WebServer as a test task
How it all started
Despite the fact that my work at the moment is related to desktop applications, I have recently been interested in “server technologies”. Some surfing the Internet, reading man'ov and trying to write something server-like for yourself - this is all that has been done recently, as there is no clear goal. Having come up with an interesting task, you can improve your skill level not badly.
At one point when I was finally bored at work from the routine, I checked the one of the well-known job search resources, that I don’t mind looking at the market, all of a sudden, what’s interesting will come up ... As a result, a certain number of job offers on the topic: “Perhaps it will interest you.” Among these offers, there was an offer with a test task. Test task - to write WebServer in C ++ under Linux with the implementation of the HTTP protocol; simple ...
Taking the phrase from the test task and driving it into Google, I found more reviews about this not the shortest test task on the RSDN forum. The task was one to one lying in my mailer. As an assignment, he did not. The principle is simple: if the test task is worth it, it should be designed for no more than 4 hours of working time. But to try everything that was read and tried in places was interesting. This became an incentive, i.e. statement of an interesting problem. I can’t say which office this task belongs to, since it came from a recruiting agency, but it’s not so important either.
This article will examine the approaches and related APIs that I have found on this topic. I will give several implementations of WebServer using different approaches and tools, a comparative testing of the received "crafts" was conducted. The article is not intended for “bearded” server writers, but as a review, people who encounter similar tasks (not only in tests) may well be useful. I will be glad to have constructive comments from everyone, especially from “bearded” server-writers, since writing an article is not only about sharing experience, but, it may well be, replenishing it for yourself ...
Overview of APIs and Libraries
The result of consideration of the server-side scripting tools was the API * nix of systems, the Windows API (why not see, although there is no such platform for the purpose of this task), and libraries such as boost.asio and libevent.
Berkeley sockets, although a universal, portable mechanism, but it is not entirely unambiguously ported. So in some platforms close to close the socket, and in some closesocket; some need to initialize the library (Windows - WSAStartup / WSACleanup), some do not; somewhere, the socket descriptor is the int type, and somewhere, SOCKET and other minor differences. It turns out that if you do not apply all sorts of cross-platform programming approaches such as pImpl and others, then the same code will not work, and often it will be built on different platforms the same way. All these little things are hidden in type libraries.boost.asio , libevent and similar. In addition, such libraries use more specific API methods of the corresponding platform to implement the most optimal work with sockets, providing the user with a convenient interface without hints of the platform.
If we take the server’s work in a very generalized way, we get the following sequence of actions:
- Create socket
- Bind a socket to a network interface
- Listen to a socket bound to a specific network interface
- Accept incoming connections
- Respond to events on sockets
All points except the fifth are relatively similar and of little interest, but there are many mechanisms for responding to events occurring on a socket, and most of them are specific to each platform.
If you look at Windows, you can see the following methods:
- Using select. Basically, for compatibility with the code of other platforms, it has no more advantages here.
- WSAAsyncSelect - Designed for windowed applications to send events on a socket to a windowed queue. Not fast and is unlikely to be interesting as a server code mechanism.
- WSAEventSelect work with the event object on the network interface. Already a more attractive tool. Those. if you are planning a server for no more than hundreds of simultaneously serviced connections, then this is the most optimal mechanism by the criterion of performance / development speed.
- Overlapping I / O is a faster mechanism than WSAEventSelect, but it is also more time-consuming to develop.
- I / O completion ports - for high-load server applications.
There is an excellent book on developing network software for Windows - "Programming in Microsoft Windows Networks."
Now, if you look at * nix systems, then there is also a small set of event selectors:
- The same select. And again, his role is compatibility with other platforms. It is also not fast, since it is triggered (returns control) when an event occurs on any of the sockets that it is observing. After such an operation, you need to run through everything and look at which of the sockets the event occurred. Summarizing: one operation is a run across the pool of observed sockets.
- poll is a faster mechanism, but is not designed for a large number of sockets for monitoring.
- epoll (Linux systems) and kqueue (FreeBSD) are roughly the same mechanisms, but furious FreeBSD fans in some forums very eagerly insist that kqueue is much more powerful. We will not foment holy wars ... These mechanisms can be considered the main when writing highly loaded server applications in * nix systems. If you briefly describe their principle of operation and its dignity, they return a certain amount of information related only to those sockets on which something happened and you do not need to run around and check what happened and where. Also, these mechanisms are designed for a larger number of simultaneously serviced connections.
In addition to functions for waiting for events on descriptors, there are some more small but very useful things:
- sendfile (Linux) and TransmitFile (Windows) allow them to feed a couple of descriptors “from” and “where” to send data. A very useful thing in HTTP servers when you need to transfer files, as it eliminates the need for buffer allocation and calling read / write functions, which positively affects performance.
- aio - allows you to transfer a certain amount of work to the operating system, as it makes it possible to carry out asynchronous operations on a file descriptor. For example, tell the system a buffer for you, write it here in this file descriptor, how to finish the signal (similarly with reading).
- The Neigl algorithm is a useful thing when writing applications that need to send data to the network in small portions and without buffering delays, but it is not always useful. In applications such as an HTTP server, it is better to tell the system to buffer the outgoing data and send it to the TCP frames as much as possible with useful information (for this you can use a socket option like TCP_CORK).
- And of course, non-blocking sockets. No comments...
- There are also functions such as writev (nix) (and similar WSA functions of Windows) that allow you to send several buffers at once, which is useful when you need to send an HTTP packet header and data attached to it and at the same time save on the number of system calls.
It is better to say about using libraries with a code to begin with, which will be done below on the examples of boost.asio and libevent. boost.asio greatly simplifies the development of network applications, libevent is a server classic.
Epoll implementation
Whatever mechanism is chosen to respond to network events epoll, poll, select, there are still many other nuances.
One of the very first issues when implementing a multi-threaded server is the choice of the number of threads. Most of those who once had to quickly assemble their “socket server” for training or pseudo-combat purposes chose the strategy “One connection - one thread”. This approach has both its pros and cons. The biggest plus is the ease of development. There are many disadvantages: a large number of expended system resources, a lot of synchronization actions (code, something synchronizing with something). However, this approach is not bad for the HTTP server in terms of synchronization, since there are no special intersections between sessions. But, despite the simplicity of development, I did not consider this strategy for its implementation. There are different recommendations on the optimal choice of the number of threads - this is the number of processors / processor cores in the system, the same number, but with a certain coefficient. In the proposed implementation, the number of workflows is an optional parameter specified by the user when the server starts. For myself, it was decided that the number of workflows is equal to the number of processors / cores times two.
In the current context, a workflow should be understood as a thread that processes user requests. In addition to these flows, two more were involved: the listening stream and the main one. Listening stream - listens to the server socket and accepts incoming connections, then they are queued for workflows for processing. The main thread - starts the server and waits for a certain action from the user to stop it.
The second question that interested me when implementing this example was what flows and how to handle network events when using epoll. The first thing that occurred to me was to react to all events monitored by epoll in one thread, and to process them in other threads (workers), passing them there through a certain queue. Those. one thread monitors both incoming events on the listening socket, and events about the arrival of data on received connections and events about closing the connection. Got an event, put it in a queue, signaled to worker threads, worker threads called accept to accept a new connection, added epoll, read, write and close to the pool of observed sockets for connections. The decision is wrong, because while processing one event, say reading data from a socket, A socket closure event may already be in the queue on this socket. Of course, the reading will end with an error, but it will not immediately come to the steps to clear all resources related to the connection, but only when subtracting this event from the queue. Many socket closure events were simply lost in my implementation. Implementation became more complicated, the number of synchronization locations grew and under strange conditions there were drops. The falls were for a different reason. With each socket in the structure of the epoll event as user data, a pointer was attached to the session object, which was responsible for all work with the client until it was closed. Since the sequence of event processing became more complicated, this caused a fall, since the object attached as user data was already deleted (for example, when closing a session not from an outside event, and according to the logic of the session itself inside it), and in the queue there was still an event on the side with an already broken pointer. Having received some such experience "on the rake" from the first idea that came up, a different strategy was adopted: the main listening stream through epoll responds only to events on the listening socket, accepts incoming connections and, if their number is more than allowed for the waiting queue, then closes them otherwise, queues the received connections for processing; workflows subtract this queue, put this socket already in their epoll set, which they observe. It turns out that workflows work with their epoll descriptor and everything is done within the same thread: placing in epoll, responding to events of data arrival, reading / writing, closing (deletion from epoll occurs automatically at the system level when the handle is closed) . As a result of such an organization, there is only one synchronization primitive to protect the queue of incoming connections. On the one hand, only the listening stream writes to this queue, and on the other hand, the received threads are selected from it for received connections. One less problem. It remains to abandon the binding of the pointer to the session object with the user data of the epoll structure. Solution: use an associative array; the key is a socket descriptor, data is a session object. This allows you to work with sessions not only when an event occurs, when we have the opportunity to get user data from the epoll event, but also when, according to some logic, it is necessary, for example, to close some connections by timeout (the connection pool is available). only the listening stream writes to this queue, and on the other hand, it accepts received connections from the worker threads. One less problem. It remains to abandon the binding of the pointer to the session object with the user data of the epoll structure. Solution: use an associative array; the key is a socket descriptor, data is a session object. This allows you to work with sessions not only when an event occurs, when we have the opportunity to get user data from the epoll event, but also when, according to some logic, it is necessary, for example, to close some connections by timeout (the connection pool is available). only the listening stream writes to this queue, and on the other hand, it accepts received connections from the worker threads. One less problem. It remains to abandon the binding of the pointer to the session object with the user data of the epoll structure. Solution: use an associative array; the key is a socket descriptor, data is a session object. This allows you to work with sessions not only when an event arrives, when we have the opportunity to get user data from the epoll event, but also when, according to some logic, it is necessary, for example, to close some connections by timeout (the connection pool is available). the key is a socket descriptor, data is a session object. This allows you to work with sessions not only when an event occurs, when we have the opportunity to get user data from the epoll event, but also when, according to some logic, it is necessary, for example, to close some connections by timeout (the connection pool is available). the key is a socket descriptor, data is a session object. This allows you to work with sessions not only when an event arrives, when we have the opportunity to get user data from the epoll event, but also when, according to some logic, it is necessary, for example, to close some connections by timeout (the connection pool is available).
The first option, written entirely in one file and in the style of a C # / Java developer (without splitting into declarations and definitions), I had more than 1800 lines of code. Too much for the test task, despite the fact that the implementation of the HTTP protocol is minimal, the very minimum for processing GET / HEAD without anything else and with a minimum of processing the parameters of the HTTP header. That is not the point. Once again, the test task was just a “kick” to try something. The main interest for me in this solution was not the implementation of the HTTP protocol, but the implementation of a multi-threaded server, managing connections and sessions (a session can be understood as some logical data structure with a processing algorithm related to the connection).
Having smashed this monstrous file and combed the implementation in some places, here's what I got:
class TCPServer
: private Common::NonCopyable
{
public:
TCPServer(InetAddress const &locAddr, int backlog, int maxThreadsCount,
int maxConnectionsCount, UserSessionCreator sessionCreator);
private:
typedef std::tr1::shared_ptr IDisposablePtr;
typedef std::vector IDisposablePool;
Private::ClientItemQueuePtr AcceptedItems;
IDisposablePool Threads;
};
This is perhaps the shortest server class implementation I've had to write. This class only creates several threads: the listener and several workers, and is their holder.
Implementation
also not great. Both classes are likeTCPServer::TCPServer(InetAddress const &locAddr, int backlog, int maxThreadsCount,
int maxConnectionsCount, UserSessionCreator sessionCreator)
: AcceptedItems(new Private::ClientItemQueue(backlog))
{
int EventsCount = maxConnectionsCount / maxThreadsCount;
for (int i = 0 ; i < maxThreadsCount ; ++i)
{
Threads.push_back(IDisposablePtr(new Private::WorkerThread(
EventsCount + (i <= maxThreadsCount - 1 ? 0 : maxConnectionsCount % maxThreadsCount),
AcceptedItems
)));
}
Threads.push_back(IDisposablePtr(new Private::ListenThread(locAddr, backlog, AcceptedItems, sessionCreator)));
}
listening stream
so and class ListenThread
: private TCPServerSocket
, public Common::IDisposable
{
public:
ListenThread(InetAddress const &locAddr, int backlog,
ClientItemQueuePtr acceptedClients,
UserSessionCreator sessionCreator)
: TCPServerSocket(locAddr, backlog)
, AcceptedClients(acceptedClients)
, SessionCreator(sessionCreator)
, Selector(1, WaitTimeout, std::tr1::bind(&ListenThread::OnSelect,
this, std::tr1::placeholders::_1, std::tr1::placeholders::_2))
{
Selector.AddSocket(GetHandle(), Network::ISelector::stRead);
}
private:
enum { WaitTimeout = 100 };
ClientItemQueuePtr AcceptedClients;
UserSessionCreator SessionCreator;
SelectorThread Selector;
void OnSelect(SocketHandle handle, Network::ISelector::SelectType selectType)
{
//Принятие нового соединения, создание объекта-сессии и помещение его в очередь
}
};
work flows
use event flow classclass WorkerThread
: private Common::NonCopyable
, public Common::IDisposable
{
public:
WorkerThread(int maxEventsCount, ClientItemQueuePtr acceptedClients)
: MaxConnections(maxEventsCount)
, AcceptedClients(acceptedClients)
, Selector(maxEventsCount, WaitTimeout, std::tr1::bind(&WorkerThread::OnSelect,
this, std::tr1::placeholders::_1, std::tr1::placeholders::_2),
SelectorThread::ThreadFunctionPtr(new SelectorThread::ThreadFunction(std::tr1::bind(
&WorkerThread::OnIdle, this))))
{
}
private:
enum { WaitTimeout = 100 };
typedef std::map ClientPool;
unsigned MaxConnections;
ClientItemQueuePtr AcceptedClients;
ClientPool Clients;
SelectorThread Selector;
void OnSelect(SocketHandle handle, Network::ISelector::SelectType selectType)
{
//Реакция на события, происходящие на наблюдаемых описателях сокетов (чтение данных, их обработка, закрытие сокетов)
}
void OnIdle()
{
//Выполнение фоновых операций сессий. Вычитывание данных из очереди принятых соединений и помещение объектов-сессий в epoll.
}
}; Selectorthread
. This thread usesclass SelectorThread
: private EPollSelector
, private System::ThreadLoop
{
public:
using EPollSelector::AddSocket;
typedef System::Thread::ThreadFunction ThreadFunction;
typedef std::tr1::shared_ptr ThreadFunctionPtr;
SelectorThread(int maxEventsCount, unsigned waitTimeout, ISelector::SelectFunction onSelectFunc,
ThreadFunctionPtr idleFunc = ThreadFunctionPtr());
virtual ~SelectorThread();
private:
void SelectItems(ISelector::SelectFunction &func, unsigned waitTimeout, ThreadFunctionPtr idleFunc);
}; EPollSelector
for organizing reactions to events occurring on descriptors of accepted compounds. class EPollSelector
: private Common::NonCopyable
, public ISelector
{
public:
EPollSelector(int maxSocketCount);
~EPollSelector();
virtual void AddSocket(SocketHandle handle, int selectType);
virtual void Select(SelectFunction *function, unsigned timeout);
private:
typedef std::vector EventPool;
EventPool Events;
int EPoll;
static int GetSelectFlags(int selectType);
}; If you look at the source class of the server, you can see that the functor for creating user session classes is passed as the last parameter. A user session is an implementation of an interface
struct IUserSession
{
virtual ~IUserSession() {}
virtual void Init(IConnectionCtrl *ctrl) = 0;
virtual void Done() = 0;
virtual unsigned GetMaxBufSizeForRead() const = 0;
virtual bool IsExpiredSession(std::time_t lastActionTime) const = 0;
virtual void OnRecvData(void const *buf, unsigned bytes) = 0;
virtual void OnIdle() = 0;
};
struct IConnectionCtrl
{
virtual ~IConnectionCtrl() { }
virtual void MarkMeForClose() = 0;
virtual void UpdateSessionTime() = 0;
virtual bool SendData(void const *buf, unsigned *bytes) = 0;
virtual bool SendFile(int fileHandle, unsigned offset, unsigned *bytes) = 0;
virtual InetAddress const& GetAddress() const = 0;
virtual SocketTuner GetSocketTuner() const = 0;
};
The IConnectionCtrl interface is passed so that the user session can send data to the network (SendData and SendFile methods), mark itself as intended for closing (MarkMeForClose method), say that it is “alive” (UpdateSessionTime method; updates the time that arrives at IsExpiredSession), the same session can get the address of the incoming connection (GetAddress method) and the SocketTuner object for the socket settings - the current connection (GetSocketTuner method).
The implementation of the HTTP protocol is in the HttpUserSession class. As I said above, the HTTP implementation was not the most interesting and priority for me, so I did not think much about it; I thought exactly as much as was enough to write what happened :)
Libevent implementation
Implementation on libevent is still a favorite for me. This library makes it possible to organize asynchronous input-output and hide from the developer many of the subtleties of network programming. Allows you to implement work with raw data, hanging callback functions for receiving, transmitting data and other events, send data asynchronously. In addition to low-level data processing, there are also higher-level protocols. libevent has a built-in HTTP server, which makes it possible to abstract from parsing the request headers and generating the same response headers. It is possible to implement RPC using the library and other features.
If you implement an HTTP server using the built-in, the sequence will be something like this:
- Create some basic object by calling event_base_new (there is also a simplified one for simpler cases - event_init). The paired function for deleting an object is event_base_free.
- Create an HTTP engine object by calling evhttp_new. A paired function to delete an evhttp_free object.
- You can specify the methods that the server will support using the evhttp_set_allowed_methods function with a combination of flags. So, for example, to support only the GET method, it will look something like this: evhttp_set_allowed_methods (Http, EVHTTP_REQ_GET), where Http is the descriptor created in step (2).
- Set a callback function to handle incoming requests by calling evhttp_set_gencb.
- Associate the listening socket with an instance of the HTTP server object by calling the evhttp_accept_socket function. A listening socket can be created and configured through the same socket / bind / listen.
- Start the event loop by calling the event_base_loop function. There is a simplified option - event_base_dispatch. event_base_loop needs to be called in a loop. This function either does something useful in the bowels of the library, whence calls come to the installed callback functions, or when there is nothing to do, it returns control and you can do something useful at this moment yourself; also makes it possible to more easily control the life time of the message processing cycle.
- In the request handler, you can send some text data by calling the evbuffer_add_printf function or give the library a file descriptor and let it send it by calling evbuffer_add_file. These functions work with some buffer object that you can create yourself (and do not forget to delete it in time) or use the request field: evhttp_request :: output_buffer. All the charm is that these functions are asynchronous, i.e. In the example with sending the file, you can give the file descriptor to the same evbuffer_add_file and it will return control immediately, and after the file is sent, it will close the file itself.
Everything turns out very beautifully in one thread, but as it turned out, making a multi-threaded server is also not difficult. If you use boost :: thread or your cross-platform class that encapsulates the work of a stream, or something similar, you can get a fully cross-platform solution, since libevent is a cross-platform library. In my own implementation, I will take some wrapper only over streams for Linux. But this is not so important.
The main thread for each workflow must create its own descriptors, i.e. complete steps 1-5. Workflows should only twist message processing cycles - step 6. Step 7 will be performed on each workflow. Summarizing, we can say: we create one listening socket and we impose its processing on several worker threads.
So in my implementation, given that I already have some primitives for streams, files and command line parsing, I got an HTTP server with support for only the GET method of about 200 lines in C # / Java style. This reduction in the work of writing code with the full control of what is happening cannot but rejoice. In addition, subjectively, the resulting server works a little faster, but let's look at the tests at the end ...
Implementing an HTTP server on libevent
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include "tcp_server_socket.h"
#include "inet_address_v4.h"
#include "thread.h"
#include "command_line.h"
#include "logger.h"
#include "file_holder.h"
namespace Network
{
namespace Private
{
DECLARE_RUNTIME_EXCEPTION(EventBaseHolder)
class EventBaseHolder
: private Common::NonCopyable
{
public:
EventBaseHolder()
: EventBase(event_base_new())
{
if (!EventBase)
throw EventBaseHolderException("Failed to create new event_base");
}
~EventBaseHolder()
{
event_base_free(EventBase);
}
event_base* GetBase() const
{
return EventBase;
}
private:
event_base *EventBase;
};
DECLARE_RUNTIME_EXCEPTION(HttpEventHolder)
class HttpEventHolder
: public EventBaseHolder
{
public:
typedef std::tr1::function RequestHandler;
HttpEventHolder(SocketHandle sock, RequestHandler const &handler)
: Handler(handler)
, Http(evhttp_new(GetBase()))
{
evhttp_set_allowed_methods(Http, EVHTTP_REQ_GET);
evhttp_set_gencb(Http, &HttpEventHolder::RawHttpRequestHandler, this);
if (evhttp_accept_socket(Http, sock) == -1)
throw HttpEventHolderException("Failed to accept socket for http");
}
~HttpEventHolder()
{
evhttp_free(Http);
}
private:
RequestHandler Handler;
evhttp *Http;
static void RawHttpRequestHandler(evhttp_request *request, void *prm)
{
reinterpret_cast(prm)->ProcessRequest(request);
}
void ProcessRequest(evhttp_request *request)
{
try
{
Handler(request->uri, request->output_buffer);
evhttp_send_reply(request, HTTP_OK, "OK", request->output_buffer);
}
catch (std::exception const &e)
{
evhttp_send_reply(request, HTTP_INTERNAL,
e.what() ? e.what() : "Internal server error.",
request->output_buffer);
}
}
};
class ServerThread
: private HttpEventHolder
, private System::Thread
{
public:
ServerThread(SocketHandle sock, std::string const &rootDir, std::string const &defaultPage)
: HttpEventHolder(sock, std::tr1::bind(&ServerThread::OnRequest, this,
std::tr1::placeholders::_1,
std::tr1::placeholders::_2))
, Thread(std::tr1::bind(&ServerThread::DispatchProc, this))
, RootDir(rootDir)
, DefaultPage(defaultPage)
{
}
~ServerThread()
{
IsRun = false;
}
private:
enum { WaitTimeout = 10000 };
bool volatile IsRun;
std::string RootDir;
std::string DefaultPage;
void DispatchProc()
{
IsRun = true;
while(IsRun)
{
if (event_base_loop(GetBase(), EVLOOP_NONBLOCK))
{
Common::Log::GetLogInst() << "Failed to run dispatch events";
break;
}
usleep(WaitTimeout);
}
}
void OnRequest(char const *resource, evbuffer *outBuffer)
{
std::string FileName;
GetFullFileName(resource, &FileName);
try
{
System::FileHolder File(FileName);
if (!File.GetSize())
{
evbuffer_add_printf(outBuffer, "Empty file");
return;
}
evbuffer_add_file(outBuffer, File.GetHandle(), 0, File.GetSize());
File.Detach();
}
catch (System::FileHolderException const &)
{
evbuffer_add_printf(outBuffer, "File not found");
}
}
void GetFullFileName(char const *resource, std::string *fileName) const
{
fileName->append(RootDir);
if (!resource || !strcmp(resource, "/"))
{
fileName->append("/");
fileName->append(DefaultPage);
}
else
{
fileName->append(resource);
}
}
};
}
class HTTPServer
: private TCPServerSocket
{
public:
HTTPServer(InetAddress const &locAddr, int backlog,
int maxThreadsCount,
std::string const &rootDir, std::string const &defaultPage)
: TCPServerSocket(locAddr, backlog)
{
for (int i = 0 ; i < maxThreadsCount ; ++i)
{
ServerThreads.push_back(ServerThreadPtr(new Private::ServerThread(GetHandle(),
rootDir, defaultPage)));
}
}
private:
typedef std::tr1::shared_ptr ServerThreadPtr;
typedef std::vector ServerThreadPool;
ServerThreadPool ServerThreads;
};
}
int main(int argc, char const **argv)
{
if (signal(SIGPIPE, SIG_IGN) == SIG_ERR)
{
std::cerr << "Failed to call signal(SIGPIPE, SIG_IGN)" << std::endl;
return 0;
}
try
{
char const ServerAddr[] = "Server";
char const ServerPort[] = "Port";
char const MaxBacklog[] = "Backlog";
char const ThreadsCount[] = "Threads";
char const RootDir[] = "Root";
char const DefaultPage[] = "DefaultPage";
// Server:127.0.0.1 Port:5555 Backlog:10 Threads:4 Root:./ DefaultPage:index.html
Common::CommandLine CmdLine(argc, argv);
Network::HTTPServer Srv(
Network::InetAddressV4::CreateFromString(
CmdLine.GetStrParameter(ServerAddr),
CmdLine.GetParameter(ServerPort)),
CmdLine.GetParameter(MaxBacklog),
CmdLine.GetParameter(ThreadsCount),
CmdLine.GetStrParameter(RootDir),
CmdLine.GetStrParameter(DefaultPage)
);
std::cin.get();
}
catch (std::exception const &e)
{
Common::Log::GetLogInst() << e.what();
}
return 0;
}
Implementation on boost.asio
boost.asio is part of boost, which can help greatly reduce the development of network applications, and also cross-platform ones. The library hides a lot of routine from the developer.
I did not write the implementation of the HTTP server on boost. I took the finished example from boost.asio. Example multithreaded HTTP server. HTTP Server 3 The implementation of this example is quite suitable for testing in conjunction with the examples above.
There is an implementation of an HTTP server for testing, but it would not be bad to talk about general principles ... Unfortunately, unlike libevent, boost.asio does not support any higher-level protocols similar to HTTP and others. The library will hide the work with the network over TCP in this case, but the HTTP implementation will have to be done by the developer himself: to collect and parse the protocol headers.
Below is a small example of a multi-threaded echo server with a description, since it was less interesting for me to parse / collect HTTP headers in the light of this topic. The sequence of steps for creating a multi-threaded server using boost.asio is something like this:
- Create objects of the boost :: asio :: io_service and boost :: asio :: ip :: tcp :: acceptor classes.
- Using boost :: asio :: ip :: tcp :: resolver and boost :: asio :: ip :: tcp :: endpoint translate the local address to which the listening socket will be bound into the structure used by the library.
- Call bind and listen on an object of class boost :: asio :: ip :: tcp :: acceptor.
- Create some class “Connection”; aka “Session”, the instances of which will be used when receiving incoming user connections.
- Configure appropriate callback functions to receive incoming connections, receive data.
- Start the message processing loop by calling boost :: asio :: io_service :: run.
And as with the libevent example, a multi-threaded server is very simple to create from a single-threaded server using the set of steps described above. In this case, the difference between a single-threaded and a multi-threaded server is only that the boost :: asio :: io_service :: run method needs to be called in each thread for a multi-threaded implementation.
Echo server implementation on boost.asio
#include
#include
#include
#include
#include
#include
#include
#include
namespace Network
{
namespace Private
{
class Connection
: private boost::noncopyable
, public boost::enable_shared_from_this
{
public:
Connection(boost::asio::io_service &ioService)
: Strand(ioService)
, Socket(ioService)
{
}
boost::asio::ip::tcp::socket& GetSocket()
{
return Socket;
}
void Start()
{
Socket.async_read_some(boost::asio::buffer(Buffer),
Strand.wrap(
boost::bind(&Connection::HandleRead, shared_from_this(),
boost::asio::placeholders::error,
boost::asio::placeholders::bytes_transferred)
));
}
void HandleRead(boost::system::error_code const &error, std::size_t bytes)
{
if (error)
return;
std::vector Buffers;
Buffers.push_back(boost::asio::const_buffer(Buffer.data(), bytes));
boost::asio::async_write(Socket, Buffers,
Strand.wrap(
boost::bind(&Connection::HandleWrite, shared_from_this(),
boost::asio::placeholders::error)
));
}
void HandleWrite(boost::system::error_code const &error)
{
if (error)
return;
boost::system::error_code Code;
Socket.shutdown(boost::asio::ip::tcp::socket::shutdown_both, Code);
}
private:
boost::array Buffer;
boost::asio::io_service::strand Strand;
boost::asio::ip::tcp::socket Socket;
};
}
class EchoServer
: private boost::noncopyable
{
public:
EchoServer(std::string const& locAddr, std::string const& port, unsigned threadsCount)
: Acceptor(IoService)
, Threads(threadsCount)
{
boost::asio::ip::tcp::resolver Resolver(IoService);
boost::asio::ip::tcp::resolver::query Query(locAddr, port);
boost::asio::ip::tcp::endpoint Endpoint = *Resolver.resolve(Query);
Acceptor.open(Endpoint.protocol());
Acceptor.set_option(boost::asio::ip::tcp::acceptor::reuse_address(true));
Acceptor.bind(Endpoint);
Acceptor.listen();
StartAccept();
std::generate(Threads.begin(), Threads.end(),
boost::bind(
&boost::make_shared const &>,
boost::function(boost::bind(&boost::asio::io_service::run, &IoService))
));
}
~EchoServer()
{
std::for_each(Threads.begin(), Threads.end(),
boost::bind(&boost::asio::io_service::stop, &IoService));
std::for_each(Threads.begin(), Threads.end(),
boost::bind(&boost::thread::join, _1));
}
private:
boost::asio::io_service IoService;
boost::asio::ip::tcp::acceptor Acceptor;
typedef boost::shared_ptr ConnectionPtr;
ConnectionPtr NewConnection;
typedef boost::shared_ptr ThreadPtr;
typedef std::vector ThreadPool;
ThreadPool Threads;
void StartAccept()
{
NewConnection = boost::make_shared(IoService);
Acceptor.async_accept(NewConnection->GetSocket(),
boost::bind(&EchoServer::HandleAccept, this,
boost::asio::placeholders::error));
}
void HandleAccept(boost::system::error_code const &error)
{
if (!error)
NewConnection->Start();
StartAccept();
}
};
}
int main()
{
try
{
Network::EchoServer Srv("127.0.0.1", "5555", 4);
std::cin.get();
}
catch (std::exception const &e)
{
std::cerr << e.what() << std::endl;
}
return 0;
}
Testing
It's time to compare the received crafts ...
The platform on which everything was developed and tested - a regular laptop with 4GB of RAM and a 2-core processor running Ubuntu 12.04 desktop.
First of all, I put the utility for testing:
sudo apt-get install apache2-utils
ab -c 100 -k -r -t 5 "http://127.0.0.1:5555/test.jpg"Results:
Epoll implementation
Benchmarking 127.0.0.1 (be patient)
Finished 2150 requests
Server Software: MyTestHttp
Server Server Hostname: 127.0.0.1
Server Port: 5555
Document Path: /test.jpg
Document Length: 2496629 bytes
Concurrency Level: 100
Time taken for tests: 5.017 seconds
Complete requests : 2150
Failed requests: 0
Write errors: 0
Keep-Alive requests: 0
Total transferred: 5389312814 bytes
HTML transferred: 5388981758 bytes
Requests per second: 428.54 [# / sec] (mean)
Time per request: 233.348 [ms] (mean)
Time per request: 2.333 [ms] (mean, across all concurrent requests)
Transfer rate: 1049037.42 [Kbytes / sec] received
Connection Times (ms)
min mean [± sd] median max
Connect: 0 0 0.5 0 3
Processing: 74 226 58.2 229 364
Waiting: 2 133 64.8 141 264
Total: 77 226 58.1 229 364
Finished 2150 requests
Server Software: MyTestHttp
Server Server Hostname: 127.0.0.1
Server Port: 5555
Document Path: /test.jpg
Document Length: 2496629 bytes
Concurrency Level: 100
Time taken for tests: 5.017 seconds
Complete requests : 2150
Failed requests: 0
Write errors: 0
Keep-Alive requests: 0
Total transferred: 5389312814 bytes
HTML transferred: 5388981758 bytes
Requests per second: 428.54 [# / sec] (mean)
Time per request: 233.348 [ms] (mean)
Time per request: 2.333 [ms] (mean, across all concurrent requests)
Transfer rate: 1049037.42 [Kbytes / sec] received
Connection Times (ms)
min mean [± sd] median max
Connect: 0 0 0.5 0 3
Processing: 74 226 58.2 229 364
Waiting: 2 133 64.8 141 264
Total: 77 226 58.1 229 364
Libevent implementation
Benchmarking 127.0.0.1 (be patient)
Finished 1653 requests
Server Software:
Server Hostname: 127.0.0.1
Server Port: 5555
Document Path: /test.jpg
Document Length: 2496629 bytes
Concurrency Level: 100
Time taken for tests: 5.008 seconds
Complete requests: 1653
Failed requests: 0
Write errors: 0
Keep-Alive requests: 1653
Total transferred: 4263404830 bytes
HTML transferred: 4263207306 bytes
Requests per second: 330.05 [# / sec] (mean)
Time per request: 302.987 [ms] (mean)
Time per request: 3.030 [ms] (mean, across all concurrent requests)
Transfer rate: 831304.15 [Kbytes / sec] received
Connection Times (ms)
min mean [± sd] median max
Connect: 0 53 223.3 0 1000
Processing: 3 228 275.5 62 904
Waiting: 0 11 42.5 5 639
Total: 3 280 417.9 62 1864
Finished 1653 requests
Server Software:
Server Hostname: 127.0.0.1
Server Port: 5555
Document Path: /test.jpg
Document Length: 2496629 bytes
Concurrency Level: 100
Time taken for tests: 5.008 seconds
Complete requests: 1653
Failed requests: 0
Write errors: 0
Keep-Alive requests: 1653
Total transferred: 4263404830 bytes
HTML transferred: 4263207306 bytes
Requests per second: 330.05 [# / sec] (mean)
Time per request: 302.987 [ms] (mean)
Time per request: 3.030 [ms] (mean, across all concurrent requests)
Transfer rate: 831304.15 [Kbytes / sec] received
Connection Times (ms)
min mean [± sd] median max
Connect: 0 53 223.3 0 1000
Processing: 3 228 275.5 62 904
Waiting: 0 11 42.5 5 639
Total: 3 280 417.9 62 1864
Implementation on boost.asio
Benchmarking 127.0.0.1 (be patient)
Finished 639 requests
Server Software:
Server Hostname: 127.0.0.1
Server Port: 5555
Document Path: /test.jpg
Document Length: 2496629 bytes
Concurrency Level: 100
Time taken for tests: 5.001 seconds
Complete requests: 639
Failed requests: 0
Write errors: 0
Keep-Alive requests: 0
Total transferred: 1655047414 bytes
HTML transferred: 1654999464 bytes
Requests per second: 127.78 [# / sec] (mean)
Time per request: 782.584 [ms] (mean)
Time per request: 7.826 [ms] (mean, across all concurrent requests)
Transfer rate: 323205.36 [Kbytes / sec] received
Connection Times (ms)
min mean [± sd] median max
Connect: 0 0 1.1 0 4
Processing: 286 724 120.0 689 1106
Waiting: 12 364 101.0 394 532
Total: 286 724 120.0 689 1106
Finished 639 requests
Server Software:
Server Hostname: 127.0.0.1
Server Port: 5555
Document Path: /test.jpg
Document Length: 2496629 bytes
Concurrency Level: 100
Time taken for tests: 5.001 seconds
Complete requests: 639
Failed requests: 0
Write errors: 0
Keep-Alive requests: 0
Total transferred: 1655047414 bytes
HTML transferred: 1654999464 bytes
Requests per second: 127.78 [# / sec] (mean)
Time per request: 782.584 [ms] (mean)
Time per request: 7.826 [ms] (mean, across all concurrent requests)
Transfer rate: 323205.36 [Kbytes / sec] received
Connection Times (ms)
min mean [± sd] median max
Connect: 0 0 1.1 0 4
Processing: 286 724 120.0 689 1106
Waiting: 12 364 101.0 394 532
Total: 286 724 120.0 689 1106
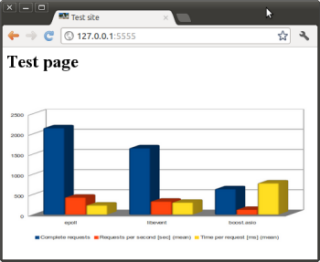
The results are summarized in the table.
| epoll | libevent | boost.asio | |
| Complete requests | 2150 | 1653 | 639 |
| Total transferred (bytes) | 5389312814 | 4263404830 | 1655047414 |
| HTML transferred (bytes) | 5388981758 | 4263207306 | 1654999464 |
| Requests per second [sec] (mean) | 428.54 | 330.05 | 127.78 |
| Time per request [ms] (mean) | 233.348 | 302.987 | 782.584 |
| Transfer rate [Kbytes / sec] received | 1049037.42 | 831304.15 | 323205.36 |
There are three types of lies: lies, blatant lies and statistics. Although, I must admit, the result cannot but please me. I think you should not pay special attention to the results, but you can look at them as some supporting information that may be useful in deciding on the choice of a development tool for your server software. To ensure the accuracy of the results, it is desirable to arrange multiple runs on the server hardware, clients running on other machines on the network, etc.
100 parallel queries - this would seem small, but quite enough for testing in such modest conditions. Of course, I would like to check the results on thousands of parallel queries, but there are already other factors. One such factor is the number of simultaneously open file descriptors for a process. You can find out and set some process parameters by calling getrlimit and setrlimit functions. In order to find out how many file descriptors are allocated per process, you can call getrlimit with the RLIMIT_NOFILE flag of the rlimit structure. For its operating system, these are 1024 file descriptors per process by default and 4096 maximum that can be set on the process. By this criterion you won’t accelerate much ... As an option, in order so that your server in one process can work with a large number of file descriptors, you can configure the system accordingly. There is a good description in the articleLinux socket performance increase
Conclusions and Conclusion
Writing your WebServer on bare sockets is definitely interesting, but remember that the devil is in the details. As they are realized, these very details, like a snowball, are rolling more and more. Despite my great love for the bicycle industry in the field of information technology, I would still leave this approach to the case when you need to write something very specific, sacrifice some generalizations and something more high-level in favor of achieving maximum performance server. The code attached to the article with the implementation on epoll can still be improved and improved. Bringing to industrial implementation and supporting such a development will be very expensive, respectively, the planned return on such a system should also be not small. But the "blatant lie"
As already noted above, the libevent library turned out to be my favorite, it is very simple for a quick start, it gives very good results in performance, cross-platform, it hides routines a lot. For most projects, I would consider it first.
In my subjective opinion, boost is very peculiar. It gives many advantages in the development of various software and in some places is very attractive. boost.asio provides a fairly high level of abstraction from most of the necessary things when developing network software. I would very much like to hear the opinions of “experienced” about the use of this library in the development of server software and, preferably, with a high load.
There is another interesting mechanism for asynchronous input output in Linux (aio), but so far there has not been enough time to make an implementation on it on all the same “bare” sockets for comparison with other implementations.
All code with minimal assembly files is available in SVN . The code, of course, can still be improved and improved. But! Exacerbated perfectionism can either drastically delay the implementation of something, or make it generally unattainable. According to the article “Development through suffering” , the first thing to do is to make it work, the second to be beautiful, and the third to work quickly. The given code went through the first stage and bit by bit touched the second and third :)
So the “small” test task became an interesting incentive for me to some overview of the API of operating systems and libraries.
Interesting materials
- Writing your HTTP server using libevent
- Boost network performance with libevent and libev
- MULTI-THREADED HTTPSERVER USING EVHTTP (LIBEVENT)
- Boost application performance using asynchronous I / O
- Configuring FreeBSD to Serve 100-200 Thousand Connections
Thanks for attention!