An experiment integrating video extensions into an audio speech recognition system
Instead of introducing
I continue to conduct a series of reports on research work that I spent several months studying at the university and in the first months after graduation. Over the entire period of work, many elements of the system that I developed were re-evaluated and the vector of work as a whole has seriously changed. It was all the more interesting to look at our previous experience and publish materials that were not previously published with new comments. In this report I publish materials that are almost 2 years old with fresh additions that I hope have not lost their relevance.
Content:
1. Search and analysis of the color space optimal for constructing prominent objects on a given class of images
2. Determination of the dominant signs of classification and the development of a mathematical model of facial expressions "
3. Synthesis of an optimal recognition algorithm for facial expressions
4. Implementation and testing of the facial recognition algorithm
5. Creation of a test database lip images of users in various states to increase the accuracy of the system
6. Search for the optimal audio speech recognition system based on open source passcode
7.Search for an optimal audio recognition system for speech recognition with closed source code, but with open APIs, for integration
8. Experiment of integrating a video extension into an audio recognition system with speech test protocol
Objectives:
Based on the experience gained in previous research, carry out a test integration of the video extension into the speech recognition system, conduct test reports, and draw conclusions.
Tasks:
Consider in detail how to integrate a video extension with a speech recognition program, explore the principle of audio-video synchronization itself, as well as carry out trial integration of the developed video extension into a speech recognition system, evaluate the solution being developed.
Introduction
In the course of previous research, conclusions were drawn on the appropriateness of using speech recognition audio systems based on open and closed source code for our goals and objectives. As we have determined: the implementation of its own speech recognition system is a very complex, time-consuming and resource-intensive task, which is difficult to accomplish within the framework of this work. Therefore, we decided to integrate the presented video identification technology into speech recognition systems, which have special capabilities for this. Since speech recognition systems with closed source code are implemented more efficiently and the accuracy of speech recognition in them is higher due to the more capacious content of the vocabulary, therefore, the integration of our video development into their work should be considered a more promising direction, Compared to open source audio speech recognition systems. However, it is necessary to bear in mind the fact that closed-source speech recognition systems often have complex documentation for the possibility of integrating third-party solutions into their work with serious restrictions on the use of the system on the basis of a license agreement, or this direction is paid, that is, you must buy a special license for the use of speech technologies provided by the licensor.
To begin with, as an experiment, it was decided to try to improve the quality of speech recognition of the Google Speech Recognition API speech recognition system due to the work of our developed video extension. I note that at the time of testing, the Google Speech API based on the Chrome browser did not yet have Google continuous speech recognition function, which at that time was already built into Speech Input continuous speech recognition technology based on Android OS.
As a basis for video processing, we took our decision to analyze the movement of the user's lips and algorithms for fixing the phase of the movement of points in the object of interest together with audio processing. With that in the end it turned out can be found below.

The logic of the lip movement analyzer to improve the performance of speech recognition systems
The use of additional visualization in the tasks of increasing the accuracy of speech recognition in the presented video extension consists of the following technological features:
Due to the parallel processing of the user's lips and analysis of the voice frequency of the speaker, the presented video extension more accurately determines the speech flow that is directly related to real speech user. To do this, the software being developed constantly analyzes the sound signal and the lips of the user. However, recording a signal to determine the user's speech, highlighting pauses of the speaker’s speech and other circumstances that are necessary for subsequent sending and processing of the audio signal in the database of speech recognition systems occurs only after a number of reasons. Let's consider them in more detail:
• The solution records and subsequently processes those audio frequencies that fall into the system’s microphone. However, if the user does not make any active movement of his lips together with these sound vibrations, then the system does not start recording speech for subsequent recognition tasks. Figure 1 shows the process of analyzing the movement of the user's lips and the sound wave recorded in that time period when there are no active sound vibrations and the user does not make active lip movement. At this moment, the system does not record a sound fragment, which must be recorded for tasks of subsequent speech recognition;

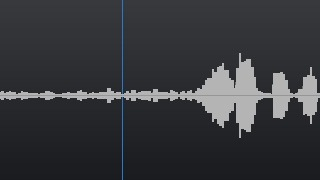
Figure 1. An example of the system when the active movement of the user's lips and the active vibration of the speech wave are not observed in the dynamics - accordingly, voice recording is not performed for tasks of subsequent recognition.
• Also, the extension does not record and subsequently process the audio frequency when the user actively moves his lips, while the user's microphone is turned off or is not sensitive to noise, that is, there are no active sound vibrations. In this case, the system begins to analyze the data in dynamics. If the movement of the user's lips does not follow any further sound vibrations, then, accordingly, the invention should not record this speech stream for tasks of subsequent recognition. Figure 2 presents such a possible example, when the user changed his lip movement, but this process was not followed by any active sound vibrations in the temporal dynamics;
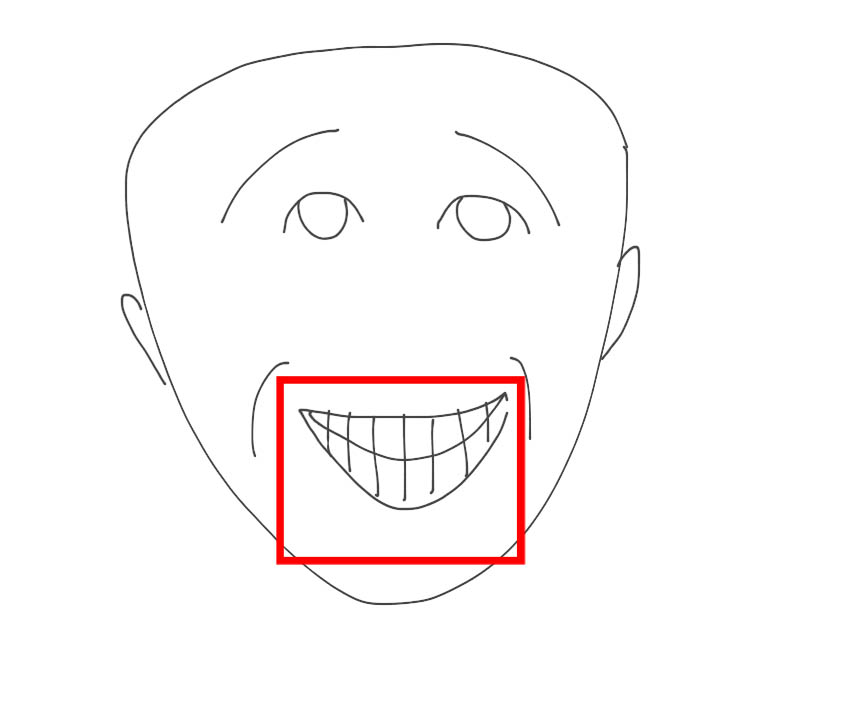
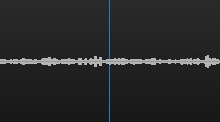
Figure 2. An example of the system when the active movement of the lips is recorded (in the case presented, the user smiles), but in the temporal dynamics there was no active vibration of the sound frequency - accordingly, voice recording is not made for subsequent recognition.
• Also, the presented solution does not record and subsequently process the audio signal for recognition tasks, if there are sound vibrations, but there is no active movement of the lips of a particular user, which can be traced in the time dynamics. Figure 3 shows one of such possible examples: the user's lips are closed, and their position in the dynamics does not change actively, at the same time there are certain sound vibrations - therefore, in this case, the device does not record an audio track for subsequent recognition tasks.
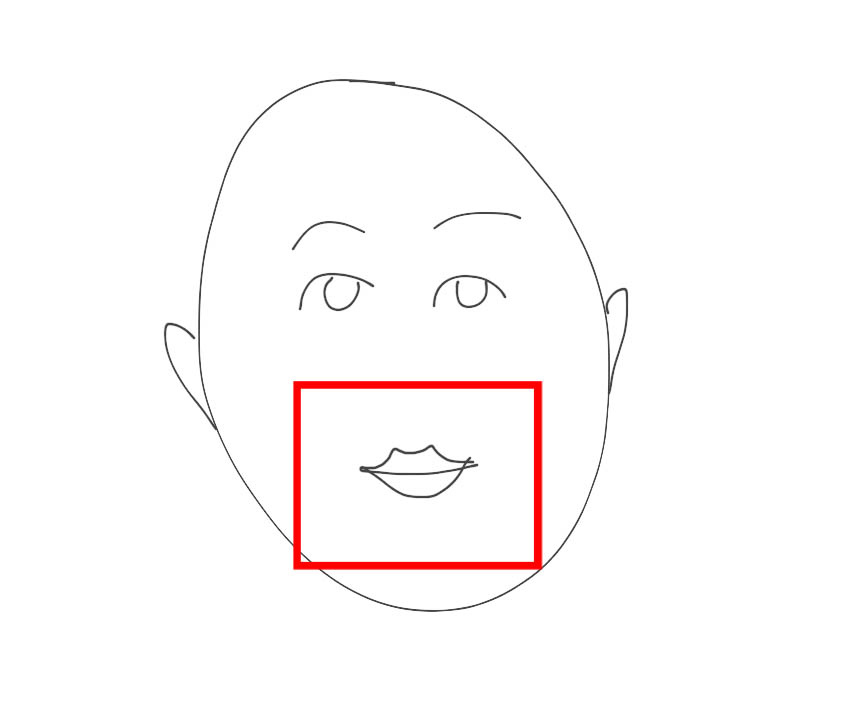
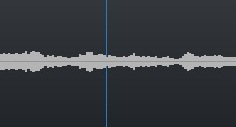
Figure 3. An example of the system when the active movement of the user's lips in the temporal dynamics is not fixed, at the same time there are some active fluctuations in the sound frequency (in the presented case, the music is on) - accordingly, speech is not recorded for subsequent recognition.
• If the user's microphone is turned on and properly configured, just as the device’s camera is turned on and properly configured, the device’s operation will be turned on. Recording and subsequent processing of the sound signal begins only after the active sound vibrations begin to coincide with the active movement of the user's lips. It is necessary to keep in mind the following:
a) The active movement of the lips, the user, as a rule, begins to pronounce a little earlier than the active sound vibrations. In this case, the presented solution looks at the movement of the user's lips and active sound vibrations in the temporal dynamics. If the further active movement of the user's lips begins to coincide with the active fluctuation of the sound frequency, then in the case where the beginning of the active phase of the movement of the lips and the sound frequency coincides as much as possible, the presented solution starts recording the user's speech for further processing and recognition in the database speech recognition systems. An example of the beginning of the active movement of the user's lips and the subsequent active sound vibration are presented in Figure 4.

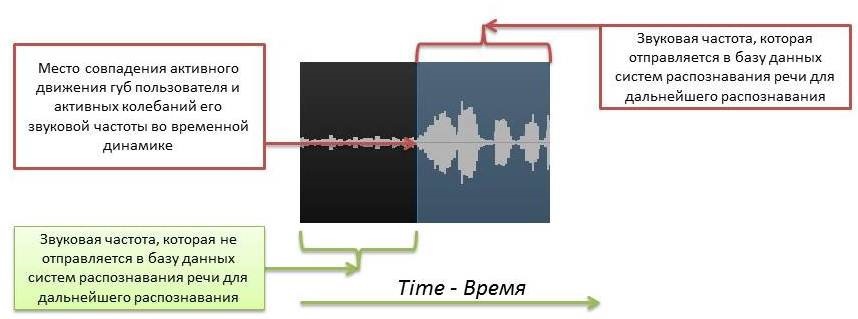
Figure 4. An example of the location of the beginning of the sound track, which must be recorded in order to be sent to the database of speech recognition systems for further analysis. As you can see, the system recorded an active movement of the user's lips, which in time dynamics coincided with active sound vibrations. At the place where the sound vibrations and movements of the user's lips became most active, the beginning of speech for recording was determined.
b) However, there are times when, as a result of co-articulation, the imposition of the articulation characteristic of the subsequent sound on the entire previous sound, the movement of the user's lips for various reasons do not have time to fully close during the moment when the speaker paused in the previous part speech. This is due to the fact that in the open state the user's lips need to spend less time and effort to create movement together with the user's audio-speech stream. In this case, the beginning of the recording of speech will definitely be at the moment when the most active movement of the user's lips coincides with the active fluctuation of the audio frequency when analyzing the audio-video stream in the time dynamics. This principle is also relevant for the moment when the announcer stops his speech, but only in this case it is about that the active phase of the movement of the speaker’s lips and fluctuations in its frequency begins to stop. At the place of maximum simultaneous termination of the active phase of these indicators of the user's speech, the presented solution stops the recording of the user's speech and sends the recorded fragment to the database of speech recognition systems for the implementation of the corresponding recognition. An example of the system for this situation is presented in Figure 5.

Figure 5 shows an example when the user's lips were in the open state, but the active sound oscillation in time began a little later. In this case, the system begins to record speech for subsequent recognition tasks at the moment when the most active period of fluctuations in the movement of the lips and the frequency of the user's voice is observed. As can be seen from the figure, the active phase of the sound wave, which is fixed for subsequent recognition, was determined by the presented invention a little earlier than the active sound vibrations of speech began. The moment of fixation was determined precisely due to the parallel analysis of the movement of the lips and the frequency of the user's voice in the time dynamics based on the average most relevant value.
The termination of speech recording for subsequent processing tasks is determined at the moment when the user stops conducting active lip movement and fluctuations in his sound frequency. This moment is considered for analysis in time space. For convenience, the system itself breaks the user's speech into pauses and micro pauses, guided by the principle of choosing the most correct speech fragment, which must be separated from the stream that should not be recorded for further recognition tasks, as well as the principle of fast and high-quality data processing in time space.
Thus, the system itself adapts to the manner of speech of a particular user. If the user makes his speech quickly, then in this case the presented system begins to fix pauses in speech to highlight individual speech fragments, these can be either individual expressions or sentences. If the user makes his speech clearly and clearly, then in this case, the system begins to record shorter speech fragments in the speaker’s speech, it can be either expressions, sentences, or individual words, and so on. If desired, the intensity of the analysis of the audio-visual flow in time space and the ability of the system to automatically determine pauses in the speech of a particular user can be adjusted.
As in the case of fixing the beginning of the user's speech for tasks of subsequent recognition, it is necessary to be guided by the fact that the movement of the user's lips, as a rule, ends a little later than the fluctuation of the voice. Therefore, in order for the speech stop to be determined most correctly, the system records the termination of the user's speech based on the average value of the moment when the termination of the active sound vibrations is as close as possible to the active termination of the movement of the user's lips. Figure 6 shows the moment when the user closed his lips completely and the system stopped recording speech for subsequent recognition tasks.
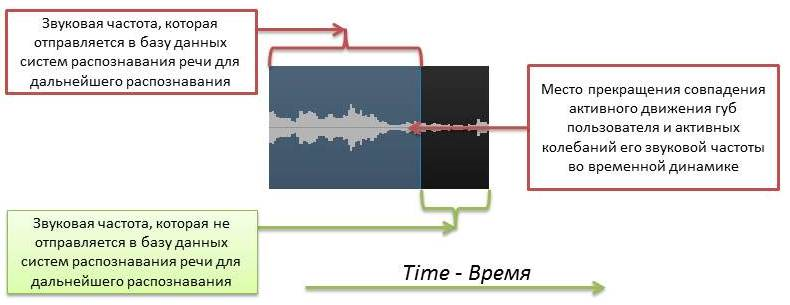
Figure 6. An example of a possible termination of a user’s speech recording for further recognition tasks.
It is also necessary to bear in mind that the system under development focuses on the processing of the audio stream for subsequent recognition tasks based on the parallel analysis of the active movement of the user's lips and the active sound vibrations of the user in the timeline. At the same time, the developed system captures the most relevant, most accurate moment when the combination or termination of the combination of the active movement of the user's lips occurs together with the vibration of the sound wave.
But in general, the developed system makes the main emphasis in its work on the determination and analysis of the movement of the user's lips. This is due to the fact that the video identification system, in addition to the means of audio recognition of speech of a real user, is a more reliable system (due to an additional source of video information) in comparison with other systems that focus mainly on processing audio data of a user's speech. So if the developed system begins to determine the active sound vibration of speech, while this process is not followed by any active movements of the user's lips in time space, this means that we are talking about speech frequencies that have nothing to do with user speech - therefore, they do not need to be processed.
Test video
Test reports
pros
Thus, due to the parallel processing of the movement of the user's lips in conjunction with the analysis of the frequency of his voice in the time dynamics, the presented video extension increases the accuracy of speech recognition systems due to just preliminary visual processing of audio data in real time:
• The developed system does not process the audio frequency, which has nothing to do with the user's speech - therefore, these audio data do not fall into the database of speech recognition systems for tasks of subsequent awareness;
• The system under development, due to the parallel processing of the audio-video stream of the user's speech, is able to automatically more accurately determine the beginning and end of the speech of a specific user - after the system has fixed this sound file, it sends it for subsequent recognition tasks to the database of speech recognition systems;
• The system under development is adapted to the user's speech style. For a more reliable fixation of pauses and micro pauses, the developed system identifies gaps where you can start or stop recording voice for subsequent recognition tasks, based on the speaker’s speech information presented in time dynamics. If desired, this analysis process can be adjusted for a specific user;
• The system under development produces voice recording constantly. That is, the device from which audio-visual speech recording is performed does not stop its work during the entire speech recognition process and the user of the presented invention has the ability to continuously recognize his speech without being distracted by the device itself;
• The resulting data after passing through the appropriate recognition process is displayed on the user's device in automatic mode;
• The presented system gives the main emphasis in its work to the movement of the user's lips in temporal dynamics and to the combination of the active phase of the movement of the user's lips with the active phase of combining the frequency of his voice. This is due to the fact that the movement of the lips gives a more informative idea of the real user of this system and his speech than using exclusively audio information.
• Due to the preliminary processing of the audio stream based on determining the movement of the lips of a real user, together with the analysis of the frequency of his voice, the overall processing speed is reduced. Since, on the one hand, an extraneous audio stream that has nothing to do with the speaker’s speech does not get into the database of speech recognition systems; on the other hand, in the database of speech recognition systems, after preliminary audiovisual processing, the user's speech frequency comes in separate small structured fragments, and not in the general speech stream.
• Indeed, through the use of an additional source of information, the quality of speech recognition is improved.
Minuses
• Unnaturalness. To fix the movement of the lips with the program, the subject should always be in the frame, which is unnatural for most potential users and makes the program uncomfortable. This contradicts the main advantage of speech recognition systems = the effect of freedom, decoupling from the device and its keyboard;
• Sensitivity to image quality. The system usually requires a background without artifacts. Any external motley review of the subject or a dark-bright, contrasting or other room with an abundance of interference in the background can adversely affect the quality of the system;
• Sensitivity to the camera. For the system to work, as a rule, a widescreen camera is required, which should read information from video as efficiently as possible;
• Sensitivity to the device. For the system to work correctly, a device is required that can calculate data in real time, calculating information in video at a frequency of 25 frames per second;
• Distance. For the program to work properly, it is necessary to observe the subordination between the camera and the subject. The program should be able to see the entire face of a person in full-face position in front of the camera. In this case, the distance should be sufficient so that you can read information from the lips as efficiently as possible;
• Behavioral features. The person in the frame should behave calmly, when communicating, do not use unnecessary gestures and so on, which may interfere with the system
• The presence of interference on the face of a person. Information from images of a person’s face should be well read out - there should be no beard, foreign objects, etc., which will cover the object of interest in the system’s operation.
If the conditions presented are not met, the speech recognition quality may not only not improve, but even worsen.
Conclusion
Thus, having examined the most common closed-source speech recognition systems, we decided to use Google’s speech tools, which are more built-in, accurate and faster due to the large computing power and have no restrictions on the number of voice requests per day.
Given these circumstances in the presented research work, we were able to carry out a test integration of the developed video extension into the existing speech recognition system based on the Google Speech Recognition API. We were able to experimentally prove that video (namely, the analyzer of the lips of the user during speech recognition) can be an additional source of information. However, the presented solution is far from user implementation, since it is currently not natural to work with and contradicts the main advantage of speech technologies: “The effect of freedom from the device”. Next, we plan on the basis of our experience to fix the architecture of the system and do so,
To be continued