Some methods for finding fuzzy duplicate videos
There is a fairly wide range of tasks where analysis is required, audio-visual models of reality. This applies to still images and video.

Below is a short overview of some existing methods for searching and identifying fuzzy duplicate videos, their advantages and disadvantages are considered. Based on the structural presentation of the video, a combination of methods is built.
The review is very small, for details, it is better to refer to the source.
The term “fuzzy duplicate” means an incomplete or partial coincidence of an object with another object of a similar class. Duplicates are natural and artificial. Natural duplicates are similar objects under similar conditions. Artificial fuzzy duplicates - obtained on the basis of the same original.
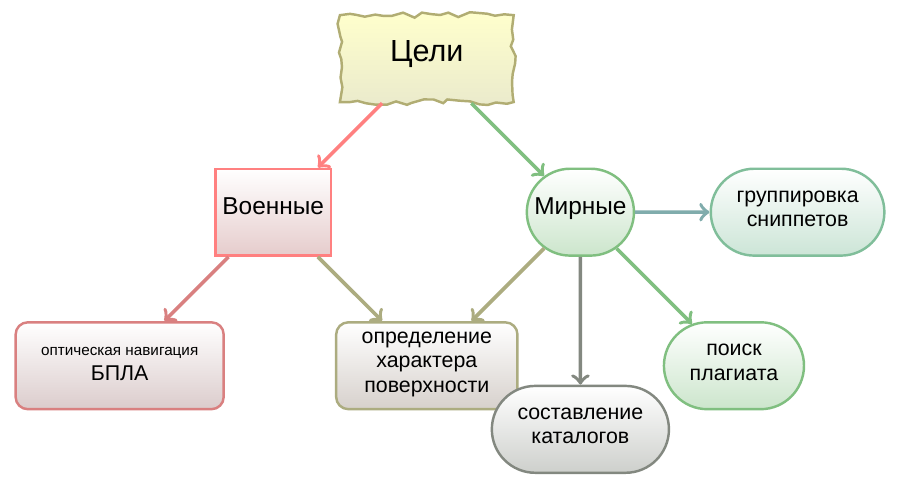
The search for fuzzy duplicates can be useful for optical navigation of unmanned aerial vehicles (unfortunately, not always for peaceful purposes), for determining the nature of the terrain, compiling video catalogs, grouping search engine snippets, filtering video ads, and searching for “pirated” video.
The problem of searching for fuzzy duplicate video (NDV) is closely related to the problems of classification (CV) and video search (PV). The task of NDV search can be reduced to classification, and that, in turn, to annotation and video search. | {NDV Search} | <| {KB} | <| {PV} |. But these tasks are independent.

To search for NDV, the video is divided into segments. Key frames are extracted from each segment. The characteristics of key frames are used to represent the entire video. The similarity between the videos is calculated as the similarity of sets of these characteristics.
Methods of searching for NDV form two categories: methods using global characteristics (GC); methods using local characteristics (LH). The line between the categories is conditional, very often mixed techniques are used. GC methods extract frame level signatures for modeling spatial, color, and temporal information. GCs summarize global statistics of low-level features. The similarity between videos is defined as the correspondence between sequences of signatures (signatures). They can be useful for searching for “almost identical” videos and can reveal minor edits in the space-time domain. GC are ineffective when working with artificial NDV, which were obtained as a result of cosmetic editing. For such groups, methods using the low-level characteristics of a segment or frame are more useful. Typically, these methods are affected by changes in the temporal order and insertion or deletion of frames. Compared to global methods, segment level approaches are slower. They are more demanding in memory, although they are capable of identifying copies that have undergone substantial editing.
LH methods reduce the task of searching for similar videos to the task of finding duplicate images. The main steps when comparing images: identification of special points; selection of neighborhoods of singular points; construction of feature vectors; selection of image descriptors; comparing descriptors of a pair of images. In the work of the Robust voting algorithm based on labels of behavior for video copy detection , specific points of the frame (using the Harris detector) are distinguished and their position is monitored throughout the video. After that, many trajectories of points are formed.

Pattern matching is based on a fuzzy search. The approach facilitates the localization of fuzzy duplicate fragments. However, the method is expensive due to the allocation of special frame points. And the fact that the trajectories of the points are sensitive to the movement of the camera makes the algorithm applicable only to search for exact copies of the video.
The authors of Non-identical Duplicate Video Detection Using The SIFT method highlight the special points of key frames, and evaluate the similarity of frames based on SIFT. The similarity of frames is calculated as the arithmetic mean of the number of coincident singular points. But to determine the similarity of the video, a full conformity assessment (PIC) is used as the average value of the similarity of key frames throughout the video. It is important that the average value is calculated, not for all possible pairs of frames, but only for some of them. This saves computing resources.
The work is also interesting in that in it the selection of frames occurs along the time axis, and not across, as in a regular video. Such a slice allows you to extract temporary information from the video, and apply spatial comparison methods to it, the same as for ordinary frames: SIFT is applied to the slices of two videos and the PIC is calculated.
According to the results of experiments, the method of longitudinal frame allocation is worse than usual. This is especially true if there are a lot of sudden movements of the camera in the video. The disadvantages of the general approach include the use of SIFT. The experiments were conducted on video with a small resolution (320 × 240). As the frame size increases, highlighting special points will be very costly. If PIC is applied only to regular frames, the temporary video information will not be taken into account.
Methods that use visual words are an improved version of the direct comparison of specific frame points. They are based on the quantization of singular points - the formation of "words". Comparison of frames (and video) takes place entirely in frequency dictionaries, as for texts. Work Inria-Learar's video copy detection system demonstrates the excellent performance of the method. Keyframes are represented by features that are obtained using SIFT. Then these characteristics are quantized into visual words. A binary signature is built from visual words. But, for the application of visual words, frequency dictionaries for a previously known subject area must be constructed.
Using GC methods, color, spatial and temporal information is extracted from the video, presented as a sequence of characters, and methods for finding matching lines are used.
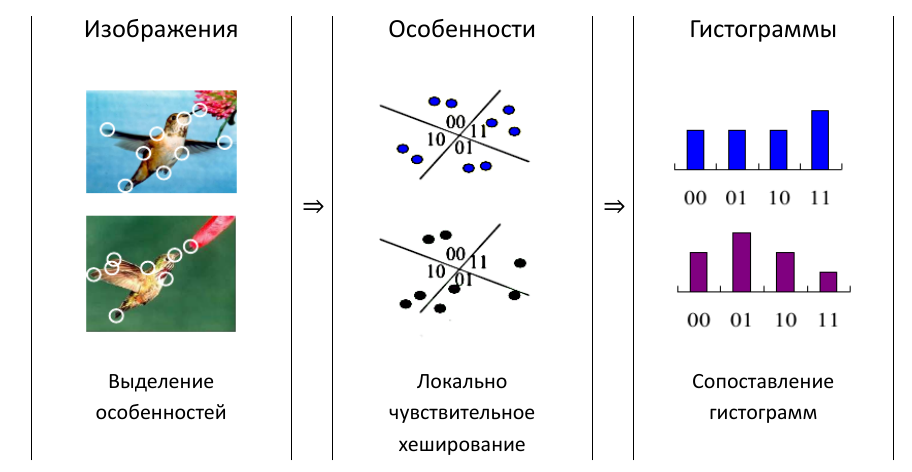
The paper Efficiently matching sets of features with random histograms applied locally sensitive hash (LCHH). It is used to display the color histogram of each key frame on a binary vector. Frame characteristics are distinguished from local features of the image. These characteristics are represented as sets of points in the space of characteristics. Using the LF, the points are mapped to discrete values. Based on a set of features, a histogram of the frame is built. The histograms are then compared as normal sequences.
Experimental results confirmed effectiveness. But, as pointed out in the Large-scale near-duplicate Web video search: challenge and opportunity method, it suffers from the potential problem of high memory consumption. Temporary information is not taken into account in any way.
In the Robust video signature based on ordinal measure used ordinal signatures to simulate the relative intensity distribution in the frame. The distance between two fragments is measured using the temporary similarity of signatures. The approach allows you to search for fuzzy duplicates of videos with different resolutions, frame rates, with minor spatial changes in frames. The advantage of the algorithm is the ability to work in real time. The disadvantages include instability to large inserts of extra frames. The method is poorly applicable for the search for natural fuzzy duplicates, for example, if the subject was shot in different light conditions.
In the Comparison of sequence matching techniques for video copy detection described signature movement that captures the relative change in intensity over time. Color signatures, motion signatures, and serial signatures are compared. Experiments show that ordinal signature is more efficient ...
The approach proposed in Near-duplicate Video Retrieval Based on Clustering by Multiple Sequence Alignment reduces the problem of finding fuzzy duplicates of a video to the problem of video classification. The method is based on multiple sequence alignment (MSA). A similar approach is used in bioinformatics to search for DNA sequence alignment. The authors use heuristic alignment and iterative methods proposed by Muscle: multiple sequence alignment with high accuracy and high throughput . The method can be described by the following sequence of steps.
To represent the video as genomes, key frames are extracted, transferred to a grayscale color space, and frames are divided into 2 × 2 blocks. Perhaps only 24 = (2 ⋅ 2)! spatial ordinal pattern. Each such pattern can be associated with a letter of the Latin alphabet.

The distance matrix is constructed using a sliding window of size n. Thus, the video comparison is based on n-grams. The comparison between the two DNA representations of the video takes place only in the window.
Window size and step size (how much to shift the window after comparison) are set as parameters.
The guide tree is built by a greedy heuristic algorithm for joining neighbors. According to the distance matrix, the two closest DNA representations are distinguished and combined into a single tree node as a video profile. In this model, each video DNA is a tree leaf, and profiles appear in the tree nodes. Profiles are also compared with each other, and glued similarly to the sheet representation. The result is a decision tree.
The guide tree is shown below.

Advantages of the approach: it has high accuracy and completeness and does not require special computational costs. Cons of the approach - the method does not take into account the temporal information of the video.
A suffix array approach to video copy detection in video sharing socialnetworks introduced a signature based on the definition of the boundaries of scenes (filming).
There are three different concepts. Frame or photographic frame - a static picture. A scene or editing frame is a set of frames connected by the unity of place and time. Shooting or cinematic shot, many frames connected by the unity of shooting. A scene may include several shots. In the literature, filming is often referred to as the “scene”. Next, we will consider the shooting, but we will call it the same - “scene”.
A video contains more information than just a series of frames. Events in a video uniquely determine its temporal structure, which can be represented by a set of key frames.
In this case, keyframes are not understood as an I-frame, but simply some special video frame. Events are not understood as the semantic component of the plot of the video, but only a change in the contents of the frames. Highlighting keyframes is based on the search for differences in brightness histograms. After extracting the keyframes, the length between the current keyframe and the previous one is calculated. All lengths are written as a one-dimensional sequence. This sequence of scene lengths is the signature of the video. Experiments show that two unrelated video clips do not have a long set of consecutive key frames with the same scene lengths. An effective way of matching video signatures is proposed. a suffix array is used for this. The problem comes down to finding common substrings. The method does not work well if there are many movements of the camera or objects in the video and during smooth transitions between scenes. The disadvantages include the inability to work in real time, for comparison, you must have the entire video.
In the work , Duplicate Search Algorithm in the Video Sequences Database Based on Comparison of the Scene Change Hierarchyan algorithm is proposed for matching the tree of scenes (filming). Based on the found scene changes, a binary tree is built. Subtrees correspond to video fragments. The root vertices of the subtrees store the values and position of the dominant change of scenes in the current fragment. When comparing, in one tree (longer video) they look for the vertices closest in magnitude to the root of the second tree, and compare their coordinates. The procedure is performed recursively for the remaining scene changes. The advantages of the method are resistance to most methods of creating artificial duplicates (since only temporary information is used), low complexity of comparing two clips and the ability to create hierarchical movie indices. This allows you to catch discrepancies in the initial stages of verification. The disadvantages of the approach, as well as the previous one, are that the characteristics of the scenes themselves are not taken into account.
A variety of methods are used to search for NDV. At the moment, GC methods seem to be the most promising. They allow you to approximately solve the problem without much computational cost. However, for clarification, LH methods may be required. As shown in the work of Large-scale near-duplicate Web video search: challenge and opportunity, the use of combined approaches gives higher accuracy than each of the methods individually.
Of interest are the works in which the structural model of video is built. Video can be seen as a sequence of facts developing over time. Moreover, in different videos, both the facts themselves and their order can be different. The properties of the facts form the spatial characteristic of the video, and the duration and order of the facts is temporary. The easiest way to extract facts from a video is to use scene change points. It’s important to keep in mind that time in two different videos can go differently. We propose using the ratio of the lengths of the scenes to the lengths of adjacent scenes ... The relative lengths of the scenes of the two fuzzy duplicates will rarely coincide. This is due, inter alia, to errors in recognizing the boundaries of scenes. To solve this problem, you can apply sequence alignment algorithms. But, so, we only compare the order of video facts. To compare the facts themselves, the internal characteristics of the scenes are required, for example, the characteristics of the initial and final frames. Here it is convenient to use visual words, as a technique from LH methods. So we got a scene handle.
Formally, a scene is “shooting,” a cinematic frame is a collection of many photographic frames within the time domain, frames that differ significantly from frames in neighboring areas. In the picture below - the first frames of scenes of some video.
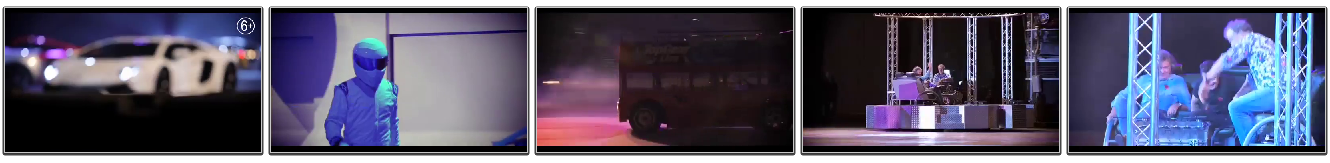
If the source video is compressed with different codecs, we get fuzzy duplicates of this video. Highlighting the scenes in each video, we see that the scene change points for these two files do not match.
To solve this problem, it is proposed to use the relative lengths of the scenes. The relative length of the scene is calculated as the vector of the ratio of the absolute length of the scene to the absolute lengths of the remaining video scenes. In practical problems, it is more convenient to calculate the ratio of lengths for the three previous scenes, and not for all. This is also convenient if the entire video is inaccessible to us and we are dealing with a video stream, for example, in real-time tasks.
The relative lengths of the scenes of the two fuzzy duplicates will rarely coincide. Moreover, many scenes may simply not be recognized. This is due, inter alia, to errors in recognizing the boundaries of scenes.
If the relative scene length of one video differs from the scene length of another video by no more than two times, and all previous scenes are aligned, then the current pair of scenes expresses the same phenomenon, provided that both videos are fuzzy duplicates of each other ( hypothesis Gale Church ). A similar approach is used in mathematical linguistics to align parallel cases of texts in different languages. The less the relative lengths of the scenes differ, the more likely the scenes are similar. If the lengths differ by more than two times, then the length of the smaller scene is added to the length of the next scene of the same video, and the combined scene is considered as one. If the relative lengths of the video scenes coincide, a comparison of the internal properties of the scene is applied.
Thus, the proposed scene descriptor can be formally described. It consists of a vector of relations of the length of the scene to the lengths of other scenes and the characteristics of the initial and final frames. It is convenient to store it right away, with associations of neighboring scenes (the three previous ones) given the Gale Church hypothesis.
Thanks to such a descriptor and various technical tricks (semantic hashing), a fairly obvious algorithm was built.

But its practical implementation is still in its infancy. Some results were nevertheless obtained * , but for some external reasons the work was temporarily stopped.
I will be very glad to any comments and additions.
UPD 1:
Some additions to the material can be found in the presentation: Elements of the search for fuzzy duplicates of the video
Related topic:
Thanks to goodok for fixing grammar errors.
Below is a short overview of some existing methods for searching and identifying fuzzy duplicate videos, their advantages and disadvantages are considered. Based on the structural presentation of the video, a combination of methods is built.
The review is very small, for details, it is better to refer to the source.
The term “fuzzy duplicate” means an incomplete or partial coincidence of an object with another object of a similar class. Duplicates are natural and artificial. Natural duplicates are similar objects under similar conditions. Artificial fuzzy duplicates - obtained on the basis of the same original.
The search for fuzzy duplicates can be useful for optical navigation of unmanned aerial vehicles (unfortunately, not always for peaceful purposes), for determining the nature of the terrain, compiling video catalogs, grouping search engine snippets, filtering video ads, and searching for “pirated” video.
The problem of searching for fuzzy duplicate video (NDV) is closely related to the problems of classification (CV) and video search (PV). The task of NDV search can be reduced to classification, and that, in turn, to annotation and video search. | {NDV Search} | <| {KB} | <| {PV} |. But these tasks are independent.
General algorithm
To search for NDV, the video is divided into segments. Key frames are extracted from each segment. The characteristics of key frames are used to represent the entire video. The similarity between the videos is calculated as the similarity of sets of these characteristics.
The approaches
Methods of searching for NDV form two categories: methods using global characteristics (GC); methods using local characteristics (LH). The line between the categories is conditional, very often mixed techniques are used. GC methods extract frame level signatures for modeling spatial, color, and temporal information. GCs summarize global statistics of low-level features. The similarity between videos is defined as the correspondence between sequences of signatures (signatures). They can be useful for searching for “almost identical” videos and can reveal minor edits in the space-time domain. GC are ineffective when working with artificial NDV, which were obtained as a result of cosmetic editing. For such groups, methods using the low-level characteristics of a segment or frame are more useful. Typically, these methods are affected by changes in the temporal order and insertion or deletion of frames. Compared to global methods, segment level approaches are slower. They are more demanding in memory, although they are capable of identifying copies that have undergone substantial editing.
Local characteristics
Track tracking
LH methods reduce the task of searching for similar videos to the task of finding duplicate images. The main steps when comparing images: identification of special points; selection of neighborhoods of singular points; construction of feature vectors; selection of image descriptors; comparing descriptors of a pair of images. In the work of the Robust voting algorithm based on labels of behavior for video copy detection , specific points of the frame (using the Harris detector) are distinguished and their position is monitored throughout the video. After that, many trajectories of points are formed.
Pattern matching is based on a fuzzy search. The approach facilitates the localization of fuzzy duplicate fragments. However, the method is expensive due to the allocation of special frame points. And the fact that the trajectories of the points are sensitive to the movement of the camera makes the algorithm applicable only to search for exact copies of the video.
Mean
The authors of Non-identical Duplicate Video Detection Using The SIFT method highlight the special points of key frames, and evaluate the similarity of frames based on SIFT. The similarity of frames is calculated as the arithmetic mean of the number of coincident singular points. But to determine the similarity of the video, a full conformity assessment (PIC) is used as the average value of the similarity of key frames throughout the video. It is important that the average value is calculated, not for all possible pairs of frames, but only for some of them. This saves computing resources.
Longitudinal frames
The work is also interesting in that in it the selection of frames occurs along the time axis, and not across, as in a regular video. Such a slice allows you to extract temporary information from the video, and apply spatial comparison methods to it, the same as for ordinary frames: SIFT is applied to the slices of two videos and the PIC is calculated.
According to the results of experiments, the method of longitudinal frame allocation is worse than usual. This is especially true if there are a lot of sudden movements of the camera in the video. The disadvantages of the general approach include the use of SIFT. The experiments were conducted on video with a small resolution (320 × 240). As the frame size increases, highlighting special points will be very costly. If PIC is applied only to regular frames, the temporary video information will not be taken into account.
Visual words
Methods that use visual words are an improved version of the direct comparison of specific frame points. They are based on the quantization of singular points - the formation of "words". Comparison of frames (and video) takes place entirely in frequency dictionaries, as for texts. Work Inria-Learar's video copy detection system demonstrates the excellent performance of the method. Keyframes are represented by features that are obtained using SIFT. Then these characteristics are quantized into visual words. A binary signature is built from visual words. But, for the application of visual words, frequency dictionaries for a previously known subject area must be constructed.
Global characteristics
Using GC methods, color, spatial and temporal information is extracted from the video, presented as a sequence of characters, and methods for finding matching lines are used.
Locally Sensitive Hashing
The paper Efficiently matching sets of features with random histograms applied locally sensitive hash (LCHH). It is used to display the color histogram of each key frame on a binary vector. Frame characteristics are distinguished from local features of the image. These characteristics are represented as sets of points in the space of characteristics. Using the LF, the points are mapped to discrete values. Based on a set of features, a histogram of the frame is built. The histograms are then compared as normal sequences.
Experimental results confirmed effectiveness. But, as pointed out in the Large-scale near-duplicate Web video search: challenge and opportunity method, it suffers from the potential problem of high memory consumption. Temporary information is not taken into account in any way.
Ordinal Signatures
In the Robust video signature based on ordinal measure used ordinal signatures to simulate the relative intensity distribution in the frame. The distance between two fragments is measured using the temporary similarity of signatures. The approach allows you to search for fuzzy duplicates of videos with different resolutions, frame rates, with minor spatial changes in frames. The advantage of the algorithm is the ability to work in real time. The disadvantages include instability to large inserts of extra frames. The method is poorly applicable for the search for natural fuzzy duplicates, for example, if the subject was shot in different light conditions.
In the Comparison of sequence matching techniques for video copy detection described signature movement that captures the relative change in intensity over time. Color signatures, motion signatures, and serial signatures are compared. Experiments show that ordinal signature is more efficient ...
Video like DNA
The approach proposed in Near-duplicate Video Retrieval Based on Clustering by Multiple Sequence Alignment reduces the problem of finding fuzzy duplicates of a video to the problem of video classification. The method is based on multiple sequence alignment (MSA). A similar approach is used in bioinformatics to search for DNA sequence alignment. The authors use heuristic alignment and iterative methods proposed by Muscle: multiple sequence alignment with high accuracy and high throughput . The method can be described by the following sequence of steps.
- A DNA representation is built for the video.
- Video from the database, each is compared with each, and a matrix of distances is built.
- Based on the distance matrix, a guide tree is constructed using the neighbor joining method.
- Based on the guide tree, progressive video alignment is performed.
- Alignment results are used to form clusters of videos.
- When searching the database, the query is compared with the centers of the clusters. If the similarity between the request and the center of the cluster exceeds a certain threshold, then all the clips in the cluster are considered fuzzy duplicates of the request.
To represent the video as genomes, key frames are extracted, transferred to a grayscale color space, and frames are divided into 2 × 2 blocks. Perhaps only 24 = (2 ⋅ 2)! spatial ordinal pattern. Each such pattern can be associated with a letter of the Latin alphabet.
The distance matrix is constructed using a sliding window of size n. Thus, the video comparison is based on n-grams. The comparison between the two DNA representations of the video takes place only in the window.
Window size and step size (how much to shift the window after comparison) are set as parameters.
The guide tree is built by a greedy heuristic algorithm for joining neighbors. According to the distance matrix, the two closest DNA representations are distinguished and combined into a single tree node as a video profile. In this model, each video DNA is a tree leaf, and profiles appear in the tree nodes. Profiles are also compared with each other, and glued similarly to the sheet representation. The result is a decision tree.
The guide tree is shown below.
Advantages of the approach: it has high accuracy and completeness and does not require special computational costs. Cons of the approach - the method does not take into account the temporal information of the video.
Scene change
A suffix array approach to video copy detection in video sharing socialnetworks introduced a signature based on the definition of the boundaries of scenes (filming).
There are three different concepts. Frame or photographic frame - a static picture. A scene or editing frame is a set of frames connected by the unity of place and time. Shooting or cinematic shot, many frames connected by the unity of shooting. A scene may include several shots. In the literature, filming is often referred to as the “scene”. Next, we will consider the shooting, but we will call it the same - “scene”.
A video contains more information than just a series of frames. Events in a video uniquely determine its temporal structure, which can be represented by a set of key frames.
In this case, keyframes are not understood as an I-frame, but simply some special video frame. Events are not understood as the semantic component of the plot of the video, but only a change in the contents of the frames. Highlighting keyframes is based on the search for differences in brightness histograms. After extracting the keyframes, the length between the current keyframe and the previous one is calculated. All lengths are written as a one-dimensional sequence. This sequence of scene lengths is the signature of the video. Experiments show that two unrelated video clips do not have a long set of consecutive key frames with the same scene lengths. An effective way of matching video signatures is proposed. a suffix array is used for this. The problem comes down to finding common substrings. The method does not work well if there are many movements of the camera or objects in the video and during smooth transitions between scenes. The disadvantages include the inability to work in real time, for comparison, you must have the entire video.
In the work , Duplicate Search Algorithm in the Video Sequences Database Based on Comparison of the Scene Change Hierarchyan algorithm is proposed for matching the tree of scenes (filming). Based on the found scene changes, a binary tree is built. Subtrees correspond to video fragments. The root vertices of the subtrees store the values and position of the dominant change of scenes in the current fragment. When comparing, in one tree (longer video) they look for the vertices closest in magnitude to the root of the second tree, and compare their coordinates. The procedure is performed recursively for the remaining scene changes. The advantages of the method are resistance to most methods of creating artificial duplicates (since only temporary information is used), low complexity of comparing two clips and the ability to create hierarchical movie indices. This allows you to catch discrepancies in the initial stages of verification. The disadvantages of the approach, as well as the previous one, are that the characteristics of the scenes themselves are not taken into account.
Conclusion
A variety of methods are used to search for NDV. At the moment, GC methods seem to be the most promising. They allow you to approximately solve the problem without much computational cost. However, for clarification, LH methods may be required. As shown in the work of Large-scale near-duplicate Web video search: challenge and opportunity, the use of combined approaches gives higher accuracy than each of the methods individually.
Combination
Of interest are the works in which the structural model of video is built. Video can be seen as a sequence of facts developing over time. Moreover, in different videos, both the facts themselves and their order can be different. The properties of the facts form the spatial characteristic of the video, and the duration and order of the facts is temporary. The easiest way to extract facts from a video is to use scene change points. It’s important to keep in mind that time in two different videos can go differently. We propose using the ratio of the lengths of the scenes to the lengths of adjacent scenes ... The relative lengths of the scenes of the two fuzzy duplicates will rarely coincide. This is due, inter alia, to errors in recognizing the boundaries of scenes. To solve this problem, you can apply sequence alignment algorithms. But, so, we only compare the order of video facts. To compare the facts themselves, the internal characteristics of the scenes are required, for example, the characteristics of the initial and final frames. Here it is convenient to use visual words, as a technique from LH methods. So we got a scene handle.
Formally, a scene is “shooting,” a cinematic frame is a collection of many photographic frames within the time domain, frames that differ significantly from frames in neighboring areas. In the picture below - the first frames of scenes of some video.
If the source video is compressed with different codecs, we get fuzzy duplicates of this video. Highlighting the scenes in each video, we see that the scene change points for these two files do not match.
To solve this problem, it is proposed to use the relative lengths of the scenes. The relative length of the scene is calculated as the vector of the ratio of the absolute length of the scene to the absolute lengths of the remaining video scenes. In practical problems, it is more convenient to calculate the ratio of lengths for the three previous scenes, and not for all. This is also convenient if the entire video is inaccessible to us and we are dealing with a video stream, for example, in real-time tasks.
The relative lengths of the scenes of the two fuzzy duplicates will rarely coincide. Moreover, many scenes may simply not be recognized. This is due, inter alia, to errors in recognizing the boundaries of scenes.
If the relative scene length of one video differs from the scene length of another video by no more than two times, and all previous scenes are aligned, then the current pair of scenes expresses the same phenomenon, provided that both videos are fuzzy duplicates of each other ( hypothesis Gale Church ). A similar approach is used in mathematical linguistics to align parallel cases of texts in different languages. The less the relative lengths of the scenes differ, the more likely the scenes are similar. If the lengths differ by more than two times, then the length of the smaller scene is added to the length of the next scene of the same video, and the combined scene is considered as one. If the relative lengths of the video scenes coincide, a comparison of the internal properties of the scene is applied.
Thus, the proposed scene descriptor can be formally described. It consists of a vector of relations of the length of the scene to the lengths of other scenes and the characteristics of the initial and final frames. It is convenient to store it right away, with associations of neighboring scenes (the three previous ones) given the Gale Church hypothesis.
What next …
Thanks to such a descriptor and various technical tricks (semantic hashing), a fairly obvious algorithm was built.
But its practical implementation is still in its infancy. Some results were nevertheless obtained * , but for some external reasons the work was temporarily stopped.
I will be very glad to any comments and additions.
UPD 1:
Some additions to the material can be found in the presentation: Elements of the search for fuzzy duplicates of the video
Related topic:
Acknowledgments
Thanks to goodok for fixing grammar errors.