AI, practical course. Deep learning to generate music
- Transfer

This is the last article in a series of training articles for developers in the field of artificial intelligence. It discusses the steps to create a deep learning model for generating music, choosing the right model and data preprocessing, and describes the procedures for setting, training, testing and modifying BachBot.
Music Generation - Thinking About a Task
The first step in solving many problems using artificial intelligence (AI) is to reduce the problem to a basic problem that can be solved by means of AI. One such problem is sequence prediction, which is used in natural language translation and processing applications. Our task of generating music can be reduced to the problem of predicting a sequence, and the prediction will be performed for a sequence of musical notes.
Model selection
There are several different types of neural networks that can be considered as models: direct distribution neural networks, recurrent neural networks and long-term memory neural networks.
Neurons are the basic abstract elements that combine to form neural networks. Essentially, a neuron is a function that receives data at the input and outputs the result.
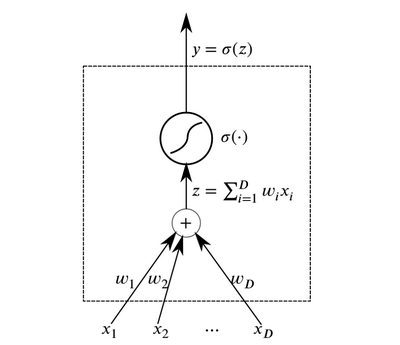
Neuron
Layers of neurons that receive the same data at the input and have connected outputs can be combined to build a neural network with direct propagation . Such neural networks demonstrate high results due to the composition of nonlinear activation functions when passing data through several layers (the so-called deep learning).
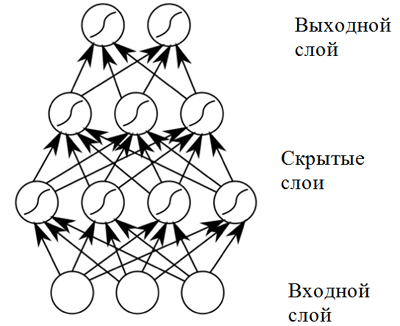
Direct Distribution Neural Network A direct distribution
neural network shows good results in a wide range of applications. However, such a neural network has one drawback that does not allow its use in a task related to musical composition (sequence prediction): it has a fixed dimension of input data, and musical works can have different lengths. In addition, direct distribution neural networks do not take into account input from previous time steps, which makes them not very useful for solving the sequence prediction problem! A model called a recurrent neural network is better suited for this task .
Recursive neural networks solve both of these problems by introducing links between hidden nodes: in this case, at the next time step, nodes can receive information about the data at the previous time step.
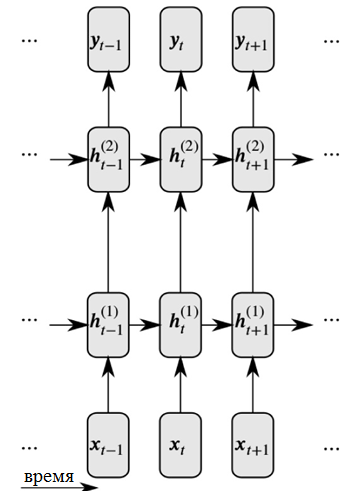
Detailed view of a recurrent neural network
As can be seen in the figure, each neuron now receives input from both the previous neural layer and the previous time.
Recursive neural networks dealing with large input sequences face the so-called vanishing gradient problem: this means that the influence of earlier time steps is quickly disappearing. This problem is characteristic of the task of musical composition, since there are important long-term dependencies in musical works that must be taken into account.
To solve the problem of a vanishing gradient, a modification of the recurrent network, which is called a neural network with long short-term memory (or LSTM neural network), can be used . This problem is solved by introducing memory cells, which are carefully monitored by three types of “gates”. Click the following link for more information: General information about LSTM neural networks .
Thus, BachBot uses a model based on the LSTM neural network.
Preliminary processing
Music is a very complex art form and includes various dimensions: pitch, rhythm, tempo, dynamic shades, articulation and more. To simplify the music for the purposes of this project , only the pitch and duration of the sounds are considered . Moreover, all chorales were transposed to the key in C major or A minor, and the note durations were quantized in time (rounded) to the nearest multiple of the sixteenth note. These actions were taken to reduce the complexity of the compositions and increase network performance, while the basic content of the music remained unchanged. Operations to normalize the tonalities and durations of notes were performed using the music21 library.
def standardize_key(score):
"""Converts into the key of C major or A minor.
Adapted from https://gist.github.com/aldous-rey/68c6c43450517aa47474
"""
# conversion tables: e.g. Ab -> C is up 4 semitones, D -> A is down 5 semitones
majors = dict([("A-", 4),("A", 3),("B-", 2),("B", 1),("C", 0),("C#",-1), ("D-", -1),("D", -2),("E-", -3),("E", -4),("F", -5),("F#",6), ("G-", 6), ("G", 5)])
minors = dict([("A-", 1),("A", 0),("B-", -1),("B", -2),("C", -3),("C#",-4), ("D-", -4),("D", -5),("E-", 6),("E", 5),("F", 4),("F#",3), ("G-",3),("G", 2)])
# transpose score
key = score.analyze('key')
if key.mode == "major":
halfSteps = majors[key.tonic.name]
elif key.mode == "minor":
halfSteps = minors[key.tonic.name]
tScore = score.transpose(halfSteps)
# transpose key signature
for ks in tScore.flat.getKeySignatures():
ks.transpose(halfSteps, inPlace=True)
return tScore
The code used to standardize key characters in the collected works, the output uses tonality in C major (A major) or A minor (A minor).
Time quantization to the nearest multiple of the sixteenth note was performed using the Stream.quantize () function of the library music21. The following is a comparison of statistics associated with a dataset before and after its preprocessing:
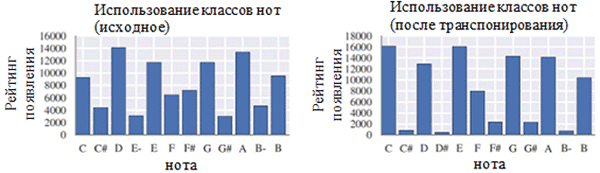
Using each class of notes before (left) and after preprocessing (right). The note class is a note, regardless of its octave.
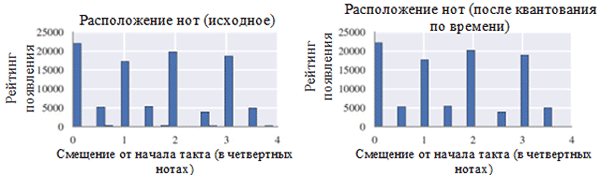
Location of notes before (left) and after preprocessing (right)
As can be seen in the figure above, the transposition of the original key of the chorales to the key of C major or C minor (A minor) significantly influenced the class of notes used in the collected works. In particular, the number of occurrences for notes in keys in major keys (C major) and A minor (A minor) (C, D, E, F, G, A, B) increased. You can also observe small peaks for notes F # and G # due to their presence in the ascending sequence of the melodic A minor (A, B, C, D, E, F # and G #). On the other hand, time quantization had a much smaller effect. This can be explained by the high resolution of quantization (similar to rounding to many significant digits).
Coding
After the data has been pre-processed, it is necessary to encode the chorales into a format that can be easily processed using a recurrent neural network. The required format is a sequence of tokens . For the BachBot project, coding was chosen at the level of notes (each token represents a note) instead of the level of chords (each token represents a chord). This solution reduced the size of the dictionary from 128 4 possible chords to 128 possible notes, which allowed to increase work efficiency.
An original coding scheme for musical compositions was created for the BachBot project. The chorale is divided into time steps corresponding to sixteenth notes. These steps are called frames. Each frame contains a sequence of tuples representing the value of the pitch of a note in the format of a digital musical instrument interface (MIDI) and a sign of binding of this note to a previous note of the same height (note, sign of binding). The notes within the frame are numbered in descending order of height (soprano → alt → tenor → bass). Each frame may also have a frame that marks the end of a phrase; Fermata is represented by a dot (.) symbol above the note. Symbols START and ENDadded to the beginning and end of each chorale. These symbols cause initialization of the model and allow the user to determine when the composition ends. An example of encoding two chords. Each chord lasts an eighth beat of a measure, the second chord is accompanied by a farm. The sequence "|||" indicates the end of the frame.
START
(59, True)
(56, True)
(52, True)
(47, True)
|||
(59, True)
(56, True)
(52, True)
(47, True)
|||
(.)
(57, False)
(52, False)
(48, False)
(45, False)
|||
(.)
(57, True)
(52, True)
(48, True)
(45, True)
|||
ENDdef encode_score(score, keep_fermatas=True, parts_to_mask=[]):
"""
Encodes a music21 score into a List of chords, where each chord is represented with
a (Fermata :: Bool, List[(Note :: Integer, Tie :: Bool)]).
If `keep_fermatas` is True, all `has_fermata`s will be False.
All tokens from parts in `parts_to_mask` will have output tokens `BLANK_MASK_TXT`.
Time is discretized such that each crotchet occupies `FRAMES_PER_CROTCHET` frames.
"""
encoded_score = []
for chord in (score
.quantize((FRAMES_PER_CROTCHET,))
.chordify(addPartIdAsGroup=bool(parts_to_mask))
.flat
.notesAndRests): # aggregate parts, remove markup
# expand chord/rest s.t. constant timestep between frames
if chord.isRest:
encoded_score.extend((int(chord.quarterLength * FRAMES_PER_CROTCHET)) * [[]])
else:
has_fermata = (keep_fermatas) and any(map(lambda e: e.isClassOrSubclass(('Fermata',)), chord.expressions))
encoded_chord = []
# TODO: sorts Soprano, Bass, Alto, Tenor without breaking ties
# c = chord.sortAscending()
# sorted_notes = [c[-1], c[0]] + c[1:-1]
# for note in sorted_notes:
for note in chord:
if parts_to_mask and note.pitch.groups[0] in parts_to_mask:
encoded_chord.append(BLANK_MASK_TXT)
else:
has_tie = note.tie is not None and note.tie.type != 'start'
encoded_chord.append((note.pitch.midi, has_tie))
encoded_score.append((has_fermata, encoded_chord))
# repeat pitches to expand chord into multiple frames
# all repeated frames when expanding a chord should be tied
encoded_score.extend((int(chord.quarterLength * FRAMES_PER_CROTCHET) - 1) * [
(has_fermata,
map(lambda note: BLANK_MASK_TXT if note == BLANK_MASK_TXT else (note[0], True), encoded_chord))
])
return encoded_scoreCode used to encode the music21 tonality using a special encoding scheme
Model task
In the previous part, an explanation was given showing that the task of automatic composition can be reduced to the task of predicting a sequence. In particular, a model can predict the most likely next note based on previous notes. To solve this type of problem, a neural network with long short-term memory (LSTM) is best suited. Formally, the model should predict P (x t + 1 | x t , h t-1 ), the probability distribution for the next possible notes (x t + 1 ) based on the current token (x t ) and the previous hidden state (h t-1 ) . Interestingly, the same operation is performed by language models based on recurrent neural networks.
In composition mode, the model is initialized with the START token , after which it selects the next most probable token to follow. After that, the model continues to select the next most probable token using the previous note and previous hidden state until an END token is generated. The system contains temperature elements that add some degree of randomness to prevent BachBot from composing the same piece again and again.
Loss function
When training a model for prediction, there is usually some function that needs to be minimized (called the loss function). This function describes the difference between model prediction and the ground truth property. BachBot minimizes the loss of cross-entropy between the predicted distribution (x t + 1 ) and the actual distribution of the objective function. Using cross entropy as a loss function is a good starting point for a wide range of tasks, but in some cases you can use your own loss function. Another acceptable approach is to try to use various loss functions and apply a model that minimizes actual loss during verification.
Training / testing
In training a recursive neural network, BachBot used token correction with the value x t + 1 instead of applying model prediction. This process, known as compulsory learning, is used to ensure convergence, since model predictions will naturally produce poor results at the start of training. In contrast, during validation and composition, the prediction of the model x t + 1 should be reused as input to the next prediction.
Other considerations
To increase the efficiency in this model, the following practical methods were used that are common to LSTM neural networks: normalized gradient truncation, elimination method, packet normalization, and truncated time error back propagation (BPTT) method.
The normalized gradient truncation method eliminates the problem of uncontrolled growth of the gradient value (the inverse of the vanishing gradient problem, which was solved using the architecture of LSTM memory cells). Using this technique, gradient values that exceed a certain threshold are truncated or scaled.
The exclusion method is a technique in which some neurons randomly selectedare disconnected (excluded) during network training. This avoids overfitting and improves the quality of generalization. The problem of overfitting arises when the model becomes optimized for the training data set and less applicable for samples outside this set. The exclusion method often worsens the loss during training, but improves it at the verification stage (more on this below).
The calculation of the gradient in a recurrent neural network for a sequence of 1000 elements is equivalent in cost to the forward and backward passes in the neural network of direct propagation of 1000 layers. Truncated Error Propagation Method(BPTT) over time is used to reduce the cost of updating parameters during training. This means that errors are propagated only during a fixed number of time steps counted back from the current moment. Please note that long-term learning dependencies are still possible with the BPTT method, since latent states have already been revealed at many previous time steps.
Parameters
The following is a list of relevant parameters for models of recurrent neural networks / neural networks with long short-term memory:
- The number of layers . Increasing this parameter may increase the efficiency of the model, but it will take longer to train it. In addition, too many layers can lead to overfitting.
- The dimension of the latent state . Increasing this parameter may increase the complexity of the model, however, this can lead to overfitting.
- Dimension of vector comparisons
- The sequence length / number of frames before truncating the back propagation of the error over time.
- Probability of exclusion of neurons . The probability with which a neuron will be excluded from the network during each update cycle.
The methodology for selecting the optimal set of parameters will be discussed later in this article.
Implementation, training and testing
Platform selection
Currently, there are many platforms that allow you to implement machine learning models in various programming languages (including even JavaScript!). Popular platforms include scikit-learn , TensorFlow, and Torch .
The Torch library was selected as the platform for the BachBot project. At first, the TensorFlow library was tried, but at that time it used extensive recurrent neural networks, which led to an overflow of the RAM of the GPU. Torch is a scientific computing platform powered by the fast programming language LuaJIT *. The Torch platform contains excellent libraries for working with neural networks and optimization.
Model implementation and training
The implementation, obviously, will vary depending on the language and platform on which you choose. To learn how BachBot implements neural networks with long, short-term memory using Torch, check out the scripts used to train and set BachBot parameters. These scripts are available on the Feynman Lyang GitHub website . The 1-train.zsh
script is a good starting point for navigating the repository . With it, you can find the path to the bachbot.py file . More precisely, the main script for setting model parameters is the LSTM.lua file . The script for training the model is the train.lua file .
Hyperparameter Optimization
To search for the optimal values of the hyperparameters, the grid search method was used using the following parameter grid.
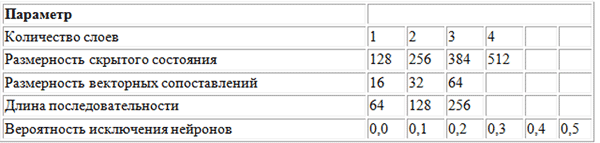
The grid of parameters used by BachBot when searching the grid. The grid
search is a complete search of all possible combinations of parameters. Other suggested methods for optimizing hyperparameters are random search and Bayesian optimization.
The optimal set of hyperparameters detected as a result of a grid search is as follows: number of layers = 3, dimension of the hidden state = 256, dimension of vector comparisons = 32, sequence length = 128, probability of elimination of neurons = 0.3.
This model reached a cross-entropy loss of 0.324 during training and 0.477 at the verification stage. The learning curve graph demonstrates that the learning process converges after 30 iterations (≈28.5 minutes when using a single GPU).
Loss graphs during training and during the verification phase can also illustrate the effect of each hyperparameter. Of particular interest to us is the probability of excluding neurons:
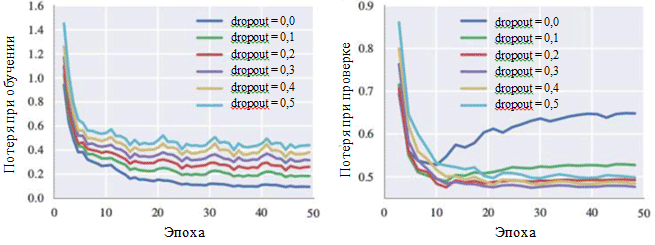
Learning curves for various settings of the exclusion method
It can be seen in the figure that the elimination method really avoids the occurrence of overfitting. Although with a probability of exclusion of 0.0, the loss during training is minimal, at the verification stage, the loss has a maximum value. Large values of probability lead to an increase in losses during training and a decrease in losses at the verification stage. The minimum value of the loss during the verification phase when working with BachBot was fixed with an exception probability of 0.3.
Alternative assessment methods (optional)
For some models — especially for creative applications such as composing music — loss may not be an appropriate measure of the success of the system. Instead, subjective human perception may be the best criterion.
The aim of the BachBot project is to automatically compose music that is indistinguishable from Bach’s own compositions. To assess the success of the results, a survey of users on the Internet was conducted. The survey was given the form of a competition in which users were asked to determine which works belong to the BachBot project, and which to Bach.
The survey results showed that the survey participants (759 people with different levels of training) were able to accurately distinguish between two samples in only 59 percent of cases. This is only 9 percent higher than the result of random guessing! Try the BachBot survey yourself!
Adapting the model to harmonization
Now BachBot can calculate P (x t + 1 | x t , h t-1 ), the probability distribution for the next possible notes based on the current note and previous hidden state. This sequential prediction model can subsequently be adapted to harmonize the melody. Such an adapted model is required to harmonize the melody, modulated with the help of emotions, as part of a musical project with a slide display.
When working with model harmonization, a predefined melody is provided (usually this is a soprano part), and after that the model should compose music for the rest of the pieces. To accomplish this task, a greedy “best-first” search is used with the restriction that the melody notes are fixed. Greedy algorithms involve decisions that are optimal from a local point of view. So, below is a simple strategy used for harmonization:
Assume that x t are tokens in the proposed harmonization. At time step t, if the note corresponds to the melody, then x t is equal to the given note. Otherwise, x t is equal to the most probable next note in accordance with the predictions of the model. The code for this model adaptation can be found on the Feynman Lyang GitHub website: HarmModel.lua , harmonize.lua .
The following is an example of harmonizing the lullaby Twinkle, Twinkle, Little Star with BachBot, using the above strategy.

Harmonization of the lullaby of Twinkle, Twinkle, Little Star with BachBot (in the soprano part). Viola, tenor and bass parts were also filled with BachBot.
In this example, the melody of the lullaby Twinkle, Twinkle, Little Star is given in the soprano part. After that, the parts of viola, tenor and bass were filled using BachBot using a harmonization strategy. And here is how it sounds .
Despite the fact that BachBot has shown good performance in performing this task, there are certain limitations associated with this model. More precisely, the algorithm does not look aheadinto a melody and uses only the current note of the melody and past context to generate subsequent notes. When harmonizing a melody by people, they can cover the whole melody, which simplifies the derivation of suitable harmonizations. The fact that this model is not capable of doing this can lead to surprises due to restrictions on the use of subsequent information that cause errors. To solve this problem, the so-called beam search can be used .
When using beam search, various motion lines are checked. For example, instead of using only one, the most probable note, which is currently being done, four or five most probable notes can be considered, after which the algorithm continues its work with each of these notes. Examining the various options can help the model recover from errors . Beam searching is commonly used in natural language processing applications to create sentences.
Melodies modulated with the help of emotions can now be passed through such a harmonization model to complete them.