Parse and calculate MS Excel formulas
One of the most interesting problems that we had to deal with while working on the Spreadsheet component was the mechanism for calculating formulas. Working on it, we thoroughly delved into the mechanics of the functioning of a similar mechanism in MS Excel.
And today I want to tell you about the principles of its work, tricks and pitfalls. And in order not to boil down to dry retelling of documentation, diluted with additions “from life” - I will at the same time briefly describe how we implemented such a mechanism.
So, in this article we will talk about three main parts of the classic calculator of formulas - parsing expressions, storing and calculating.

The expression in Excel is stored in the reverse Polish notation , RPN . An expression in an RPN form is a simple array whose elements are called ParsedThing.
The full ParsedThing suite consists of the following elements:
Let me give you a couple of examples.
The expression written in the reverse Polish notation is calculated using the stack machine. A good example is given on Wikipedia.
But in calculating expressions from Excel, there were some tricks. The developers endowed all operands with the property “type of value”. This property indicates how the operand should be converted before evaluating the operator or function. For example, ordinary mathematical operators cannot be performed on links, but can only on simple values (numeric, logical, etc.). For the expression “A1 + B1: C1” to work correctly, Excel indicates for links A1 and B1: C1 that they must be converted to a simple value before pushing the result of the calculation onto the stack.
There are three types of operands:
Each operand is of the default type:
The result of evaluating a function can be of any type. Most functions return Value, some (for example, INDIRECT) -Reference, the rest - Array (MMULT).
End users do not need to clog their heads with data types: Excel itself selects the desired operand type already at the stage of parsing the expression. And at the stage of calculation, one cannot do without “implicit type conversion”. It occurs in accordance with the following scheme:
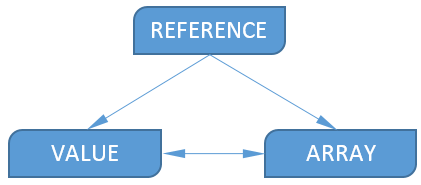
Value of type Value can be converted to Array , in this case an array of one value will be created. In the opposite direction ( Array-> Value ), the transformation is also quite simple - the first element is taken from the array.
As you can see from the diagram, a value of type Reference cannot be obtained from Value or Array.. This is quite logical, from a number, a string, etc. Get the link does not work.
When converting Reference to Array, all values from the cells in the range are overwritten into an array. In the case when the range is complex (consisting of two or more other ranges), the conversion result is equal to the error #VALUE!
An interesting way is the conversion of Reference to Value . We called this rule “Crossing” among ourselves. The easiest way to explain its essence is as an example:
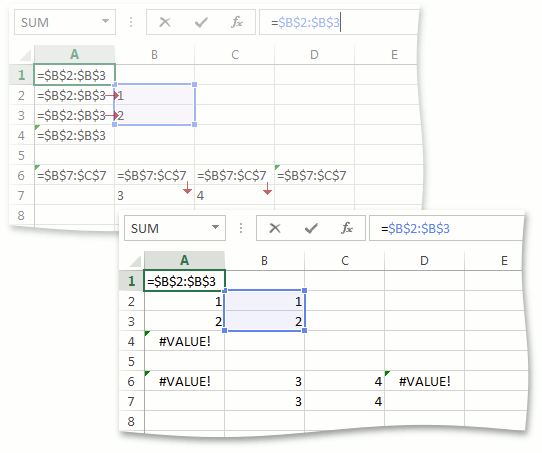
Suppose we want to bring to Value the values of cells A1 through A4, which contain the same formula “= B2: B3”, which is of type Reference. Range B2: B3 consists of one column. If this were not the case and there would be more columns, the conversion of Reference to Value for all cells from A1 to A4 would return #VALUE! and that would be the end. Cells A2 and A3 are in rows intersecting the range B2: B3. The Reference-> Value transformation for these cells will return the corresponding value from the range B2: B3, i.e. the conversion for A2 will return 1, and for A3 it will return 2. For the remaining cells, such as A1 and A4, the conversion will return #VALUE!
The exact same behavior will be for the range B7: C7, consisting of one line. For cells B6 and C6, the conversion will return the values 3 and 4, respectively, and for A6 and - D6 #VALUE! Similarly, if there were more rows in the range, the conversion would return #VALUE! For all cells A6 through D6, there
are several type conversion rules.
The values of all formulas inside the cells are always cast to the Value type.
For instance:
Mathematical, logical and textual operators cannot work with links . Therefore, arguments for them are prepared and cast to either Value or Array. The second option is possible only inside Array formulas. For example, when calculating the expression "= B1: B2 + A3: B3" written in cell A1, both arguments of the mathematical addition operator will first be converted to the Value type by the Crossing rule, and then the results will be added. Those. the value will be equal to the sum of the values of cells B1 and A3.
Link operators cannot work with any type other than Reference . For example, the formula "= A1:" test "" will be incorrect, entering such a formula will lead to an error - Excel simply will not allow such a formula to be written to the cell.
Expressions inside “names” and some other constructions are cast to the default type . Unlike formulas inside cells, expressions in which are cast to the Value type. The expression inside some “name” name "= A1: B1" as a result of calculation will be equal to the range A1: B1. The same expression in the cell will be calculated and as a result there will be either a single value or a #VALUE error! But the expression in the cell "= name" will already be of type Value and will be calculated depending on the current cell.
Having written the first version of the parser on our knees, we realized that the monster is too large and poorly modernizable. And in our case it was inevitable, because we knew a large number of subtleties when the parser somehow worked. For fun, I decided to try other methods and armed myself with a Coco / R translator generator . The choice fell on him at that moment mainly due to the fact that I was already quite familiar with him. Coco / R lived up to my expectations. The parser generated by him showed very good results in terms of speed, so we decided to stop on this option.
Of course, as part of this article, I will not dwell on describing the features and retelling the Coco / R documentation. Fortunately, the documentationwritten in my opinion is very clear. In addition, I recommend reading the article on Habr .
In some places, Coco / R generates non-CLS-compliant code.
The problem is in public constants, whose name begins with an underscore. There is only one correct way out of the situation - to fix Coco / R, since its full source code is available on the developers website.
Having rummaged in source codes found three places where public constants are created. All of them are in the ParserGen.cs file. For instance:
Further, the resulting code continues to be invalid, now according to FxCop . In our company, assemblies are constantly tested for compliance with a large number of rules. Of course, since the code is generated, it would be possible to make an exception for it and suppress the verification of the generated classes. But this is not the best way out. Fortunately, there is only one problem - public fields do not comply with the Microsoft.Design rule : CA1051 . To fix everything, just make the necessary changes to the Parser.frame and Scanner.frame files, which are located next to the grammar file. That is, Coco / R itself does not need to be rebuilt. Here are some examples:
Some of these fields are not used at all outside the class - they are simply made private, the rest - we create public properties.
When developing grammar for Coco / R, I used a plugin for the studio .
The plugin also had to be taught to generate CLS compliant code. Download the source code of the plugin , and repeat the same operations as with Coco / R itself.
Let me remind you that to parse the expression Coco / R creates a couple of classes - Parser and Scanner. Both are recreated for each new expression. Since in our case there are a lot of expressions, reconstructing the scanner may take extra time on a large number of calls. In general, one set of a parser scanner is enough for us. The first modernization touched on precisely this.
The second upgrade involved the Buffer helper class, which is created by the scanner to read the incoming character stream. Out of the Box Coco / R contains a couple implementations of Buffer and UTF8Buffer. Both of them work with a stream. We don’t need a stream: enough work with the string. To do this, create a third implementation of StringBuffer, simultaneously highlighting the IBuffer interface:
The implementation of StringBuffer itself is simple:
The grammar for Coco / R is described in the RBNF ( EBNF ) . The development of grammar for Coco / R is reduced to the construction of RBNF and its design in accordance with the Coco / R grammar in a file with the extension atg.
The parser is built on the basis of recursive descent, the grammar must satisfy LL (k). The scanner is based on a deterministic state machine .
So let's get started. The first in the grammar file is the name of the future compiler:
The scanner specification should follow. The scanner will be case-insensitive, we indicate this using the keyword IGNORECASE. Now we need to decide on the symbols. We need to separate the numbers, letters, control characters. It turned out the following:
Coco / R allows you to not only add lots of characters, but also subtract them. So, the ANY keyword is used in the letter description, which substitutes the entire set of characters from which the other sets defined above are subtracted.
An important task of the scanner is the identification of tokens in the input sequence. While working on the parser, the set of tokens is constantly changing and as a result it looks like this:
Please note that the identifier may contain one or more dot characters. Such, for example, can be the name of the sheet in the link to the range. An additional, extended, identifier is also required. It differs from the usual one by the presence of a question mark or backslash. I note that in Excel, the concept of an identifier is quite complex and difficult to describe in grammar. Instead, all the lines identified by the scanner as ident and wideident, I check in the code for compliance with the following rules:
Separating quotedOpenBracket, quotedSymbol and pathPart into a hotel token is nothing more than a trick. She allowed to skip the characters in the column names in the table link, followed by an apostrophe. For example, in the expression “= Table1 [Column '[1']]”, the column name begins after the character '[' and continues to the character ']'. At the same time, the first such character, along with the apostrophe preceding it, will be read by the scanner as the terminal quotedSymbol (']) and, therefore, reading the column name on it will not stop.
Finally, tell the scanner to skip line feeds and tabs.
IGNORE eol + '\ n' + '\ t'. Expressions themselves can be written in several lines, but this does not affect the grammar.
We have come to the main section of PRODUCTIONS. It is necessary to describe all non-terminals in it. In the examples below, I will provide simplified code, I cut out most of the semantic inserts, because they will make it difficult to understand grammar. I will leave only the places for constructing the expression itself, without optimizations.
For all non-terminals (of which Coco / R will make methods) a reference will be transmitted to the expression in RPN form, as well as the type of data to which it must be converted. When calling the parser for the formula inside the cell, the initial data type is Value. Further, during parsing, it will change, and the prepared type will be passed to the branch of the parsing tree. For example, when parsing the expression “= OFFSET (A1: B1, A1, A2)”, the Polish entry element - the OFFSET function - will receive the type Value, while parsing the arguments, the first will be converted to Reference, the other two to Value. For all functions, we store information which arguments and what types should be passed to it.
The task of the parser is also to check the formula for correctness. We will consider the formula incorrect if Excel does not allow us to write it to the cell. In addition to syntax errors, an incorrect number of arguments passed to a function or data type mismatch to the requested one can also make the formula incorrect. For example, the ROW function either does not need parameters at all, or only one, and it should be exclusively Reference. We have already said that no other type can be cast to Reference, which means that the expressions “= ROW (1)”, “= ROW (“ A1 ”)” will be invalid.
Because our grammar is a complicated grammar for ordinary mathematical expressions, it is constructed in the same way depending on the seniority of operations. The first is followed by logical expressions, the last is range operators. Those. in order of increasing priority.
For visualization of RBNF I use a small program EBNF Visualizer . This is how the first nonterminal in our grammar will look like - a logical expression:
Next is the grammar for Coco / R. In semantic inserts drawn between “(.” And “.)” I will add the necessary ParsedThing to the expression.
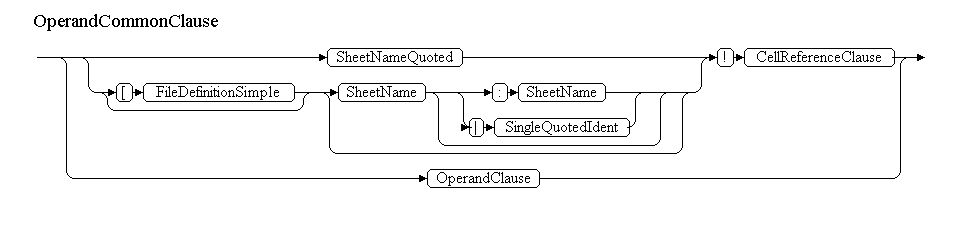
According to this principle, they will be built: ConcatenateClause, AddClause, MultipyClause, PowerClause, UnaryClause, PercentClause, RangeUnionClause, RangeIntersectionClause, CellRangeClause. CellRangeClause ends with non-terminals describing the operators. It is followed by the first operand - OperandCommonClause. It will look something like this:
However, there is ambiguity in the given grammar. It lies in the fact that SheetName and OperandClause can start from the same terminal - with an identifier. For example, the expression “= Sheet! A1” may follow, or maybe “= name”. Here “Sheet” and “name” are identifiers. Fortunately, Coco / R allows you to resolve conflicts by scanning the incoming stream with the scanner several terminals ahead. Those. we can look in search of the '!' character, if one is found, then we parse SheetName, otherwise OperandClause. This is how the grammar will look:
To resolve the conflict, the IsSheetDefinition () method defined in the Parser class is used. It is convenient to write such methods in a separate file, marking the class as partial.
The SheetName nonterminal can start with a digit or consist only of numbers. In this case, the sheet name must be enclosed in apostrophes. Otherwise, Excel adds the missing apostrophes.
There are a couple of errors in this grammar. Firstly, all terminals inside the non-terminal are optional. And secondly, it allows you to insert a space or any character described in the IGNORE section between a number and an identifier. The problem can be solved using the conflict resolution mechanism, but without additional functions. Right in the grammar, we check for a gap between the number and the identifier following it:
In OperandClause, we will get from OperandCommonClause if there is no link to the sheet, external book or DDE source. From this nonterminal, we can get to ArrayClause, StringConstant (both cannot have a link to the sheet in front of them), CellReferenceClause, or we will meet the bracket and go to the beginning of the entire parse tree - LogicalClause.
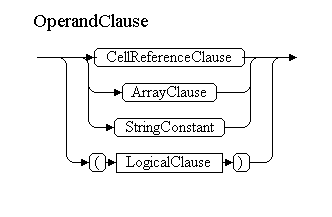
CellReferenceClause is probably the largest non-terminal, it contains almost all types of operands:
Most non-terminals have to create conflict resolution methods. Next, we describe the grammar for all remaining non-terminals.
Consider the task of highlighting the ranges involved in the formula.
The problem here is that the expression can be invalid, and ranges should be highlighted anyway. At that moment, the parser, without mastering the expression, always returned null. Of course, one could try to figure out the partially read expression and collect links from it, but how do you know where in the expression the specific link is? Therefore, we decided to teach the parser to immediately put together everything interesting in the course of reading. So, all the links by type were in specially designed collections. A parser, when it detects, for example, a range reference, calls the corresponding method
After reading, regardless of whether it ended successfully or not, we have a set of links.
Another mechanism began to be based on this - predictions. In the expression “= 1 * (1 + 2”, the balance of the brackets is violated, but most likely the user forgot to put the bracket at the end of the expression. That is, you can try to fix this formula by adding the missing bracket to it. Of course, the parser does this he won’t just say where and what he thinks is missing, for example, in OperandClause we already know the following lines:
Of course, all these actions are done only when the expression is entered manually and there is a need to draw the ranges involved or try to correct the unfinished formula.
Excel, still at the stage of parsing the expression, is trying to make it easier for itself further life. To this end, whenever possible, he fills the expression with all sorts of auxiliary elements. Let's look at them.
AttrSemi Attribute. This attribute is added as the first element in those expressions that contain volatile functions.
Attribute Class Mem. This includes several attributes at once. They are united by the fact that they are created to optimize the calculation of links. In fact, they are a wrapper over some expression. During the calculation, the internal expression may not be evaluated, the result will be Mem. A distinctive feature of these elements is that they are inserted in the reverse Polish notation before the expression that is optimized.
The AttrSum attribute is used as a simplified form for writing the SUM function when only one argument is passed to the function.
The AttrIf attribute is used in conjunction with one or two Goto statements to optimize the calculation of the IF function. Let me remind you the syntax of the IF: IF function (condition, true_value, [false_value]). Of the two values, you can calculate only one and save time on calculating the other, if immediately after calculating the condition go to the desired value. Thus, the simple expression = IF (condition, ”v_true”, ”v_false”) Excel thickens with attributes. It turns out approximately the following:

The calculation goes like this. The value of condition is pushed onto the stack. The next in line is the IF attribute. He looks at the value on top of the stack. If it is true, it does nothing. If false, adds the current counter of elements in the expression to the offset recorded inside, thereby the counter begins to point to “v_false”. Next, either v_true or v_false is calculated and the result is pushed onto the stack. Next is Goto, first or second. But both of them refer to the end of the expression (or to the following operators in the expression, if any).
AttrChoose works in a very similar way. Let me remind you that the CHOOSE function selects one of the arguments whose sequence number is specified in the first argument.
Thus, only one argument affects the further result of the calculation, all the others can be skipped. AttrChoose stores a set of mixes, each of which points to the beginning of each subsequent argument. After the argument follows the familiar AttrGoto, which points to the end of the expression or the element following the CHOOSE function.
The Space attribute is used to save the format of the user-entered expression, namely line feeds and spaces. Each such attribute, in addition to quantity, has a type. There are only six types:
Looking at these types, you can guess that Excel cannot keep spaces at the end of the line and before the '=' sign. In addition, spaces within structured links and arrays will not be saved either.
When our control just learned to read and write files in the OpenXML format, we hastened to check it in practice. And the best way for this is to find many, many files and try to drive the reading and writing of these files. So we pumped about 10k random OpenXML files and wrote a simple program. They created a task for her on a test farm. Every night, the task starts automatically and reads and writes files. If any errors occur, all the necessary information is recorded in the log. So we were able to debug a huge number of errors.
As the control developed, both supported formats and features were added. So now 20k xls files and 15k csv files are constantly being tested. And they are tested not only for read-write, but also checked by third-party utilities, which also help us a lot.
We got a huge amount of knowledge about the work of formulas in Excel when we launched the task of testing formula calculations from the same 10k OpenXML and 20k xls files. The file is opened, written to the data model. Then, in turn, we begin to mark the cells on the sheet as not counted, calculate and compare the new value with the value that was read from the file. Thus, we killed two birds with one stone - we debugged the formula parser and brought the calculation results as close as possible to those obtained using Excel.
Of course, we did not get rid of all the problems associated with formulas - this is too extensive a topic. But already a lot of things have been studied and implemented, and we are not resting on our laurels. Personally, I was interested to work on it, I hope that it was interesting for you to read this article.
Thanks for attention!
And today I want to tell you about the principles of its work, tricks and pitfalls. And in order not to boil down to dry retelling of documentation, diluted with additions “from life” - I will at the same time briefly describe how we implemented such a mechanism.
So, in this article we will talk about three main parts of the classic calculator of formulas - parsing expressions, storing and calculating.
The internal representation of an expression
The expression in Excel is stored in the reverse Polish notation , RPN . An expression in an RPN form is a simple array whose elements are called ParsedThing.
The full ParsedThing suite consists of the following elements:
Operands - constants, arrays, links;
Constants:
- ParsedThingNumeric
- ParsedThingInt
- ParsedThingString
- ParsedThingBool
- ParsedThingMissingArg
- ParsedThingError
- ParsedThingArray
- ParsedThingName, ParsedThingNameX
- ParsedThingArea, ParsedThingAreaErr, ParsedThingArea3d, ParsedThingAreaErr3d, ParsedThingAreaN, ParsedThingArea3dRel
- ParsedThingRef, ParsedThingRefErr, ParsedThingRef3d, ParsedThingErr3d, ParsedThingRefRel, ParsedThingRef3dRel
- ParsedThingTable, ParsedThingTableExt
Operators - mathematical, logical, reference, as well as function calls;
Function Calls:
- ParsedThingFunc
- ParsedThingFuncVar
- ParsedThingAdd
- ParsedThingSubtract
- ParsedThingMultiply
- ParsedThingDivide
- ParsedThingPower
- ParsedThingConcat
- ParsedThingLess
- ParsedThingLessEqual
- ParsedThingEqual
- ParsedThingGreaterEqual
- ParsedThingGreater
- ParsedThingNotEqual
- ParsedThingIntersect
- ParsedThingUnion
- ParsedThingRange
- ParsedThingUnaryPlus
- ParsedThingUnaryMinus
- ParsedThingPercent
Auxiliary elements and attributes (to optimize the speed of calculations, preserve spaces and line breaks in the expression, i.e. not affecting the result of the calculation of the expression).
Auxiliary:
- ParsedThingMemArea
- ParsedThingMemNoMem
- ParsedThingMemErr
- ParsedThingMemFunc
- ParsedThingParentheses
- ParsedThingAttrSemi
- ParsedThingAttrIf
- ParsedThingAttrChoose
- ParsedThingAttrGoto
- ParsedThingAttrSum
- ParsedThingAttrSpace
Let me give you a couple of examples.
- "= A1 * (1 + true)". In the internal view, it will look like this: {ParsedThingRef (A1), ParsedThingInt (1), ParsedThingBool (true), ParsedThingAdd, ParsedThingMultiply}
- "= SUM (A1,1,” 2 ”,)". In the internal view it will look like this: {ParsedThingRef (A1), ParsedThingInt (1), ParsedThingString (“2”), ParsedThingMissing, ParsedThingFuncVar (“SUM”, 4 arguments)}
Calculations
The expression written in the reverse Polish notation is calculated using the stack machine. A good example is given on Wikipedia.
But in calculating expressions from Excel, there were some tricks. The developers endowed all operands with the property “type of value”. This property indicates how the operand should be converted before evaluating the operator or function. For example, ordinary mathematical operators cannot be performed on links, but can only on simple values (numeric, logical, etc.). For the expression “A1 + B1: C1” to work correctly, Excel indicates for links A1 and B1: C1 that they must be converted to a simple value before pushing the result of the calculation onto the stack.
There are three types of operands:
- Reference;
- Value
- Array
Each operand is of the default type:
| All kinds of links | Reference |
| Constants except arrays | Value |
| Arrays | Array |
| Function calls | Value, Reference, Array |
End users do not need to clog their heads with data types: Excel itself selects the desired operand type already at the stage of parsing the expression. And at the stage of calculation, one cannot do without “implicit type conversion”. It occurs in accordance with the following scheme:
Value of type Value can be converted to Array , in this case an array of one value will be created. In the opposite direction ( Array-> Value ), the transformation is also quite simple - the first element is taken from the array.
As you can see from the diagram, a value of type Reference cannot be obtained from Value or Array.. This is quite logical, from a number, a string, etc. Get the link does not work.
When converting Reference to Array, all values from the cells in the range are overwritten into an array. In the case when the range is complex (consisting of two or more other ranges), the conversion result is equal to the error #VALUE!
An interesting way is the conversion of Reference to Value . We called this rule “Crossing” among ourselves. The easiest way to explain its essence is as an example:
Suppose we want to bring to Value the values of cells A1 through A4, which contain the same formula “= B2: B3”, which is of type Reference. Range B2: B3 consists of one column. If this were not the case and there would be more columns, the conversion of Reference to Value for all cells from A1 to A4 would return #VALUE! and that would be the end. Cells A2 and A3 are in rows intersecting the range B2: B3. The Reference-> Value transformation for these cells will return the corresponding value from the range B2: B3, i.e. the conversion for A2 will return 1, and for A3 it will return 2. For the remaining cells, such as A1 and A4, the conversion will return #VALUE!
The exact same behavior will be for the range B7: C7, consisting of one line. For cells B6 and C6, the conversion will return the values 3 and 4, respectively, and for A6 and - D6 #VALUE! Similarly, if there were more rows in the range, the conversion would return #VALUE! For all cells A6 through D6, there
are several type conversion rules.
The values of all formulas inside the cells are always cast to the Value type.
For instance:
- "= 123" A constant is specified in this formula, it is already of type Value. There is no need to convert anything.
- "= {1,2,3}" An array is specified here. Converting to Value by the rule gives us the first element of the array - 1. It will be the result of evaluating the expression.
- The formula "= A1: B1" is in cell B2. The range reference operand is of type Reference by default. When calculating it, it will be reduced to Value according to the “crossing” rule. The result in this case will be the value from cell B1.
Mathematical, logical and textual operators cannot work with links . Therefore, arguments for them are prepared and cast to either Value or Array. The second option is possible only inside Array formulas. For example, when calculating the expression "= B1: B2 + A3: B3" written in cell A1, both arguments of the mathematical addition operator will first be converted to the Value type by the Crossing rule, and then the results will be added. Those. the value will be equal to the sum of the values of cells B1 and A3.
Link operators cannot work with any type other than Reference . For example, the formula "= A1:" test "" will be incorrect, entering such a formula will lead to an error - Excel simply will not allow such a formula to be written to the cell.
Expressions inside “names” and some other constructions are cast to the default type . Unlike formulas inside cells, expressions in which are cast to the Value type. The expression inside some “name” name "= A1: B1" as a result of calculation will be equal to the range A1: B1. The same expression in the cell will be calculated and as a result there will be either a single value or a #VALUE error! But the expression in the cell "= name" will already be of type Value and will be calculated depending on the current cell.
Parser
Having written the first version of the parser on our knees, we realized that the monster is too large and poorly modernizable. And in our case it was inevitable, because we knew a large number of subtleties when the parser somehow worked. For fun, I decided to try other methods and armed myself with a Coco / R translator generator . The choice fell on him at that moment mainly due to the fact that I was already quite familiar with him. Coco / R lived up to my expectations. The parser generated by him showed very good results in terms of speed, so we decided to stop on this option.
Of course, as part of this article, I will not dwell on describing the features and retelling the Coco / R documentation. Fortunately, the documentationwritten in my opinion is very clear. In addition, I recommend reading the article on Habr .
We collect Coco / R from source
In some places, Coco / R generates non-CLS-compliant code.
The problem is in public constants, whose name begins with an underscore. There is only one correct way out of the situation - to fix Coco / R, since its full source code is available on the developers website.
Having rummaged in source codes found three places where public constants are created. All of them are in the ParserGen.cs file. For instance:
void GenTokens() {
foreach (Symbol sym in tab.terminals) {
if (Char.IsLetter(sym.name[0]))
gen.WriteLine("\tpublic const int _{0} = {1};", sym.name, sym.n);
}
}
Further, the resulting code continues to be invalid, now according to FxCop . In our company, assemblies are constantly tested for compliance with a large number of rules. Of course, since the code is generated, it would be possible to make an exception for it and suppress the verification of the generated classes. But this is not the best way out. Fortunately, there is only one problem - public fields do not comply with the Microsoft.Design rule : CA1051 . To fix everything, just make the necessary changes to the Parser.frame and Scanner.frame files, which are located next to the grammar file. That is, Coco / R itself does not need to be rebuilt. Here are some examples:
public Scanner scanner;
public Errors errors;
public Token t; // last recognized token
public Token la; // lookahead token
Some of these fields are not used at all outside the class - they are simply made private, the rest - we create public properties.
When developing grammar for Coco / R, I used a plugin for the studio .
His buns
The last feature would be very convenient, but, unfortunately, it worked for me incorrectly - it showed errors where it should not.
- Syntax highlighting for a grammar file;
- Automatic start of the generator when saving the file with the grammar;
- Intellisense for keywords
- Shows compilation errors that occur in the parser file in the appropriate place in the grammar file
The last feature would be very convenient, but, unfortunately, it worked for me incorrectly - it showed errors where it should not.
The plugin also had to be taught to generate CLS compliant code. Download the source code of the plugin , and repeat the same operations as with Coco / R itself.
We upgrade the scanner and parser
Let me remind you that to parse the expression Coco / R creates a couple of classes - Parser and Scanner. Both are recreated for each new expression. Since in our case there are a lot of expressions, reconstructing the scanner may take extra time on a large number of calls. In general, one set of a parser scanner is enough for us. The first modernization touched on precisely this.
The second upgrade involved the Buffer helper class, which is created by the scanner to read the incoming character stream. Out of the Box Coco / R contains a couple implementations of Buffer and UTF8Buffer. Both of them work with a stream. We don’t need a stream: enough work with the string. To do this, create a third implementation of StringBuffer, simultaneously highlighting the IBuffer interface:
public interface IBuffer {
string GetString(int beg, int end);
int Peek();
int Pos { get; set; }
int Read();
}
The implementation of StringBuffer itself is simple:
public class StringBuffer : IBuffer {
int stringLen;
int bufPos;
string str;
public StringBuffer(string str) {
stringLen = str.Length;
this.str = str;
if (stringLen > 0)
Pos = 0;
else
bufPos = 0;
}
public int Read() {
if (bufPos < stringLen)
return str[bufPos++];
else
return StreamBuffer.EOF;
}
public int Peek() {
int curPos = Pos;
int ch = Read();
Pos = curPos;
return ch;
}
public string GetString(int beg, int end) {
return str.Substring(beg, end - beg);
}
public int Pos {
get { return bufPos; }
set {
if (value < 0 || value > stringLen)
throw new FatalError("buffer out of bounds access, position: " + value);
bufPos = value;
}
}
}
Testing
Just in case, we check that we created the additional class for a reason. We start testing three scenarios for a string of length N:
At N = 100:
Init x 100000:
Buffer: 171 ms
StringBuffer: 2 ms
Read xNx10000:
Buffer: 14 ms
StringBuffer: 8
ms GetString x (N-10) x 10000:
Buffer: 250 ms
StringBuffer: 20 ms
- initialization from a string;
- reading a character (calling the IBuffer.Read () method N times);
- getting 10 characters from a string (call IBuffer.GetString (i-10, i) (N-10) times).
At N = 100:
Init x 100000:
Buffer: 171 ms
StringBuffer: 2 ms
Read xNx10000:
Buffer: 14 ms
StringBuffer: 8
ms GetString x (N-10) x 10000:
Buffer: 250 ms
StringBuffer: 20 ms
Grammar Design
The grammar for Coco / R is described in the RBNF ( EBNF ) . The development of grammar for Coco / R is reduced to the construction of RBNF and its design in accordance with the Coco / R grammar in a file with the extension atg.
The parser is built on the basis of recursive descent, the grammar must satisfy LL (k). The scanner is based on a deterministic state machine .
So let's get started. The first in the grammar file is the name of the future compiler:
COMPILER FormulaParserGrammar
The scanner specification should follow. The scanner will be case-insensitive, we indicate this using the keyword IGNORECASE. Now we need to decide on the symbols. We need to separate the numbers, letters, control characters. It turned out the following:
CHARACTERS
digit = "0123456789".
chars = "~!@#$%^&*()_-+={[]}|\\:;\"',./?<> ".
eol = '\r'.
blank = ' '.
letter = ANY - digit - chars - eol - blank + '_'.
Coco / R allows you to not only add lots of characters, but also subtract them. So, the ANY keyword is used in the letter description, which substitutes the entire set of characters from which the other sets defined above are subtracted.
An important task of the scanner is the identification of tokens in the input sequence. While working on the parser, the set of tokens is constantly changing and as a result it looks like this:
TOKENS
ident = letter {letter | digit | '.'}.
wideident = letter {letter | digit} ('?'|'\\') {letter | digit | '?'|'\\'}.
positiveinumber = digit {digit}.
fnumber =
"." digit {digit} [("e" | "E") ["+" | "-"] digit {digit}]
|
digit {digit}
(
"." digit {digit}
[("e" | "E" ) ["+" | "-"] digit {digit} ]
|
("e" | "E") ["+" | "-"] digit {digit}
).
space = blank.
quotedOpenBracket = "'[".
quotedSymbol = "''" | "']" | "'@" | "'#".
pathPart = ":\\".
trueConstant = "TRUE".
falseConstant = "FALSE".
Please note that the identifier may contain one or more dot characters. Such, for example, can be the name of the sheet in the link to the range. An additional, extended, identifier is also required. It differs from the usual one by the presence of a question mark or backslash. I note that in Excel, the concept of an identifier is quite complex and difficult to describe in grammar. Instead, all the lines identified by the scanner as ident and wideident, I check in the code for compliance with the following rules:
- May contain only letters, numbers, and symbols: _,., \,?;
- Cannot be equal to TRUE or FALSE;
- The first character can only be a letter, an underscore, or a backslash;
- If the first character of the string is backslash, then the second character may not be, or it must be one of: _,., \,?;
- It should not be similar to the name of the range (for example, A10);
- It should not start on a line that can be perceived as a link in the format R1C1. The nature of this condition is difficult to explain, I will give only a few examples of identifiers that do not satisfy it: “R1_test”, “R1test”, “RC1test”, “R”, “C”. At the same time, “RCtest” is quite suitable.
Separating quotedOpenBracket, quotedSymbol and pathPart into a hotel token is nothing more than a trick. She allowed to skip the characters in the column names in the table link, followed by an apostrophe. For example, in the expression “= Table1 [Column '[1']]”, the column name begins after the character '[' and continues to the character ']'. At the same time, the first such character, along with the apostrophe preceding it, will be read by the scanner as the terminal quotedSymbol (']) and, therefore, reading the column name on it will not stop.
Finally, tell the scanner to skip line feeds and tabs.
IGNORE eol + '\ n' + '\ t'. Expressions themselves can be written in several lines, but this does not affect the grammar.
We have come to the main section of PRODUCTIONS. It is necessary to describe all non-terminals in it. In the examples below, I will provide simplified code, I cut out most of the semantic inserts, because they will make it difficult to understand grammar. I will leave only the places for constructing the expression itself, without optimizations.
For all non-terminals (of which Coco / R will make methods) a reference will be transmitted to the expression in RPN form, as well as the type of data to which it must be converted. When calling the parser for the formula inside the cell, the initial data type is Value. Further, during parsing, it will change, and the prepared type will be passed to the branch of the parsing tree. For example, when parsing the expression “= OFFSET (A1: B1, A1, A2)”, the Polish entry element - the OFFSET function - will receive the type Value, while parsing the arguments, the first will be converted to Reference, the other two to Value. For all functions, we store information which arguments and what types should be passed to it.
The task of the parser is also to check the formula for correctness. We will consider the formula incorrect if Excel does not allow us to write it to the cell. In addition to syntax errors, an incorrect number of arguments passed to a function or data type mismatch to the requested one can also make the formula incorrect. For example, the ROW function either does not need parameters at all, or only one, and it should be exclusively Reference. We have already said that no other type can be cast to Reference, which means that the expressions “= ROW (1)”, “= ROW (“ A1 ”)” will be invalid.
Because our grammar is a complicated grammar for ordinary mathematical expressions, it is constructed in the same way depending on the seniority of operations. The first is followed by logical expressions, the last is range operators. Those. in order of increasing priority.
For visualization of RBNF I use a small program EBNF Visualizer . This is how the first nonterminal in our grammar will look like - a logical expression:
Next is the grammar for Coco / R. In semantic inserts drawn between “(.” And “.)” I will add the necessary ParsedThing to the expression.
LogicalClause
(. IParsedThing thing = null; .)
=
ConcatenateClause
{
(
'<' (.thing = ParsedThingLess.Instance; .)
| '>' (.thing = ParsedThingGreater.Instance; .)
| "<=" (.thing = ParsedThingLessEqual.Instance; .)
| ">=" (.thing = ParsedThingGreaterEqual.Instance; .)
| "<>" (.thing = ParsedThingNotEqual.Instance; .)
| '=' (.thing = ParsedThingEqual.Instance; .)
)
ConcatenateClause
(. expression.Add(thing); .)
}
.
According to this principle, they will be built: ConcatenateClause, AddClause, MultipyClause, PowerClause, UnaryClause, PercentClause, RangeUnionClause, RangeIntersectionClause, CellRangeClause. CellRangeClause ends with non-terminals describing the operators. It is followed by the first operand - OperandCommonClause. It will look something like this:
However, there is ambiguity in the given grammar. It lies in the fact that SheetName and OperandClause can start from the same terminal - with an identifier. For example, the expression “= Sheet! A1” may follow, or maybe “= name”. Here “Sheet” and “name” are identifiers. Fortunately, Coco / R allows you to resolve conflicts by scanning the incoming stream with the scanner several terminals ahead. Those. we can look in search of the '!' character, if one is found, then we parse SheetName, otherwise OperandClause. This is how the grammar will look:
OperandCommonClause
=
(
IF(IsSheetDefinition())
(
(
SheetNameQuoted
|
[ '[' FileDefinitionSimple ]
[
SheetName
[
':' SheetName
|
'|'
SingleQuotedIdent
]
]
)
'!'
CellReferenceClause
)
|
OperandClause
)
.
To resolve the conflict, the IsSheetDefinition () method defined in the Parser class is used. It is convenient to write such methods in a separate file, marking the class as partial.
The SheetName nonterminal can start with a digit or consist only of numbers. In this case, the sheet name must be enclosed in apostrophes. Otherwise, Excel adds the missing apostrophes.
SheetName
(. int sheetNameStart = la.pos;.)
=
(
[positiveinumber | fnumber]
[ident]
)
(. sheetName = scanner.Buffer.GetString(sheetNameStart, la.pos); .)
.
There are a couple of errors in this grammar. Firstly, all terminals inside the non-terminal are optional. And secondly, it allows you to insert a space or any character described in the IGNORE section between a number and an identifier. The problem can be solved using the conflict resolution mechanism, but without additional functions. Right in the grammar, we check for a gap between the number and the identifier following it:
SheetName
(. int sheetNameStart = la.pos;.)
=
(
positiveinumber | fnumber
[
IF(la.pos - t.pos == t.val.Length)
ident
]
|
ident
)
(. sheetName = scanner.Buffer.GetString(sheetNameStart, la.pos); .)
.
In OperandClause, we will get from OperandCommonClause if there is no link to the sheet, external book or DDE source. From this nonterminal, we can get to ArrayClause, StringConstant (both cannot have a link to the sheet in front of them), CellReferenceClause, or we will meet the bracket and go to the beginning of the entire parse tree - LogicalClause.
OperandClause
=
(
CellReferenceClause
|
ArrayClause
|
StringConstant
)
|
'('
CommonCellReference
')'
(. expression.Add(ParsedThingParentheses.Instance);.)
.
CellReferenceClause is probably the largest non-terminal, it contains almost all types of operands:
CellReferenceClause
=
(
IF (IsTableDefinition())
TableReferenceExpressionClause
|
IF (IsFunctionDefinition())
FunctionClause
|
IF (IsDefinedNameDefinition())
DefinedNameClause
|
IF(IsRCCellPosition())
CellPositionRCClause
|
IF(IsA1CellPosition())
CellPositionA1Clause
|
CellError
|
TermNumber
|
BoolConstant
|
wideident
(. expression.Add(new ParsedThingName(t.val);.)
)
.
Most non-terminals have to create conflict resolution methods. Next, we describe the grammar for all remaining non-terminals.
Parsing incomplete expressions and "predictions"
Consider the task of highlighting the ranges involved in the formula.
The problem here is that the expression can be invalid, and ranges should be highlighted anyway. At that moment, the parser, without mastering the expression, always returned null. Of course, one could try to figure out the partially read expression and collect links from it, but how do you know where in the expression the specific link is? Therefore, we decided to teach the parser to immediately put together everything interesting in the course of reading. So, all the links by type were in specially designed collections. A parser, when it detects, for example, a range reference, calls the corresponding method
void RegisterCellRange(CellRange range, int sheetDefinitionIndex, int position, int length)
After reading, regardless of whether it ended successfully or not, we have a set of links.
Another mechanism began to be based on this - predictions. In the expression “= 1 * (1 + 2”, the balance of the brackets is violated, but most likely the user forgot to put the bracket at the end of the expression. That is, you can try to fix this formula by adding the missing bracket to it. Of course, the parser does this he won’t just say where and what he thinks is missing, for example, in OperandClause we already know the following lines:
'('
CommonCellReference
(.
if(la.val != ")")
parserContext.RegisterSuggestion(new FunctionCloseBracketSuggestion(la.pos));
.)
')'
Of course, all these actions are done only when the expression is entered manually and there is a need to draw the ranges involved or try to correct the unfinished formula.
Computing Performance Optimization
Excel, still at the stage of parsing the expression, is trying to make it easier for itself further life. To this end, whenever possible, he fills the expression with all sorts of auxiliary elements. Let's look at them.
AttrSemi Attribute. This attribute is added as the first element in those expressions that contain volatile functions.
Attribute Class Mem. This includes several attributes at once. They are united by the fact that they are created to optimize the calculation of links. In fact, they are a wrapper over some expression. During the calculation, the internal expression may not be evaluated, the result will be Mem. A distinctive feature of these elements is that they are inserted in the reverse Polish notation before the expression that is optimized.
- ParsedThingMemFunc — указывает на то, что выражение внутри должно вычисляться каждый раз и не результат не может быть закеширован. Например, все выражение =INDIRECT(«A1»):B1 будет обернуто в MemFunc, т.к. функция INDIRECT является volatile функцией и при следующем расчете может вернуть уже другое значение.
- ParsedThingMemArea. Заключает в себе выражение, значение которого уже посчитано и не будет меняться. Это значение сохранится внутри атрибута и при следующем расчете в стек будет добавлено именно оно, а внутреннее выражение вычисляться вообще не будет.
- ParsedThingMemErr. Заключает в себе выражение, значение которого посчитано, не будет меняться и равно ошибке.
- ParsedThingMemNoMem. При вычислении выражения внутри Excel столкнулся с нехваткой памяти. На практике я такое ни разу не встречал.
The AttrSum attribute is used as a simplified form for writing the SUM function when only one argument is passed to the function.
The AttrIf attribute is used in conjunction with one or two Goto statements to optimize the calculation of the IF function. Let me remind you the syntax of the IF: IF function (condition, true_value, [false_value]). Of the two values, you can calculate only one and save time on calculating the other, if immediately after calculating the condition go to the desired value. Thus, the simple expression = IF (condition, ”v_true”, ”v_false”) Excel thickens with attributes. It turns out approximately the following:
The calculation goes like this. The value of condition is pushed onto the stack. The next in line is the IF attribute. He looks at the value on top of the stack. If it is true, it does nothing. If false, adds the current counter of elements in the expression to the offset recorded inside, thereby the counter begins to point to “v_false”. Next, either v_true or v_false is calculated and the result is pushed onto the stack. Next is Goto, first or second. But both of them refer to the end of the expression (or to the following operators in the expression, if any).
AttrChoose works in a very similar way. Let me remind you that the CHOOSE function selects one of the arguments whose sequence number is specified in the first argument.
Thus, only one argument affects the further result of the calculation, all the others can be skipped. AttrChoose stores a set of mixes, each of which points to the beginning of each subsequent argument. After the argument follows the familiar AttrGoto, which points to the end of the expression or the element following the CHOOSE function.
The Space attribute is used to save the format of the user-entered expression, namely line feeds and spaces. Each such attribute, in addition to quantity, has a type. There are only six types:
- SpaceBeforeBaseExpression,
- CarriageReturnBeforeBaseExpression,
- SpaceBeforeOpenParentheses,
- CarriageReturnBeforeOpenParentheses,
- SpaceBeforeCloseParentheses,
- CarriageReturnBeforeCloseParentheses,
- SpaceBeforeExpression;
Looking at these types, you can guess that Excel cannot keep spaces at the end of the line and before the '=' sign. In addition, spaces within structured links and arrays will not be saved either.
Testing
When our control just learned to read and write files in the OpenXML format, we hastened to check it in practice. And the best way for this is to find many, many files and try to drive the reading and writing of these files. So we pumped about 10k random OpenXML files and wrote a simple program. They created a task for her on a test farm. Every night, the task starts automatically and reads and writes files. If any errors occur, all the necessary information is recorded in the log. So we were able to debug a huge number of errors.
As the control developed, both supported formats and features were added. So now 20k xls files and 15k csv files are constantly being tested. And they are tested not only for read-write, but also checked by third-party utilities, which also help us a lot.
We got a huge amount of knowledge about the work of formulas in Excel when we launched the task of testing formula calculations from the same 10k OpenXML and 20k xls files. The file is opened, written to the data model. Then, in turn, we begin to mark the cells on the sheet as not counted, calculate and compare the new value with the value that was read from the file. Thus, we killed two birds with one stone - we debugged the formula parser and brought the calculation results as close as possible to those obtained using Excel.
Of course, we did not get rid of all the problems associated with formulas - this is too extensive a topic. But already a lot of things have been studied and implemented, and we are not resting on our laurels. Personally, I was interested to work on it, I hope that it was interesting for you to read this article.
Thanks for attention!