Wandering monster: how to get rid of problems on the map
- Transfer

Already in the process of creating The Witness has become one of my favorite games. I started to play it from the moment when Jonathan Blow began its development, and could not wait for its release.
Unlike John Braid’s previous game , The Witness’s resources and programming were much closer to AAA projects than to indie games. Everyone who works on such projects, it is known that the amount of work when choosing such a path increases significantly. Above The Witness has worked a lot more people than on Braid A , but as is the case with any project of this level, it does have a number of aspects that require more attention than can afford the project management.
So I always wanted to find some free time to help create The Witness when it came to the release of the game. Therefore, one day at Thanksgiving, John and I sat down and looked at the list of things in the code base that would benefit from the extra effort of another programmer. Having decided on the relative importance of the list items, we decided that the gameplay would benefit the most if we make improvements to the player’s movement code.
Walkmonster in wall
In the context of The Witness , the task of the player’s movement code is to be as unobtrusive as possible. The player must fully immerse himself in an alternate reality, and in this gaming experience every detail is important. The last thing we wanted was for the player to notice that he was sitting at the computer and moving the virtual camera.
Therefore, the movement code of the player must be absolutely reliable. If a player clings to corners, gets stuck in the walls, falls through the floor, descends a hill without being able to go back, etc., this will instantly destroy the illusion of immersion and remind the player that he is inside an artificial gameplay, which is hampered by an unreliable system. displacements. In some circumstances, this may even lead to disastrous consequences for the player if he does not have the opportunity to solve the problem by restarting the game or reloading (probably very old) “saved”. If you often play games, you must have encountered problems of this type, and you know what I mean.
After our discussion, I began to work on this task. First of all, I decided to write integrated tools for working with the player’s movement code, so that we could analyze it and observe its current behavior. Having opened the project, I ran into a serious problem already known to me: how to name the first file of the source code? This is always the most important part of any project ( as Bob Pollard once said about the names of bands and albums ). If you give the source file a suitable name, then further work will be clear and smooth. Choose the wrong - you can destroy the whole project.
But how to call a system to ensure the quality of the player’s movement code? I have never had to write such code before. When I thought about it, I realized that I personally saw an example of such a code only once: when playing in the early Quake beta . It contained bugs with the location of monsters, and in the console window, you could see error messages stating that monsters, instead of being created on the surface of the earth, are created, partially intersecting with the geometry of the levels. Each debugging message began with the phrase "walkmonster in wall at ..."
Bingo! It’s hard to pick a better name for the code file than “walk_monster.cpp”. And I was almost sure that from now on, the code will be generated without problems.
Movement to the point
When you want to test a system, the most important thing is to actually test the system . Although this rule looks simple, people who write tests often fail to observe it.
In our particular case, it is very easy to imagine that we are testing a player’s movement code without actually testing it. Here is one example: you can perform an analysis of the volume of collisions and surfaces along which you can move in the game, look for small surfaces, gaps, etc. By eliminating all these problems, you can say that the player is now able to safely move and walk around the world.
But in fact, we tested the data, not the code. It is very likely that there will be bugs in the movement code that lead to bad behavior even with quality data.
To avoid such a trap, I wanted the testing system to be as close as possible to the behavior of the person actually controlling the movement of the character in the game. I began by writing two procedures that would become the building blocks of such testing.
The first procedure is closest to the real actions of a person. This is an update call that connects to The Witness input processing system and sends synthesized keyboard and mouse events to it. It is capable of simple things that a person can do: look around, go towards a point, look at a point, and so on. The procedure performs these actions by simply emulating user interaction with the keyboard and mouse, so I was sure that when I processed the input, The Witnesseverything will be done exactly as in testing. In the following articles I will discuss in more detail about this system and its use.
The second procedure is one step that is not used at this level. This is a function called DriveTowardPoint , which receives two points of the world and, causing an already existing system of player collisions, tries to move seamlessly from one point to another. By returning, she transmits information about the attempt: what obstacles did she encounter on the way and whether she managed to reach the end point.
This function is not as reliable as the method of testing with synthesized input, because it eliminates from testing a part of the player’s movement system. For example, any erroneous condition related to the player’s location in case of problems with the collision system will not affect testing with this feature. Nevertheless, I considered this level of testing valuable, because it can test vast areas much faster, because it does not require the execution of the entire game cycle, that is, it can be used much more often and throughout the world, and not just in individual test runs .
It is also worth noting that no physical input data is passed to this function; for example, no speeds are indicated for the starting point. This is done because The Witness- This is not an action game, so the player has few significant physical properties. Players can not jump, run on the walls, include "bullet time". You can support such behaviors with the help of systems that I will describe later, but they add levels of complexity that were not required in our project.
Anyway, after implementing DriveTowardPoint, I could begin to solve the first task of the system: determining where the player can move on The Witness Island .
Rapidly Exploring Random Trees
Where can players move? It seems that this is a simple question, but you will be surprised to know how many games were released when the development team did not know the real answer. If this is possible, then I wanted The Witness to be one of those few games in which the developers knew exactly where the player could and could not get to before the release - no surprises.
This makes problem statement (but probably not its solution) very simple: with the DriveTowardPoint function , which reliably determines whether a player can move in a straight line between two points, create a coverage map that shows where the player can be.
For some reason, I have not written a single line of code, for some reason I thought it would be best to useRapidly Exploring Random Tree . For those who are unfamiliar with this algorithm, I will explain: this is a very simple process in which we record all the points visited by us with reference to the point from which we came. To add a point to the tree, we take a random target point anywhere in the world, select the point closest to it, which is already in the tree, and try to get from this point to the target. The place where we ended up becoming the next sampling point.
Usually, this algorithm is used to search for paths: alternately for random points, we always select the same point as the target. This inclines the exploration of space towards the target point, and this is precisely what is required when our only task is to reach the goal. But in this case, I wanted to create a complete map of the places that a player can fall into, so I use only random samples.
After the implementation of this algorithm (fortunately, it is very simple and didn’t take much time), I saw that it did quite a good job of exploring space (the white paths show the paths studied, and the vertical red lines indicate the places where the algorithm collided with an obstacle) :

However, after observing his behavior, I realized that I really didn’t need such an algorithm. For example, even after many iterations, he is barely able to explore similar to the rooms shown below, despite the dense coverage of the areas outside of them. This is because it is simply not able to select fairly random points inside the rooms:

If I thought about this before starting work, I would understand that the advantage of algorithms like the Rapidly Exploring Random Tree is that they effectively explore high-dimensional spaces. In fact, this is usually the main reason for using them. But there are no high spaces in The Witness . We have a two-dimensional space (yes, distributed over a complex manifold, but this is still a two-dimensional space).
In this low-dimensional space, the advantages of the Rapidly Exploring Random Tree are weak, and its disadvantage is crucial for my task: the algorithm is designed for finding the most efficient paths to connected pairs of points in space, and not for effectively finding all the achievable points of this space. If you have such a problem, then in fact Rapidly Exploring Random Tree will take a huge amount of time to solve it.
Therefore, I quickly realized that I need to look for an algorithm that effectively completely covers low-dimensional spaces.
3D Flood Filling
When I really thought about choosing an algorithm, it became obvious that I actually needed something like the good old two-dimensional fill that is used to populate areas of a bitmap. For any starting point, I just needed to fill the entire space, exhaustively checking every possible path. Unfortunately, for many reasons, the decision for The Witness will be much more difficult than for a two-dimensional bitmap.
Firstly, we do not have a clear concept of a finite connectivity of a point. All space is continuous. This is for a pixel, we can easily list 4 possible places that can be reached from a given point, and check each of them in turn.
Secondly, there is no fixed size of a position in space, like a pixel on a bitmap. The surfaces on which the player moves, and obstacles can be anywhere, they have no maximum or minimum topological size, as there is no binding to any external grid.
Thirdly, although movement through the space of The Witness can be locally considered to be moving along a plane, space itself is in fact a deeply interconnected and changing diversity in which the areas passed for the player are directly above other areas (sometimes there are several levels located one above another) . In addition, there are connections that vary depending on the states of the world (open / closed doors, rising / descending elevators, etc.).
Taking into account the described difficulties, it is very easy to come up with your own implementation variant for the fill, which as a result will turn out to be filled with intersecting areas, missing important routes, erroneous information about connections in difficult places of diversity. In the end, the algorithm will be too cumbersome to use, because to take into account changes in the state of the world, it must be restarted.
Immediately I did not think of any good solution, so I decided to start with simple experiments. Using the Rapidly Exploring Random Tree code I wrote, I changed the choice of target points from random to very controlled. Each time I added a new point to the tree, I indicated that the points are at a unit distance along the main directions from the point, which will be considered the future target point, as is the case in a simple two-dimensional fill.
But of course, if you are not careful, it will create a useless sampling cycle. The point will branch into the neighboring 8 points around it, but these 8 points will then again try to return to the starting point, and this will continue forever. Therefore, in addition to the controlled selection of target points, I need a simple constraint: any target point that is not within a certain minimum useful distance from an existing target point will not be taken into account. To my surprise, these two simple rules create a fairly successful fill:

Not bad for a fairly simple experiment. But the algorithm suffers from what I call the “boundary echo”. This effect can be seen in the following screenshot taken during the map exploration process:

In areas without obstacles, the algorithm works well, performing samples at relatively equal distances. But when they hit the intersection border, they create points that are “outside the grid”, that is, not aligned in accordance with the sampling pattern, according to which the algorithm fills the adjacent open area. The reason why the points “in the grid” do not create excessively dense tessellation is that each new point trying to return to one of the previous ones finds the previous point there and refuses to recalculate it again. But when creating new points on the border, they are not aligned at all, so nothing can prevent them from returning to the already explored space. This leads to the creation of a wave of shifted samples, which continues until it reaches a random line of points somewhere else,
Although this does not seem to be a serious problem, in fact it is critical. The whole point of such algorithms is to concentrate the samples in areas where they are most likely to produce productive results. The more time we spend on sampling and resampling vast open areas, the less time we spend on marking the very edges of this area, which are the information we need. Since we are dealing with a continuous space, and its true form can only be described by an infinite number of samples, the ratio of significant to insignificant samples is literally a measure of the efficiency of the algorithm in creating the surface passable for the player.
However, there is a simple solution to this particular problem: you need to expand the distance at which the two points are considered “close enough.” By doing this, we will reduce the sampling density in places that are not important to us , but will also lose sampling density in places that are important to us , for example, the areas around the borders, which we want to carefully check for “holes”.
Localized directional sampling
Probably because I started with the Rapidly Exploring Random Tree, my brain ousted all other ideas except the idea of proximity. All previous algorithms for performing their task used proximity, for example, in order to determine a new point to be considered next, or to choose a point to start with to get to a new target point.
But after reflecting on the task for a while, I came to the realization that everything becomes more logical if we think not only about proximity, but also about directionality . Then it becomes obvious, but if you worked on similar tasks, you know that it is easy to fall into the trap of narrowly focused thinking and not see the big picture, even if it turns out to be simpler. That is exactly what happened to me.
When I changed my view of things, the right approach to sampling seemed obvious. Every time I wanted to expand the study of space from a point, I made a request for the existence of the nearest points in the local environment. However, instead of using the distance to these points for research, I will classify them according to their directions (before that I used only eight basic directions, but I wanted to experiment with other cores).
In any direction in which I do not “see” a point, I walk a given distance and add a point at any place where I stopped (regardless of whether I ran into something or not). If I see a point in one of the directions, then I move there and check if I can get there. If I can, then I simply add a visible edge so that the user can easily see that the points are connected. If I can't, then I add a new point at the point of collision, defining the boundary of the obstacle.
This sampling method worked just fine. It allows us to control the sampling very precisely with the help of convenient adjustable parameters, save all the necessary points and avoid unnecessary tessellation, which leads to a very fast fill of space:

Since the algorithm performs a search along directions, rather than simply using proximity, it is protected from boundary echo and limits oversampling only to the boundaries we need:

Moreover, the algorithm is completely unaffected by state changes or problems with complex manifolds. It deals only with points, and these points can be anywhere, and new ones can be added at any time. If you have already mapped an area with the door closed, then after opening the door, you simply place a single research point on the other side of the door and order the algorithm to continue expanding this map, after which it will correctly connect and properly examine the entire area behind the door.
You can also change the basic settings at any time, and the system will continue to work. Do you want the area to be sampled at a higher density? Just lower the default distance value. This can be done already in the process of constructing a map, and the algorithm will begin sampling with a higher density without having to reset previous results (which may take some time).
Rudimentary rib check
The default algorithm already carefully samples the boundaries, because the intersections create additional points that are not included in the sampling pattern, but it does not necessarily check them with the care I need, because it does not perform any special actions when encountering obstacles. I realized that since I knew which of the points were created during collisions, the two detected points of collisions are connected by an edge and we can call for additional sampling in order to try to find more boundary points in the neighborhood.
I didn’t actively explore this approach, but I created a rudimentary method for testing this theory, and it seemed promising to me. Taking any two points of collision connected by an edge, I move to the midpoint of the edge and try to conduct the outward-facing perpendicular to the edge. If it does not intersect with the border at a very short distance, then I assume that the border is more complicated, and add a new target point to continue the search in this area.
Even this simple scheme creates very high-quality dense sampling along the border without undue sampling of neighboring open areas. Here is an area with multiple borders, but without edge checking:

And here is the same area with edge checking:
No matter how satisfied I am with this result, I was surprised at the lack of significantly better algorithms for sampling the boundary, and I will try to select a few more methods in the future.
Quick wins
Even by investing just a little time in the development and creating a fairly simple code, I achieved that Walk Monster is already creating quite useful output data that can detect real problems in the game. Here are examples of problems that I found during the development of the algorithm:

The slopes on the sides of this platform should not be passable, but the player can walk on them. This happened because a pathological poor way of processing oblique geometry is present in the player’s movement code. Now I know that he is there, and I will correct him when it comes to ensuring his reliability.
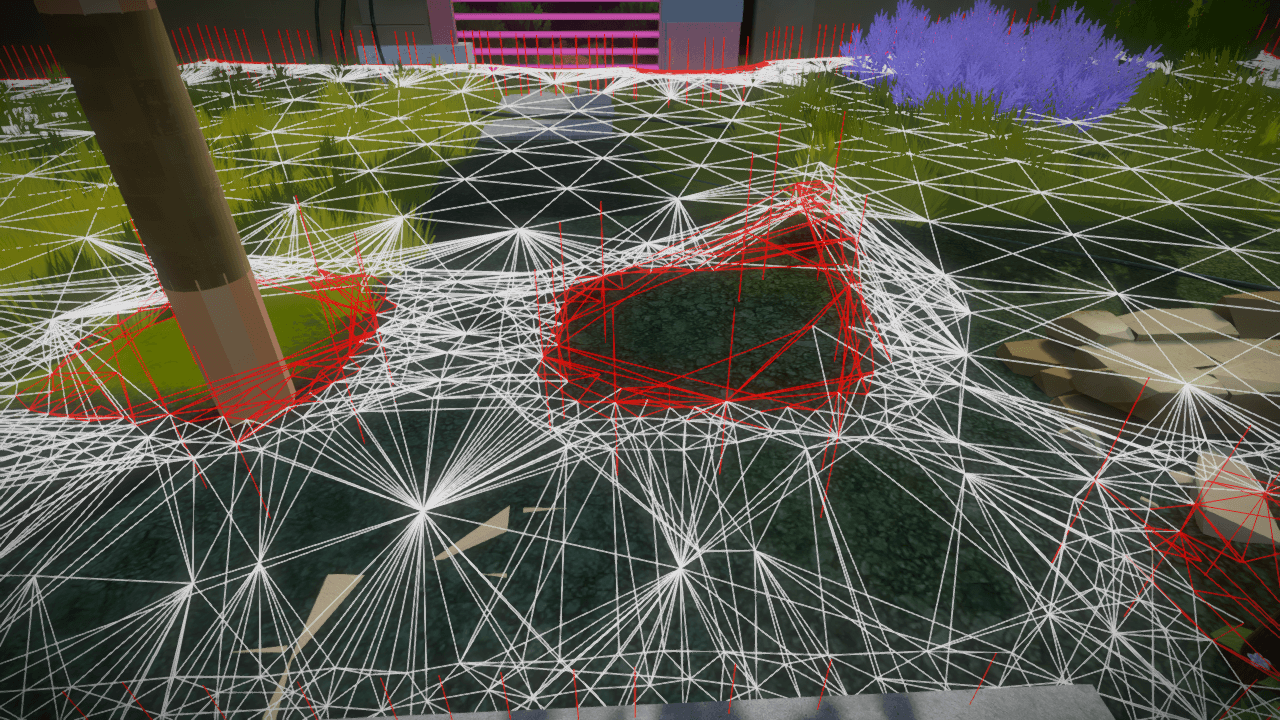
The Witness should have been a contemplative game, but wondering why it seems that there is a stone, although it does not exist, was not one of its koans. As you can guess, this problem arose because someone left in the game the amount of collision after removing the geometry that indicates it. This can easily happen, and it’s very good that we have a tool that can quickly recognize such mistakes so that people don’t have to do it.


These objects were supposed to become impassable rocks, but Walk Monster discovered that this did not happen. Worse, Walk Monster found that for some reason we only walk one way (from left to right in the screenshot), but this should not happen. I made sure that the player can really do it (I managed). It is very interesting to observe the occurrence of such errors!
Open questions
When you see good results that can be developed further, it is inspiring. As I said, if you pick a suitable name for the source files, then everything will go like clockwork! But all this work was done in just a few days, so it is far from exhaustive, and much has been done completely improvised. If I have enough time to further develop these systems, then it is worth answering a few questions.
First, what kind of post processing needs to be done with the data to make it easier to visualize? It will be difficult for people to understand the raw network of points and edges, but if we improve the description of the data, then this may make it difficult at first glance to assess the complex passable areas.
Second, how can sampling patterns be improved around boundaries to ensure that the maximum number of “holes” is found? Are there any good ways to characterize the information of the figures in the lattice, and are there any qualitative tessellation schemes that maximize the probability of crossing and passing through these figures?
Third, which sampling patterns are better for filling spaces — regular or randomized? I can easily change the criteria for selecting target points to create more randomized patterns, but it’s not very clear if you should do this, and if so, which types of randomized patterns will be better.
Fourth, what other information do we want to receive from the maps of passable areas, if we have already learned how to build them? For example, it is very easy to expand an existing system with functions such as finding paths or distance maps so that the user can select a point and request the shortest path between it and some other point, or see the heat map of the distance between the point and other points on the map. Would such queries be helpful? What other queries can I use?
At the moment, visualizations of passable areas obtained with the help of Walk Monster are more than enough to show that the player’s movement code is rather bad. I planned to go over to creating a system for nightly testing of maps using the method of simulating user input, but it is obvious that we already have enough problems without this step to solve. Therefore, the next step is to increase the reliability of the player’s movement code. And while I am working on this, I would like to check whether it is possible to increase the speed of execution by one or two orders of magnitude, because while the work of Walk Monster slows down the collision brake system very much.