Text Recognition in ABBYY FineReader (2/2)
Content
General recognition theory
We finally reached the most interesting topic - character recognition. But for starters, let's look at the theory a bit to make it clearer what exactly and why we are doing. The general task of automatic recognition or machine learning is as follows.
There is a certain set of classes C and the space of objects R. There is a certain external “expert” system with which you can determine for which object it belongs to which class.
The task of automatic recognition is to build a system that, on the basis of a limited selection of pre-classified objects transferred to it, would give out a class corresponding to it for any new object transferred to it. Moreover, the total difference in the classification between the "expert" system and the automatic recognition system should be minimal.
The class system can be discrete or continuous, many objects can be of any structure, an expert system can be arbitrary, starting with ordinary human experts, accuracy can be evaluated only on a certain sample of objects. But basically, almost any task of automatic recognition (from ranking search results to medical diagnostics) comes down to building a link between objects from a given space and a set of classes.

But in such a formulation, the task is virtually meaningless, because it is completely unclear what our objects are and how to work with them at all.
Therefore, the following scheme is usually used: a certain space of signs is constructed in which we can at least determine the distance between objects in some form. The transformation from the space of objects to the space of signs is under construction. The main requirement of the transformation under construction is to try to comply with the "compactness hypothesis": objects that are nearby in the attribute space must have the same or similar classes.
Thus, the original task is divided into the following steps:
- Construct a transformation from the space of objects to the space of signs, taking into account the "compact hypothesis"
- Mark up the feature space based on the available marked-up sample of objects, so that each point corresponds to a set of estimates of whether this point belongs to different classes.
- To make a decisive rule that, based on a set of estimates, would make the final decision to which class the object belongs.
I’ll say just a few words about the third step of the algorithm, because this is one of the rare places in the system where the idea is simple and the implementation is also simple. There are several character recognition systems, each of these systems gives a list of recognition options with some confidence. The task of the decision rule is to merge the lists of recognition options from all systems into one common list and combine the quality of recognition from several systems into one integral quality. Quality is combined using a formula specially selected for our classifiers.
And one more remark about recognition classes - in the article I use the word "symbols", because it is understandable and known to everyone. But this was done only to simplify the text, in fact, we recognize not symbols, but graphemes. A grapheme is a specific way to graphically represent a symbol. The relationship between symbols and graphemes is quite complicated - several graphemes can correspond to one grapheme (small “C” and large “C” in Latin and Cyrillic are all one grapheme), and several graphemes can correspond to one character (letter “a” in different fonts may be different graphemes). There is no standard list of graphemes, we compiled it ourselves and for each grapheme we have given a list of characters to which it can correspond.


An example of two different graphemes of the letter "a".
A couple of facts about our assessment of the quality of work of classifiers:
- We use several classifiers that complement each other. That is, in any case, a normal quality assessment is only an assessment of the integrated list of options obtained after the application of the decision rule.
- At the stage of enumerating word variants, a lot of contextual information is used, which simply does not exist within a single character. Therefore, classifiers are not required to always put the desired recognition option in the first place - instead, it is necessary that the correct option be in the first two or three recognition options.
Recognition system
Our program uses several different classifiers, which mainly differ in the features used, but at the same time have practically the same structure of the recognition system itself.
The requirements that we have for the character recognition system are quite simple:
- The system should work equally on any source set of possible characters. Because we never know in advance which language or combination of languages the user will choose for recognition. Moreover, the user usually has the opportunity to create his own language with a generally arbitrary alphabet.
- Limiting the possible characters for recognition should increase the quality and speed up the work of classifiers. If the user selects a recognition language for his document, he should notice improvements.
In connection with these two requirements, it is not very common for us to use complex and intelligent recognition systems. Often they ask a question about neural networks, so it’s better to write right away - no, we don’t use them for many reasons. The main problem with them is the brutally fixed set of recognizable classes and excessive internal complexity, which extremely complicates the exact adjustment of the classifier. Further discussion of neural networks is a topic for a big holivar, so I’d better talk about what we use.
And we use varieties of the Bayesian classifier. Its idea is as follows:
For a specific point in the space of attributes (x) we need to evaluate the probability of its belonging to different classes (C 1 , C 2 , ..., C n)
If we write formally, then we need to calculate the probability that the class of the object is C i , provided that the object is described in the attribute space by the point x - P (C i | x).
We apply the Bayes formula from the basic course of probability theory:
P (C i | x) = P (C i ) * P (x | C i ) / P (x);
As a result, we compare the probabilities for different classes to determine the answer for the symbol, so we throw the denominator out of the formula, it is common for all classes. We will need to compare the set of values P (C i ) * P (x | C i ) for different classes and choose the largest value from them.
P (C i) Is the a priori probability of the class. It does not depend on the recognized object; it can be calculated in advance. For any set of possible classes (possible alphabets), it can be calculated in advance by the frequency of occurrence of letters in the specified language. And practice shows that sometimes it’s even better to take the same a priori probabilities of all the characters.
P (x | C i ) is the probability for a particular class C iget an object with description x. We can determine this probability in advance at the classifier training stage. Here, completely standard methods from mathematical statistics work - we make an assumption about the distribution form (normal, uniform, ...) for a class in the attribute space, take a large sample of objects of this class, and from this sample determine the necessary parameters for the selected distribution.

A very small fragment of our image database for training classifiers.
What gives us the use of a Bayesian classifier? This system is completely independent of the recognition alphabet. The probability distribution for each class is considered by the sample to be completely independent. It is better not to use a priori probabilities for classes in practice at all. The final grade for each class is the probability, and therefore for any class it is in the same range.
Thus, we get a system that can work without any additional settings both on the image of the binary code from zeros and ones, and on the text from the phrasebook in 4-5 languages. An additional advantage is that probabilistic models are very easy to interpret and you can independently train individual characters if such a need arises.
Feature space
As I said earlier, there are several character classifiers in our system, and the main difference between these classifiers is precisely in the space of attributes.
The space of signs for our classifiers is based on a combination of two ideas:
- It is very simple for the Bayesian classifier to work if the attribute space consists of numerical vectors of fixed length - for numerical vectors it is very easy to consider the mathematical expectation, variance and other characteristics that are necessary to restore the distribution parameters.
- If the basic characteristics are calculated on the image, such as the amount of black in a certain fragment of the image, then each such characteristic individually will not say anything about the image belonging to a particular symbol. But if you collect a lot of such characteristics into one vector, then these vectors in total will already noticeably differ among different classes.
So we have several classifiers constructed as follows: we select a lot (of the order of hundreds) of basic features, collect a vector from them, declare such vectors as our feature space and build a Bayesian classifier on them.
As a simplified example, we divide the image into several vertical and horizontal stripes, and for each strip we consider the ratio of black and white pixels. Moreover, we believe that we have a normal distribution of the resulting vectors. For a normal distribution, we need to calculate the mathematical expectation and variance to find out the distribution parameters. To do this on vectors, with a fairly large selection of elementary. Thus, we obtain a classifier from very simple features and using simple mathematics, which in practice has a fairly high quality.
This was a simplified example, and what exactly signs and in which particular combinations are actually used are just the result of accumulated experience and long studies, so I will not give a detailed description of them here.
Raster classifier
Separately, you need to write about the raster classifier. The simplest feature space that you can think of for character recognition is the image itself. We select a certain (small) size, we bring any image to this size and actually get a vector of values of a fixed length. Everyone knows how to add and average vectors, so that we get a completely normal space of signs.
This is the most basic classifier - raster. We reduce all images of one grapheme from the training base to the same size, and then average them. The result is a gray image where the color of each dot corresponds to the probability that this dot should be white or black for a given symbol. The raster classifier, if desired, can be interpreted as Bayesian and consider some probability that this image appeared with this standard for the symbol. But for this classifier, this approach only complicates everything, so we use the usual distance between the black-and-white image and the gray standard to assess whether the image belongs to a given class.
The advantage of the raster classifier is its simplicity and speed. And the minus is low accuracy, mainly due to the fact that when we reduce to the same size, we lose all information about the geometry of the symbols - say, the dot and the letter “I” in this classifier are reduced to the same black square. As a result, this classifier is an ideal mechanism for generating an initial list of recognition options, which can then be refined using more complex classifiers.
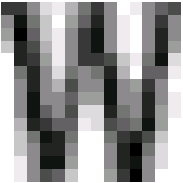


A few examples of raster standards for a single letter.
Structural classifier
In addition to printed text, our system can also recognize handwritten text. And the problem with the handwritten text is that its variability is very large, even if a person tries to write in block letters.
Therefore, for handwritten text, all standard classifiers cannot provide sufficient quality. So for this task in our system there is one more step - a structural classifier.
His idea is as follows - each symbol actually has a clearly defined structure. But if we just try to highlight this structure in the image, nothing will work out, the variability is very large and we still need to somehow compare the found structure with the structure of each possible symbol. But we have basic classifiers - they are inaccurate, but in 99.9% of cases the correct recognition option will still be on the list of, say, the top 10 options.
So let's go from the back end:
- For each symbol, we describe its structure through the basic elements - a line, an arc, a ring, ... The description will have to be done manually, this is a big problem, but so far no one has been able to come up with an automatic selection of the topology with acceptable quality for us.
- For a structural description of the symbol, we will separately describe how to search for it in the image — from which elements to start and in what order to go.
- When recognizing a character, we get a small list of possible recognition options using basic classifiers.
- For each recognition option, we try to find a structural description corresponding to it in the image.
- If the description came up, we evaluate its quality. It didn’t fit - that means the recognition option does not fit at all.
Since in this approach we test specific hypotheses, we always know exactly what exactly and in what order to look for in the image - so the algorithm for selecting the structure is greatly simplified.

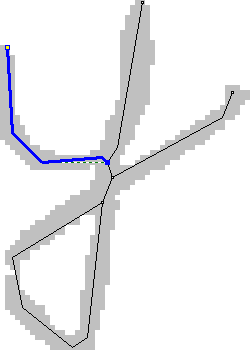


An example of selected structural elements in a symbol image
Differential classifier
As an add-on for a set of classifiers, we still have a differential classifier. The reason for its appearance in the following is that there are pairs of characters that are very similar to each other, with the exception of some small very specific features. Moreover, for each pair of characters, these features are different. If you try to embed knowledge about these features in a common classifier, then the general classifier will be overloaded with signs, each of which will not bring benefits in the vast majority of cases. On the other hand, after the work of ordinary classifiers, we already have a list of recognition hypotheses, and we know exactly which options we need to compare with each other.
Therefore, for similar pairs of characters we find special features that distinguish precisely these two classes and construct a classifier based on these features only for these two classes. If we have two similar variants with close estimates in recognition options, such a classifier can tell you exactly which of these two options is preferable.
In our system, differential classifiers are used after all the main classifiers work to further sort the list of character recognition options. To determine similar pairs of characters, an automatic system is used that looks at which characters are confused with which ones most often when using only basic classifiers. Then, for each suspicious pair, additional features are manually selected and a differential classifier is trained.
Practice shows that for ordinary languages there are not very many pairs of close characters. Moreover, the addition of each new differential classifier greatly improves recognition.
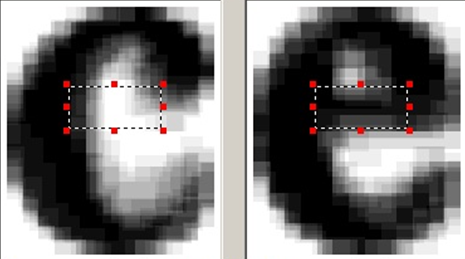
An example area for highlighting additional features for a pair of similar characters.
In conclusion
This article in no way claims to be an accurate description of the mechanisms that are used internally by FineReader and our other products for recognition. This description is only the basic principles that were used to create the technology. The real system is too large and complex to be described in two or three articles on Habré. If you are really interested in how everything is really arranged there, it’s better to