Kubernetes in production: services
 Six months ago, we completed the migration of all our stateless services to kubernetes. At first glance, the task is quite simple: you need to deploy a cluster, write application specifications and go ahead. Due to the obsession with ensuring stability in the operation of our service, we had to immediately start to understand how k8s works and test various failure scenarios. Most of the questions I had to everything related to the network. One of these "slippery" moments - the work of services (Services) in kubernetes.
Six months ago, we completed the migration of all our stateless services to kubernetes. At first glance, the task is quite simple: you need to deploy a cluster, write application specifications and go ahead. Due to the obsession with ensuring stability in the operation of our service, we had to immediately start to understand how k8s works and test various failure scenarios. Most of the questions I had to everything related to the network. One of these "slippery" moments - the work of services (Services) in kubernetes.
The documentation tells us:
- roll out the app
- set the liveness / readiness of the sample
- create a service
- then everything will work: load balancing, bounce handling, and so on.
But in practice everything is more complicated. Let's see how it actually works.
A bit of theory
Further, I mean that the reader is already familiar with the device kubernetes and its terminology, just remember what a service is.
Service - the essence of k8s, which describes a set of pods and methods of access to them.
For example, we launched our application:
apiVersion: apps/v1
kind: Deployment
metadata:
name: webapp
spec:
selector:
matchLabels:
app: webapp
replicas: 2
template:
metadata:
labels:
app: webapp
spec:
containers:
- name: webapp
image: defaultxz/webapp
command: ["/webapp", "0.0.0.0:80"]
ports:
- containerPort: 80
readinessProbe:
httpGet: {path: /, port: 80}
initialDelaySeconds: 1
periodSeconds: 1$ kubectl get pods -l app=webapp
NAME READY STATUS RESTARTS AGE
webapp-5d5d96f786-b2jxb 1/1 Running 0 3h
webapp-5d5d96f786-rt6j7 1/1 Running 0 3hNow, in order to access it, we need to create a service in which we define to which subsections we want to have access (selector) and on which ports:
kind: Service
apiVersion: v1
metadata:
name: webapp
spec:
selector:
app: webapp
ports:
- protocol: TCP
port: 80
targetPort: 80$ kubectl get svc webapp
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
webapp ClusterIP 10.97.149.77 <none> 80/TCP 1dNow we can access our service from any cluster machine:
curl -i http://10.97.149.77
HTTP/1.1 200 OK
Date: Mon, 24 Sep 2018 11:55:14 GMT
Content-Length: 2
Content-Type: text/plain; charset=utf-8How it all works
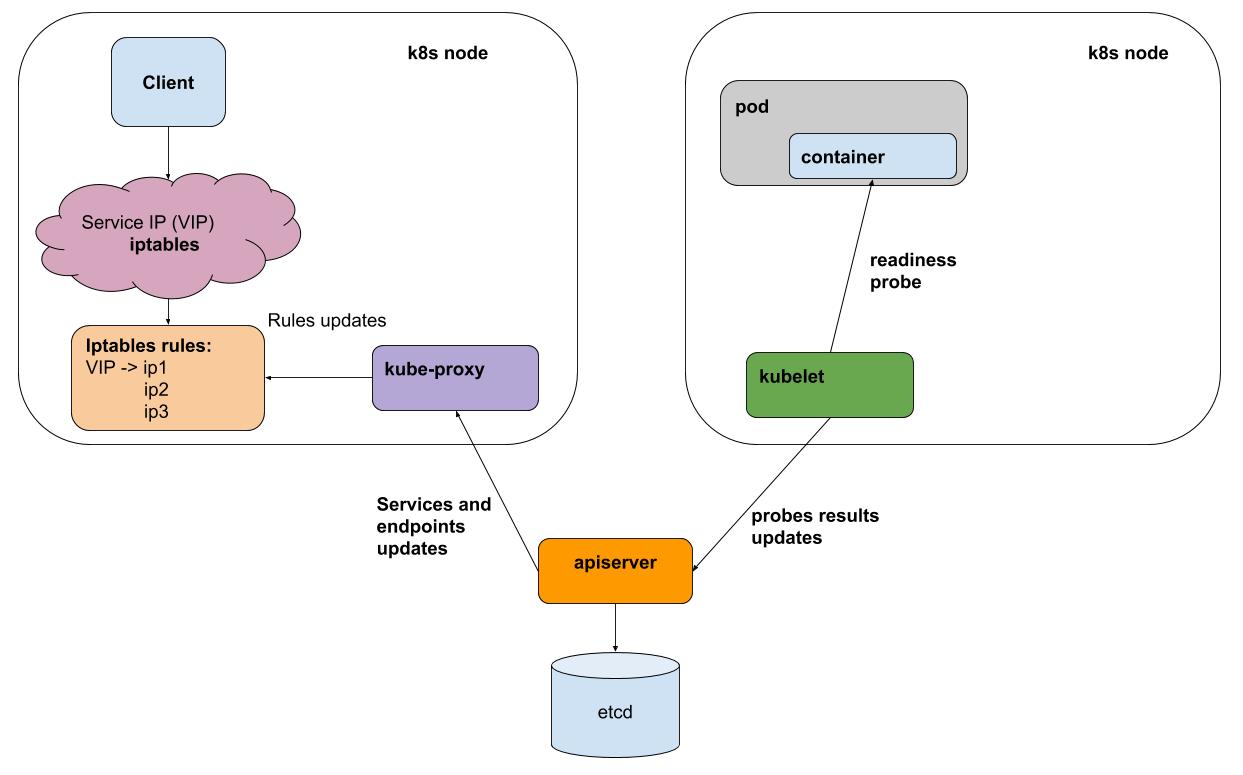
Very simplistic:
- you made kubectl apply Deployment specifications
- there is magic, the details of which are not important in this context
- As a result, on some nodes, there were running applications
- Once a kubelet interval (the k8s agent on each node) performs liveness / readiness samples of all the subs running on its node, it sends the results to the apiserver (interface to the k8s brains)
- kube-proxy on each node receives notifications from apiserver about all changes to services and pods that are involved in services
- kube-proxy reflects all changes in the configuration of the underlying subsystems (iptables, ipvs)
For simplicity, consider the default method of proxying - iptables. In iptables we have for our virtual ip 10.97.149.77:
-A KUBE-SERVICES -d 10.97.149.77/32 -p tcp -m comment --comment "default/webapp: cluster IP" -m tcp --dport 80 -j KUBE-SVC-BL7FHTIPVYJBLWZNtraffic goes to the chain KUBE-SVC-BL7FHTIPVYJBLWZN , in which it is distributed between 2 other chains
-A KUBE-SVC-BL7FHTIPVYJBLWZN -m comment --comment "default/webapp:" -m statistic --mode random --probability 0.50000000000 -j KUBE-SEP-UPKHDYQWGW4MVMBS
-A KUBE-SVC-BL7FHTIPVYJBLWZN -m comment --comment "default/webapp:" -j KUBE-SEP-FFCBJRUPEN3YPZQTthis is ours
-A KUBE-SEP-UPKHDYQWGW4MVMBS -p tcp -m comment --comment "default/webapp:" -m tcp -j DNAT --to-destination 10.244.0.10:80
-A KUBE-SEP-FFCBJRUPEN3YPZQT -p tcp -m comment --comment "default/webapp:" -m tcp -j DNAT --to-destination 10.244.0.11:80Testing the failure of one of the pods
My webapp test application can switch to the "rash errors" mode, for this you need to do pull the URL "/ err".
The results of ab -c 50 -n 20000 in the middle of the test yanked "/ err" on one of the pods:
Complete requests: 20000
Failed requests: 3719The point here is not in the specific number of errors (their number will vary depending on the load), but in the fact that they exist. In general, we threw the "bad" under out of balancing, but at the time of switching the client of the service received errors. The reason for the errors is fairly easy to explain: the readiness of the test is performed by the kubelet once a second + there is still a short time for the dissemination of information that did not respond to the test.
Will IPVS help back end for kube-proxy (experimental)?
Not really! It solves the optimization problem of proxying, offers a custom balancing algorithm, but does not solve the problem of processing failures.
How to be
This problem can be solved only by a balancer who can retry (retries). In other words, for http we need an L7 balancer. Such balancers for kubernetes are already fully used either in the form of ingress (it was meant as a point in turn into a cluster, but by and large it does exactly what is needed) or as an implementation of a separate layer - a service mesh, for example istio .
In our production we didn’t use either the ingress or the service mesh due to the added complexity. Such abstractions, in my opinion, help in cases where you need to often configure a large number of services. But at the same time you “pay” for controllability and simple infrastructure. You will spend extra time to figure out how to set up schedules, timeouts for a particular service.
How do we
We use headless k8s services. Such services do not have a virtual ip and, accordingly, kube-proxy and iptables do not participate in their work. For each such service, you can get a list of live podov either through DNS, or through API.
For applications that interact with other services, we make a sidecar container with envoy . Evoy periodically receives an up-to-date list of hearths for all necessary services via DNS, and most importantly is able to make repeated attempts to query other hearths in case of an error. You can run it as a DaemonSet on each node, but then if this instance fails, all applications that use it would stop working. Since the consumption of resources by this proxy is rather small, we decided to use it in the variant sidecar container.
This is essentially exactly what istio does, but in our case the balance has shifted towards simplicity (no need to learn istio, run into its bugs). Perhaps this balance will change, and we will start using something like istio.
We in Okmeter.io kubernetes definitely got accustomed, and we believe in its further distribution. Support monitoring k8s in our service on the way, stay tuned!