Fast morphology or files against MySQL
At the entrance of one project, I had to create ultrafast Russian morphology. About 50,000 words per second on a rather weak laptop, which is only 2-3 times slower than stamming (trimming the endings according to the rules), but it is much more accurate. This data is on a regular disk, on an SSD or virtual disk, the search is much faster.
The initial version was in MySQL, but translating it into files I managed to achieve a hundredfold increase in productivity. About when and why files are faster than MySQL and I will tell in the article.
But for starters, so as not to torment those who are interested in my implementation. Here is the link to her on GitHub. There is a source for PHP. For other languages, writing an analogue is quite easy, there will be no more than 100 lines of code. The main problem is to convert the database into a searchable form that I have already completed. You just need to port the search to your language.
Task
Everyone who is even a little in the subject of contextual advertising uses Yandex.WordStat . This is a service for selecting keywords. However, it contains a lot of noise.
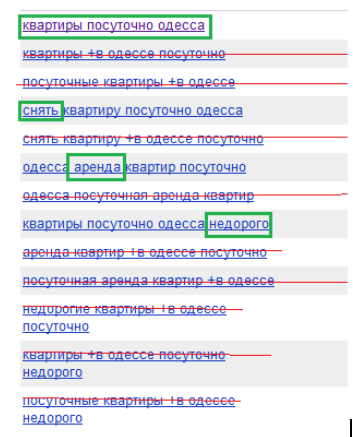
All requests that duplicate past ones are crossed out in the screenshot. The difference between the main request and the refinement is highlighted in green. Those. All these 60 words from the screenshot can be written with 6types:
Odessa apartments take off rent inexpensively
Those. 90% of the information in WordStat is noise. But the main problem is that you need to copy data, paste it into a notebook and edit. It was more convenient for users to use checkmarks. Here, for example, comparing WordStat with what I got as a result:
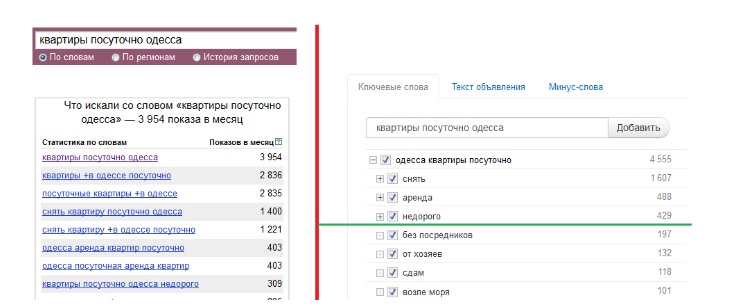
In the screenshot, Yandex.Wordstat and HTraffic . Data alone, different visualization.
In general, this allows you to 10-20 times speed up the selection of keywords. However, all this requires morphology. At the same time, the Wordstat API can issue up to 200 requests, each of them has an average of 5 words. This is already 1000 words. In addition, along with the request, we also break through its synonyms, there can be up to 10. Those. 10,000 words is a very real situation.
Of course, you can use caching and remember previously found word forms. Then the number of searches will be reduced once every 10. But this does not completely eliminate the problems with speed.
Homonymy and normalization
Speed is not our only problem. Russian is too big and powerful. It has a huge number of word forms (spellings of a word in another case, gender, etc.). And sometimes different word forms of different words are written the same way. This is called homonymy. For example, when the system encounters the word-string “delhi” in the text, it does not know to which word it belongs:
- Delhi. “Delhi is the capital of India.”
- Share. “Boldly divided by two.”
- Child. “Where did you share my socks?”
Such ambiguity greatly disturbs us. It was much more convenient if each word-string had no more than one interpretation. In this case, we would have much less code and increased speed.
But to teach resolving machine homonymy is a difficult task. It takes a lot of time to implement, and can also negatively affect performance.
I copied the solution to this problem from Yandex.Direct. It combines words having homonymy into one. Those. they get one ID. Sometimes this leads to glitches when the request does not contain the searched word, but glued to it, but this happens quite rarely. Otherwise, Direct would not use such a solution.
Base AOT.ru
In runet there is only one free base of Russian morphology - Aot.ru . It has about 200 thousand words, each with an average of about 15 word forms. The documentation on it is very confusing and has inaccuracies. Therefore, I will spend a couple of paragraphs to describe it.
The base looks like this: it has sets of endings, prefixes and words. The word has a pseudo-basis (roughly speaking the root of the word), the number of the prefix (if any), and the number of endings. To generate all variants of a word, you need to loop through the endings in a loop, and add a prefix and a pseudo-base to each of them in front.
There are several points:
- There may be no pseudo-foundations. For example: go, walked. In this case, “#” is written in the database instead of the pseudo-base.
- Sometimes there are prefixes in the ending table. This happens in superlative adjectives (best -> best). The prefix from the end should go before the main prefix.
The type of base when endings are separated from words is called compressed. In this case, the base weighs a little, but the search on it is extremely slow. Therefore, the dictionary needs to be "unclenched" - write down each word form separately. But word forms in the database are several million, so this requires several tens of megabytes. The first thing I looked in the direction of databases.
MySQL
I wrote all the word forms in one table with two columns, text and id of the word. I added an index on the text of the word form, but the speed was extremely low. Running table optimization procedures did not help.
To understand the same reason, I began to search immediately for 10 words, through IN. Speed increased slightly, therefore. it was not about parsing SQL and NO-SQL would not help me.
Games with an index type and storage also yielded almost nothing.
I also studied several performance tests comparing MySQL with other engines, for example, Mongo. However, not a single engine demonstrates a noticeable superiority of read speed over MySQL in them.
CRC32
I decided to reduce the length of the index. The text of the word form was replaced with its checksum (crc32).
Since word forms are about 2 million, and 2 ^ 32 = 4 billion, we get a probability of collision of 0.05%. According to well-known words, there are about 1,000 collisions in total, you can exclude them simply by specifying everything in the associative array with their real id:
if(isset($Collisions[$wordStr])) return $Collisions[$wordStr];But this does not exclude false positives if the word form is not in the database, then the left id is returned in 1 out of 2000 cases. But this is critical only for searching huge enormous data arrays (like Wikipedia).
A person’s vocabulary is extremely rare above 10,000 words. For example, Leo Tolstoy has 20,000. There are 200,000 words in the database, if you organize a search in the complete works of Tolstoy, then the probability that due to a collision he finds something superfluous will be 1 in 10 * 2000. That is, 1 to 20,000.
In other words, the likelihood of glitches due to the use of crc32 is extremely small. And this is more than offset by an increase in productivity and a decrease in the amount of data.
However, this did not help much. The speed was about 500 words per second. I began to look towards the files.
Files
When all methods of optimizing MySQL were tried, I decided to write the morphological dictionary to a file and search it with binary search. The results exceeded my expectations. Speed has tripled somewhere.
For me, this figure was unexpected, since I wrote in PHP, and scripting languages bear their overhead (like marshaling). At the same time, MySQL and my implementation use similar algorithms - binary trees and quick search.
In both cases, the complexity of log (n). Those. log2 (2.000.000) ~ 21 occurs, the read operation from the file. PHP should convert a string from its current look 21 times to its internal one. In MySQL, this does not happen. In theory, PHP should noticeably lose in speed.
To understand what’s the matter, I added file locking for reading. The lock itself is not needed here, because reading with reading does not conflict, and I tested it in one thread. The overhead was interesting. Speed dropped 1.5 times. It is likely that one of the main reasons is that MySQL prevents write conflicts in multiple threads, and this is not necessary in our task.
But this does not explain even half the difference in speed. Where the rest of the brakes came from is not clear to me. Although trees and drivers can carry their overhead, they are not so big. Your opinion is interesting in the comments.
Hashing
Trees are not the optimal structure for finding data. The hash is much faster. Hash has a constant time. In our case, instead of 21 operations, we will spend 1-2. In this case, reading will occur sequentially, i.e. the disk cache will work better and the read head will not have to jump back and forth.
The hash is used, for example, in PHP to implement associative arrays. Binary trees are used in the database, because they allow you to organize sorting and more and less operators. But when you need to select elements equal to some value, then here the trees lose the hash on large tables tens of times.
Thus, I managed to speed up the library 10-15 times. But I did not stop there, I began to store CRC and id words in different files. Thus, the reading became completely consistent. I also began to keep the file pointer open between several search runs.
The total performance gain before MySQL was 80-100 times. The scatter of the assessment is due to the fact that I tested on a different ratio of errors and correct word forms.
conclusions
I do not call for replacing the database with files anytime, anywhere. The database has a lot more features. But there are several cases when this replacement will be justified. For example, these are static bases (cities by IP, morphology). In this case, switching to files, among other things, will make life easier, for installing on another server it will be enough to simply copy the files.
The main feature of the database is getting rid of conflicts between threads. This is quite difficult to organize when working with files. DBs block reading when recording is in progress. But at high loads, this gives rise to its problems.
How many servers and flows you did not have, all of them are blocked when one of them writes data to the database. It all depends on the type of storage, some put a lock at the row level, but this does not always help.
Therefore, the bases are often shared. One is used for reading, the second for writing. They are synchronized from time to time, for example at night. If, in most read requests, you select with the “=” operator, then you can increase the speed many times by making copies of tables in files and using a hash.
If the recording database slows down, then, in some cases, it will be faster to write something like a log with changes, and when synchronizing, translate this log into a normal database. But this option does not always help.