We consider the statistics on the experiments on hh.ru
Hello!
Today I will tell you how we at hh.ru consider manual statistics on experiments. We'll see where the data comes from, how we process it and what pitfalls we encounter. In the article I will share the general architecture and approach, the real scripts and code will be at a minimum. The main audience is novice analysts who are interested in how the data analysis infrastructure in hh.ru is arranged. If this topic is interesting - write in the comments, we can delve into the code in the following articles.
How automatic metrics for A / B experiments are considered can be found in our other article .

We analyze access logs and any custom logs that we write ourselves.
In our architecture, each service writes logs locally, and then through a samopisny client-server logs (including the access logs of nginx) are collected on a central repository (further logging). Developers have access to this machine and can manually log logs if necessary. But how in a reasonable time a few hundred gigabytes of logs? Of course, pour them into hadoop!
Not only service logs are stored in hadoop, but also prod-database unloading. Every day in the hadoop we unload some of the tables that are necessary for analytics.
Logs of services get into hadoop in three ways.
Consider each approach in more detail.
Cron runs a regular bash script.
As we remember, in the log storage all the logs are in the form of regular files, the folder structure is something like this: /logging/java/2018/08/10/16service_namey/*.log
Hadoop stores its files in about the same folder structure hdfs- we use raw / banner-versions / year = 2018 / month = 08 / day = 10
year, month, day as partitions.
Thus, we only need to form the correct paths (lines 3-4), then select all the necessary logs (line 6) and use rsync to fill them in hadoop (line 8).
Advantages of this approach:
Minuses:
Since we upload logs to the repository with a self-written script, it was logical to tie the ability to pour them not only on the server, but also in kafka.
pros
Minuses
It differs from the fashionable only in the absence of kafka. Therefore, it inherits all the minuses and only some advantages of the previous approach. A separate service (ustats-uploader) on java periodically reads the necessary files, makes them preprocessing and uploads into hadoop.
pros
Minuses
And the data got into hadoop and is ready for analysis. Let's stop a bit and remember what hadoop is and why hundreds of gigabytes can be stuck on it much faster than the usual grep.
Hadoop is a distributed data repository. The data does not lie on any separate server, but is distributed among several machines, and is also stored not in one instance, but in several - this is done to ensure reliability. The basis of the speed of data processing lies in the change in approach in comparison with conventional databases.
In the case of a regular database, we retrieve data from it and send it to the client, who does some analysis and returns the result to the analytics. Thus, in order to be able to read more quickly, we need to have many clients and parallel requests (for example, divide the data by months - and each client can read the data for his month).
Hadoop is the opposite. We send the code (what exactly we want to count) to the data, and this code is executed on the cluster. As we know, data rests on many machines, so each machine executes code only on its data and returns the result to the client.
Many have probably heard about map-reduce , but writing code for analytics is not very convenient and fast, while writing in SQL is much easier. Therefore, services have emerged that are able to turn SQL into map-reduce transparently for the user, and the analyst may not even suspect how his request is actually considered.
In hh.ru for this we use hive and presto. Hive was the first, but we gradually move to presto, since it is much faster for our requests. We use hue and zeppelin as GUI.
It is more convenient for me to consider analytics on python in jupyter, this allows you to read it with one click and get properly styled excel tables at the output, which saves time. Write in the comments, this topic pulls on a separate article.
Let's return to the analyst itself.
We send an email-newsletter, in which we send suitable vacancies for the applicant (do everyone like such newsletters?). We decided to slightly change the design of the letter and we want to understand whether it became better. For this we will consider:
Let me remind you that all we have is an access log and a base. We need to formulate our metrics in terms of linking.
Transition is a GET request on hh.ru/vacancy/26646861 . To understand where the transition came from, we add utm tags of the form? Utm_source = email_campaign_123. For GET requests, the access log will have information about the parameters, and we can filter the transitions only from our mailing list.
Here we could just count the number of responses to vacancies from the newsletter, but then the statistics would be wrong, because the responses could have been influenced by something else besides our letter, for example, a ClickMe ad was bought for the vacancy, and therefore the number of responses has grown a lot.
We have two options for how to formulate the number of responses:
The choice of approach is determined by business requirements, usually the first option is enough, but it all depends on what the product manager is waiting for.
Finally, let's talk about how the result of calculations should look.
In our example, there are 2 groups and 2 metrics that form a funnel.
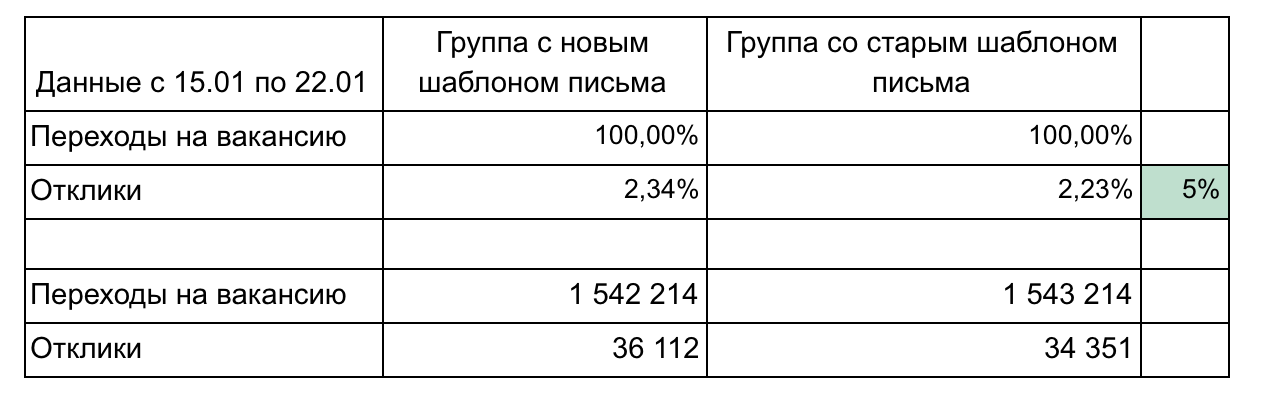
Recommendations for the design of the results:
It is necessary to count various metrics quite often, because we practically release each task within the framework of the A / B experiment. There is nothing complicated in the calculations, after 2-3 experiments there comes an understanding of how to do it. Remember that access logs store a lot of useful information that can save a company money, help you promote your idea and prove which change option is better. The main thing - to be able to get this information.
Today I will tell you how we at hh.ru consider manual statistics on experiments. We'll see where the data comes from, how we process it and what pitfalls we encounter. In the article I will share the general architecture and approach, the real scripts and code will be at a minimum. The main audience is novice analysts who are interested in how the data analysis infrastructure in hh.ru is arranged. If this topic is interesting - write in the comments, we can delve into the code in the following articles.
How automatic metrics for A / B experiments are considered can be found in our other article .
What data we analyze and where they come from
We analyze access logs and any custom logs that we write ourselves.
95.108.213.12 - - [13 / Aug / 2018: 04: 00: 02 +0300] 200 "GET / employer / 2574971 HTTP / 1.1" 12012 "-" Mozilla / 5.0 (compatible; YandexBot / 3.0; + http: / /yandex.com/bots) "" - "" gardabani.headhunter.ge "" 0.063 "" - "" 1534122002.858 "" - "" 192.168.2.38:1500 "" [0.064] "{15341220027959c8c01c51a6e01b682f 200 https 1 -" - "- - [35827] [0.000 0]
178.23.230.16 - - [13 / Aug / 2018: 04: 00: 02 +0300] 200" GET / vacancy / 24266672 HTTP / 1.1 "24229" hh.ru/vacancy/ 24007186? Query = bmw"Mozilla / 5.0 (Macintosh; Intel Mac OS X 10_10_5) AppleWebKit / 603.3.8 (KHTML, like Gecko) Version / 10.1.2 Safari / 603.3.8" "-" "hh.ru" "0.210" "last_visit = 1534111115966 :: 1534121915966; hhrole = anonymous; regions = 1; tmr_detect = 0% 7C1534121918520; total_searches = 3; unique_banner_user = 1534121429.273825242076558 "" 1534122002.859 "" - "" 192.168.2.239:1500 "" [0.208] "{1534122002649b7eef2e901d8c9c0469} 200 https 1 -" - "- - [35927] [0.001 0]
In our architecture, each service writes logs locally, and then through a samopisny client-server logs (including the access logs of nginx) are collected on a central repository (further logging). Developers have access to this machine and can manually log logs if necessary. But how in a reasonable time a few hundred gigabytes of logs? Of course, pour them into hadoop!
Where does the data appear in hadoop?
Not only service logs are stored in hadoop, but also prod-database unloading. Every day in the hadoop we unload some of the tables that are necessary for analytics.
Logs of services get into hadoop in three ways.
- Path to the forehead - cron is started from the log repository at night, and rsync unloads raw logs in hdfs.
- The path is fashionable - logs from services flow not only into the general storage, but also into kafka, from where they are read by flume, does preprocessing and stores in hdfs.
- The path is old-fashioned - in the days before kafka, we wrote our service, which reads raw logs from the repository, makes preprocessing and fills in hdfs.
Consider each approach in more detail.
Way to the forehead
Cron runs a regular bash script.
#!/bin/bash
LOGGING_DATE_PATH_PART=$(date -d yesterday +\%Y/\%m/\%d)
HADOOP_DATE_PATH_PART=$(date -d yesterday +year=\%Y/month=\%m/day=\%d)
ls /logging/java/${LOGGING_DATE_PATH_PART}/hh-banner-sync/banner-versions*.log | whileread source_filename; do
dest_filename=$(basename "$source_filename")
/usr/bin/rsync --no-relative --no-implied-dirs --bwlimit=12288 ${source_filename} rsync://hadoop2.hhnet.ru/hdfs-raw/banner-versions/${HADOOP_DATE_PATH_PART}/${dest_filename};
doneAs we remember, in the log storage all the logs are in the form of regular files, the folder structure is something like this: /logging/java/2018/08/10/16service_namey/*.log
Hadoop stores its files in about the same folder structure hdfs- we use raw / banner-versions / year = 2018 / month = 08 / day = 10
year, month, day as partitions.
Thus, we only need to form the correct paths (lines 3-4), then select all the necessary logs (line 6) and use rsync to fill them in hadoop (line 8).
Advantages of this approach:
- Rapid development
- Everything is transparent and clear
Minuses:
- No preprocessing
Fashionable way
Since we upload logs to the repository with a self-written script, it was logical to tie the ability to pour them not only on the server, but also in kafka.
pros
- Online logs (logs in hadoop appear as fills in kafka)
- You can do preprocessing
- Well holds the load and you can upload large logs
Minuses
- More difficult setup
- You need to write code
- More components of the pouring process
- More difficult to monitor and analyze incidents
The path is old fashioned
It differs from the fashionable only in the absence of kafka. Therefore, it inherits all the minuses and only some advantages of the previous approach. A separate service (ustats-uploader) on java periodically reads the necessary files, makes them preprocessing and uploads into hadoop.
pros
- You can do preprocessing
Minuses
- More difficult setup
- You need to write code
And the data got into hadoop and is ready for analysis. Let's stop a bit and remember what hadoop is and why hundreds of gigabytes can be stuck on it much faster than the usual grep.
Hadoop
Hadoop is a distributed data repository. The data does not lie on any separate server, but is distributed among several machines, and is also stored not in one instance, but in several - this is done to ensure reliability. The basis of the speed of data processing lies in the change in approach in comparison with conventional databases.
In the case of a regular database, we retrieve data from it and send it to the client, who does some analysis and returns the result to the analytics. Thus, in order to be able to read more quickly, we need to have many clients and parallel requests (for example, divide the data by months - and each client can read the data for his month).
Hadoop is the opposite. We send the code (what exactly we want to count) to the data, and this code is executed on the cluster. As we know, data rests on many machines, so each machine executes code only on its data and returns the result to the client.
Many have probably heard about map-reduce , but writing code for analytics is not very convenient and fast, while writing in SQL is much easier. Therefore, services have emerged that are able to turn SQL into map-reduce transparently for the user, and the analyst may not even suspect how his request is actually considered.
In hh.ru for this we use hive and presto. Hive was the first, but we gradually move to presto, since it is much faster for our requests. We use hue and zeppelin as GUI.
It is more convenient for me to consider analytics on python in jupyter, this allows you to read it with one click and get properly styled excel tables at the output, which saves time. Write in the comments, this topic pulls on a separate article.
Let's return to the analyst itself.
How to understand what we want to count?
The product manager came with the task to calculate the results of the experiment.
We send an email-newsletter, in which we send suitable vacancies for the applicant (do everyone like such newsletters?). We decided to slightly change the design of the letter and we want to understand whether it became better. For this we will consider:
- the number of transitions to vacancies from the letter;
- post-transition feedback
Let me remind you that all we have is an access log and a base. We need to formulate our metrics in terms of linking.
Number of transitions to a job from a letter
Transition is a GET request on hh.ru/vacancy/26646861 . To understand where the transition came from, we add utm tags of the form? Utm_source = email_campaign_123. For GET requests, the access log will have information about the parameters, and we can filter the transitions only from our mailing list.
The number of responses after the transition
Here we could just count the number of responses to vacancies from the newsletter, but then the statistics would be wrong, because the responses could have been influenced by something else besides our letter, for example, a ClickMe ad was bought for the vacancy, and therefore the number of responses has grown a lot.
We have two options for how to formulate the number of responses:
- The response is a POST on hh.ru/applicant/vacancy_response/popup?vacancy_id=26646861 , which has referer hh.ru/vacancy/26646861?utm_source=email_campaign_123 .
- The nuance of this approach is that if the user switched to a vacancy, and then walked around the site a bit and then responded to the vacancy, then we will not deduct it.
- We can remember the id of the user who switched to hh.ru/vacancy/26646861 , and calculate the number of reviews per vacancy during the day.
The choice of approach is determined by business requirements, usually the first option is enough, but it all depends on what the product manager is waiting for.
Pitfalls that may occur
- Not all data is in hadoop, you need to add data from the prod-database. For example, in logs usually only id, and if you need a name, then it is in the database. Sometimes you need to search for user by resume_id, and this is also stored in the database. To do this, we unload the part of the base in hadoop, so that the join is simpler.
- Data may be curves. This is generally the trouble of hadoop and how we load data into it. Depending on the data, an empty value can be null, None, none, an empty string, etc. You need to be careful in each case, because the data is really different, loaded in different ways and for different purposes.
- Long count for the entire period. For example, we need to count our transitions and responses for the month. These are about 3 terabytes of logs. Even hadoop will take it for quite a while. Usually it is quite difficult to write a 100% work request the first time, so we write it by trial and error. Each time waiting for 20 minutes is very long. Solutions:
- Debugging request for logs for 1 day. Since the data in hadoop is partitioned by us, it’s pretty quick to calculate something for 1 day of logs.
- Download the necessary logs to the temporary table. As a rule, we understand which URLs are interesting to us, and we can make a temporary table for the logs from these URLs.
Personally, I prefer the first option, but sometimes it’s necessary to make a temporary table, depending on the situation. - Distortions in summary metrics
- It is better to filter the logs. You need to pay attention, for example, to the response code, redirect, etc. Better is less data, but more accurate, of which you are sure.
- As few as possible intermediate steps in the metric. For example, a transition to a job is one step (GET request to / vacancy / 123). Response - two (go to the job + POST). The shorter the chain, the less errors and the more accurate the metric. Sometimes it happens that the data between the transitions are lost and counting something is impossible at all. To solve this problem, it is necessary before the development of the experiment to think about what we will consider and how. Extremely helps your separate log of the necessary events. We are able to shoot the necessary events, and thus the chain of events will be more accurate, and it will be easier to count.
- Bots can generate a bunch of transitions. You need to understand where bots can go (for example, on pages that require authorization, they should not be), and filter this data.
- Big bumps - for example, in one of the groups there may be one applicant who generates 50% of all responses. There will be a bias of statistics, such data also needs to be filtered.
- It is difficult to formulate what to consider in terms of access log. Here helps knowledge of the code base, experience and chrome dev tools. We read the description of the metric from the product, we repeat with our hands on the site and see which transitions are generated.
Finally, let's talk about how the result of calculations should look.
Counting result
In our example, there are 2 groups and 2 metrics that form a funnel.
Recommendations for the design of the results:
- Do not overload with parts until it is required. Simply and less is better (for example, here we could show each vacancy separately or clicks by day). Focus on one thing.
- Details may be needed in the process of demo results, so think about what questions you may ask, and prepare the details. (In our example, the detailing can be on the speed of transition after sending an email - 1 day, 3 days, week, grouping of vacancies by trade area)
- Remember about statistical significance. For example, a change of 1% with the number of transitions of 100 and clicks of 15 is insignificant and could be accidental. Use calculators
- Automate as much as possible, because you’ll have to count several times. Usually in the middle of an experiment you already want to understand how things are going. After the experiment, there may be questions and something will have to be clarified. Thus, it will be necessary to calculate 3-4 times, and if each calculation is a sequence of 10 requests and then manual copying to excel, it will be painful and spend a lot of time. Learn python, it will save a lot of time.
- Use a graphical representation of the results when justified. The built-in tools hive and zeppelin allow out of the box to build simple graphics.
It is necessary to count various metrics quite often, because we practically release each task within the framework of the A / B experiment. There is nothing complicated in the calculations, after 2-3 experiments there comes an understanding of how to do it. Remember that access logs store a lot of useful information that can save a company money, help you promote your idea and prove which change option is better. The main thing - to be able to get this information.