Modern aspects of the presentation of texts in the analysis of natural language: classic and alternative approaches
Introduction
In computer science, the topic of natural language processing is becoming more and more popular year after year. Due to the huge number of tasks where such an analysis is required, it is difficult to overestimate the need for automatic processing of text documents.
In this article we will simply try to describe the most popular modern approaches to the presentation of text documents for computer processing. And on one of them, which has not yet received wide distribution, but it has every chance, we will dwell in more detail, since we use this method in SlickJump when developing algorithms, for example, contextual advertising targeting .
Note that the approaches cited are applicable not only to texts, but generally to any objects that can be represented as symbolic sequences, for example, some macromolecules (DNA, RNA, proteins) from genetics. In total, we will consider 4 methods:
- Characteristic description.
- Pairwise overlay (alignment) of texts.
- The formation of a profile and a hidden Markov model.
- Presentation by fragments.
So let's get started.
Feature Description
A characteristic description is an approach that can be called classical in the analysis of natural language. It implies that a certain number of features, for example, words, or pairs of consecutive words (the so-called bigrams) are distinguished from the analyzed text documents. Signs can be filtered, for example, by the frequency of occurrence in a set of documents, or you can remove from their list those that are not of interest - for example, prepositions or conjunctions ("stop words"). Further, each document is characterized by the number of occurrences of these attributes in it, or, for example, by their presence / absence, which is convenient to represent as a vector, where each element corresponds to a particular attribute. Their order, of course, should be fixed in advance. Note that an important task is to identify the same signs in different forms - for example, it is convenient to consider that Katya and Katya are one and the same sign. For this, the processes of stemming are used, in which only the basics of words are considered (most often, the roots, and prefixes, suffixes, endings are discarded) or lemmatization, when all words are reduced to "normal form", for example, in Russian, nouns are convenient to lead to the nominative case in the singular. The second process is almost always more complicated, often you need to have a base of word forms (without them, for example, for the word "people" you can’t get the normal form "man"), while for the first process for many languages a list of rules for converting words is sufficient. endings are discarded) or lemmatization, when all words are reduced to “normal form”, for example, in Russian, nouns are convenient to lead to the form of the nominative case in the singular. The second process is almost always more complicated, often you need to have a base of word forms (without them, for example, for the word "people" you can’t get the normal form "man"), while for the first process for many languages a list of rules for converting words is sufficient. endings are discarded) or lemmatization, when all words are reduced to “normal form”, for example, in Russian, nouns are convenient to lead to the form of the nominative case in the singular. The second process is almost always more complicated, often you need to have a base of word forms (without them, for example, for the word "people" you can’t get the normal form "man"), while for the first process for many languages a list of rules for converting words is sufficient.
For example, let us be given a text taken from N. Gumilyov’s beautiful poem “Giraffe”:
Listen: far, far, on the lake Chad theWe single out the signs from here (we will use only individual words), lemmatize them, and get the following set:
Exquisite giraffe wanders.
(listen, far, lake, Chad, exquisite, wander, giraffe)
We do not take the preposition “on” as a stop word. If we now present the first line of the given text in vector form based on the above list, we get the following vector:
(1, 2, 1, 1, 0, 0, 0)
The resulting vectors can be combined into a matrix, measure different distances (of which there is a great many) between them, apply frequency conversion techniques to them (TF-IDF, for example - but in this case, for its adequate operation, the number of signs and documents should be sufficient).
Overlaying sequences, forming profiles
Some tasks use an approach consisting in pairwise overlapping (alignment) of character sequences. The essence of this method is to maximize the number of positions in which matching sequence symbols are located, while the sequences themselves can be “broken”. This approach is actively used in bioinformatics problems, where macromolecules, for example, DNA, play the role of symbol sequences, and usually such that some of them are the results of changes in others, for example, historical modifications. It is often assumed that all compared sequences have a common ancestor. For this approach, several proximity measures have been developed that generate distance matrices, with which further work is ongoing.
In addition, there is a method involving the formation of a profile and a hidden Markov model for text documents. This approach is again based on overlapping sequences, but not pairwise, but multiple. Positions in which all sequences participate are highlighted separately. The hidden Markov model is a development of this approach, suggesting that sequences are generated by transitions between its states. At each transition with certain probabilities its symbols are formed. This method is not widespread, therefore we will dwell on such a brief description of it.
Fragment view
And finally, the last approach, which we will focus on, is a fragmentary description of the texts. This approach uses the so-called annotated suffix trees. Annotated suffix tree (ASD) is a data structure used to calculate and store all text fragments together with their frequencies. It is defined as the root tree (that is, one vertex in it is highlighted and called the root), in which each node corresponds to one character and is marked by the frequency of that piece of text that encodes the path from the root to this node.
When using the ASD, all text is divided into lines - chains of characters. As a rule, one line is formed of 2-4 consecutive words. An example of an ASD for a short line is
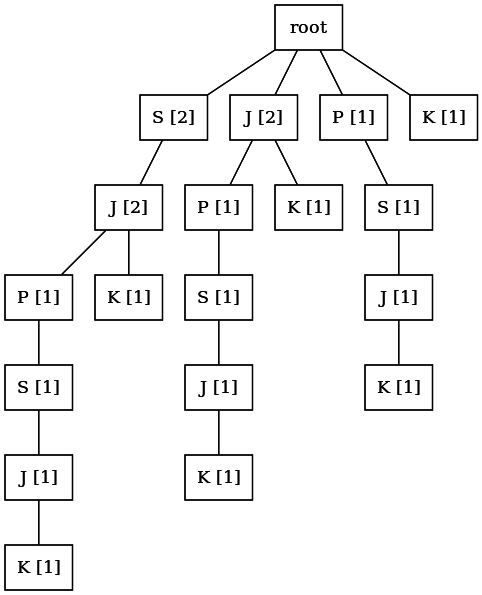
Suffix for
- Initialize an empty structure for storing the ADA -
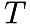 . This structure should be able to store a tree with symbols and numbers (their frequency) in nodes.
. This structure should be able to store a tree with symbols and numbers (their frequency) in nodes. - Find all suffixes lines:
 .
. - For each suffix,
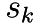 we look in such a way from the root that the coincidence with the beginning of the suffix is maximum in length -
we look in such a way from the root that the coincidence with the beginning of the suffix is maximum in length - 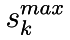 . For all characters that match , we increase the frequency of the corresponding nodes by 1.
. For all characters that match , we increase the frequency of the corresponding nodes by 1. - If the match in length is less
 , then the suffix is not passed to the end. Then it is necessary to create new nodes by assigning them a frequency of 1.
, then the suffix is not passed to the end. Then it is necessary to create new nodes by assigning them a frequency of 1.
When constructing an ASD for two or more lines, the suffixes of all lines are sequentially superimposed on a common tree. Thus, presenting the document in the form of multiple lines, you can build for him the corresponding ASD.
ASD, built for a document, allows you to successfully solve such a problem as finding the proximity of a line and a document. This task is called the task of determining the degree of occurrence of a substring in a tree. We present its solution (proposed and described in detail in [3]).
We introduce the concept of conditional probability of a node
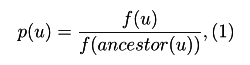
where
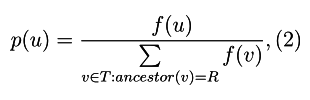
where the set
For each suffix of the

Then the assessment of the degree of occurrence of a string in a tree is defined as:
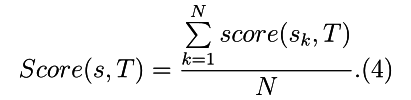
When comparing the degrees of occurrence of a string in two or more ASDs, the formula
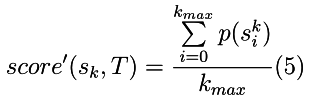
If you practice and calculate, according to this formula, the degree of occurrence in the ADS of some lines in the tree shown in the figure above, then we will get the following plate:
| Line | Degree of occurrence of a string in a tree |
|---|---|
| JAVASCRIPT | 0.083 |
| Jeep | 0.125 |
| SLICKJUMP | 0.111 |
| Jk | 0.291 |
| Juke | 0.125 |
Benefits of Fragmentation
We note the advantages of this approach compared to the characteristic method. Characteristic approaches feel much worse the deep “structure” of the text, even when using bigrams as signs (or even longer sequences of words - trigrams, etc., which, by the way, greatly increases the dimension of vectors). In addition, the fragmentary approach does not require the reduction of words to normal forms (if, of course, it uses only the transformation rules, and not the wordform base) - if the word is included in the ASD, then its base, obviously, will be located on some some branches. But the most important thing is that the fragmented approach is tolerant of minor errors in the texts. Of course, there are special methods that allow us to teach this and attribute approaches, but this often complicates the algorithms.
The technology of contextual targeting of goods of affiliate stores in SlickJump is based on the probabilistic thematic model LDA (hidden placement of Dirichlet), which works with signs. In general, probabilistic thematic modeling is a separate, vast and interesting topic, and if we will get into it, then not in this article. We only note that this approach allows us to solve the problem of finding the degrees of proximity of documents (i.e. the context and the goods offered), and to solve it for a huge number of documents - and there are more than 2 million goods of partner stores in our company bases.
But for the contextual targeting of banners, the number of which is incomparably smaller than the number of products in partner online stores, we use a specially developed model based on the ASD method. This allows you to give good quality contextual targeting even where people write like chicken paw - for example, on forums. Consider an example.
Suppose we have electronics store banners offering fashion accessories for smartphones at discounted prices. And a forum about mobile technology as an advertising platform. The advertiser indicates a list of keywords for their banners or provides it to us (which is convenient when the number of banners is in the thousands, we have the corresponding functionality). We need to select banners that are relevant to the context (usually a web page, forum post, etc.). Let’s compare two contextual targeting models: LDA (based on attributes) and our model based on ASD, and find out if relevant banners will be found in two different situations: when people write correctly and when they make mistakes.
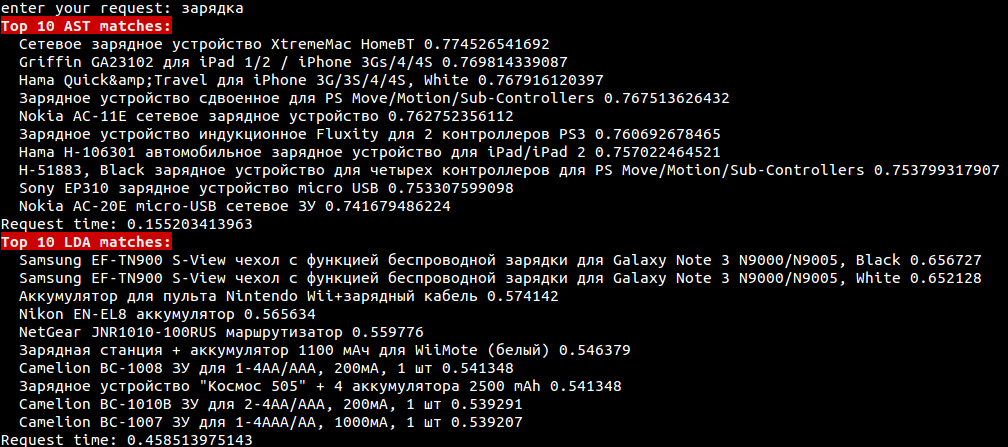
If all people wrote without errors, no problems with contextual targeting would ever have arisen. If there is a keyword “charger”, and somewhere in the message text it says “charging”, then there will be no problems with targeting due to the process of normalizing signs. The screenshot below shows that both models found relevant banners.
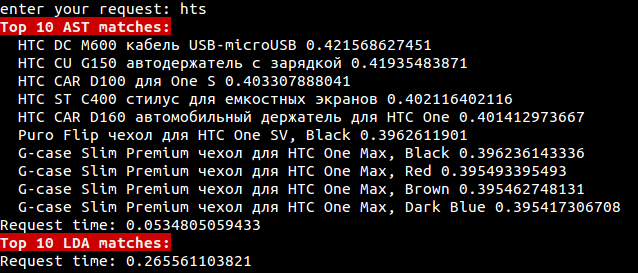
But if a person wrote hts instead of htc (although a primitive example, but a classic of the genre), everything is much more interesting. Let’s try to find banners relevant to this word. The LDA model, based on a feature-based approach without special devices, will not find anything (or anything adequate, which is also bad). And the method based on the ASD gives an excellent result, even though there is a whole mistake in the word for only three letters. This is demonstrated in the screenshot below, which shows the corresponding names of products found on request.
Conclusion
Of course, an approach using ASD will not solve the problems of synonymy and homonymy that are extremely complex for a natural language, so it is not a panacea for everything. In addition, the degree of occurrence of a row in a tree, necessary for calculating relevance, is calculated in a time dependent on the length of this row — the longer the row, the longer the time. And with a primitive approach, such a check must be done in the ADA for all documents. But in SlickJump, we use special higher-order data structures that allow us to determine the list of candidates for documents that are relevant among all and check the degree of their inclusion only without loss of quality, and not to search where there is obviously nothing. We are actively working in this direction, there is much more that can be improved.
We have no doubt that the fragment method for presenting texts in the coming years will actively develop, and will develop in many directions. And in the next articles we will review modern algorithms for constructing and representing annotated suffix trees.
References for reading on the topic
- Manning K. D., Raghavan P., Schütze H. Introduction to the Information Search. M .: Williams, 2011
- Mirkin, B. G. Cluster analysis methods for decision support: a review. M .: Publishing House of the National Research University Higher School of Economics, 2011
- Mirkin B.G., Chernyak E.L., Chugunova O.N. Annotated suffix tree method for assessing the degree of occurrence of lines in text documents. Business Informatics. 2012.Vol. 3. No. 21. P. 31-41.
- Dubov M.S., Chernyak E.L. Annotated suffix trees: implementation features. In: Reports of the All-Russian Scientific Conference AIST-2013 / Otv. Ed .: E. L. Chernyak; scientific Ed .: D.I. Ignatov, M. Yu. Khachai, O. Barinova. M .: National Open University "INTUIT", 2013. S. 49-57.
- Mirkin BG, Core Concepts of Data Analysis. Springer, 2012
- Korshunov A, Gomzin A. Thematic modeling of texts in natural language. Proceedings of ISP RAS. 2012. no. S.215-244.
- Steven Bird, Ewan Klein, Edward Loper. Natural Language Processing with Python. OReilly Media, 2009