How to use static analysis correctly
Now they are increasingly talking about static analysis to search for vulnerabilities as a necessary stage of development. However, many talk about the problems of static analysis. We talked a lot about this in the past Positive Hack Days , and based on the results of these discussions, we already wrote about how the static analyzer works. If you have tried any serious tool, you might be frightened off by long reports with confusing recommendations, difficulty setting up the tool and false positives. So is static analysis needed?
Our experience tells you what you need. And many problems that arise when you first look at the tool, it is quite possible to solve. I will try to tell you what the user can do and what the analyzer should be, so that its use is useful, and does not contribute “another unnecessary tool that security personnel require.”

So, we have already talked about the theoretical limitations of static analysis. For example, deep static analysis tries to solve problems exponential in complexity. Therefore, each tool seeks a trade-off between work time, resources expended, the number of vulnerabilities found and the number of false positives.
Why do you need a deep analysis? Any IDE very quickly finds errors, sometimes even related to security - what are some exponential problems? A classic example is SQL injection (and any other injection, such as XSS, RCE, and the like) that goes through several functions (that is, reading data from the user and executing the query occur in different functions). To search for it, an interprocedural analysis of the data flow is needed, and this is a problem of exponential complexity. You must admit that analysis of such vulnerabilities cannot be considered deep. For the same reason, you need to analyze the code in its entirety, and not in parts - otherwise you can miss interprocedural vulnerabilities.
In recent years, I have gained a lot of experience in communicating with (potential) customers of various static analyzers. Including we are discussing claims to the instruments based on the results of the first use (pilot). Most claims in one way or another follow from the theoretical limitations of the technology. In addition, the tools may simply not have the desired user functionality. However, in my opinion, analyzers can move (and move) towards the user in terms of solving the problems identified further. But you also need to be able to use analyzers, leveling the consequences of these same problems - as it turns out, this is not so difficult. Let's take it in order.
You can imagine a model situation: you decide to try the technology in action or choose a static analyzer - conduct a pilot. Of course, you do not trust the test examples of the vendor and want to try to analyze your code (at the same time you can find real vulnerabilities and fix them). You are provided with an installer or a ready-made virtual machine with a system for a short time.
First you need to run the analysis. You enter the interface, and, it seems, everything should be clear: we load the archive with the source code into the form and click “analyze”. But no: you get several forms with different fields that you need to somehow fill out. It is necessary to specify programming languages, some analyzer settings, select vulnerability packages (how do you know what is included in them?) And so on. You pass this test, and the analysis begins. And no - scanning error. “The format does not meet the requirements,” “This language requires code assembly,” “No files were found for scanning” ... If you did not write this code yourself, you will still have to go to the developers for help.

The developer delivers the source code for testing.
Separate attention is given to the requirements for the assembly of the code. Most analyzers for a number of languages require that code be compiled during analysis (JVM languages - Java, Scala, Kotlin and the like, C / C ++, Objective-C, C #). You understand what a pain it is: to reproduce the environment of a large project for assembly on a new machine. On the other hand, these requirements are justified, they follow from the technology of analysis and the specifics of these languages.
How do analyzers solve these problems? First, they make the launch of the analysis as automated as possible. Ideally, it is enough to load a file of any format, and the analyzer itself should understand what languages there are, how to try to build and how to set the rest of the default settings so that the results are as complete as possible. It is clear that you can not foresee everything - but you can try to handle most of the cases.
Assembly requirements should be made as soft as possible. For example, for JVM languages, it is not necessary to require assembly during analysis — all you have to do is download the artifacts, that is, the collected code along with the source code (and this is much simpler). For Xcode, in the case of Objective-C, the assembly can be automated for most cases. If it failed to collect the code, the analyzer may try to carry out a partial analysis. Its results will not be so complete, but it is better than no results at all. It is also convenient if the analysis module can be delivered to the developer’s machine, where the assembly of the code is already configured, and the architecture should allow the remaining modules and the interface part to be transferred to another machine.
Finally, the analyzer should make the most gentle format requirements and deal with the input files. Archive with source code, attached archives, archive from repository, link to repository, archive from production, executable file from production - it’s good if the analyzer supports all this.
However, one should not forget that the analyzer does not possess artificial intelligence and cannot foresee everything. Therefore, when errors occur, it is worth getting acquainted with the manual - there is a lot of useful information on preparing code for analysis. Well, all this work on launching a scan when implementing an analyzer is done only once for each code base. Most often, the analyzer is generally embedded in the CI cycle, that is, there will be no problems with the assembly.
Okay, the scan started. An hour passes - no results. Progress bar hangs somewhere in the middle, it is unclear with what percentage and what is the forecast at the end. The second hour passes - the progress has moved by 99 percent and has been hanging there for half an hour. The third hour passes - and the analyzer drops, reporting a lack of RAM. Or hangs another hour and ends. You could expect the analysis to go as fast as your checkstyle, and then the expectations will diverge dramatically from reality.

Yes, a good static analyzer can consume a lot of resources, one of the reasons I mentioned above: finding complex vulnerabilities is an exponentially difficult task. So the more resources there are and the more time, the better the results will be (with a good engine, of course). It is really difficult to predict both the analysis time and the required resources - the operation time of the static analysis algorithms depends heavily on language constructs, on the complexity of the code, on the depth of the calls - on characteristics that are difficult to calculate in advance.
The problem with resources is a necessary evil. You need to be careful about allocating the necessary resources, patiently waiting for the scan to finish, and also understand that no one can predict exactly the resources required for the analyzer, even with a given code base, and you should be prepared to change these parameters. Moreover, the required parameters may change even without updating the code base - due to the update of the analyzer.
Nevertheless, the analyzer can help a little with this problem. It is able to separate the resource-intensive part (engines) and the interface according to different machines. This will allow not to load the machines with unnecessary programs that will slow down their work, thus it will be possible to use the system interface for any workload on scans (for example, to view and edit the results). It will also allow for easy scaling without reinstalling the entire system (raising the analyzer on a new virtual machine, specifying the IP of the main machine - and voila).
In addition, the analyzer can allow to select the analysis depth, disable heavy checks, use incremental analysis (which does not check all the code, but only the changed one). These things need to be used very carefully, as they can greatly influence the scan results. If you use this functionality, it is recommended to perform a full analysis with some frequency.
Let us turn to the results of the scan (for a long time we went to them). With trepidation you are waiting for the number of vulnerabilities in the analyzer window, and you are very surprised to see it. 156 critical, 1260 medium and 3210 low. You visit the results page and drown in the number of problems found. You upload a pdf-report - and see several thousand pages of text. Guess what the code developer will say when he sees such a canvas?

Bezpehnik lucky developer developer report on vulnerabilities
But let's still try to see the results, give him a chance. After studying a few dozen occurrences more closely, you begin to understand why there are so many vulnerabilities. Several vulnerabilities and the truth look serious, you understand that they need to be fixed. However, immediately you find a dozen false. And also - a huge number of vulnerabilities in library code. You will not fix the library! And then you understand how much time you spend on the analysis of the results. And this procedure should be repeated every day, week, or at least every release. (Not really).
To begin with, the falsity of triggering can be understood in very different ways. Someone will not consider as false only critical vulnerabilities that can be exploited right now. Someone will consider as false only explicit errors of the analyzer. Much depends on what you want from the tool. We recommend considering virtually all occurrences, since even a low-level vulnerability, which cannot be exploited now, can become a serious problem tomorrow — for example, when code and external conditions change.
Ok, you have to look at all the entries, but this is still a huge amount of work. And here analyzers can help very well. The most important function of the analyzer is the ability to track vulnerabilities between scans of a single project, while keeping track of it is resistant to small changes that are standard for developing code. This removes the problem that a long analysis of vulnerabilities needs to be repeated: the first time you spend more time removing false alarms and changing the criticality of the entries, but then you will need to look only at new vulnerabilities that will be several times smaller.
Good, but is it the first time to look through all the vulnerabilities? We recommend doing this, but generally speaking, this is not necessary. First, analyzers allow you to filter results by directories and files: for example, when you start a scan, you can immediately exclude from the analysis some components, libraries, test code. This will affect the speed of analysis. Secondly, analyzers allow you to filter the results by vulnerabilities, that is, when starting a scan, you can limit the set of vulnerabilities. Finally, in addition to criticality, the analyzer can produce something like the probability of falsehood of vulnerability (that is, its confidence in this vulnerability). Using this metric, you can filter the results.
Separately, it is worth noting the technology Software Composition Analysis (it is now beginning to support an increasing number of tools at different levels). The technology allows you to detect the use of libraries in your code, determine the names and versions, show known vulnerabilities, as well as licenses. This technology can separate library code from your own, which also allows you to filter results.
It turns out that it is possible to fight the problem of abundant analysis results, and this is not very difficult. And although the first viewing of the results may indeed take time, then it will be spent less and less when rescanning it. However, I note once again that any filtering of results must be treated carefully - you can skip the vulnerability. Even if the library is known, it does not mean that there is no vulnerability in it. If now this vulnerability is detected poorly (that is, the tool shows a lot of false positives of this vulnerability), and you disable it, when updating the analyzer, you can skip the real vulnerability.
Deal with a large report and false positives. But you want to go further - make sure that the analyzer finds those vulnerabilities that you know for certain (you could have intentionally laid them out, or another tool found them).

For a start, it is important to understand that the analyzer could not find vulnerability for various reasons. The simplest thing is that the scan was incorrectly configured (you need to pay attention to error messages). But also from the point of view of technology of the analysis, the reasons may be different. A static analyzer consists of two important components: the engine (it contains all the algorithmic complexity and mathematics) and the base of the rules for searching vulnerabilities. One situation is when the engine allows you to find a vulnerability of this class, but there is no vulnerability in the rule base. In this case, it is usually not difficult to add a rule. A completely different situation, if the engine in principle does not support such vulnerabilities - here the refinement can be very significant. I gave an example at the beginning of the article: you will never find a SQL injection without data flow analysis algorithms.
A static analyzer should implement in the engine a set of algorithms covering the available classes of vulnerabilities for a given programming language (analysis of control flow, data flow, interval analysis, etc.). An important point is the ability to add your own vulnerability search rules to the tool - this will eliminate the first reason for missing a vulnerability.
Thus, if you did not find the existing vulnerability in the scan results, you first need to understand the reason for the skip - usually a vendor can help with this. If the reason is in the rule base or in the scan configuration, then the situation can be fairly easily resolved. The most important thing is to assess the depth of the analysis, that is, what basically allows you to search for the engine.
After reading the article to this point, we can assume that to work with the tool requires a deep examination of the developer, because you need to understand what the false positives, and what are true. In my opinion, it all depends on how friendly the tool behaves. If it provides convenient and understandable functionality, understandable descriptions of vulnerabilities with examples, links and recommendations in different languages, if the tool shows traces for vulnerabilities associated with data flow analysis, working with it will not require deep developer expertise with an understanding of all the subtleties of a programming language and frameworks. However, there should be a minimal background in the development in order to read the code.
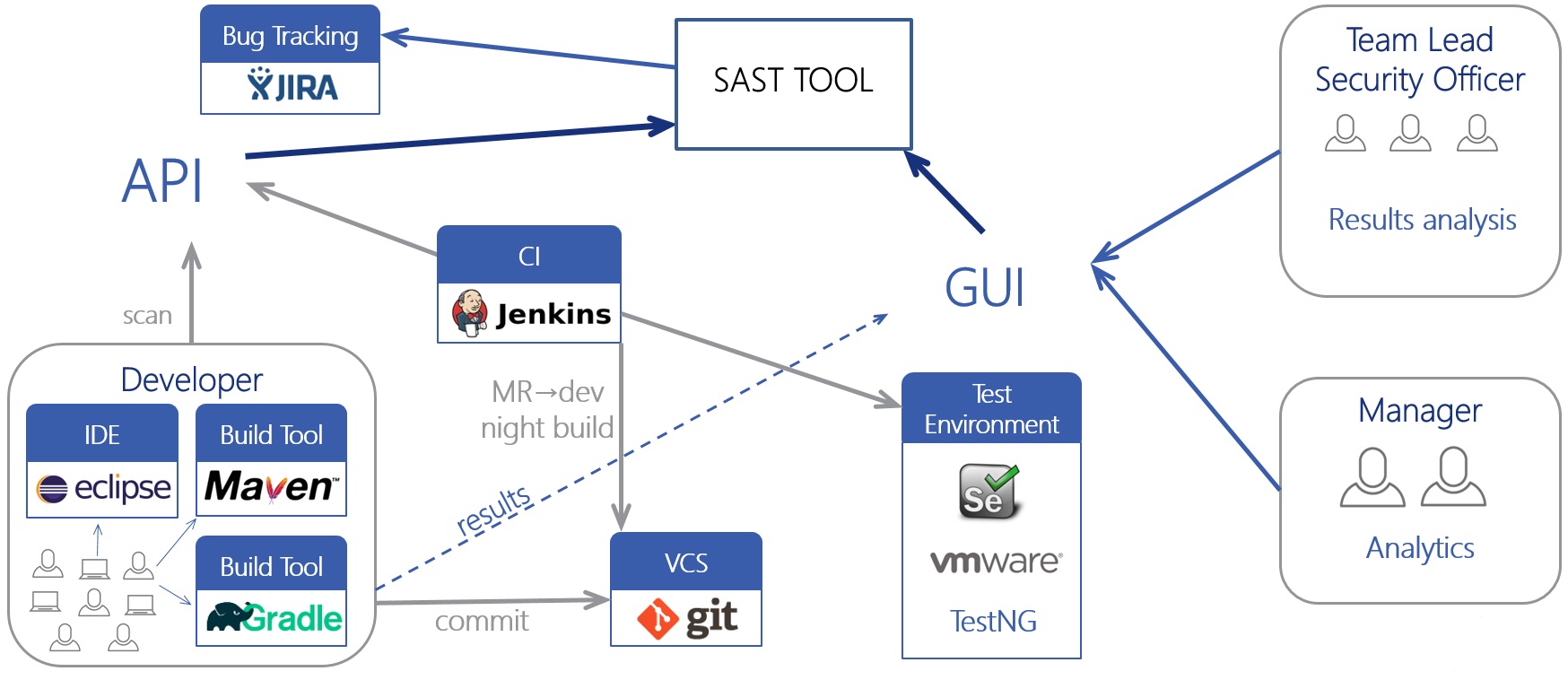
At the end of the article we will briefly touch on one of the most important issues of using the tool, and consider it in detail in the following articles. Suppose you decide to use a static analyzer. However, you have a streamlined development process, both technological and organizational, and you don’t want to change it (no one will).
The tool must have a full non-graphical interface (for example, CLI or REST API), with which you can embed the analyzer into any of your processes. It is good if the analyzer has ready-made integrations with various components: plug-ins for IDE or build systems, integration with version control systems, plug-ins for CI / CD servers (Jenkins, TeamCity), integration with project management systems (JIRA), or work with users ( Active Directory).
Integration of static analysis into the development process (the so-called SDLC) is the most effective way to use if the process is well established and all participants have agreed and know why. Constant analysis of the code after its changes or updates of the analyzer will allow finding vulnerabilities as early as possible. Separating the roles of developers and IS specialists, a clear indication of IS requirements and smooth integration into the current process (for example, at first - the advisory nature of the system) will allow the tool to be used without serious consequences. However, no one has canceled the manual use of the tool, unless your development model involves a similar process.
The article contains basic recommendations on how to start using a static analyzer. A good analyzer works an order of magnitude better than any lightweight checker; it searches for problems of a fundamentally different complexity. Therefore, it is necessary to take into account the features of static analysis as a technology, but at the same time choose a specific tool so that its functionality smoothes out all such features as much as possible.
Our experience tells you what you need. And many problems that arise when you first look at the tool, it is quite possible to solve. I will try to tell you what the user can do and what the analyzer should be, so that its use is useful, and does not contribute “another unnecessary tool that security personnel require.”
About static analysis
So, we have already talked about the theoretical limitations of static analysis. For example, deep static analysis tries to solve problems exponential in complexity. Therefore, each tool seeks a trade-off between work time, resources expended, the number of vulnerabilities found and the number of false positives.
Why do you need a deep analysis? Any IDE very quickly finds errors, sometimes even related to security - what are some exponential problems? A classic example is SQL injection (and any other injection, such as XSS, RCE, and the like) that goes through several functions (that is, reading data from the user and executing the query occur in different functions). To search for it, an interprocedural analysis of the data flow is needed, and this is a problem of exponential complexity. You must admit that analysis of such vulnerabilities cannot be considered deep. For the same reason, you need to analyze the code in its entirety, and not in parts - otherwise you can miss interprocedural vulnerabilities.
In recent years, I have gained a lot of experience in communicating with (potential) customers of various static analyzers. Including we are discussing claims to the instruments based on the results of the first use (pilot). Most claims in one way or another follow from the theoretical limitations of the technology. In addition, the tools may simply not have the desired user functionality. However, in my opinion, analyzers can move (and move) towards the user in terms of solving the problems identified further. But you also need to be able to use analyzers, leveling the consequences of these same problems - as it turns out, this is not so difficult. Let's take it in order.
You can imagine a model situation: you decide to try the technology in action or choose a static analyzer - conduct a pilot. Of course, you do not trust the test examples of the vendor and want to try to analyze your code (at the same time you can find real vulnerabilities and fix them). You are provided with an installer or a ready-made virtual machine with a system for a short time.
Run analysis
First you need to run the analysis. You enter the interface, and, it seems, everything should be clear: we load the archive with the source code into the form and click “analyze”. But no: you get several forms with different fields that you need to somehow fill out. It is necessary to specify programming languages, some analyzer settings, select vulnerability packages (how do you know what is included in them?) And so on. You pass this test, and the analysis begins. And no - scanning error. “The format does not meet the requirements,” “This language requires code assembly,” “No files were found for scanning” ... If you did not write this code yourself, you will still have to go to the developers for help.
The developer delivers the source code for testing.
Separate attention is given to the requirements for the assembly of the code. Most analyzers for a number of languages require that code be compiled during analysis (JVM languages - Java, Scala, Kotlin and the like, C / C ++, Objective-C, C #). You understand what a pain it is: to reproduce the environment of a large project for assembly on a new machine. On the other hand, these requirements are justified, they follow from the technology of analysis and the specifics of these languages.
How do analyzers solve these problems? First, they make the launch of the analysis as automated as possible. Ideally, it is enough to load a file of any format, and the analyzer itself should understand what languages there are, how to try to build and how to set the rest of the default settings so that the results are as complete as possible. It is clear that you can not foresee everything - but you can try to handle most of the cases.
Assembly requirements should be made as soft as possible. For example, for JVM languages, it is not necessary to require assembly during analysis — all you have to do is download the artifacts, that is, the collected code along with the source code (and this is much simpler). For Xcode, in the case of Objective-C, the assembly can be automated for most cases. If it failed to collect the code, the analyzer may try to carry out a partial analysis. Its results will not be so complete, but it is better than no results at all. It is also convenient if the analysis module can be delivered to the developer’s machine, where the assembly of the code is already configured, and the architecture should allow the remaining modules and the interface part to be transferred to another machine.
Finally, the analyzer should make the most gentle format requirements and deal with the input files. Archive with source code, attached archives, archive from repository, link to repository, archive from production, executable file from production - it’s good if the analyzer supports all this.
However, one should not forget that the analyzer does not possess artificial intelligence and cannot foresee everything. Therefore, when errors occur, it is worth getting acquainted with the manual - there is a lot of useful information on preparing code for analysis. Well, all this work on launching a scan when implementing an analyzer is done only once for each code base. Most often, the analyzer is generally embedded in the CI cycle, that is, there will be no problems with the assembly.
Analysis process
Okay, the scan started. An hour passes - no results. Progress bar hangs somewhere in the middle, it is unclear with what percentage and what is the forecast at the end. The second hour passes - the progress has moved by 99 percent and has been hanging there for half an hour. The third hour passes - and the analyzer drops, reporting a lack of RAM. Or hangs another hour and ends. You could expect the analysis to go as fast as your checkstyle, and then the expectations will diverge dramatically from reality.
Yes, a good static analyzer can consume a lot of resources, one of the reasons I mentioned above: finding complex vulnerabilities is an exponentially difficult task. So the more resources there are and the more time, the better the results will be (with a good engine, of course). It is really difficult to predict both the analysis time and the required resources - the operation time of the static analysis algorithms depends heavily on language constructs, on the complexity of the code, on the depth of the calls - on characteristics that are difficult to calculate in advance.
The problem with resources is a necessary evil. You need to be careful about allocating the necessary resources, patiently waiting for the scan to finish, and also understand that no one can predict exactly the resources required for the analyzer, even with a given code base, and you should be prepared to change these parameters. Moreover, the required parameters may change even without updating the code base - due to the update of the analyzer.
Nevertheless, the analyzer can help a little with this problem. It is able to separate the resource-intensive part (engines) and the interface according to different machines. This will allow not to load the machines with unnecessary programs that will slow down their work, thus it will be possible to use the system interface for any workload on scans (for example, to view and edit the results). It will also allow for easy scaling without reinstalling the entire system (raising the analyzer on a new virtual machine, specifying the IP of the main machine - and voila).
In addition, the analyzer can allow to select the analysis depth, disable heavy checks, use incremental analysis (which does not check all the code, but only the changed one). These things need to be used very carefully, as they can greatly influence the scan results. If you use this functionality, it is recommended to perform a full analysis with some frequency.
Analysis results
Let us turn to the results of the scan (for a long time we went to them). With trepidation you are waiting for the number of vulnerabilities in the analyzer window, and you are very surprised to see it. 156 critical, 1260 medium and 3210 low. You visit the results page and drown in the number of problems found. You upload a pdf-report - and see several thousand pages of text. Guess what the code developer will say when he sees such a canvas?
Bezpehnik lucky developer developer report on vulnerabilities
But let's still try to see the results, give him a chance. After studying a few dozen occurrences more closely, you begin to understand why there are so many vulnerabilities. Several vulnerabilities and the truth look serious, you understand that they need to be fixed. However, immediately you find a dozen false. And also - a huge number of vulnerabilities in library code. You will not fix the library! And then you understand how much time you spend on the analysis of the results. And this procedure should be repeated every day, week, or at least every release. (Not really).
To begin with, the falsity of triggering can be understood in very different ways. Someone will not consider as false only critical vulnerabilities that can be exploited right now. Someone will consider as false only explicit errors of the analyzer. Much depends on what you want from the tool. We recommend considering virtually all occurrences, since even a low-level vulnerability, which cannot be exploited now, can become a serious problem tomorrow — for example, when code and external conditions change.
Ok, you have to look at all the entries, but this is still a huge amount of work. And here analyzers can help very well. The most important function of the analyzer is the ability to track vulnerabilities between scans of a single project, while keeping track of it is resistant to small changes that are standard for developing code. This removes the problem that a long analysis of vulnerabilities needs to be repeated: the first time you spend more time removing false alarms and changing the criticality of the entries, but then you will need to look only at new vulnerabilities that will be several times smaller.
Good, but is it the first time to look through all the vulnerabilities? We recommend doing this, but generally speaking, this is not necessary. First, analyzers allow you to filter results by directories and files: for example, when you start a scan, you can immediately exclude from the analysis some components, libraries, test code. This will affect the speed of analysis. Secondly, analyzers allow you to filter the results by vulnerabilities, that is, when starting a scan, you can limit the set of vulnerabilities. Finally, in addition to criticality, the analyzer can produce something like the probability of falsehood of vulnerability (that is, its confidence in this vulnerability). Using this metric, you can filter the results.
Separately, it is worth noting the technology Software Composition Analysis (it is now beginning to support an increasing number of tools at different levels). The technology allows you to detect the use of libraries in your code, determine the names and versions, show known vulnerabilities, as well as licenses. This technology can separate library code from your own, which also allows you to filter results.
It turns out that it is possible to fight the problem of abundant analysis results, and this is not very difficult. And although the first viewing of the results may indeed take time, then it will be spent less and less when rescanning it. However, I note once again that any filtering of results must be treated carefully - you can skip the vulnerability. Even if the library is known, it does not mean that there is no vulnerability in it. If now this vulnerability is detected poorly (that is, the tool shows a lot of false positives of this vulnerability), and you disable it, when updating the analyzer, you can skip the real vulnerability.
Check the analyzer
Deal with a large report and false positives. But you want to go further - make sure that the analyzer finds those vulnerabilities that you know for certain (you could have intentionally laid them out, or another tool found them).
For a start, it is important to understand that the analyzer could not find vulnerability for various reasons. The simplest thing is that the scan was incorrectly configured (you need to pay attention to error messages). But also from the point of view of technology of the analysis, the reasons may be different. A static analyzer consists of two important components: the engine (it contains all the algorithmic complexity and mathematics) and the base of the rules for searching vulnerabilities. One situation is when the engine allows you to find a vulnerability of this class, but there is no vulnerability in the rule base. In this case, it is usually not difficult to add a rule. A completely different situation, if the engine in principle does not support such vulnerabilities - here the refinement can be very significant. I gave an example at the beginning of the article: you will never find a SQL injection without data flow analysis algorithms.
A static analyzer should implement in the engine a set of algorithms covering the available classes of vulnerabilities for a given programming language (analysis of control flow, data flow, interval analysis, etc.). An important point is the ability to add your own vulnerability search rules to the tool - this will eliminate the first reason for missing a vulnerability.
Thus, if you did not find the existing vulnerability in the scan results, you first need to understand the reason for the skip - usually a vendor can help with this. If the reason is in the rule base or in the scan configuration, then the situation can be fairly easily resolved. The most important thing is to assess the depth of the analysis, that is, what basically allows you to search for the engine.
Competences
After reading the article to this point, we can assume that to work with the tool requires a deep examination of the developer, because you need to understand what the false positives, and what are true. In my opinion, it all depends on how friendly the tool behaves. If it provides convenient and understandable functionality, understandable descriptions of vulnerabilities with examples, links and recommendations in different languages, if the tool shows traces for vulnerabilities associated with data flow analysis, working with it will not require deep developer expertise with an understanding of all the subtleties of a programming language and frameworks. However, there should be a minimal background in the development in order to read the code.
Integration into the development process
At the end of the article we will briefly touch on one of the most important issues of using the tool, and consider it in detail in the following articles. Suppose you decide to use a static analyzer. However, you have a streamlined development process, both technological and organizational, and you don’t want to change it (no one will).
The tool must have a full non-graphical interface (for example, CLI or REST API), with which you can embed the analyzer into any of your processes. It is good if the analyzer has ready-made integrations with various components: plug-ins for IDE or build systems, integration with version control systems, plug-ins for CI / CD servers (Jenkins, TeamCity), integration with project management systems (JIRA), or work with users ( Active Directory).
Integration of static analysis into the development process (the so-called SDLC) is the most effective way to use if the process is well established and all participants have agreed and know why. Constant analysis of the code after its changes or updates of the analyzer will allow finding vulnerabilities as early as possible. Separating the roles of developers and IS specialists, a clear indication of IS requirements and smooth integration into the current process (for example, at first - the advisory nature of the system) will allow the tool to be used without serious consequences. However, no one has canceled the manual use of the tool, unless your development model involves a similar process.
Summary
The article contains basic recommendations on how to start using a static analyzer. A good analyzer works an order of magnitude better than any lightweight checker; it searches for problems of a fundamentally different complexity. Therefore, it is necessary to take into account the features of static analysis as a technology, but at the same time choose a specific tool so that its functionality smoothes out all such features as much as possible.