CQRS Types
CQRS is a pretty well-studied pattern. You can often hear that you are either following CQRS or not, bearing in mind that this is a bit of a binary choice. In this article, I would like to show that there is a range of variations of this concept, as well as how different types of CQRS may look in practice.
With this type, you do not use the CQRS pattern at all. This means that your domain model uses domain classes to serve both commands and queries.
Consider the Customer class as an example:
With a null type of CQRS, you work with the CustomerRepository class, which looks like this:
The Search method here is a request. It is used to retrieve data on custom meters from the database and return this data to the client (which can be a UI or a separate application that accesses your application through the API). Note that this method returns a list of domain objects.
The advantage of this approach is that there is no overhead in terms of the amount of code. In other words, you have the only model that you can use for both commands and queries, and you do not have to duplicate the code.
The disadvantage here is that this single model is not optimized for read operations. If you need to show a list of custom meters on the UI, you usually do not need to display their orders. Instead, in most cases you will want to show only brief information, such as id, name and number of orders.
Using domain classes for data transportation leads to the fact that all subobjects (such as Orders) of customomers are loaded into memory from the database. This leads to serious overhead, as The UI only needs the number of orders, not the orders themselves.
This type of CQRS is good for applications with little (or no) performance requirements. For other types of applications, we must use the following types of CQRS.
With this type of CQRS, your class structure is split to serve read and write operations. This means that you are creating a set of DTO classes to transport data loaded from the database.
The DTO for the Customer class might look like this:
The Search method in the repository returns a DTO list instead of a list of domain objects:
Search can use both ORM and regular ADO.NET to fetch the required data. This should be determined by the performance requirements in each case. There is no need to roll back to ADO.NET if the performance of the method is satisfactory.
DTOs add some duplication in the sense that we now need to create two classes instead of one: once for commands in the form of a domain object and one more time for requests in the DTO format. At the same time, they allow us to create clean and clear data structures that clearly fall on the needs of our read operations, as they contain only what is needed when displaying. And the more clearly we express our intentions in the code, the better.
In my opinion, this type of CQRS is sufficient for most enterprise applications, as it gives a pretty good balance between simplicity and code performance. Also, with this approach, we have some flexibility in which tool to choose for queries. If the performance of the method is not critical, we can use ORM and save developer time. Otherwise, we can use ADO.NET directly (or a lightweight ORM like Dapper) and write complex and optimized queries manually.
This type of CQRS involves the use of separate models and a set of APIs to serve read and write requests.
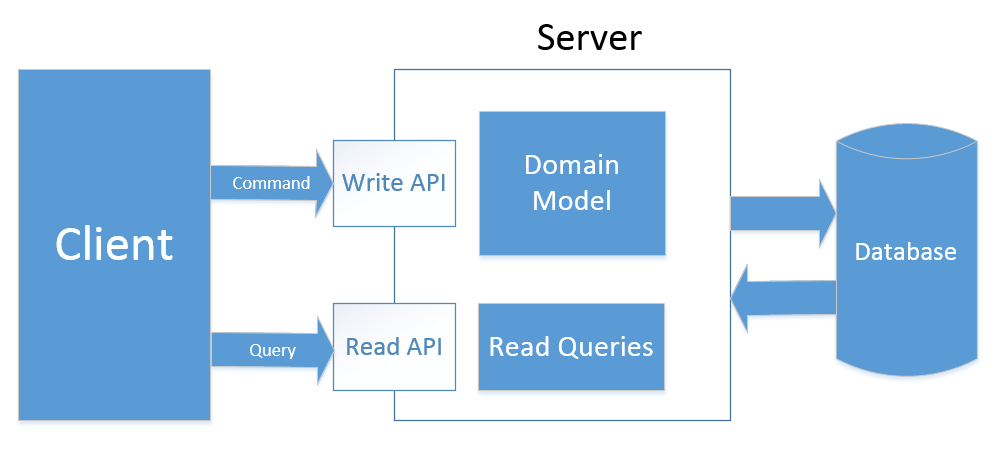
This means that in addition to the DTO, we extract all read operations from our model. Repositories now contain only methods that relate to commands:
And the search logic is in a separate class:
This approach adds more overhead compared to the previous one in terms of the amount of code needed to process requests, but this is a good solution if you have large data reading loads.
In addition to being able to write optimized queries, type 2 allows us to easily wrap the part of the API related to the queries into some caching mechanism or even move this API to a separate server or group of servers with a configured loader-belenser. This solution is perfect for applications with a large difference in read and write loads, as allows you to scale read operations well.
If you need an even greater increase in performance in terms of reading operations, you need to move in the direction of type 3.
This is the type that is considered by many to be the “true” CQRS. To scale the read operations even more, we can use a separate storage optimized for the requests of our system. Often a similar storage is a NoSQL database, for example MongoDB, or a set of replicas from several instances:

Synchronization here takes place in the background and may take some time. Such repositories are called “eventually consistent”.
A good example here is indexing customer data using Elastic Search. Often we do not want to use the full-text search built into SQL Server, because It doesn’t scale very well. Instead, we can use non-relational data storages optimized for custom search.
Together with the best scalability of read operations, this type of CQRS carries the largest overhead. We not only share our model of reading and writing logically, i.e. we use separate classes and even assemblies for this, but we also share the database itself.
There are different gradations of the CQRS pattern that you can use in your application. There is nothing wrong with sticking to type 1 and not moving toward types 2 and 3 if type 1 meets your application's performance requirements.
I would like to emphasize this point: CQRS is not a binary choice. There are various variations between not separating the read and write operations at all (type 0) and separating them completely (type 3).
A balance should be struck between the degree of segregation and the complexity that this segregation brings. The balance should be sought in each case separately, often using several iterations. The CQRS pattern should not be applied simply because "we can."
English version of the article: Types of CQRS
Type 0: without CQRS
With this type, you do not use the CQRS pattern at all. This means that your domain model uses domain classes to serve both commands and queries.
Consider the Customer class as an example:
public class Customer
{
public int Id { get; private set; }
public string Name { get; private set; }
public IReadOnlyList Orders { get; private set; }
public void AddOrder(Order order)
{
/* … */
}
/* Other methods */
}
With a null type of CQRS, you work with the CustomerRepository class, which looks like this:
public class CustomerRepository
{
public void Save(Customer customer) { /* … */ }
public Customer GetById(int id) { /* … */ }
public IReadOnlyList Search(string name) { /* … */ }
}
The Search method here is a request. It is used to retrieve data on custom meters from the database and return this data to the client (which can be a UI or a separate application that accesses your application through the API). Note that this method returns a list of domain objects.
The advantage of this approach is that there is no overhead in terms of the amount of code. In other words, you have the only model that you can use for both commands and queries, and you do not have to duplicate the code.
The disadvantage here is that this single model is not optimized for read operations. If you need to show a list of custom meters on the UI, you usually do not need to display their orders. Instead, in most cases you will want to show only brief information, such as id, name and number of orders.
Using domain classes for data transportation leads to the fact that all subobjects (such as Orders) of customomers are loaded into memory from the database. This leads to serious overhead, as The UI only needs the number of orders, not the orders themselves.
This type of CQRS is good for applications with little (or no) performance requirements. For other types of applications, we must use the following types of CQRS.
Type 1: separate class hierarchy
With this type of CQRS, your class structure is split to serve read and write operations. This means that you are creating a set of DTO classes to transport data loaded from the database.
The DTO for the Customer class might look like this:
public class CustomerDto
{
public int Id { get; set; }
public string Name { get; set; }
public int OrderCount { get; set; }
}
The Search method in the repository returns a DTO list instead of a list of domain objects:
public class CustomerRepository
{
public void Save(Customer customer) { /* … */ }
public Customer GetById(int id) { /* … */ }
public IReadOnlyList Search(string name) { /* … */ }
}
Search can use both ORM and regular ADO.NET to fetch the required data. This should be determined by the performance requirements in each case. There is no need to roll back to ADO.NET if the performance of the method is satisfactory.
DTOs add some duplication in the sense that we now need to create two classes instead of one: once for commands in the form of a domain object and one more time for requests in the DTO format. At the same time, they allow us to create clean and clear data structures that clearly fall on the needs of our read operations, as they contain only what is needed when displaying. And the more clearly we express our intentions in the code, the better.
In my opinion, this type of CQRS is sufficient for most enterprise applications, as it gives a pretty good balance between simplicity and code performance. Also, with this approach, we have some flexibility in which tool to choose for queries. If the performance of the method is not critical, we can use ORM and save developer time. Otherwise, we can use ADO.NET directly (or a lightweight ORM like Dapper) and write complex and optimized queries manually.
Type 2: separate models
This type of CQRS involves the use of separate models and a set of APIs to serve read and write requests.
This means that in addition to the DTO, we extract all read operations from our model. Repositories now contain only methods that relate to commands:
public class CustomerRepository
{
public void Save(Customer customer) { /* … */ }
public Customer GetById(int id) { /* … */ }
}
And the search logic is in a separate class:
public class SearchCustomerQueryHandler
{
public IReadOnlyList Execute(SearchCustomerQuery query)
{
/* … */
}
}
This approach adds more overhead compared to the previous one in terms of the amount of code needed to process requests, but this is a good solution if you have large data reading loads.
In addition to being able to write optimized queries, type 2 allows us to easily wrap the part of the API related to the queries into some caching mechanism or even move this API to a separate server or group of servers with a configured loader-belenser. This solution is perfect for applications with a large difference in read and write loads, as allows you to scale read operations well.
If you need an even greater increase in performance in terms of reading operations, you need to move in the direction of type 3.
Type 3: separate storage
This is the type that is considered by many to be the “true” CQRS. To scale the read operations even more, we can use a separate storage optimized for the requests of our system. Often a similar storage is a NoSQL database, for example MongoDB, or a set of replicas from several instances:
Synchronization here takes place in the background and may take some time. Such repositories are called “eventually consistent”.
A good example here is indexing customer data using Elastic Search. Often we do not want to use the full-text search built into SQL Server, because It doesn’t scale very well. Instead, we can use non-relational data storages optimized for custom search.
Together with the best scalability of read operations, this type of CQRS carries the largest overhead. We not only share our model of reading and writing logically, i.e. we use separate classes and even assemblies for this, but we also share the database itself.
Conclusion
There are different gradations of the CQRS pattern that you can use in your application. There is nothing wrong with sticking to type 1 and not moving toward types 2 and 3 if type 1 meets your application's performance requirements.
I would like to emphasize this point: CQRS is not a binary choice. There are various variations between not separating the read and write operations at all (type 0) and separating them completely (type 3).
A balance should be struck between the degree of segregation and the complexity that this segregation brings. The balance should be sought in each case separately, often using several iterations. The CQRS pattern should not be applied simply because "we can."
English version of the article: Types of CQRS