How to win a rock-paper-scissors game? (implementation of the optimal strategy in Wolfram Mathematica)
- Transfer

Translation post by John Mcloone (Director of International Business and Strategic Development, Wolfram Research). Original post: How to Win at Rock-Paper-Scissors
Download the post as a Mathematica document
From a mathematical point of view, the game paper-scissors-paper (see Appendix 1 at the end) is not particularly interesting. The Nash equilibrium strategy is very simple: randomly and with equal probability choose from three options, and if you have a large number of games, neither you nor your opponent can win. Although, when calculating the strategy using a computer, it is still possible to beat a person after a large number of games.
My nine-year-old daughter showed me a program created by her using Scratch, which won absolutely every time just by tracking what choices you made before making your own! But I will introduce you to a simple solution that wins a person in stone-paper-scissors without cheating.

Since it is impossible to win the one who always makes a completely random choice, we will count on the fact that people are not very random. If the computer can notice a pattern by which you act in your attempts to be random, it will be one step closer to predicting your future actions.
I was thinking of creating an algorithm as one of the topics of our statistics course as part of the Computer-Based Math concept.. But the very first article that I came across in search of predictive algorithms examined the solution using a complex construction based on copula distributions. This decision was difficult for the student to understand (and possibly for me), so I decided to develop a simpler solution that I could explain in simple words. And even if it has already been developed earlier, it’s much more fun to create things in your own way than to find their finished implementation.
To get started, we just need to be able to start the game. At that time, a demonstration had already been developed and made available that allowed you to play rock-paper-scissors, but that was not quite what I needed, so I wrote my version. This item does not require any special explanation:
In [1]: =

Out [1] =

For the most part, this code describes the user interface and game rules. The whole strategy of the computer player is contained in this function:
In [2]: =
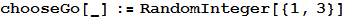
where 1 corresponds to the stone, 2 to paper and 3 to scissors. This is the best solution. No matter how you play, you will win as many games as the computer, and your winning rate will fluctuate around zero.
So, now it would be interesting to rewrite the chooseGo function to make a prediction regarding your choice, using data about the latest games stored in the history variable. The first step is to analyze the choices made during the last few games and search for all cases of occurrence of any sequence. Watching what a person did in each next game, we can find a certain pattern of behavior.
In [3]: =

The first argument to the function is the history of past games. For example, in the dataset presented below, the computer (the second column is the second element of each sublist) just played paper (it corresponds to number 2) against a stone played by a person (number 1). This can be seen in the last element of the list. It is also evident that such a situation has already arisen twice, and both times the next move of the person was again a stone.
In [4]: =
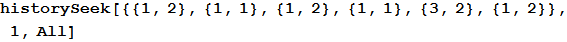
Out [4] =
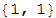
The second argument is the number of the last elements of the story that will be searched. In this case, the number 1 was passed as an argument to the function, which searches the data only for occurrences of {1,2}. If we choose 2, then the function will look for occurrences of the sequence {3,2}, {1,2} and will return an empty list, since such a sequence has not been encountered before.
Third argument, All, indicates that in the desired sequences both the human moves and the computer moves must match. The argument can be changed to 1 to look only at the history of the person’s moves (that is, assuming that the human choice depends only on his previous moves), or 2 to pay attention only to the second column, that is, the history of the computer’s moves (i.e. assuming that the person is responding to previous moves of the computer regardless of which moves he made and, therefore, regardless of whether he won or lost).
For example, in this case, we find that a person chose after a stone, regardless of the fact that he chose a computer in the same games.
In [5]: =
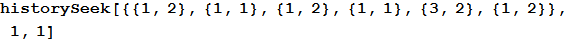
Out [5] =

Having a large amount of data, we can do only with the All argument, and the program will be able to decide for itself whose moves, computer or person, are more important. For example, if the history of computer moves is ignored by a person during the selection process, then the data set obtained for any history of computer moves will have the same distribution as for any other history of computer moves, provided that there is enough data about previous games. By searching all pairs of games, we get the same result as if we first selected data on the history of computer moves, and then used this subset for the function shown above. The same thing will happen if only the history of computer moves matters. But at the same time, by searching separately for both of these assumptions, one can get more faithful coincidences in history, and this is most manifested in cases
Thus, from these two checks, we can find that the first gives a 100% rating, that the next choice is a stone, and the second shows that a person will choose a stone with 75% probability and scissors with a 25% probability.
And here I am somewhat stalled in solving the problem.
In this case, the two predictions are at least more or less similar in result, although they differ in numerical values of the probabilities. But if you search in three “slices” of data with a number of different lengths of history, and the results of the predictions are contradictory - how to combine them?
I put a note about this problem in the “Write about this blog” folder and forgot about it until a few weeks ago there was a debate about how to illuminate the concept of " statistical significance"in Computer-Based Math.
I realized that the question is not how to combine the predictions received, but how to determine which of the predictions is the most significant. One of the predictions could be more significant than the others, because it reflects a more pronounced trend or maybe based on a larger dataset.It was not important for me, and therefore I just used the p-value of the significance test (with the null hypothesis that both players play randomly) to streamline the predictions .
I think I should to listen to our very first principle that the first step in solving any mathematical problem is to “correctly pose the question.”
In [6]: =

Now, if we take the last result we obtained, it turns out that the best prediction is a stone with a p-value of 0.17. This means that only with a probability of 0.17, the data used for this prediction deviate from the discrete uniform distribution ( DiscreteUniformDistribution [{1,3}] ), and more likely by chance than due to a systematic error made by a human or any another reason that could change the distribution.
In [7]: =
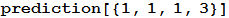
Out [7] =
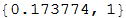
The smaller this p-value, the more confident we can be that we have found a real pattern of behavior. So we just make predictions for different lengths of history and data slices and select the prediction with the smallest p-value.
In [8]: =

And we make a choice that will beat the choice of man.
In [10]: =

Here you see the result. You can download and try it out yourself from Wolfram Demonstrations.
In [11]: =

Out [11] =

When a program has too little data, it plays randomly, so you start on an equal footing. At first, when she is just starting to learn, she makes some stupid decisions, so you can get ahead. But after 30-40 games, she begins to receive really significant predictions, and you will see how your indicator of victories falls into the negative area and so remains there.
Of course, such a solution is only good against primitive attempts to seem random. Its predictability makes it prone to losing against a well-calculated and planned strategy. It is extremely interesting to try to defeat this program with the help of intuition. It is possible, but if you stop thinking or think too hard, you will soon leave. Of course, a program could easily do this, using the same algorithm to predict the next move of this program.
Such an approach leads to the beginning of a kind of “arms race”, competitions in writing algorithms that will win a rock-paper-scissors rival algorithm, and the only way to stop this is to return to the Nash equilibrium strategy by making a choice through RandomInteger [{1,3 }] .
Supplement 1
In the event that you do not know how to play this game, the rules are as follows: you select a stone, scissors or paper using one of the three gestures shown simultaneously by you and your opponent. The stone defeats the scissors (makes them blunt), the scissors defeats the paper (they cut it), and the paper defeats the stone (it wraps it). The winner receives one point; in the event of a tie, both players do not receive points.
I thank Sergey Shevchuk for the help provided in the translation of this post.