system limits, - it may ultimately be the case that a significant part of the memory allocated for stacks is not used during the coroutine's idle time.
- It is necessary to implement complex logic for saving, restoring and deleting the state of coroutines:
- for each case of processor architectures (even model) and binary interface (ABI): example ,
- New or optional architecture features introduce potentially latent problems (for example, Intel TSX, ARM or MIPS co-processors),
- other potential problems due to proprietary systems proprietary documentation (the Boost documentation refers to this).
- Potential problems with dynamic analysis tools and with security in general:
- for example, integration with Valgrind is required due to the same skipping stacks,
- It's hard to speak for antiviruses, but they probably don’t really like it using the example of JVM problems in the past,
- I am sure that new types of attacks will appear and vulnerabilities related to the implementation of coroutines will be revealed.
Opinion of the author: generators and yieldfundamental evil
This seemingly third-party topic is directly related to the concept of coroutines and the "continue" property.
In short, for any collection there should be a full-fledged iterator. Why create the problem of a truncated iterator generator is not clear. For example, a case with range()Python is more like an exclusive showcase than an excuse for technical complication.
If the case of an infinite generator, then the logic of its implementation is elementary. Why create additional technical difficulties to shove an infinite continuous cycle inside?
The only sensible, later appeared justification that supporters of coroutines bring is all kind of stream parsers with inverted controls. In fact, this is a narrow specialized case for solving single problems of the library level, and not the business logic of applications. At the same time there is an elegant, simple and more descriptive solution through finite automata. The area of these technical problems is much smaller than the area of banal business logic.
In fact, the solved problem turns out to be sucked from the finger and requires a relatively serious effort for initial implementation and long-term support. To the extent that some projects may prohibit the use of coroutines of machine code level following the example of a ban on gotoor the use of dynamic memory allocation in certain industries.
Opinion of the author: async/awaitPromise model from ECMAScript is more reliable, but requires adaptation
Unlike continuing coroutines, in this model, pieces of code are secretly divided into uninterrupted blocks, decorated in the form of anonymous functions. In C ++, this is not quite suitable due to the memory management features, for example:
structSomeObject {using Value = std::vector<int>;
Promise funcPromise(){
return Promise.resolved(value_);
}
voidfuncCallback(std::function<void()> &&cb, const Value& val){
somehow_call_later(cb);
}
Value value_;
};
Promise example(){
SomeObject some_obj;
return some_obj.funcPromise()
.catch([](conststd::exception &e){
// ...
})
.then([&](SomeObject::value &&val){
return Promise([&](Resolve&& resolve, Reject&&){
some_obj.funcCallback(resolve, val);
});
});
}First, it some_objwill be destroyed when exiting example()and before calling the lambda functions.
Secondly, lambda functions with variable or reference capture are objects and secretly add copying / moving, which can adversely affect performance with a large number of captures and the need to allocate memory on the heap during type erasure in normal std::function.
Thirdly, the interface itself is Promiseconceived on the concept of "promising" the result, rather than the consistent implementation of business logic.
A schematic NOT optimal solution might look something like this:
Promise example(){
structLocalContext {
SomeObject some_obj;
};
auto ctx = std::make_shared<LocalContext>();
return some_obj.funcPromise()
.catch([](conststd::exception &e){
// ...
})
.then([ctx](SomeObject::Value &&val){
struct LocalContext2 {
LocalContext2(std::shared_ptr<LocalContext> &&ctx, SomeObject::Value &&val) :
ctx(ctx), val(val)
{}
std::shared_ptr<LocalContext> ctx;
SomeObject::Value val;
};
auto ctx2 = std::make_shared<LocalContext2>(
std::move(ctx),
std::forward<SomeObject::Value>(val)
);
return Promise([ctx2](Resolve&& resolve, Reject&&){
ctx2->ctx->some_obj.funcCallback([ctx2, resolve](){ resolve(); }, val);
});
});
}Note: std::moveinstead of std::shared_ptrnot suitable because of the impossibility of transmission in several lambdas at once and the growth of their size.
With the addition of async/awaitasynchronous "horrors" come in a digestible state:
async voidexample(){
SomeObject some_obj;
try {
SomeObject::Value val = await some_obj.func();
} catch (conststd::exception& e) (
// ...
}
// Capture "async context"return Promise([async](Resolve&& resolve, Reject&&){
some_obj.funcCallback([async](){ resolve(); }, val);
});
}Opinion of the author: the coroner planner is a bust
Some critics have called the problem of the lack of a scheduler and the "dishonest" use of processor resources. Perhaps a more serious problem is data locality and efficient use of the processor cache.
On the first problem: prioritization at the level of individual coroutines looks like a big overhead. Instead, they can be operated in common for a specific unified task. So come with traffic flows.
This is possible by creating separate instances of the Event Loop with its own “iron” streams and planning at the OS level. The second option is to synchronize the coroutines with respect to the primitive (Mutex, Throttle) that limits the competition and / or performance.
Asynchronous programming does not make the processor resources rubber and requires absolutely normal restrictions on the number of simultaneously processed tasks and the limit on the total execution time.
Protection against long-term blocking on one coroutine requires the same measures as with callbacks — to avoid blocking system calls and long data processing cycles.
For the second problem, research is needed, but at a minimum the coroutine stacks themselves and the details of the Future / Promise implementation already violate the data locality. It is possible to try to continue with the same coroutine if Future already matters. It requires some mechanism for counting the runtime or the number of such continuations to prevent one coroutine from capturing the entire processor time. This may either not give a result, or give a very double result depending on the size of the processor cache and the number of threads.
There is also a third point - many implementations of coroutine planners allow you to run them on different processor cores, which, on the contrary, adds problems due to the mandatory synchronization when accessing shared resources. In the case of a single Event Loop stream, such synchronization is required only at the logic level, since Each synchronous callback unit is guaranteed to work without a race with others.
Opinion of the author: everything is good in moderation
The presence of threads in modern operating systems does not negate the use of separate processes. Also, processing a large number of clients in the Event Loop does not cancel the use of separate "iron" streams for other needs.
In any case, coroutines and various variants of Event Loops complicate the debugging process without the necessary support in the tools, and with local variables on the coroutine stack, everything becomes even more difficult - they can hardly be reached.

FutoIn AsyncSteps - alternative to coroutines
We will take as a basis the already well-established Event Loop pattern and the organization of the ECMAScript (JavaScript) Promise callback scheme.
From a planning point of view, we are interested in the following actions from the Event Loop:
- Immediate callback calling
Handle immediate(callack)for a clean call stack. - Deferred callback
Handle deferred(delay, callback). - Cancel callback
handle.cancel().
So we get an interface with a name AsyncToolthat can be implemented in a variety of ways, including over existing proven developments. He has no direct relation to writing business logic, so we will not go into further details.
Step tree:
In the concept of AsyncSteps, an abstract tree of synchronous steps is built up and is performed by going deep into the creation sequence. The steps of each deeper level are dynamically set as such a passage is completed.
All interaction takes place through a single interface AsyncStepsthat is conventionally passed as the first parameter in each step. By convention, the name of the parameter asior obsolete as. Such an approach makes it possible to almost completely break the link between a specific implementation and the writing of business logic in plug-ins and libraries.
In canonical implementations, each step receives its own copy of the object that implements AsyncSteps, which allows timely tracking of logical errors in the use of the interface.
Abstract example:
asi.add( // Level 0 step 1func( asi ){
print( "Level 0 func" )
asi.add( // Level 1 step 1func( asi ){
print( "Level 1 func" )
asi.error( "MyError" )
},
onerror( asi, error ){ // Level 1 step 1 catchprint( "Level 1 onerror: " + error )
asi.error( "NewError" )
}
)
},
onerror( asi, error ){ // Level 0 step 1 catchprint( "Level 0 onerror: " + error )
if ( error strequal "NewError" ) {
asi.success( "Prm", 123, [1, 2, 3], true)
}
}
)
asi.add( // Level 0 step 2func( asi, str_param, int_param, array_param ){
print( "Level 0 func2: " + param )
}
)Result of performance:
Level0 func 1Level1 func 1Level1 onerror 1: MyError
Level0 onerror 1: NewError
Level0 func 2: PrmIn synchronous form it would look like this:
str_res, int_res, array_res, bool_res // undefinedtry {
// Level 0 step 1print( "Level 0 func 1" )
try {
// Level 1 step 1print( "Level 1 func 1" )
throw"MyError"
} catch( error ){
// Level 1 step 1 catchprint( "Level 1 onerror 1: " + error )
throw"NewError"
}
} catch( error ){
// Level 0 step 1 catchprint( "Level 0 onerror 1: " + error )
if ( error strequal "NewError" ) {
str_res = "Prm"
int_res = 123
array_res = [1, 2, 3]
bool_res = true
} else {
re-throw
}
}
{
// Level 0 step 2print( "Level 0 func 2: " + str_res )
}Immediately visible is the maximum mimicry of the traditional synchronous code, which should help in readability.
From the point of view of business logic, a large number of requirements are growing over time , but we can divide it into easily understandable parts. Described below, the result of running in practice for four years.
Base Runtime APIs:
add(func[, onerror])- imitationtry-catch.success([args...])- explicit indication of successful completion:- implied by default
- can transfer the results to the next step.
error(code[, reason)- interruption of execution with an error:code- has a string type to better integrate with network protocols in the microservice architecture,reason- arbitrary explanation for the person.
state()- Analogue Thread Local Storage. Predefined associative keys:error_info- an explanation of the last error for a personlast_exception- pointer to the object of the last exception,async_stack- a stack of asynchronous calls as far as technology allows,- the rest is set by the user.
The previous example already has real C ++ code and some additional features:
#include<futoin/iasyncsteps.hpp>usingnamespace futoin;
voidsome_api(IAsyncSteps& asi){
asi.add(
[](IAsyncSteps& asi) {
std::cout << "Level 0 func 1" << std::endl;
asi.add(
[](IAsyncSteps& asi) {
std::cout << "Level 1 func 1" << std::endl;
asi.error("MyError");
},
[](IAsyncSteps& asi, ErrorCode code) {
std::cout << "Level 1 onerror 1: " << code << std::endl;
asi.error("NewError", "Human-readable description");
}
);
},
[](IAsyncSteps& asi, ErrorCode code) {
std::cout << "Level 0 onerror 1: " << code << std::endl;
if (code == "NewError") {
// Human-readable error info
assert(asi.state().error_info ==
"Human-readable description");
// Last exception thrown is also available in statestd::exception_ptr e = asi.state().last_exception;
// NOTE: smart conversion of "const char*"
asi.success("Prm", 123, std::vector<int>({1, 2, 3}, true));
}
}
);
asi.add(
[](IAsyncSteps& asi, const futoin::string& str_res, int int_res, std::vector<int>&& arr_res) {
std::cout << "Level 0 func 2: " << str_res << std::endl;
}
);
}API for creating loops:
loop( func, [, label] )- step with infinitely repeated body.forEach( map|list, func [, label] )- step iteration over the collection object.repeat( count, func [, label] )- iteration step a specified number of times.break( [label] )- analogue of the traditional interrupt cycle.continue( [label] )- analogue of the traditional continuation of the cycle with a new iteration.
The specification suggests alternative names breakLoop, continueLoopand others in the event of a conflict with reserved words.
C ++ example:
asi.loop([](IAsyncSteps& asi) {
// infinite loop
asi.breakLoop();
});
asi.repeat(10, [](IAsyncSteps& asi, size_t i) {
// range loop from i=0 till i=9 (inclusive)
asi.continueLoop();
});
asi.forEach(
std::vector<int>{1, 2, 3},
[](IAsyncSteps& asi, size_t i, int v) {
// Iteration of vector-like and list-like objects
});
asi.forEach(
std::list<futoin::string>{"1", "2", "3"},
[](IAsyncSteps& asi, size_t i, const futoin::string& v) {
// Iteration of vector-like and list-like objects
});
asi.forEach(
std::map<futoin::string, futoin::string>(),
[](IAsyncSteps& asi,
const futoin::string& key,
const futoin::string& v) {
// Iteration of map-like objects
});
std::map<std::string, futoin::string> non_const_map;
asi.forEach(
non_const_map,
[](IAsyncSteps& asi, conststd::string& key, futoin::string& v) {
// Iteration of map-like objects, note the value reference type
});API for integration with external events:
setTimeout( timeout_ms )- causes an errorTimeoutafter a time expires, if the step and its subtree have not completed execution.setCancel( handler )- installs a cancel handler, which is called when the thread is completely canceled and the stack of asynchronous steps is expanded during error handling.waitExternal()- simple waiting for an external event.- Note: it is safe to use only in technologies with a garbage collector.
Calling any of these functions necessitates an explicit call success().
C ++ example:
asi.add([](IAsyncSteps& asi) {
auto handle = schedule_external_callback([&](bool err) {
if (err) {
try {
asi.error("ExternalError");
} catch (...) {
// pass
}
} else {
asi.success();
}
});
asi.setCancel([=](IAsyncSteps& asi) { external_cancel(handle); });
});
asi.add(
[](IAsyncSteps& asi) {
// Raises Timeout error after specified period
asi.setTimeout(std::chrono::seconds{10});
asi.loop([](IAsyncSteps& asi) {
// infinite loop
});
},
[](IAsyncSteps& asi, ErrorCode code) {
if (code == futoin::errors::Timeout) {
asi();
}
});ECMAScript example:
asi.add( (asi) => {
asi.waitExternal(); // disable implicit success()
some_obj.read( (err, data) => {
if (!asi.state) {
// ignore as AsyncSteps execution got canceled
} elseif (err) {
try {
asi.error( 'IOError', err );
} catch (_) {
// ignore error thrown as there are no// AsyncSteps frames on stack.
}
} else {
asi.success( data );
}
} );
} );Future / Promise integration API:
await(promise_future[, on_error])- Future / Promise waiting as a step.promise()- Turns the entire execution thread into Future / Promise, used insteadexecute().
C ++ example:
[](IAsyncSteps& asi) {
// Proper way tocreatenew AsyncSteps instances
// without hard dependency on implementation.
auto new_steps = asi.newInstance();
new_steps->add([](IAsyncSteps& asi) {});
// Can be called outside of AsyncSteps event loop
// new_steps.promise().wait();
// or
// new_steps.promise<int>().get();
// Proper way to wait for standard std::future
asi.await(new_steps->promise());
// Ensure instance lifetime
asi.state()["some_obj"] = std::move(new_steps);
};Business Logic Flow Control API:
AsyncSteps(AsyncTool&)- a constructor that binds a thread of execution to a specific Event Loop.execute()- starts a thread of execution.cancel()- cancels the thread of execution.
It already requires a specific implementation of the interface.
C ++ example:
#include<futoin/ri/asyncsteps.hpp>#include<futoin/ri/asynctool.hpp>voidexample(){
futoin::ri::AsyncTool at;
futoin::ri::AsyncSteps asi{at};
asi.loop([&](futoin::IAsyncSteps &asi){
// Some infinite loop logic
});
asi.execute();
std::this_thread::sleep_for(std::chrono::seconds{10});
asi.cancel(); // called in d-tor by fact
}other APIs:
newInstance()- allows you to create a new thread of execution without direct dependence on the implementation.sync(object, func, onerror)- the same, but with synchronization with respect to the object implementing the corresponding interface.parallel([on_error])- specialadd(), which substages are separate AsyncSteps streams:- all streams of the total
state(), - the parent thread continues execution upon completion of all children,
- an uncaught error in any child immediately cancels all other child threads.
- all streams of the total
C ++ Examples:
#include<futoin/ri/mutex.hpp>usingnamespace futoin;
ri::Mutex mtx_a;
voidsync_example(IAsyncSteps& asi){
asi.sync(mtx_a, [](IAsyncSteps& asi) {
// synchronized section
asi.add([](IAsyncSteps& asi) {
// inner step in the section// This synchronization is NOOP for already// acquired Mutex.
asi.sync(mtx_a, [](IAsyncSteps& asi) {
});
});
});
}
voidparallel_example(IAsyncSteps& asi){
using OrderVector = std::vector<int>;
asi.state("order", OrderVector{});
auto& p = asi.parallel([](IAsyncSteps& asi, ErrorCode) {
// Overall error handler
asi.success();
});
p.add([](IAsyncSteps& asi) {
// regular flow
asi.state<OrderVector>("order").push_back(1);
asi.add([](IAsyncSteps& asi) {
asi.state<OrderVector>("order").push_back(4);
});
});
p.add([](IAsyncSteps& asi) {
asi.state<OrderVector>("order").push_back(2);
asi.add([](IAsyncSteps& asi) {
asi.state<OrderVector>("order").push_back(5);
asi.error("SomeError");
});
});
p.add([](IAsyncSteps& asi) {
asi.state<OrderVector>("order").push_back(3);
asi.add([](IAsyncSteps& asi) {
asi.state<OrderVector>("order").push_back(6);
});
});
asi.add([](IAsyncSteps& asi) {
asi.state<OrderVector>("order"); // 1, 2, 3, 4, 5
});
};Standard synchronization primitives
Mutex- restricts simultaneous execution inNstreams with a queue inQ, by defaultN=1, Q=unlimited.Throttle- limits the number of entriesNin thePqueue inQ, by defaultN=1, P=1s, Q=0.Limiter- a combinationMutexandThrottle, which is typically used at the input of processing external requests and when calling external systems for the purpose of stable operation under load.
In case of going beyond the queue limits, an error rises DefenseRejected, the meaning of which is clear from the description Limiter.
Key benefits
The concept of AsyncSteps was not an end in itself, but was born due to the need for more controlled asynchronous program execution in terms of time limit, cancellation and overall coherence of individual callbacks. None of the universal solutions at that time and now provides the same functionality. Therefore:
The unified FTN12 specification for all technologies is a quick adaptation for developers when switching from one technology to another.
Cancel IntegrationsetCancel() - allows you to cancel all external requests and clean up resources in a clear and secure way when there is an external cancellation or a runtime error occurs. This avoids the problem of asynchronous execution of heavy tasks, the result of which is no longer required. This is an analogue of RAII and atexit()in traditional programming.
Immediately cancellationcancel() is typically used when disconnecting a client, expiration of the maximum request execution time, or other reasons for termination. This is an analogue SIGTERMor pthread_cancel(), both of which are very specific in implementation.
Step cancellation timerssetTimeout() - typically used to limit the total execution time of a request and to limit the latency of subqueries and external events. They act on the whole subtree, throwing out the intercepted error "Timeout".
Integration with other technologies of asynchronous programming - using FutoIn AsyncSteps does not require abandoning the technologies already used and does not require the development of new libraries.
Universal implementation at the level of a specific programming language - there is no need for specific and potentially dangerous with ABI changes, manipulations at the level of machine code that are required for coroutines. Good fit for embedded and safe on defective MMU.

To numbers
For tests, Intel Xeon E3-1245v2 / DDR1333 with Debian Stretch and the latest microcode update is used.
Five options are compared:
- Boost
protected_fixedsize_stack. Fiber with . - Boost.Fiber with
pooled_fixedsize_stackand selection on a common heap. - FutoIn AsyncSteps as standard.
- FutoIn AsyncSteps in a dynamically disabled memory pool (
FUTOIN_USE_MEMPOOL=false).- given only for evidence of effectiveness
futoin::IMemPool.
- given only for evidence of effectiveness
- FutoIn NitroSteps <> is an alternative implementation with static allocation of all buffers during object creation.
- Specific limit parameters are specified as advanced template parameters.
Due to the functional limitations of Boost.Fiber, the following performance indicators are compared:
- The sequential creation and execution of 1 million threads.
- Parallel creation of streams with a limit of 30 thousand and execution of 1 million threads.
- a limit of 30 thousand comes from the need to call
mmap()/mprotect()forboost::fiber::protected_fixedsize_stack. - A large number is also chosen to put pressure on the processor’s cache.
- a limit of 30 thousand comes from the need to call
- Parallel creation of 30 thousand streams and 10 million switchings in anticipation of an external event.
- in both cases, the "external" event is satisfied in a separate thread within the same technology.
One core and one “iron” stream are used, since This allows you to achieve maximum performance, eliminating the race on the backs and atomic operations. The best values from a series of tests go to the result. The stability of the indicators is checked.
The build is made with GCC 6.3.0. Results with Clang and tcmalloc were also checked, but the differences are not relevant for the article.
The source code of the tests is available on GitHub and GitLab .
1. Consecutive creation
| Technology | Time | Hz |
|---|---|---|
| Boost.Fiber protected | 4.8s | 208333.333Hz |
| Boost. Fiber pooled | 0.23s | 4347826.086Hz |
| FutoIn AsyncSteps | 0.21s | 4761904.761Hz |
| FutoIn AsyncSteps no mempool | 0.31s | 3225806.451Hz |
| FutoIn NitroSteps | 0.255s | 3921568.627Hz |
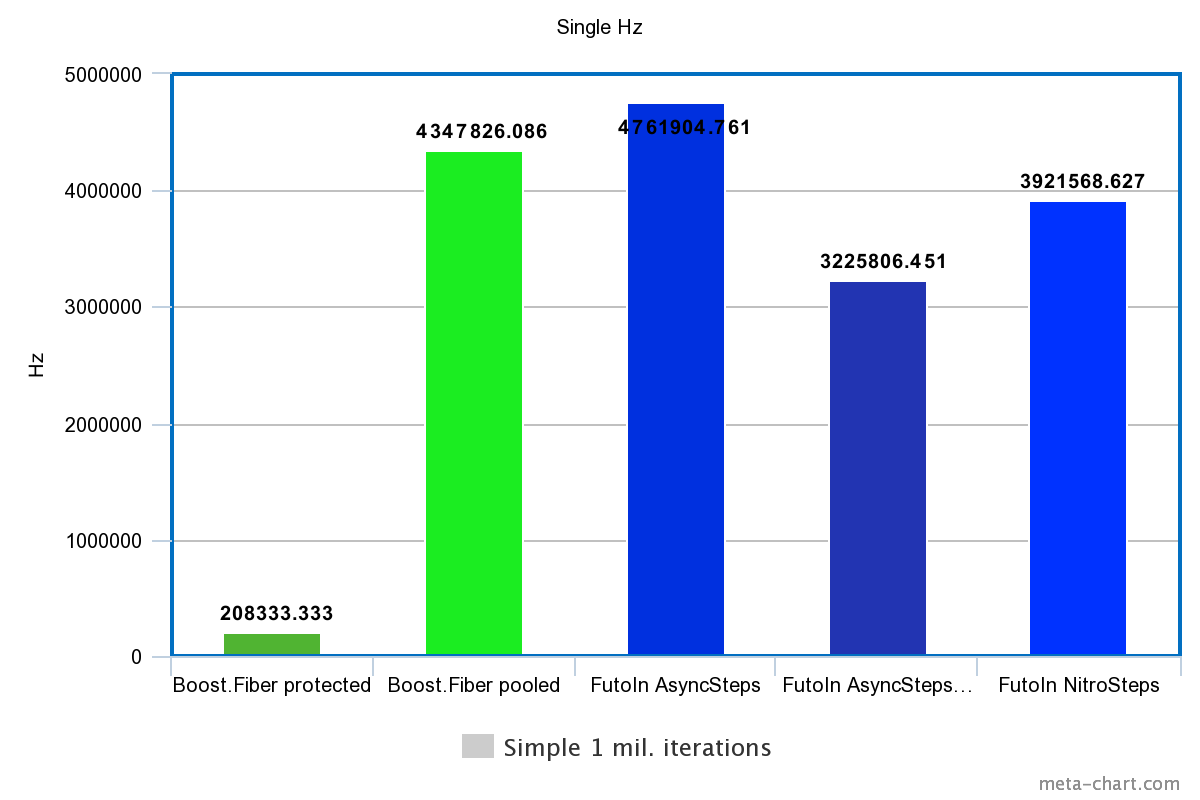
More is better.
Here, the main loss of Boost.Fiber is due to system page calls for working with memory pages, but even less safe pooled_fixedsize_stackis slower than the standard implementation of AsyncSteps.
2. Parallel creation and execution
| Technology | Time | Hz |
|---|---|---|
| Boost.Fiber protected | 6.31s | 158478.605Hz |
| Boost. Fiber pooled | 1.558s | 641848.523Hz |
| FutoIn AsyncSteps | 1.13s | 884955.752Hz |
| FutoIn AsyncSteps no mempool | 1.353s | 739098.300Hz |
| FutoIn NitroSteps | 1.43s | 699300.699Hz |
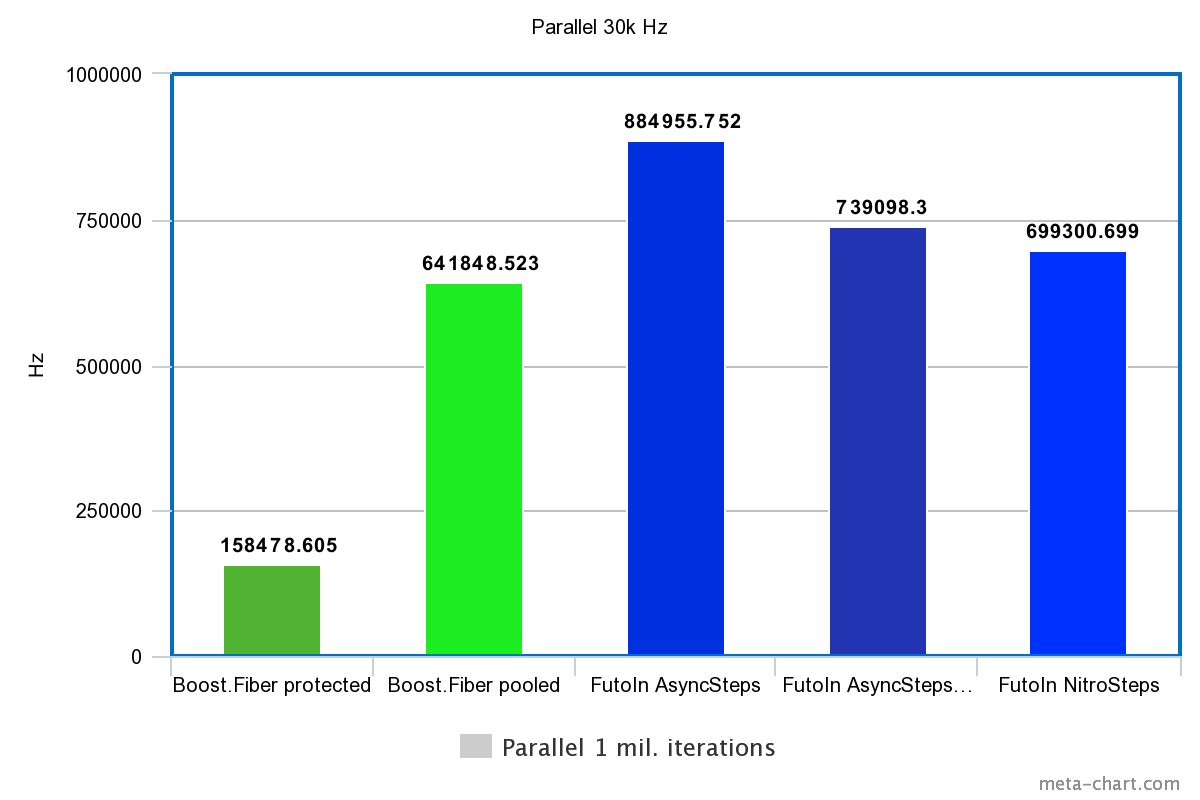
More is better.
Here are the same problems, but we see a significant slowdown compared with the first test. A more detailed analysis is needed, but a theoretical guess points to caching inefficiency — selective values of the number of parallel threads provide a picture of the function with many obvious breaks.
3. Parallel loops
| Technology | Time | Hz |
|---|---|---|
| Boost.Fiber protected | 5.096s | 1962323.390Hz |
| Boost. Fiber pooled | 5.077s | 1969667.126Hz |
| FutoIn AsyncSteps | 5.361s | 1865323.633Hz |
| FutoIn AsyncSteps no mempool | 8.288s | 1206563.706Hz |
| FutoIn NitroSteps | 3.68s | 2717391.304Hz |
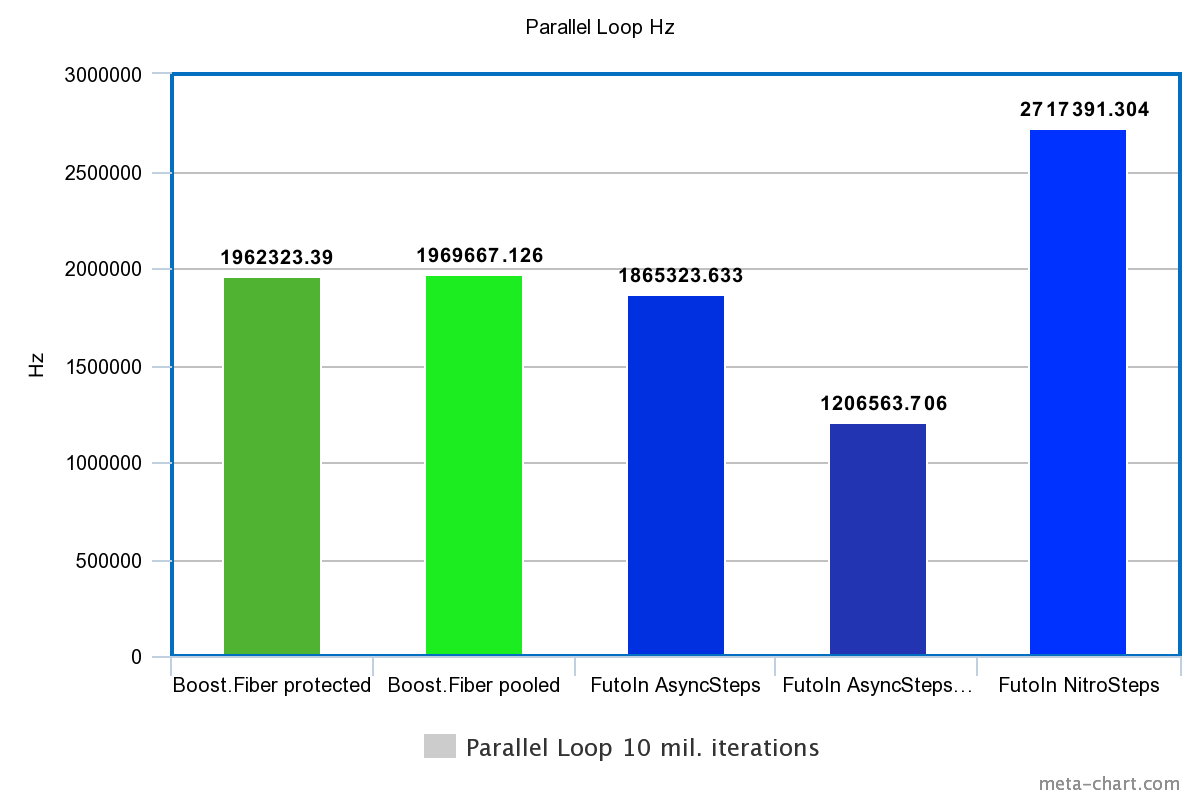
More is better.
By removing the creation overhead, we see that in the bare switching of threads, Boost.Fiber starts to beat the standard implementation of AsyncSteps, but NitroSteps loses much.
Memory usage (by RSS)
| Technology | Memory |
|---|---|
| Boost.Fiber protected | 124M |
| Boost. Fiber pooled | 505M |
| FutoIn AsyncSteps | 124M |
| FutoIn AsyncSteps no mempool | 84M |
| FutoIn NitroSteps | 115M |
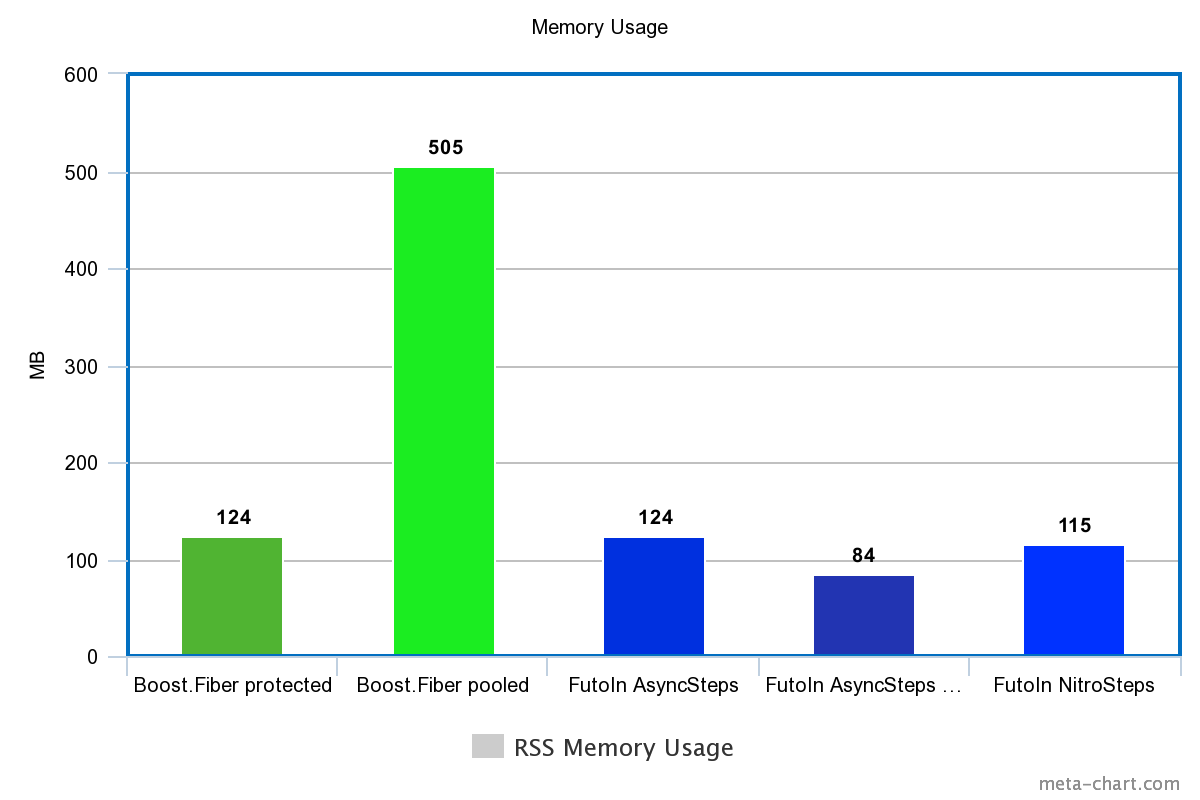
Less is better.
And again, Boost. Fiber has nothing to be proud of.
Bonus: tests on Node.js
Only two tests are also due to limitations Promise: creation + execution and cycles of 10 thousand iterations. Each test is 10 seconds. Take the average values in Hz of the second pass after the optimizing JIT when NODE_ENV=productionusing the packet @futoin/optihelp.
The source code is also on GitHub and GitLab . Node.js v8.12.0 and v10.11.0 versions are used, installed via the FutoIn CID .
| Tech | Simple | Loop |
|---|---|---|
| Node.js v10 | ||
| FutoIn AsyncSteps | 1342899.520Hz | 587.777Hz |
| async / await | 524983.234Hz | 630.863Hz |
| Node.js v8 | ||
| FutoIn AsyncSteps | 682420.735Hz | 588.336Hz |
| async / await | 365050.395Hz | 400.575Hz |
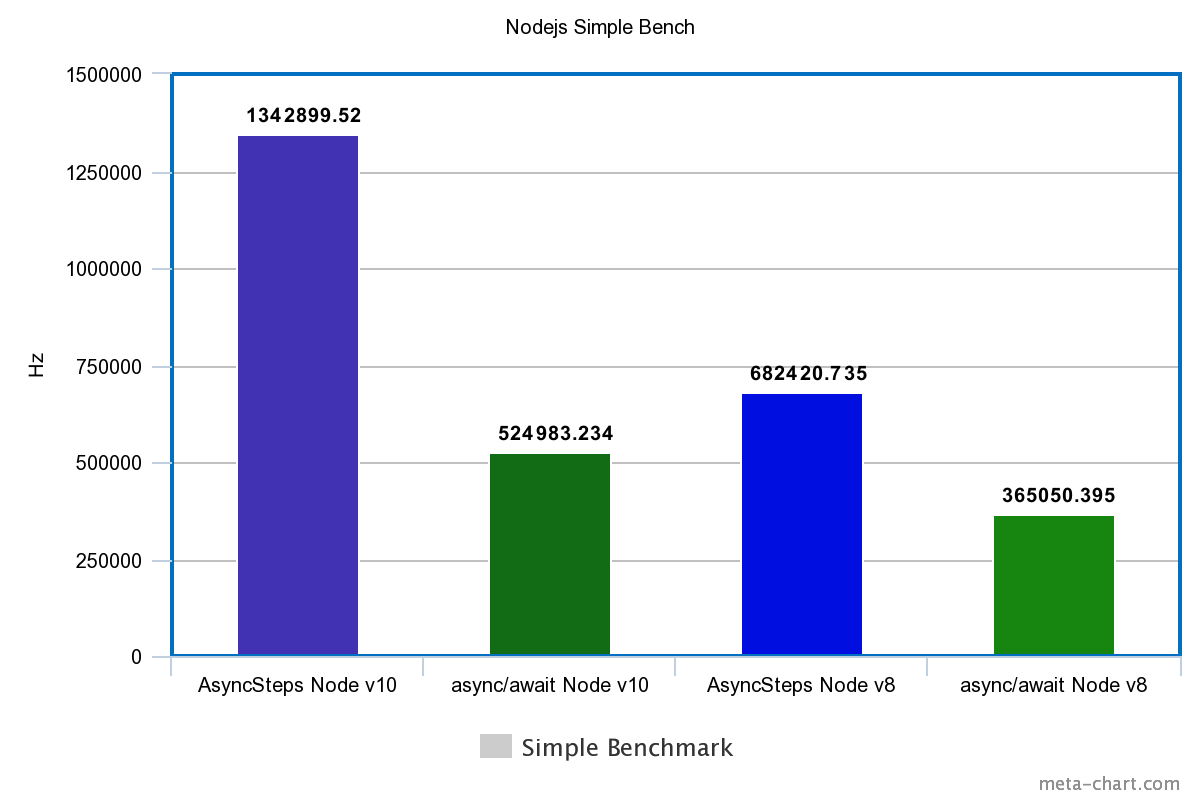
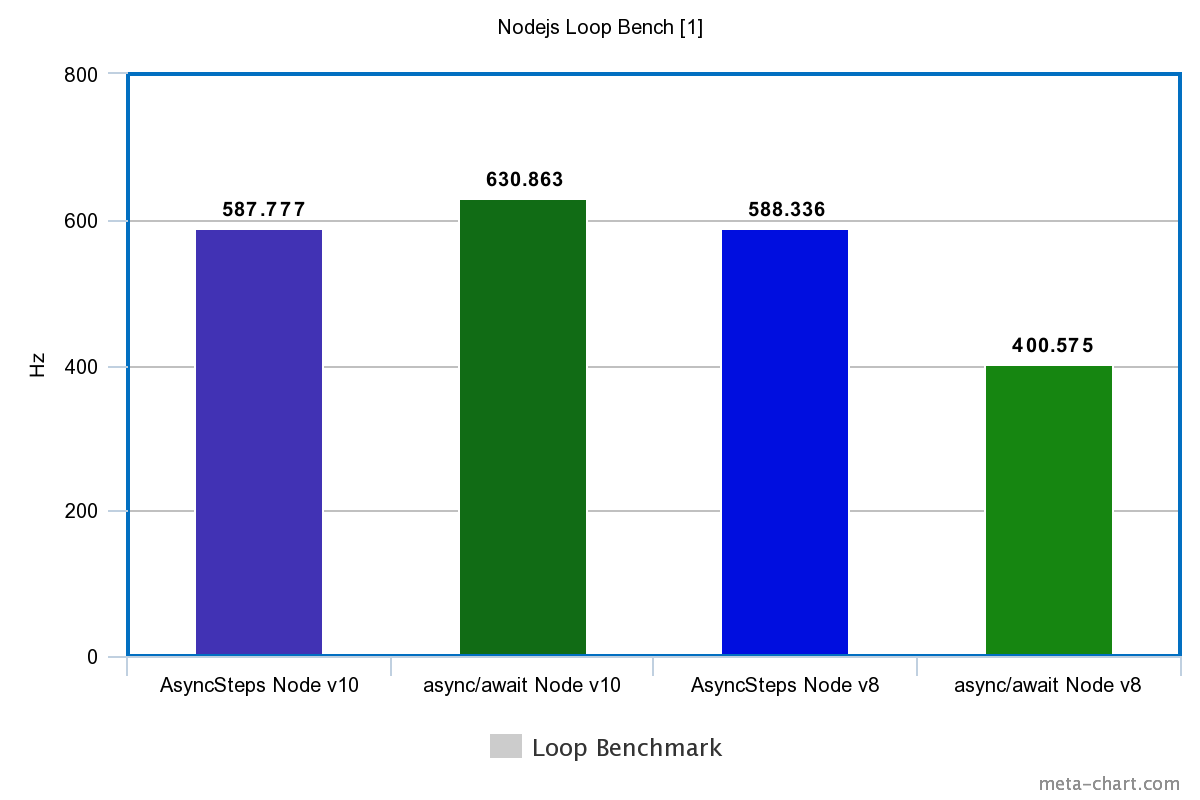
More is better.
Sudden defeat async/await? Yes, but in V8 for Node.js v10, we tightened the optimization of the cycles and it became a little better.
It should be added that implementation of Promise and async/awaitblocks Node.js Event Loop. An endless loop without waiting for an external event simply hangs the process ( proof ), but this does not happen with FutoIn AsyncSteps.
A periodic exit from AsyncSteps in the Node.js Event Loop is the reason for a false victory async/awaitin the test loop on Node.js v10.
I will make a reservation that it will be incorrect to compare the performance indicators with C ++ - a different implementation of the testing methodology. For approximation, the results of testing cycles Node.js need to be multiplied by 10 thousand.
findings
Using the example of C ++, FutoIn AsyncSteps and Boost.Fiber show similar long-term performance and memory consumption, but at the launch of Boost.Fiber seriously loses and is limited by system limits on the number mmap()/mprotect.
Maximum performance depends on efficient use of the cache, but in real life, business logic data can put more pressure on the cache than implementation of coroutines. The question of a full-fledged planner remains open.
FutoIn AsyncSteps for JavaScript excels async/awaitin performance even in the latest version of Node.js v10.
Ultimately, the main load should be directly from business logic, and not from the implementation of the concept of asynchronous programming. Therefore, minor deviations should not be a significant argument.
Reasonably written business logic introduces asynchronous transitions only when it is implied to wait for an external event in any form or when the volume of data being processed is too large and blocks the “iron” flow of execution for a long time. An exception to this rule is writing library APIs.
Conclusion
Fundamentally, the FutoIn AsyncSteps interface is simpler, clearer and more functional than any of the competitors without sugar async/await. In addition, it is implemented by standard means and unified for all technologies. As in the case Promiseof ECMAScript, AsyncSteps can get its "sugar" and its support in compilers or runtimes of almost any language.
Performance measurements of poorly optimized implementations show comparable and even superior results with respect to alternative technologies. The flexibility of a possible implementation is proven by two different approaches of AsyncSteps and NitroSteps for a single interface.
In addition to the above specification , there is user-oriented documentation .
Upon request, it is possible to implement a version for Java / JVM or any other language with adequate anonymous functions — otherwise the readability of the code falls. Any assistance to the project is welcome.
If you really like this alternative, feel free to put stars on GitHub and / or GitLab .